Содержание лабораторной работы.
1. В соответствии с поставленной задачей исследования определить необходимые фиктивные переменные и спецификацию модели.
2. Сформировать и ввести выборочные данные с учетом фиктивных переменных.
3. Методом наименьших квадратов оценить параметры модели (следуя работе №6).
4. Верификация модели (проверка значимости коэффициентов уравнения регрессии и всего уравнения в целом при уровне значимости α=0,05), оценка качества построенной модели.
5. По критерию Чоу проверить гипотезу о однородности выборок для разных значений качественного признака».
6. Интерпретация модели и общее заключение о проведенном исследовании.
Выполнение работы в MSExcel. Построение регрессионной модели с фиктивными переменными рассмотрим на примере исследования зависимости заработной платы Y (тыс. руб.) от возраста X(лет) и пола работника по данным приведенным в таблице 8.1
Таблица 8.1
| № п/п | Y | X | Пол | № п/п | Y | X | Пол |
| 1 | 30 | 29 | Ж | 11 | 25 | 28 | Ж |
| 2 | 40 | 40 | М | 12 | 35 | 30 | М |
| 3 | 30 | 36 | Ж | 13 | 20 | 25 | М |
| 4 | 32 | 32 | Ж | 14 | 40 | 48 | М |
| 5 | 20 | 23 | М | 15 | 22 | 30 | Ж |
| 6 | 35 | 45 | Ж | 16 | 32 | 40 | М |
| 7 | 35 | 38 | Ж | 17 | 39 | 40 | М |
| 8 | 40 | 40 | М | 18 | 36 | 38 | М |
| 9 | 38 | 50 | М | 19 | 26 | 29 | Ж |
| 10 | 40 | 47 | М | 20 | 25 | 25 | М |
Определение необходимой фиктивной переменной и спецификации модели. В данной задаче «Пол» является качественнымпризнаком, принимающим два значения. Признак представим фиктивной бинарной переменной zпринимающей значение 1 для мужчин и 0 для женщин. Этот признак может оказывать влияние на среднюю зарплату при одинаковом возрасте мужчин и женщин, а также приводить к разному изменению зарплаты с изменением возраста. Поэтому рассмотрим две модели с фиктивной переменной:
|
|
|
 ; (8.6)
; (8.6)
 . (8.7)
. (8.7)
Первая из них позволяет проанализировать различие средних зарплат мужчин и женщин одинакового возраста. Вторая позволяет также проанализировать влияние пола работника на изменение средней зарплаты с увеличением возраста работника. Переменная  во второй модели представляет новую количественную объясняющую переменную.
во второй модели представляет новую количественную объясняющую переменную.
Формирование и ввод выборочных данных с учетом фиктивных переменных. Для обеих моделей построим в MSExcel единую матрицу значений объясняющих переменных. В ячейках A1-А21 расположим имя фактора Х (возраст) и его выборочные значения, в ячейках B1-В21 имя фиктивной переменной (пол) и его оцифрованные значения, в ячейках С1-С21 имя новой переменной ( ) и его значения, в ячейках D1-D21 имя зависимой переменной Y (зарплата) и его выборочные значения (см. рис. 8.1).
Оценка параметров модели. Оценка параметров обеих моделей производится с помощью функции «Регрессия» также как в лабораторной работе № 6. Результаты регрессии для первой модели (8.6) приведены на рис. 8.1, для второй модели (8.7) на рис. 8.2.
|
|
|

Рис. 8.1. Регрессия с фиктивной переменной z
Оценка значимости коэффициентов уравнений регрессии и уравнений в целом, оценка качества построенных моделей. Из приведенных результатов следует, что оцененная модель (8.6) имеет вид
 ,
,
а модель (8.7)

По F-критерию оба уравнения статистически значимы, но коэффициенты при фиктивной переменной z и новой переменнойxz незначимо отличаются от нуля при уровне значимости α=0,05. Скорректированные коэффициенты детерминации, равные для первой модели 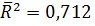 и для второй
и для второй  , говорят об удовлетворительном качестве подгонки. Следуя работе № 4, построим линейное уравнение регрессии без учета фактора «Пол». Полученное уравнение
, говорят об удовлетворительном качестве подгонки. Следуя работе № 4, построим линейное уравнение регрессии без учета фактора «Пол». Полученное уравнение 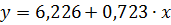 значимо, так как значимость Fдля F-статистики, равная
значимо, так как значимость Fдля F-статистики, равная  , меньше заданного уровня значимости α=0,05. Скорректированный коэффициент детерминации равен 0,713. Результаты этой регрессии приведены на рис. 8.3.
