Метод последовательного равномерного поиска.
Итерационный метод, где на каждой итерации применяется метод равномерного поиска, причем интервал неопределенности уменьшается с каждой итерацией.
 |
Рис. 2.6
Количество отрезков m, на которое делится интервал неопределенности L задается (на рис. 2.6 m=8). После каждой итерации интервал неопределенности уменьшается в пропорции  (на рис. 2.6 в четыре раза). За n итераций имеем
(на рис. 2.6 в четыре раза). За n итераций имеем  , причем для обеспечения требуемой точности расчетов должно быть
, причем для обеспечения требуемой точности расчетов должно быть  , откуда получаем
, откуда получаем  (2.9).
(2.9).
Выражение (2.9) определяет число итераций, требуемое для решения задачи с заданной погрешностью  . Общее количество расчетов целевой функции при этом Nпр = (m+1) n.
. Общее количество расчетов целевой функции при этом Nпр = (m+1) n.
Пусть m=10, d=0,001. Логарифмируя (2.9), получим  откуда
откуда  - число итераций расчета.
- число итераций расчета.
 <<
<<  , т.е. объем вычислений по сравнению с методом равномерного поиска уменьшается почти в 20 раз.
, т.е. объем вычислений по сравнению с методом равномерного поиска уменьшается почти в 20 раз.
Метод дихотомии
(Метод деления интервала неопределенности пополам)
Идея метода заключается в том, чтобы делить интервал неопределенности  пополам и по результатам каждой итерации отбрасывать ту половину, где максимума быть не может.
пополам и по результатам каждой итерации отбрасывать ту половину, где максимума быть не может.
Для этого достаточно вычислить значения f0(x) в точках  и
и  , где
, где  ,
,  ,
,  - допустимая погрешность определения максимума. И сравнить их между собой.
- допустимая погрешность определения максимума. И сравнить их между собой.
Проиллюстрируем порядок расчета с помощью рис. 2.7


Рис. 2.7
Для функции, показанной на рис. 2.7, на первой итерации расчета
 >
>  , поэтому отбрасываем правую часть интервала неопределенности, делаем переприсвоение X* =
, поэтому отбрасываем правую часть интервала неопределенности, делаем переприсвоение X* =  ,
,
|
|
|
Рассчитываем новые значения  ,
, 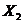 , затем значения
, затем значения  , и сравниваем их между собой. На второй итерации расчета
, и сравниваем их между собой. На второй итерации расчета 
(рис. 2.7), поэтому отбрасываем левую часть интервала неопределенности и делаем переприсвоение Х* =  и т. д.
и т. д.
Вычисления заканчиваются, когда интервал неопределенности становится меньше допустимой погрешности e, и за решение принимается наибольшее из двух последних вычисленных значений или .
Определим количество вычислений целевой функции, необходимое для нахождения точки максимума  методом дихотомии с заданной точностью.
методом дихотомии с заданной точностью.
На каждой итерации интервал неопределенности уменьшиться в два раза, т.е. 
За n итераций имеем 
Для обеспечения требуемой точности расчета должно быть
 , откуда
, откуда  .
.
Логарифмируя, получаем выражение, определяющее число итераций расчета, требуемое для решения задачи с заданной погрешностью .
 ;
;
Общее количество расчетов целевой функции при этом ND=2n.
При  получаем
получаем  , откуда n=10 и
, откуда n=10 и  .
.
Метод золотого сечения
Интервал неопределенности делится на три отрезка, причем внутренние точки располагаются симметрично по отношению к крайним (рис. 2.8), таким образом, чтобы выполнялось соотношение  (2.10)
(2.10)
|
|
|
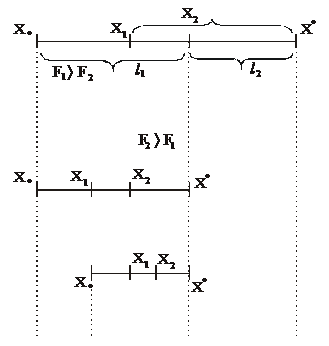
| |
Величина  определяется следующим образом. Из (2.10), с учетом того, что
определяется следующим образом. Из (2.10), с учетом того, что  , получаем
, получаем 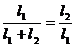 , откуда
, откуда  (2.11)
(2.11)
Разделив обе части выражения (2.11) на 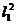 , получим
, получим
 (2.12)
(2.12)
С учетом (2.10) из (2.12) имеем  , откуда
, откуда
 - золотое сечение.
- золотое сечение.
|
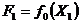 и
и  . Если
. Если  >
>  , то интервал неопределенности сокращается путем отбрасывания правого отрезка, а если
, то интервал неопределенности сокращается путем отбрасывания правого отрезка, а если  < , то левого (см. рис. 2.8). Расчет повторяется до тех пор, пока после очередного этапа
< , то левого (см. рис. 2.8). Расчет повторяется до тех пор, пока после очередного этапа  , и за решение принимается наибольшее из двух последних вычисленных значений F1 или F2.
, и за решение принимается наибольшее из двух последних вычисленных значений F1 или F2.
Т.к. 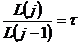 , то
, то  , где n - число итераций расчета.
, где n - число итераций расчета.
В случае задания допустимой погрешности как , имеем
 (2.13) .
(2.13) .
После сокращения левой части (2.13) на L(0) и логарифмирования, получаем  , Nзс=n+1 – общее число вычислений целевой функции.
, Nзс=n+1 – общее число вычислений целевой функции.
При  ,
,  ,
, 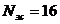 .
.
Сравнивая требуемое количество расчетов целевой функции для решения задачи одномерной оптимизации разными методами с одной и той же допустимой погрешностью , получаем
|
|
|
 .
.
Заметим, что метод золотого сечения более эффективен, с точки зрения требуемого объема вычислений, по сравнению с методом дихотомии, в котором на каждой итерации необходимо два раза вычислять целевую функцию, а в методе золотого сечения на всех итерациях кроме первой целевая функция вычисляется только один раз, а второе сравниваемое значение целевой функции берется из предыдущей итерации.
Так, из рис. 2.8. имеем, f0 (X1) на первой итерации равно f0 (X2) на второй итерации равно f0 (X1) на третьей итерации и т.д.
Таким образом, можно сделать вывод, что развитие методов одномерного поиска было направлено исключительно на уменьшениеобъема вычислений, необходимых для решения оптимизационных задач.
Дата добавления: 2018-02-15; просмотров: 776; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!