Содержание лабораторной работы.
1. Ввести выборочные данные и построить диаграмму рассеяния.
2. Оценить параметры уравнения парной линейной регрессии.
3. Проверить значимость коэффициента корреляции, параметров уравнения регрессии и самого уравнения регрессии при уровне значимости 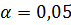 .
.
4. Оценить точность построенной модели. Построить 95%-й доверительный интервал для дисперсии 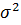 ошибки регрессии.
ошибки регрессии.
5. Построить точечные и интервальные, надежности 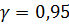 , прогнозы среднего зависимой переменной для выборочныхзначений независимой переменной. Построить линию регрессии и 95%-е доверительные кривые.
, прогнозы среднего зависимой переменной для выборочныхзначений независимой переменной. Построить линию регрессии и 95%-е доверительные кривые.
6. Дать общее заключение об оцененной модели и ее интерпретацию.
Выполнение работы в MSExcel. Выполнение работы в Excel рассмотрим на примере построения регрессионной зависимости  совокупных расходов на жилье (y, млрд.дол.) от располагаемого совокупного личного дохода (x, млрд. дол.) (функции спроса на жилье в зависимости от располагаемого дохода), используя данные для США за 1959–1970 г., приведенные в книге К. Доугерти «Введение в эконометрику». Эти данные приведены на рис. 4.1.
совокупных расходов на жилье (y, млрд.дол.) от располагаемого совокупного личного дохода (x, млрд. дол.) (функции спроса на жилье в зависимости от располагаемого дохода), используя данные для США за 1959–1970 г., приведенные в книге К. Доугерти «Введение в эконометрику». Эти данные приведены на рис. 4.1.
Ввод данных и построение диаграммы рассеяния. Выборочные данные по расходам на жилье и располагаемому личному доходу разместим по столбцам: в ячейке А1 имя независимой переменной 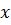 , в ячейках А2–А13 ее наблюдаемые значения; в ячейке В1 имя зависимой переменной
, в ячейках А2–А13 ее наблюдаемые значения; в ячейке В1 имя зависимой переменной  , в ячейках В2–В13 ее наблюдаемые значения, соответствующие значениям независимой переменной.
, в ячейках В2–В13 ее наблюдаемые значения, соответствующие значениям независимой переменной.
|
|
|
Для построения диаграммы рассеяния выберем вкладку «Вставка», в группе «Диаграммы» выберем «Точечная», в ее окне выберем тип диаграммы «Точечная с маркерами». Далее во вкладке «Работа с диаграммами» откроем вкладку «Конструктор» и в группе «Макеты диаграмм» выберем «Макет 1», а в группе «Данные» откроем «Выбрать данные». В открывшемся окне «Выбор источника данных» в поле «Диапазон данных для диаграммы» введем диапазон ячеек с данными для диаграммы, в рассматриваемом примере $A$1:$B$13. Внимание! В первом столбце (строке) должны находится значения независимой переменной. По «ОК» на открытом листе Excel получим диаграмму рассеяния. В соответствующих полях введем необходимые названия осей координат и название диаграммы. Диаграмма рассеяния представлена на рис.4.1.

Рис. 4.1. Данные и диаграмма рассеяния
Оценка уравнения парной линейной регрессии.Откроем вкладку «Данные», в группе «Анализ» выберем надстройку «Анализ данных». В открывшемся окне «Инструменты анализа» выберем функцию «Регрессия». В появившемся окне «Регрессия» укажем входные данные для оценки параметров регрессии, выводимые результаты и их расположение. Заполнение окна «Регрессия» для рассматриваемого примера приведено на рис. 4.2. В части «Входные данные» в поле ввода «Входной интервал Y» указываем диапазон ячеек, содержащий значения зависимой переменной, в нашем примере это B1:B13; в поле ввода «Входной интервал X» – диапазон ячеек, содержащий значения независимой переменной, в примере это A1:A13. В поле «Метки» устанавливаем флажок  , он указывает на то, что первые строки диапазонов данных содержат имена этих данных (заголовки). В «Константа-ноль» флажок не устанавливаем, в этом случае строится регрессия
, он указывает на то, что первые строки диапазонов данных содержат имена этих данных (заголовки). В «Константа-ноль» флажок не устанавливаем, в этом случае строится регрессия 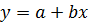 ; при установке флажка строится регрессия
; при установке флажка строится регрессия  без постоянной
без постоянной  . При установке флажка в левом поле «Уровень надежности», наряду с используемым по умолчанию стандартным уровнем надежности 95% (
. При установке флажка в левом поле «Уровень надежности», наряду с используемым по умолчанию стандартным уровнем надежности 95% ( 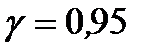 ), можно задать и другое его значение, в этом случае будут выведены интервальные оценки параметров регрессии для двух уровней надежности.