, меньше заданного уровня значимости α=0,05. Скорректированный коэффициент детерминации равен 0,713. Результаты этой регрессии приведены на рис. 8.3.

Рис. 8.2. Регрессия с переменными z и xz

Рис. 8.3. Регрессия Y на X
Проверка гипотезы об однородности выборок по критерию Чоу. Исходную выборку разделим на две части по значению признака «Пол». Результаты этого разбиения приведены на рис. 8.4. На каждой из выборок оценим линейную регрессию Y на X. Их результаты приведены на рис. 8.5-8.6.
|
|
|

Рис. 8.4. Выборки, сгруппированные по признаку «Пол»

Рис. 8.5. Регрессии по отдельным выборкам
Вычислим значение F-статистики критерия Чоу и критическое значение F-статистики. В рассматриваемом примере объем выборки n=20, число объясняющих переменных p=1, уровень значимости 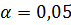 . Для нахождения сумм квадратов остатков используем функцию СУММКВ в группе «Математические» вкладки «Формулы». Выделим ячейку F183 и, учитывая формулу (8.5) и расположение остатков регрессий по полной выборке и ее частям, в строке формул введем
. Для нахождения сумм квадратов остатков используем функцию СУММКВ в группе «Математические» вкладки «Формулы». Выделим ячейку F183 и, учитывая формулу (8.5) и расположение остатков регрессий по полной выборке и ее частям, в строке формул введем
=(СУММКВ(M103:M122)-СУММКВ(C170:C181)- СУММКВ(O170:O177))* (20-2-2)/((СУММКВ(C170:C181)+СУММКВ(O170:O177))*(1+1))
По «Enter» в ячейке F183получим вычисленное значение F-статистики равное 0,538. Для нахождения критического значения F-статистики используем функцию F.ОБР.ПХ группы «Статистические». Выделим ячейку H183и, учитывая объем выборки n=20 и число объясняющих переменных p=1, в строке формул введем
=F.ОБР.ПХ(0,05;2;16)
По «Enter в ячейке»Н183получим критическое значение F-статистики равное 3,634,см. рис. 8.6. Вычисленное значение F-статистики меньше критического, следовательно, нулевая гипотеза об однородности отдельных выборок принимается.
|
|
|

Рис. 8.6. Проверка однородности выборок по тесту Чоу
Интерпретация модели и общее заключение о проведенном исследовании.
Все три построенных уравнения регрессии заработной платы (y) от возраста (x) с учетом и без учета пола (z) работников
,

статистически значимы при заданном уровне значимости α=0,05 и имеют примерно одинаковые аппроксимационные свойства. Их нормированные коэффициенты детерминации равны соответственно 0,712, 0,697, 0,712. Во всех построенных уравнениях регрессии возраст x работников значимо влияет на заработную плату.Так как P-значения для коэффициентов регрессии при x, равные соответственно  , меньше заданного уровня значимости α.В первом и втором уравнениях P-значения для коэффициентов регрессии при поле работников и факторе xzзначительно превышают заданный уровень значимости. Следовательно, пол z работников и фактор xzне оказывают значимого влияния на заработную плату работников.
, меньше заданного уровня значимости α.В первом и втором уравнениях P-значения для коэффициентов регрессии при поле работников и факторе xzзначительно превышают заданный уровень значимости. Следовательно, пол z работников и фактор xzне оказывают значимого влияния на заработную плату работников.
Согласно первой модели при одинаковом возрасте средняя заработная плата работников мужчин на 1,727 тыс. руб. больше чем у женщин. С увеличением возраста на один год средняя заработная плата возрастает примерно на 0,723 тыс. руб. по третьей модели и на 0,698 тыс. руб. по первой. Уравнение, включающее произведение факторов «Возраст» и «Пол», имеет несколько худшее качество подгонки.
