Методы искусственного интеллекта в мехатронике и робототехнике
1. Задачи, решаемые методами искусственного интеллекта.
Распознавание образов и классификация
В качестве образов могут выступать различные по своей природе объекты: символы текста, изображения, образцы звуков и т. д. При обучении сети предлагаются различные образцы образов с указанием того, к какому классу они относятся. Образец, как правило, представляется как вектор значений признаков. При этом совокупность всех признаков должна однозначно определять класс, к которому относится образец. В случае, если признаков недостаточно, сеть может соотнести один и тот же образец с несколькими классами, что неверно. По окончании обучения сети ей можно предъявлять неизвестные ранее образы и получать ответ о принадлежности к определённому классу.
Принятие решений и управление
Эта задача близка к задаче классификации. Классификации подлежат ситуации, характеристики которых поступают на вход нейронной сети. На выходе сети при этом должен появиться признак решения, которое она приняла. При этом в качестве входных сигналов используются различные критерии описания состояния управляемой системы.
Кластеризация
Под кластеризацией понимается разбиение множества входных сигналов на классы, при том, что ни количество, ни признаки классов заранее не известны. После обучения такая сеть способна определять, к какому классу относится входной сигнал. Сеть также может сигнализировать о том, что входной сигнал не относится ни к одному из выделенных классов — это является признаком новых, отсутствующих в обучающей выборке, данных. Таким образом, подобная сеть может выявлять новые, неизвестные ранее классы сигналов. Соответствие между классами, выделенными сетью, и классами, существующими в предметной области, устанавливается человеком. Кластеризацию осуществляют, например, нейронные сети Кохонена.
Нейронные сети в простом варианте Кохонена не могут быть огромными поэтому их делят на гиперслои (гиперколонки) и ядра (микроколонки). Если сравнивать с мозгом человека то идеальное количество параллельных слоёв не должно быть более 112. Эти слои в свою очередь составляют гиперслои (гиперколонку), в которой от 500 до 2000 микроколонок (ядер). При этом каждый слой делится на множество гиперколонок пронизывающих насквозь эти слои. Микроколонки кодируются цифрами и единицами с получением результата на выходе. Если требуется, то лишние слои и нейроны удаляются или добавляются. Идеально для подбора числа нейронов, и слоёв использовать суперкомпьютер. Такая система позволяет нейронным сетям быть пластичной.
Прогнозирование
Способности нейронной сети к прогнозированию напрямую следуют из ее способности к обобщению и выделению скрытых зависимостей между входными и выходными данными. После обучения сеть способна предсказать будущее значение некой последовательности на основе нескольких предыдущих значений и/или каких-то существующих в настоящий момент факторов. Следует отметить, что прогнозирование возможно только тогда, когда предыдущие изменения действительно в какой-то степени предопределяют будущие. Например, прогнозирование котировок акций на основе котировок за прошлую неделю может оказаться успешным (а может и не оказаться), тогда как прогнозирование результатов завтрашней лотереи на основе данных за последние 50 лет почти наверняка не даст никаких результатов.
Аппроксимация
Нейронные сети — могут аппроксимировать непрерывные функции. Доказана обобщённая аппроксимационная теорема: с помощью линейных операций и каскадного соединения можно из произвольного нелинейного элемента получить устройство, вычисляющее любую непрерывную функцию с некоторой наперёд заданной точностью. Это означает, что нелинейная характеристика нейрона может быть произвольной: от сигмоидальной до произвольного волнового пакета или вейвлета, синуса или многочлена. От выбора нелинейной функции может зависеть сложность конкретной сети, но с любой нелинейностью сеть остаётся универсальным аппроксиматором и при правильном выборе структуры может достаточно точно аппроксимировать функционирование любого непрерывного автомата.
Сжатие данных и Ассоциативная память
Способность нейросетей к выявлению взаимосвязей между различными параметрами дает возможность выразить данные большой размерности более компактно, если данные тесно взаимосвязаны друг с другом. Обратный процесс — восстановление исходного набора данных из части информации — называется (авто)ассоциативной памятью. Ассоциативная память позволяет также восстанавливать исходный сигнал/образ из зашумленных/поврежденных входных данных. Решение задачи гетероассоциативной памяти позволяет реализовать память, адресуемую по содержимому.
2.Экспертные системы. Прямая и обратная цепочка рассуждений.