), можно задать и другое его значение, в этом случае будут выведены интервальные оценки параметров регрессии для двух уровней надежности.
|
|
|

Рис. 4.2. Заполнение окна регрессия
В части «Параметры вывода» указывается одно из мест расположения выводимых результатов:
· «Выходной интервал» – для помещения результатов на текущем рабочем листе, положение результатов указывается заданием верхней левой ячейки, начиная с которой располагаются результаты;
· «Новый рабочий лист» – для расположения результатов на новом рабочем листе;
|
|
|
· «Новая книга» – для помещения результатов в новой книге.
В нашем примере выбран «Выходной интервал» и ячейка А20. Далее, выставляя флажки, указываем какую дополнительную информацию, предлагаемую функцией «Регрессия», мы хотим иметь в результатах:
· «Остатки» – для выдачи прогнозов  и остатков регрессии
и остатков регрессии  ;
;
· «Стандартизованные остатки» – для вывода нормированных остатков  ;
;
· «График нормальной вероятности» – для вывода таблицы, в которой указывается какими перцентилями являются наблюдаемые значения зависимой переменной Y, и построения соответствующего графика;
· «График остатков» – для вывода точечной диаграммы остатков  ;
;
· «График подбора» – для вывода наложенных на диаграмму рассеяния точек (  ) линии регрессии
) линии регрессии  .
.
В примере выбраны«Остатки», «График остатков» и «График подбора». По ОКполучаем результаты регрессии, которые включают в себя таблицу регрессионной статистики, таблицу дисперсионного анализа, таблицу коэффициентов регрессии, таблицу остатков и графики остатков и подбора. Результаты регрессии приведены на рис. 4.3-4.4. В действительности на экране несколько иная картина, что обусловлено тем, что заголовки некоторых строк и столбцов таблиц не умещаются в ячейках и выводимые графики наложены друг на друга и расположены в правой верхней части экрана. Проведем коррекцию представления полученных результатов.
|
|
|

Рис. 4.3. Таблицы итогов регрессии.
Прежде всего, отформатируем ячейки содержащие заголовки для получения их полного текста. Для этого, выделив ячейку, щелкнем на ней правой клавишей мышки и в появившемся меню выберем Формат ячейки, затем в окне формата ячейки щелкнем Выравниваниеи в его окне установим флажок в позиции перенос по словам, щелкнув ОК получим полный текст заголовка. Разнесем графики подбора и остатков, разместив их рядом с таблицей остатков.

Рис. 4.4. Остатки и графики результатов регрессии
Пояснения к таблице «Регрессионная статистика»:
· Множественный  – множественный коэффициент корреляции между и
– множественный коэффициент корреляции между и  , для парной линейной регрессии значение выборочного коэффициента корреляции
, для парной линейной регрессии значение выборочного коэффициента корреляции 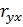 ;
;
·  -квадрат – коэффициент детерминации
-квадрат – коэффициент детерминации  ;
;
· Нормированный -квадрат – скорректированный коэффициент детерминации 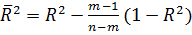 , где
, где 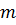 число коэффициентов в модели регрессии;
число коэффициентов в модели регрессии;
· Стандартная ошибка – оценка 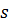 среднеквадратического отклонения
среднеквадратического отклонения  ошибок регрессии
ошибок регрессии  , т.е.
, т.е.  ;
;
· Наблюдений – объем выборки 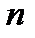 .
.
Пояснения к таблице «Дисперсионный анализ»:
· df – число степеней свободы.
· SS – сумма квадратов.
· MS – средние квадраты.
· F – вычисленное значение критерия Фишера (F-статистики).