Анализ однородности отдельных выборок для мужчин и женщин по тесту Чоу показал их однородность. Поэтому эти выборки можно объединить в одну и использовать уравнение регрессии , построенное по объединенной выборке.
Контрольные вопросы:
1. Для учета влияния каких факторов используются фиктивные переменные в моделях регрессии?
2. Какие значения может принимать бинарная фиктивная переменная?
3. Сколько фиктивных переменных следует ввести в модель для учета региональных различий, если данные собраны по пяти регионам?
4. Как используются фиктивные переменные для моделирования сезонного фактора?
5. Какие из перечисленных факторов учитываются в регрессии с помощью фиктивных переменных: 1) профессия, 2) курс доллара, 3) численность населения, 4) размер среднемесячных потребительских расходов, 5) местоположение пункта продажи?
6. С помощью фиктивных переменных напишите уравнение, соответствующее наличию двух структурных изменений в моменты времени  и
и  ,
,  <
<  .
.
7. Может ли уравнение регрессии в качестве объясняющих переменных содержать только фиктивные переменные?
8. Каким методом осуществляется оценка моделей регрессии с фиктивными переменными?
9. Как формулируется гипотеза об однородности двух выборок в регрессионном смысле?
10. Как осуществляется проверка на однородность в регрессионном смысле двух выборок по критерию Чоу?
11. Как учитывается влияние качественного фактора на коэффициент регрессии?
Лабораторная работа № 9. Выделение тенденции временного ряда:
скользящая средняя; экспоненциальное сглаживание
Цель работы. Освоение основных понятий анализа одномерных временных рядов, методов выделения тенденции временного ряда с использованием пакета анализа MSExcel 2010.
Краткие сведения.
Временной ряд – это совокупность значений  некоторого числового показателя за несколько последовательных моментов или периодов времени
некоторого числового показателя за несколько последовательных моментов или периодов времени  , характеризующая состояние и изменение изучаемого явления. Моменты времени на оси времени располагаются через одинаковые промежутки, а периоды времени одинаковой длины. Значения
, характеризующая состояние и изменение изучаемого явления. Моменты времени на оси времени располагаются через одинаковые промежутки, а периоды времени одинаковой длины. Значения  показателя в моментtили период времени называются уровнями временного ряда. Моментный временнойряд – уровни временного ряда характеризуют изучаемое явление в конкретные последовательные (равноотстоящие) моменты времени. Интервальный временнойряд – уровни временного ряда характеризуют изучаемое явление в последовательные равные промежутки времени. Существенным отличием временных рядов от пространственных данных является статистическая зависимость значений показателя в момент времени от его значений в предшествующие моменты времени.
показателя в моментtили период времени называются уровнями временного ряда. Моментный временнойряд – уровни временного ряда характеризуют изучаемое явление в конкретные последовательные (равноотстоящие) моменты времени. Интервальный временнойряд – уровни временного ряда характеризуют изучаемое явление в последовательные равные промежутки времени. Существенным отличием временных рядов от пространственных данных является статистическая зависимость значений показателя в момент времени от его значений в предшествующие моменты времени.
Уровни изучаемого временного ряда должны быть:
· однородными по экономическому содержанию и отражать существо изучаемого явления и цель исследования;
· измеренными по единой методике и в единых единицах измерения;
· не содержать аномальных (значительно отличающихся от других) наблюдений.
Уровни временного ряда формируются из следующих компонент:
· тенденции (тренда)  – характеризует изменение явления (процесса), происходящее в некотором направлении в течение значительного промежутка времени (описывает чистое влияние долговременных факторов);
– характеризует изменение явления (процесса), происходящее в некотором направлении в течение значительного промежутка времени (описывает чистое влияние долговременных факторов);
· циклической компоненты  – отражает повторяемость экономических процессов в течение длительных периодов, представляет собой более быстрые, чем тенденция квазипериодические колебания изучаемого признака;
– отражает повторяемость экономических процессов в течение длительных периодов, представляет собой более быстрые, чем тенденция квазипериодические колебания изучаемого признака;
· сезонных колебания  – отражает регулярную повторяемость экономических процессов в течение не очень длительных промежутков времени. Связаны, например, со сменой времен года и ритмами человеческой активности;
– отражает регулярную повторяемость экономических процессов в течение не очень длительных промежутков времени. Связаны, например, со сменой времен года и ритмами человеческой активности;
· случайной компоненты  – отражающей влияние не поддающихся учету и регистрации случайных факторов.
