Тема 2.5. Корреляционно-регрессионный анализ
Как показано в подразделе 1.5.4 настоящего пособия, две случайные величины Х и Y могут быть связаны функциональной зависимостью, когда связь между ними может быть представлена в виде формулы  , либо зависимостью другого рода, называемой стохастической, либо могут быть независимыми.
, либо зависимостью другого рода, называемой стохастической, либо могут быть независимыми.
Строгая функциональная зависимость на практике реализуется сравнительно редко, поскольку либо обе рассматриваемые величины, или какая-то одна из них, подвержены воздействию многочисленных случайных факторов, среди которых могут быть и общие для обеих величин. В этом случае возникает стохастическая зависимость, которую в некоторых руководствах называют вероятностной, или статистической.
Стохастической называется зависимость двух случайных величин, при которой изменение одной из величин влечет изменение распределения другой величины.
Корреляционной называется стохастическая зависимость двух случайных величин, при которой изменение одной из величин влечет изменение среднего значения (математического ожидания) другой величины.
ПРИМЕР: Если величина Y – урожай сельскохозяйственной культуры, а величина Х – количество внесенных в почву удобрений, то с одинаковых по площади участков земли при равных количествах внесенных удобрений в общем случае снимают различный урожай, т.е. величина Y не является функцией аргумента Х. Это объясняется воздействием случайных факторов: осадки, качество почвы и т.д.. Однако, как показывают опыты, средний урожай (по всем участкам) зависит от количества внесенных удобрений, т.е. рассматриваемые величины связаны корреляционной зависимостью.
Поскольку условное математическое ожидание величины Y при постоянном значении величины Х, т.е.  является функцией от
является функцией от  , то его оценка – условное среднее
, то его оценка – условное среднее  также является функцией от . Если обозначить эту функцию через
также является функцией от . Если обозначить эту функцию через  , то получим уравнение
, то получим уравнение  , которое называется выборочным уравнением регрессии Y на Х.
, которое называется выборочным уравнением регрессии Y на Х.
Заметим, что из аналогичных рассуждений можно определить и выборочное уравнение регрессии Х на Y.
Основной задачей корреляционно-регрессионного анализа является выявление наличия и характера связи между переменными Х и Y, определение параметров функции регрессии, а также количественная оценка тесноты этой связи.
Формы представления исходных для анализа данных
Простейшим случаем представления исходных данных являются не сгруппированные данные, т.е. набор пар чисел  , где
, где 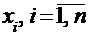 есть выборка значений величины Х, а
есть выборка значений величины Х, а  есть выборка значений величины Y.
есть выборка значений величины Y.
Однако при сравнительно большом числе наблюдений одна и та же пара значений может встречаться несколько раз. Поэтому в таких случаях данные наблюдений группируют и представляют в виде корреляционной таблицы. Поясним структуру такого представления исходных данных на конкретном примере.
Для исследования зависимости годового объема производства Y от основных фондов Х получены статистические данные по 20 предприятиям, представленные в корреляционной таблице 2.1.
Таблица 2.1.
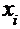

| 12,5 | 17,5 | 22,5 | 27,5 | 
|
| 20,5 | 1 | - | - | - | 1 |
| 21,5 | - | 2 | - | - | 2 |
| 22,5 | - | 1 | 2 | - | 3 |
| 23,5 | - | - | 3 | 3 | 6 |
| 24,5 | - | - | - | 8 | 8 |
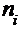
| 1 | 3 | 5 | 11 | n = 20 |
В первой строке таблицы записаны значения переменной Х, а в первом столбце – значения переменной Y. Центральную (выделенную) часть таблицы занимают частоты  (числа предприятий), соответствующие значениям переменных
(числа предприятий), соответствующие значениям переменных  и
и  . В последней строке таблицы записаны частоты
. В последней строке таблицы записаны частоты  , а в последнем столбце – частоты
, а в последнем столбце – частоты  . Здесь число значений величины Х:
. Здесь число значений величины Х:  , а число значений величины Y:
, а число значений величины Y:  . При этом общее число всех значений
. При этом общее число всех значений  .
.
Дата добавления: 2018-06-01; просмотров: 288; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!