· Значимость F – уровень значимости, при котором вычисленное значение критерия Фишера является критической точкой распределения Фишера. Нулевая гипотеза о незначимости уравнения регрессии  отклоняется, если это значение меньше заданного уровня значимостиα.
отклоняется, если это значение меньше заданного уровня значимостиα.
· В строке «Регрессия» приведены число степеней свободы равное  , сумма квадратов отклонений
, сумма квадратов отклонений  объясняемых регрессией, средний квадрат
объясняемых регрессией, средний квадрат 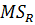 , значение F и значимость F.
, значение F и значимость F.
· В строке «Остаток» приведены число степеней свободы равное  , остаточная сумма квадратов отклонений
, остаточная сумма квадратов отклонений  , остаточный средний квадрат
, остаточный средний квадрат 
· В строке «Итого» приведены число степеней свободы  и общая сумма квадратов отклонений
и общая сумма квадратов отклонений  .
.
Следующая таблица содержит МНК-оценки коэффициентов уравнения регрессии, их стандартные ошибки, значения t-статистик для проверки нулевых гипотез  и
и  , P-значения и границы доверительных интервалов для коэффициентов уравнения регрессии для заданных надежностей.
, P-значения и границы доверительных интервалов для коэффициентов уравнения регрессии для заданных надежностей.
В строке с именем «Y-пересечение» приводятся:
· оценка  коэффициента ;
коэффициента ;
· ее стандартная ошибка  ;
;
· вычисленное значение t-статистики, равное  ;
;
· P-значение – вероятность того, что случайная величина имеющая распределение Стьюденте (t-распределение) с числом степеней свободы n-2 примет значение по абсолютной величине больше, чем модуль вычисленного значения t-статистики, т.е. P-значение это уровень значимости, при котором вычисленное значение t-статистики является критической точкой, следовательно, нулевая гипотеза отклоняется, если P-значение меньше заданного уровня значимости, и принимается в противном случае;
· нижняя и верхняя границы 95% доверительного интервала для  .
.
В строке с именем «X» приводятся аналогичные данные для коэффициента  уравнения регрессии.
уравнения регрессии.
Таблица «Вывод остатка» содержит порядковые номера наблюдений  , предсказанные (прогнозные) значения среднего зависимой переменной
, предсказанные (прогнозные) значения среднего зависимой переменной  и остатки регрессии
и остатки регрессии  .
.
На графике подбора выводится диаграмма рассеяния и точки  линии регрессии . На графике остатков представлены остатки
линии регрессии . На графике остатков представлены остатки  для наблюдаемых значений
для наблюдаемых значений 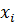 .
.
Таким образом, в рассматриваемом примере выполнив функцию «Регрессия» мы получили:
· уравнение регрессии 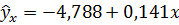 ;
;
· оценку среднеквадратического отклонения ошибок регрессии  и оценку дисперсии ошибок
и оценку дисперсии ошибок  ;
;
· 95%-е доверительные интервалы для коэффициентов уравнения регрессии  и
и  ;
;
· значение t-статистики для коэффициента ,  , и ее P-значение, равное
, и ее P-значение, равное  . P-значение больше заданного уровня значимости поэтому принимаем гипотезу , коэффициент
. P-значение больше заданного уровня значимости поэтому принимаем гипотезу , коэффициент  незначимо отличается от нуля.
незначимо отличается от нуля.
· значение t-статистики для коэффициента ,  , и ее P-значение равное
, и ее P-значение равное  , что значительно меньше заданного уровня значимости 0,05, поэтому отклоняем гипотезу , следовательно, уравнение регрессии значимо;
, что значительно меньше заданного уровня значимости 0,05, поэтому отклоняем гипотезу , следовательно, уравнение регрессии значимо;
· коэффициент детерминации  вычисленное значение F-статистики,
вычисленное значение F-статистики, 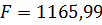 и ее уровень значимости, равный
и ее уровень значимости, равный  , что значительно меньше заданного уровня значимости 0,05, это позволяет отклонить нулевую гипотезу о незначимости коэффициента детерминации
, что значительно меньше заданного уровня значимости 0,05, это позволяет отклонить нулевую гипотезу о незначимости коэффициента детерминации  и сделать вывод о значимости уравнения регрессии;
и сделать вывод о значимости уравнения регрессии;
· выборочный коэффициент корреляции, совпадающий со значением «Множественный R» таблицы «Регрессионная статистика», т.е.  ;
;
· прогнозные значения  среднего зависимой переменной и остатки регрессии
среднего зависимой переменной и остатки регрессии  для наблюдаемых значений ;
для наблюдаемых значений ;
· линию регрессии, наложенную на диаграмму рассеяния и график остатков.