– отражающей влияние не поддающихся учету и регистрации случайных факторов.
Циклическая и сезонная компоненты характеризуют колебания уровней временного ряда относительно основной тенденции, а случайная компонента – случайный разброс уровней относительно тенденции и сезонной (и/или циклической) составляющей. Тенденция, циклическая и сезонные компоненты, при их наличии, определяют детерминированную часть уровней временного ряда.
Основные описательные статистики временных рядов средняя и дисперсия рассчитываются по обычным формулам:
 ;
;  .
.
Для характеристики корреляционной зависимости между последовательными уровнями временного ряда, отстоящими друг от друга на  промежутка времени, используется выборочный коэффициент автокорреляции k-го порядка
промежутка времени, используется выборочный коэффициент автокорреляции k-го порядка
 ,
,
 ,
,  .
.
Последовательность значений  ,
,  ,
,  , … выборочных коэффициентов автокорреляции называют выборочной автокорреляционной функцией (коррелограммой) временного ряда, аргументом которой является величина k.
, … выборочных коэффициентов автокорреляции называют выборочной автокорреляционной функцией (коррелограммой) временного ряда, аргументом которой является величина k.
Основные задачи анализа временных рядов заключаются:
· в определении его структуры (из каких компонент состоят уровни временного ряда);
· в выделении и придании количественного описания каждой его компоненте;
· построение математической модели процесса, представленного временным рядом;
· в построении прогноза будущих значений временного ряда.
В зависимости от характера колебаний уровней относительно тренда временного ряда различают:
аддитивную модель тренда и сезонности  Она применяется при приблизительно одинаковой амплитуде периодических колебаний уровней, обусловленных наличием сезонной и/или циклической компоненты, вокруг тренда;
Она применяется при приблизительно одинаковой амплитуде периодических колебаний уровней, обусловленных наличием сезонной и/или циклической компоненты, вокруг тренда;
мультипликативную модель тренда и сезонности  . Применяется при возрастающей или убывающей амплитуде сезонных или циклических колебаний уровней вокруг тренда.
. Применяется при возрастающей или убывающей амплитуде сезонных или циклических колебаний уровней вокруг тренда.
Построение аддитивной и мультипликативной модели сводится к оценке значений их компонент  для каждого уровня ряда.
для каждого уровня ряда.
Методы распознавания наличия тренда и его типа.
Графический метод. Графическое изображение временного ряда часто позволяет установить наличие тренда и его тип: линейный, нелинейный (параболический, степенной, экспоненциальный, логарифмический, гиперболический, логистический).
Методы сглаживания и фильтрации предназначеныдля преобразования временных рядов с целью удаления из них высокочастотных или сезонных колебаний уровней ряда относительно тренда и выделения основной тенденции (тренда). В этом подходе различают методы скользящей средней и аналитического выравнивания.
В методах скользящих средних наблюдаемые значения уровней временного ряда заменяются средними их значениями, вычисляемыми на отрезке (за несколько последовательных моментов времени) скользящем вдоль временного ряда. Отклонения уровней от тренда, вызванные сезонными и высокочастотными колебаниями, имеют разные знаки, и усреднение позволяет исключить эти колебания из уровней временного ряда и выделить тренд.
Аналитическое выравнивание заключается в оценивании тренда как некоторой явной функции времени , т.е.  .
.
Метод корреляционного анализа. Основывается на анализе выборочной автокорреляционной и частной автокорреляционной функций временного ряда.
