Лекция 10.Методы повышения верности передачи дискретной информации
Содержание лекции:
- избыточность сигналов дискретной информации. Принципы помехоустойчивого кодирования. Кодовое расстояние. Число обнаруживаемых и исправляемых ошибок.
Цель лекции:
- рассмотреть методы повышения верности передачи и надежности систем ПДИ.
Понятие «избыточность» определяется средним количеством информации, содержащемся в передаваемом сообщении. При двоичном кодировании в условиях равновероятности передаваемых двоичных символов «О» и «1» каждый единичный элемент содержит максимальное количество информации:  бит, где R = 2 — основание кода. Если же единичные элементы поступают в канал с разными вероятностями, то один единичный элемент переносит меньшее количество информации. В этом случае говорят, что в сигнале есть избыточность. Ее можно оценить как отношение
бит, где R = 2 — основание кода. Если же единичные элементы поступают в канал с разными вероятностями, то один единичный элемент переносит меньшее количество информации. В этом случае говорят, что в сигнале есть избыточность. Ее можно оценить как отношение 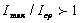 . Поскольку пропускная способность определяется в виде (9.14), то систему передачи надо строить так, чтобы
. Поскольку пропускная способность определяется в виде (9.14), то систему передачи надо строить так, чтобы  было максимальным, т. е. требовать, чтобы среднее количество информации было равно I тах (1 бит для двоичного кода).
было максимальным, т. е. требовать, чтобы среднее количество информации было равно I тах (1 бит для двоичного кода).
При отсутствии избыточности, когда любая комбинация двоичных символов представляет собой передаваемое сообщение, обнаружить ошибки в принятой кодовой комбинации невозможно. Чтобы обнаружить ошибку и даже определить место ошибочно принятого единичного элемента, необходимо увеличить объем сигнала, представляющего кодовую комбинацию. Увеличить избыточность передаваемого сигнала можно по-разному. Так как объем сигнала расчитывается по (1.2), то его увеличение возможно за счет увеличения Dк(Рк),  и Т.Практические возможности увеличения избыточности за счет мощности и ширины спектра сигнала в системах передачи дискретной информации по стандартным каналам резко ограничены. Поэтому основное развитие получили методы повышения верности приёма, основанные на увеличении времени передачи. Эти методы реализуются системами без обратной связи и системами с обратной связью. В системах без обратной связи (однонаправленных системах) для повышенияверности приема используются следующие основные способы:
и Т.Практические возможности увеличения избыточности за счет мощности и ширины спектра сигнала в системах передачи дискретной информации по стандартным каналам резко ограничены. Поэтому основное развитие получили методы повышения верности приёма, основанные на увеличении времени передачи. Эти методы реализуются системами без обратной связи и системами с обратной связью. В системах без обратной связи (однонаправленных системах) для повышенияверности приема используются следующие основные способы:
1) помехоустойчивое кодирование, т. е. использование кодов, исправляющих ошибки;
2) многократная передача кодовых комбинаций;
3) одновременная передача кодовой комбинации по нескольким параллельно работающим каналам.
Наиболее эффективно избыточность используется при применении помехоустойчивых кодов для исправления ошибок. При этом в кодовые комбинации вводится постоянная, заранее рассчитанная избыточность (дополнительные элементы, сформированные по известным правилам). Повысить верность передачи без существенного снижения пропускной способности можно, вводя переменную избыточность в сообщение в зависимости от состояния канала. Такие системы являются адаптивными, т. е. приспосабливающимися к условиям канала. Для их построения нужно уметь оценивать на приеме статистику ошибок в канале и передавать эти данные на передающую станцию. Таким образом, необходимо иметь дополнительный обратный канал от приемника к передающей станции, и поэтому вся система связи оказывается системой с обратной связью.