Проверка значимости коэффициента корреляции. Проверка значимости коэффициента корреляции, гипотезы  , заключается в проверке неравенства (4.3). В ячейке В23 находится значение коэффициента корреляции, объем выборки
, заключается в проверке неравенства (4.3). В ячейке В23 находится значение коэффициента корреляции, объем выборки  . Для вычисления t- статистики
. Для вычисления t- статистики  для коэффициента корреляции выделим, например, ячейку К41и в строке формул введем =В23*(12-2)^0,5/(1-В23^2)^0,5.По «Enter» в ячейке К41 получим значение t-статистики равное 34,147. Для нахождения критической точки
для коэффициента корреляции выделим, например, ячейку К41и в строке формул введем =В23*(12-2)^0,5/(1-В23^2)^0,5.По «Enter» в ячейке К41 получим значение t-статистики равное 34,147. Для нахождения критической точки  распределения Стьюдента при заданном уровне значимости выделим, например, ячейку К44. В вкладке «Формулы» выберем «Другие функции», в группе «Статистические» выберем функцию «СТЬЮДЕНТ.ОБР.2Х». В окне этой функции в поле «Вероятность» введем значение
распределения Стьюдента при заданном уровне значимости выделим, например, ячейку К44. В вкладке «Формулы» выберем «Другие функции», в группе «Статистические» выберем функцию «СТЬЮДЕНТ.ОБР.2Х». В окне этой функции в поле «Вероятность» введем значение 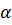 , равное 0,05, в поле «Степени свободы» зададим число степеней свободы n-2, равное 10. По «ОК» в ячейке К44получим значение , в рассматриваемом примере оно равно 2,228 (см. рис. 4.4). Модуль t-статистики для коэффициента корреляции превышает критическое значение 2,228. Следовательно, коэффициент корреляции значимо отличается от нуля и построенное уравнение регрессии значимо.
, равное 0,05, в поле «Степени свободы» зададим число степеней свободы n-2, равное 10. По «ОК» в ячейке К44получим значение , в рассматриваемом примере оно равно 2,228 (см. рис. 4.4). Модуль t-статистики для коэффициента корреляции превышает критическое значение 2,228. Следовательно, коэффициент корреляции значимо отличается от нуля и построенное уравнение регрессии значимо.
Построение 95%-о доверительного интервала для дисперсии  ошибки регрессии.Доверительный интервал надежности
ошибки регрессии.Доверительный интервал надежности 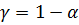 дисперсии определяется неравенством (4.2). В примере величина находится в ячейке В26, объем выборки равен 12, . Функция ХИ2.ОБР находит односторонние критические точки распределения
дисперсии определяется неравенством (4.2). В примере величина находится в ячейке В26, объем выборки равен 12, . Функция ХИ2.ОБР находит односторонние критические точки распределения  при заданном уровне значимости и числе степеней свободы. Для нахождения
при заданном уровне значимости и числе степеней свободы. Для нахождения  выделим ячейку К47и в строке формул введем =B26^2*(12-2)/ХИ2.ОБР(0,975;10).По «Enter» в этой ячейке получим 0,845. Для нахождения
выделим ячейку К47и в строке формул введем =B26^2*(12-2)/ХИ2.ОБР(0,975;10).По «Enter» в этой ячейке получим 0,845. Для нахождения  выделим ячейку L47и в строке формул введем =B26^2*(12-2)/ХИ2.ОБР(0,025;10). По «Enter» в этой ячейке получим 5,33 (см. рис.4.4). Следовательно, 95%-й доверительный интервал для имеет вид
выделим ячейку L47и в строке формул введем =B26^2*(12-2)/ХИ2.ОБР(0,025;10). По «Enter» в этой ячейке получим 5,33 (см. рис.4.4). Следовательно, 95%-й доверительный интервал для имеет вид  .