Метод проверки статистических гипотез о типе тренда. Этот метод основывается на вычислении средних характеристик динамики процесса (абсолютного прироста, абсолютного ускорения, темпа роста, темпа прироста, эластичности) на отдельных непересекающихся частях временного ряда и проверки гипотезы о незначимости их различия. Если такая гипотеза принимается, то принимается и решение о наличии соответствующего тренда. Например, принятие гипотезы о равенстве средних абсолютных приростов  на разных частях временного ряда говорит о наличии линейного тренда
на разных частях временного ряда говорит о наличии линейного тренда 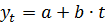 , а принятие гипотезы о равенстве средних темпов прироста говорит о наличии экспоненциального тренд
, а принятие гипотезы о равенстве средних темпов прироста говорит о наличии экспоненциального тренд 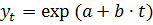 .
.
В данной работе рассматривается выделение тренда временного ряда с использованием метода скользящей средней и экспоненциального сглаживания.
Простая скользящая средняя. Среднее уровней ряда, попавших в отрезок (окно) скольжения, вычисляется как обычное выборочное среднее. Отрезок скольжения, на котором вычисляется текущее среднее уровней временного ряда, может содержать нечетное 2k+1 или четное 2k количество уровней ряда.
При нечетной 2k+1 длине окна скольжения, вычисленное среднее определяет значение тренда в средней (k+1)-й точке этого окна. Т.е. значения тренда  для моментов времени
для моментов времени  определяется как
определяется как  . Например, при длине окна скольжения равном 5 (k=2) среднее
. Например, при длине окна скольжения равном 5 (k=2) среднее 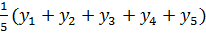 пяти первых уровней принимается за значение тренда для момента времени
пяти первых уровней принимается за значение тренда для момента времени  . Затем окно сдвигается вправо на один момент времени и среднее
. Затем окно сдвигается вправо на один момент времени и среднее  уровней ряда, попавших в это окно, принимается за значение тренда для момента времени
уровней ряда, попавших в это окно, принимается за значение тренда для момента времени  . Последовательно сдвигая окно скольжения на один шаг вправо, получают значения тренда для следующих моментов времени. Последнее значение тренда для момента времени
. Последовательно сдвигая окно скольжения на один шаг вправо, получают значения тренда для следующих моментов времени. Последнее значение тренда для момента времени  определяется как
определяется как  .
.
При четной 2k длине окна скольжения (например, для квартальных данных имеющих сезонную компоненту), вычисленное среднее определяет значение тренда для середины промежутка времени между k-м и (k+1)-м моментами времени, вошедшими в окно скольжения. Эти промежуточные моменты времени не присутствуют во временном ряде. Поэтому, после нахождения значений тренда в промежуточных точках, значения тренда для моментов времени рассматриваемых во временном ряде определяются как среднее двух значений тренда в соседних промежуточных точках. Например, при длине окна скольжения равном четырем (k=2) значения тренда сначала вычисляются для промежуточных моментов времени 2,5; 3,5; 4,5; …; n-2,5. Затем вычисляется значение тренда для как среднее значений тренда для моментов времени 2,5 и 3,5; значение тренда для как среднее значений тренда для моментов времени 3,5 и 4,5 и так далее.
Взвешенная скользящая средняя. В этом случае значение тренда для момента времени соответствующего середине окна скольжения с нечетной длиной определяется как взвешенное среднее уровней ряда, попавших в окно. Т.е. значения тренда для моментов времени определяется как
 .
.
Весовые коэффициенты  определяются в зависимости от длины 2k+1 окна скольжения и степени
определяются в зависимости от длины 2k+1 окна скольжения и степени  полинома
полинома 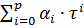 ,
,  используемого для аппроксимации уровней ряда внутри окна скольжения. При длине окна скольжения равной 5 и степени pаппроксимирующего полинома равной 2 или 3 весовые коэффициенты имеют значения
используемого для аппроксимации уровней ряда внутри окна скольжения. При длине окна скольжения равной 5 и степени pаппроксимирующего полинома равной 2 или 3 весовые коэффициенты имеют значения  ,
,  ,
,  . Для длины окна скольжения равной 7 и степени pаппроксимирующего полинома равной 2 или 3 весовые коэффициенты имеют значения
. Для длины окна скольжения равной 7 и степени pаппроксимирующего полинома равной 2 или 3 весовые коэффициенты имеют значения  ,
,  ,
,  ,
,  ,
,  .