В обычном равномерном непомехоустойчивом коде число разрядов в кодовых комбинациях определяется числом сообщений и основанием кода n= log2K. Любая из n кодовых комбинаций представляет собой какой-то знак алфавита. Если в процессе передачи такой кодовой комбинации произойдет одна ошибка, то принятая кодовая комбинация будет интерпретироваться приемником как кодовая комбинация, соответствующая другому знаку. Таким образом, возникающие в кодовых комбинациях ошибки обнаружить невозможно, поскольку нельзя отличить ошибочную комбинацию от безошибочной. Все n кодовые комбинации разрешены, и возникающие ошибки просто переводят одну разрешенную комбинацию в другую, также разрешенную. Обнаружить ошибку в данном случае может только получатель, прочтя принятое текстовое сообщение. За счет огромной языковой и смысловой избыточности текста можно легко восстановить переданное сообщение. Коды, у которых все кодовые комбинации разрешены к передаче, называются простыми или равнодоступными. Очевидно, что при передаче цифровой информации восстановление ошибочно принятых цифр невозможно. Цифровая информация избыточностью не обладает. Ясно, что текстовое сообщение, принятое с ошибками, верно восстанавливается только за счет содержащейся в нем избыточности. В этом состоит идея помехоустойчивого кодирования: в передаваемую кодовую комбинацию необходимо внести по определенным «грамматическим» правилам избыточность (признаки разрешенной комбинации). Правила внесения избыточности, т. е. признаки, должны быть известны не только на передаче, но и на приеме. Если на приемной стороне эти признаки в кодовой комбинации не обнаруживаются, то считается, что произошла ошибка (или ошибки). В противном случае (при наличии признаков) считается, что кодовая комбинация принята правильно (является разрешенной). Внесение избыточности при использовании корректирующих (помехоустойчивых) кодов обязательно связано с увеличением п — числа разрядов (длины) кодовой комбинации. Таким образом, все множество  комбинаций можно разбить на дваподмножества: подмножество разрешенных комбинаций, т. е. обладающих определенными признаками, и подмножество запрещенных комбинаций, этими признаками не обладающих. Помехоустойчивый код отличается от обычного тем, что в канал передаются не все кодовые комбинации N 0 ,которые можно сформировать из имеющегося числа разрядов п— N 0, а только их часть N , которая составляет подмножество разрешенных комбинаций:
комбинаций можно разбить на дваподмножества: подмножество разрешенных комбинаций, т. е. обладающих определенными признаками, и подмножество запрещенных комбинаций, этими признаками не обладающих. Помехоустойчивый код отличается от обычного тем, что в канал передаются не все кодовые комбинации N 0 ,которые можно сформировать из имеющегося числа разрядов п— N 0, а только их часть N , которая составляет подмножество разрешенных комбинаций:
N<N0. (10.1)
Если в результате искаженийпереданная кодоваякомбинация переходит в подмножество запрещенных кодовых комбинаций, то ошибка будет обнаружена. Однако если совокупность ошибок в данной кодовой комбинации превращает ее в какую-либо другую разрешенную, то в этом случае ошибки не могут быть обнаружены. Поскольку любая из N разрешенных комбинаций может превратиться в любую из N 0возможных, то общее число таких случаев равно N * N 0.Очевидно, что число случаев, в которых ошибки обнаруживаются, равно N( N 0 — N ),где N 0 — N—число запрещенных комбинаций. Тогда доля обнаруживаемых ошибочных комбинаций составит

(10.2)(6.2)

 Аналогичное рассуждение можно провести и для случая исправления ошибок, если рассматривать код, исправляющий ошибки. При использовании этого кода нужно произвести разбиение множества
Аналогичное рассуждение можно провести и для случая исправления ошибок, если рассматривать код, исправляющий ошибки. При использовании этого кода нужно произвести разбиение множества  ( j =1,2,…, N 0 — N )всех запрещенных комбинаций на N непересекающихся подмножеств {Мк}. Каждое из подмножеств {Мк} приписывается одной из передаваемых кодовых комбинаций Ак. Способ приема состоит в том, что если принята комбинация
( j =1,2,…, N 0 — N )всех запрещенных комбинаций на N непересекающихся подмножеств {Мк}. Каждое из подмножеств {Мк} приписывается одной из передаваемых кодовых комбинаций Ак. Способ приема состоит в том, что если принята комбинация  *,то считается, что передана Ак, т. е. если принятая кодовая комбинация осталась в том же подмножестве, что и переданная, то принимается решение о приеме комбинации Ак. Сказанное можно проиллюстрировать рисунке 10.1, где приняты следующие обозначения: А1...Ап — множество разрешенных (передаваемых) комбинаций;
*,то считается, что передана Ак, т. е. если принятая кодовая комбинация осталась в том же подмножестве, что и переданная, то принимается решение о приеме комбинации Ак. Сказанное можно проиллюстрировать рисунке 10.1, где приняты следующие обозначения: А1...Ап — множество разрешенных (передаваемых) комбинаций;  — множество всех возможных запрещенных комбинаций, в которые в результате различных ошибок могут перейти комбинации {Ак}, М1, М2 ..., М N— подмножества, на которые разбиты запрещенные комбинации.