.
Построение интервальных прогнозов, надежности  , среднего зависимой переменной для выборочных значений независимой переменной и построение линии регрессии и 95%-х доверительных кривых. Доверительный интервал для среднего зависимой переменнойy, при заданном значении x объясняющей переменной, определяется неравенством (4.4). Для построения интервальных прогнозов условного среднего Yдля выборочных значений создадим, например, в ячейках А60-D72 дополнительную таблицу. В ячейки А61:А72скопируем наблюдаемые значения , в ячейки В61:В72скопируем прогнозные значения
, среднего зависимой переменной для выборочных значений независимой переменной и построение линии регрессии и 95%-х доверительных кривых. Доверительный интервал для среднего зависимой переменнойy, при заданном значении x объясняющей переменной, определяется неравенством (4.4). Для построения интервальных прогнозов условного среднего Yдля выборочных значений создадим, например, в ячейках А60-D72 дополнительную таблицу. В ячейки А61:А72скопируем наблюдаемые значения , в ячейки В61:В72скопируем прогнозные значения  . Эти значения должны быть упорядочены по возрастанию .В столбцах С и D будем размещать нижние и верхние границы доверительных интервалов. Вычислим выборочную среднюю
. Эти значения должны быть упорядочены по возрастанию .В столбцах С и D будем размещать нижние и верхние границы доверительных интервалов. Вычислим выборочную среднюю 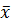 . Для этого выделим ячейку A75и в строке формул введем =СРЗНАЧ(А61:А72),по «Enter» получим в этой ячейке значение , равное 602,77. Вычислим выборочную дисперсию
. Для этого выделим ячейку A75и в строке формул введем =СРЗНАЧ(А61:А72),по «Enter» получим в этой ячейке значение , равное 602,77. Вычислим выборочную дисперсию  . Для этого выделим ячейку B75и в строке формул введем =ДИСП.В(А61:А72),по «Enter» получим в этой ячейке значение , равное 9204,31 (см. рис. 4.5). Для вычисления нижней границы
. Для этого выделим ячейку B75и в строке формул введем =ДИСП.В(А61:А72),по «Enter» получим в этой ячейке значение , равное 9204,31 (см. рис. 4.5). Для вычисления нижней границы  при
при  выделим ячейку С61 и (учитывая n=12, n-2=10 и расположение s в ячейке В26) в строке формул введем
выделим ячейку С61 и (учитывая n=12, n-2=10 и расположение s в ячейке В26) в строке формул введем
=B61-СТЬЮДЕНТ.ОБР.2Х(0,05;10)*В26*(1/12+(A61-А75)^2/(12*В75))^0,5.
По «Enter»в ячейке С61 получим искомое значение нижней границы при . Для вычисления верхней границы  для выделим ячейку D61 и в строке формул введем
для выделим ячейку D61 и в строке формул введем
=B61+СТЬЮДЕНТ.ОБР.2Х(0,05;10)*В26*(1/12+(A61-А75)^2/(12*В75))^0,5.
По Enterв ячейке D61 получим искомое значение верхней границы для . Вычисление нижних и верхних границ доверительного интервала среднего зависимой переменной для других значений производится аналогичным образом, нужно заменить в приведенных формулах ячейки В61 и А61 на имена ячеек содержащих соответствующие значения и . Границы 95%-х доверительных интервалов прогнозов среднего приведены на рис. 4.5.
Используя полученные результаты, построим верхнюю и нижнюю доверительные кривые, а также линию регрессии. Для этого выделим, например, ячейку F62; в вкладке «Вставка» в группе «Диаграммы» выберем «Точечная» и среди типов диаграмм выберем «Точечная с гладкими кривыми». В открывшейся вкладке «Конструктор» в группе «Макеты диаграмм» выберем «Макет1», после чего в группе «Данные» щелкнем по «Выбрать данные». В открывшемся окне «Выбор источника данных» в поле «Диапазон данных» укажем положение данных, для рассматриваемого примера укажем A60:D72. По ОК получим нужные графики, после чего скорректируем заголовок диаграммы и наименования осей координат. 95%-е доверительные кривые и линия регрессии приведены на рис. 4.5.