.
Метод простой скользящей средней дает хорошие результаты для временных рядов с линейной тенденцией. Для рядов с нелинейной тенденцией необходимо применять метод взвешенной скользящей средней.
Метод экспоненциального сглаживания. При построении прогноза  временного ряда для момента времени t+1 часто используется взвешенная сумма его предшествующих уровней
временного ряда для момента времени t+1 часто используется взвешенная сумма его предшествующих уровней  . Очевидно, что более поздние наблюдения
. Очевидно, что более поздние наблюдения  играют большую роль при формировании уровня ряда для момента времени t+1, чем более ранние наблюдения. Более ранние наблюдения содержат «старую» тенденцию, а более поздние наблюдения отражают «новую» тенденцию. Один из способов уменьшения роли более ранних наблюдений заключается в том, что коэффициенты
играют большую роль при формировании уровня ряда для момента времени t+1, чем более ранние наблюдения. Более ранние наблюдения содержат «старую» тенденцию, а более поздние наблюдения отражают «новую» тенденцию. Один из способов уменьшения роли более ранних наблюдений заключается в том, что коэффициенты  образуют убывающую геометрическую прогрессию,
образуют убывающую геометрическую прогрессию, 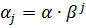 , и прогноз
, и прогноз  определяется соотношением
определяется соотношением
 ,
,
где  . Правая часть этого соотношения называется экспоненциально взвешенным скользящим средним, а построение прогнозов по этому соотношению называют экспоненциальным сглаживанием временного ряда,
. Правая часть этого соотношения называется экспоненциально взвешенным скользящим средним, а построение прогнозов по этому соотношению называют экспоненциальным сглаживанием временного ряда, 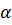 – параметр сглаживания.
– параметр сглаживания.
Путем несложных преобразований экспоненциальное сглаживание сводится к рекуррентной формуле
 ,
,
выражающей значение экспоненциального среднего как суммы экспоненциального среднего  предыдущего момента времени и доли разницы текущего наблюдения и . Применение экспоненциального сглаживания связано с выбором значения параметра сглаживания и начального значения
предыдущего момента времени и доли разницы текущего наблюдения и . Применение экспоненциального сглаживания связано с выбором значения параметра сглаживания и начального значения  . При близком к единице веса предшествующих наблюдений быстро убывают и на прогноз оказывают большое влияние только последние наблюдения. Это приводит к малым расхождениям сглаженных значений от наблюдаемых значений ряда. При близком к нулю в прогнозе веса предшествующих наблюдений убывают медленно, что приводит к отфильтровыванию случайных колебаний уровней временного ряда. В практических расчетах значение параметра сглаживания определяют, как
. При близком к единице веса предшествующих наблюдений быстро убывают и на прогноз оказывают большое влияние только последние наблюдения. Это приводит к малым расхождениям сглаженных значений от наблюдаемых значений ряда. При близком к нулю в прогнозе веса предшествующих наблюдений убывают медленно, что приводит к отфильтровыванию случайных колебаний уровней временного ряда. В практических расчетах значение параметра сглаживания определяют, как  или как
или как 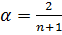 , где N – число наблюдений, входящих в интервал сглаживания,n – число наблюдений во временном ряде. За начальное сглаженное значение принимается первое значение
, где N – число наблюдений, входящих в интервал сглаживания,n – число наблюдений во временном ряде. За начальное сглаженное значение принимается первое значение  временного ряда.
временного ряда.
Использование экспоненциального сглаживания для выравнивания временного ряда оправдано для временных рядов с незначительным сезонным эффектом.
Прогноз уровней ряда методом экспоненциального сглаживания для будущих моментов времени:  ,
,  . Таким образом, прогноз будущих значений для моментов времени n+2, n+3 и так далее совпадает с прогнозом
. Таким образом, прогноз будущих значений для моментов времени n+2, n+3 и так далее совпадает с прогнозом  .
.
Дата добавления: 2018-04-15; просмотров: 727; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!