— множество всех возможных запрещенных комбинаций, в которые в результате различных ошибок могут перейти комбинации {Ак}, М1, М2 ..., М N— подмножества, на которые разбиты запрещенные комбинации.
Способ приема состоит в том, что если принимается кодовая комбинация (В1, В2 или В3, принадлежащая подмножеству M 1 ,то считается, что передавалась комбинация A1(показано на рисунке стрелками). Если действительно комбинация В1(или В2, В3) образовалась из А1, то ошибка исправлена. Если принятая кодовая комбинация переходит в другое подмножество М2, то декодер примет ошибочное решение о передаче комбинации А2. Очевидно, что каким бы образом не разбивалось множество на подмножества {Мк}, ошибка всегда исправляется в N 0 — N случаях.
Общее число переходов комбинаций АN в комбинации  равно N( N 0 — N ) , а это есть число всех обнаруживаемыхошибочных комбинаций.
равно N( N 0 — N ) , а это есть число всех обнаруживаемыхошибочных комбинаций.
Для того, чтобы можно было обнаруживать и исправлять ошибки, разрешенная комбинация должна как можно больше отличаться от неразрешенной. Если ошибки действуют независимым образом (как случайные независимые события), то вероятность преобразования одной кодовой комбинации в другую будет тем меньше, чем большим числом разрядов они различаются. Если интерпретировать кодовые комбинации как точки в пространстве, то отличие выражается в расстоянии между ними. Количество разрядов, которыми отличаются две кодовые комбинации, можно принять за расстояние между ними. Для определения этого расстояния нужно сложить две кодовые комбинации по модулю 2 и подсчитать число единиц в полученной сумме. Обозначим кодовое расстояние через d . У простого кода
dmin=d0=1. (10.3)
Рассмотрим, чему равно d 0помехоустойчивого кода. При d 0 >2код способен обнаруживать и исправлять ошибки. Приd 0 =1 такой возможности нет.
Нужное кодовое расстояние устанавливается введением определенного количества дополнительных разрядов в кодовую комбинацию. Обозначим число (кратность) обнаруживаемых ошибок через to , а число исправляемых ошибок — через t u . Ошибка не обнаруживается, если одна разрешенная комбинация переходит в другую разрешенную. Для обеспечения возможности обнаружения всех ошибок кратностью до t 0,кодовое расстояние определяется неравенством
d0  t0+1. (10.4)
t0+1. (10.4)

 Это соотношение иллюстрируется рисунком 10.2. Переход от одной точки к другой на рисунке 10.2 соответствует искажению одного разряда.
Это соотношение иллюстрируется рисунком 10.2. Переход от одной точки к другой на рисунке 10.2 соответствует искажению одного разряда.
Для обеспечения возможности исправления всех ошибок кратности до t ивключительно кодовое расстояние
d0 2tИ+1. (10.5)
Чтобы код обнаруживал ошибки кратностью to и исправлял ошибки кратностью t и,кодовое расстояние должно быть равно d0 t0+tИ+1. (10.6)
Очевидно, что количество дополнительных разрядов r связано с кодовым расстоянием do .Кодовое расстояние будет тем большим, чем больше избыточность кода и чем равномернее распределены расстояния между разрешенными кодовыми комбинациями. Формула для кода с d0=3
r log2(n+1). (10.7)
Дата добавления: 2018-09-20; просмотров: 594; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!