Рис. 4.5. Доверительные кривые и линия регрессии
Общее заключение о оцененной модели и ее интерпретация.
Построенная модель достаточно хорошо согласуется с имеющейся выборкой. Об этом свидетельствует высокое значение коэффициента детерминации  , т.е. 99,15% вариации совокупных расходов на жилье Y относительно среднего объясняется изменением располагаемого совокупного личногодохода X. Большое значение
, т.е. 99,15% вариации совокупных расходов на жилье Y относительно среднего объясняется изменением располагаемого совокупного личногодохода X. Большое значение  -статистики, , и ее уровень значимости, равный , свидетельствует о наличии значимой линейной корреляционной зависимости совокупных расходов на жильеY от располагаемого совокупного личногодоходаX. Об этом также говорит значение коэффициента корреляции и егоt-статистика,
-статистики, , и ее уровень значимости, равный , свидетельствует о наличии значимой линейной корреляционной зависимости совокупных расходов на жильеY от располагаемого совокупного личногодоходаX. Об этом также говорит значение коэффициента корреляции и егоt-статистика,  , значительно превышающая критическое значение при заданном уровне значимости . Оценка среднеквадратического отклонения
, значительно превышающая критическое значение при заданном уровне значимости . Оценка среднеквадратического отклонения  ошибок регрессии мала по сравнению с
ошибок регрессии мала по сравнению с  , что свидетельствует о малом разбросе выборочных данных относительно линии регрессии.
, что свидетельствует о малом разбросе выборочных данных относительно линии регрессии.
Оценка регрессионной зависимости проводилась для значений объясняющей переменной X из промежутка от 479 до 752, поэтому построенная модель может быть использована для прогнозов среднего объясняемой переменной на этом промежутке и для значений x близких к этому промежутку.
Интерпретация модели. Согласно модели, затраты на жилье увеличиваются линейно с ростом располагаемых доходов. Отрицательность свободного члена и значительное смещение вправо от нуля промежутка наблюдаемых значений  исключают возможность содержательной его интерпретации. Интерпретация коэффициента регрессии
исключают возможность содержательной его интерпретации. Интерпретация коэффициента регрессии  : в рамках построенной модели увеличение располагаемого совокупного личного дохода на 1 млрд. долл. влечет увеличение совокупных расходов на жилье в среднем на 0,141 млрд. долл. в ценах 1972г., т.е. предельный спрос на жилье по располагаемому доходу, согласно модели, равен 0,141.
: в рамках построенной модели увеличение располагаемого совокупного личного дохода на 1 млрд. долл. влечет увеличение совокупных расходов на жилье в среднем на 0,141 млрд. долл. в ценах 1972г., т.е. предельный спрос на жилье по располагаемому доходу, согласно модели, равен 0,141.
Контрольные вопросы.
1. Какая зависимость называется корреляционной?
2. Что описывает уравнение регрессии?
3. Запишите модель парной линейной регрессии и объясните ее компоненты.
4. Каковы источники ошибки регрессии?
5. В чем сущность метода наименьших квадратов оценивания параметров линейного уравнения регрессии?
6. Каковы предпосылки парной линейной регрессии?
7. Приведите оценки метода наименьших квадратов для параметров уравнения парной линейной регрессии.
8. Сформулируйте свойства несмещенности, состоятельности и эффективности оценок параметров.
9. Сформулируйте теорему Гаусса-Маркова.
10. В чем различие ошибок и остатков регрессии?
11. Как оценивается значимость параметров уравнения регрессии?
12. Как оценивается значимость уравнения регрессии?
13. Как связан коэффициент регрессии с коэффициентом корреляции?
14. Что характеризует коэффициент детерминации?
15. Сформулируйте нулевые гипотезы о значимости параметров уравнения регрессии. Как осуществляется проверка этих гипотез?
16. Сформулируйте понятие доверительного интервала и его надежности.
17. Как определяются доверительные интервалы для параметров уравнения парной линейной регрессии?
18. Что влияет на величину доверительного интервала прогноза среднего зависимой величины?
19. Что представляют доверительные кривые? Как они изменяются с увеличением надежности?
Дата добавления: 2018-04-15; просмотров: 703; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!