1 Прямая цепочка рассуждений Задачи каждого типа решаются наиболее оптимальными для них методами. Экспертная система должна быть ориентирована на строго конкретную предметную область, иначе она будет бесполезна. Рассмотрим такую ситуацию: во время работы у компьютера перегревается процессор. Многие с этим сталкивались, особенно жарким летним днём при недостаточной мощности кулера и в помещении без хорошего кондиционирования. Сформулируем задачу в общем виде. Имеет место ситуация (перегрев процессора), требуется предсказать её последствия. Итак, прежде всего, зафиксируем возникновение определённого состояния (перегрев процессора), а затем применим относящиеся к нему правила: Правило 1: ЕСЛИ процессор перегрелся, ТО компьютер «зависнет». Правило 2: ЕСЛИ компьютер «зависнет», ТО это приведет к потере данных и непроизводительным затратам времени. Описанная последовательность рассуждений называется прямой цепочкой потому, что констатирующая часть правила (часть ТО) выполняется только в том случае, если удовлетворяется условная часть правила (часть ЕСЛИ). Отправной точкой рассуждений, таким образом, служит уже возникшая ситуация, а затем делаются выводы... 2 Обратная цепочка рассуждений Предположим, что компьютер не включается. Какова причина - нет тока в электросети или неисправен блок питания? Рассмотрим задачу в общем виде: по известному результату (компьютер не включается) нужно определить условия, которые к нему привели, т.е. по симптомам найти причины. Она отличается от ранее рассмотренной задачи с прямой цепочкой рассуждений тем, что там уже были известны условия (перегрев процессора), но последствия, к которым они приведут, известны не были. Задача заключалась в предсказании возможного результата. Здесь же результат известен, и нужно найти вызвавшие его причины. Для решения задачи опять понадобятся правила. Сформулируем подходящие для нашего примера правила. Правило 1: ЕСЛИ компьютер не включается И нет тока в электросети ИЛИ неисправен блок питания, ТО не подается ток на материнскую плату. Правило 2: ЕСЛИ на материнскую плату не подается ток, ТО компьютер не включиться. Каким образом можно найти условия, при которых компьютер не включается? С помощью обратной цепочки рассуждений. Известен результат (компьютер не включается), что влечет за собой цепочку рассуждений, которая приведет к вызвавшим его причинам. Причины возникают раньше следствий, поэтому в процессе обратной цепочки рассуждений просматривают логические выводы, устанавливают условия, которые к ним привели, и определяют, связаны ли эти условия с предыдущими логическими выводами. Обратная цепочка рассуждений всегда начинается со следствия (часть ТО правила)...
3.Экспертные системы. Вероятность и нечеткая логика.
Рассуждение, опирающееся исключительно на точные факты и точные выводы, исходящие из этих фактов, называются строгими соображениями. В случаях, когда для принятия решений необходимо использовать неопределенные факты, строгие рассуждения становятся непригодными. Поэтому, одной из сильнейших сторон любой экспертной системы считается ее способность формировать рассуждения в условиях неопределенности так же успешно, как это делают эксперты-люди. Такие рассуждения имеют характер нестрогих. Можно смело говорить о присутствии нечеткой логики.
Неопределенность, а в следствии и нечеткая логика может рассматриваться как недостаточность адекватной информации для принятия решения. Неопределенность становится проблемой, поскольку может препятствовать созданию наилучшего решения и даже стать причиной того, что будет найдено некачественное решение. Следует отметить, что качественное решение, найденное в реальном времени, часто считается более приемлемым, чем лучшее решение, для вычисления которого требуется большое количество времени. Например, задержка в предоставлении лечения с целью проведения дополнительных анализов может привести к тому, что пациент умрет не дождавшись помощи.
Причиной неопределенности является наличие в информации различных ошибок. Упрощенная классификация этих ошибок может быть представлена в их разделении на следующие типы:
- неоднозначность информации, возникновение которой связано с тем, что некоторая информация может интерпретироваться различными способами;
- неполнота информации, связанной с отсутствием некоторых данных;
- неадекватность информации, обусловленная применением данных, не соответствуют реальной ситуации (возможными причинами являются субъективные ошибки: ложь, дезинформация, неисправность оборудования);
- погрешности измерения, которые возникают из-за несоблюдения требований правильности и точности критериев количественного представления данных;
- случайные ошибки, проявлением которых являются случайные колебания данных относительно среднего их значения (причиной могут быть: ненадежность оборудовании, броуновское движение, тепловые эффекты и т.д.).
На сегодня разработана значительное количество теорий неопределенности, в которых делается попытка устранения некоторых или даже всех ошибок и обеспечения надежного логического вывода в условиях неопределенности. К наиболее употребляемых на практике относятся теории, основанные на классическом определении вероятности и на апостериорной вероятности.
Одним из старейших и важнейших инструментальных средств решения задач искусственного интеллекта является вероятность. Вероятность — это количественный способ учета неопределенности. Классическая вероятность берет начало из теории, которая была впервые предложена Паскалем и Ферма в 1654 году. С тех пор была проведена большая работа в области изучения вероятности и осуществлении многочисленные применения вероятности в науке, технике, бизнесе, экономике и других областях.
4.Самообучающиеся системы.
Самообучающаяся система – это интеллектуальная информационная система (далее ИИС), которая на основе примеров реальной практики автоматически формирует единицы знаний.
В основе самообучающихся систем лежат методы автоматической классификации примеров реальной практики, то есть обучения на примерах. Примеры реальных ситуаций накапливаются за некоторый период и составляют обучающую выборку. В результате обучения системы автоматически строятся обобщенные правила или функции, определяющие принадлежность ситуаций классам, которыми обученная система пользуется при интерпретации незнакомых ситуаций. Из обобщающих правил автоматически формируется база знаний, которая периодически корректируется по мере накопления информации об анализируемых ситуациях.
Различают следующие виды самообучающихся систем:
1) Индуктивные системы. Система с индуктивным выводом – это самообуч-ся ИИС, работающая на принципе индукции с помощью классификации примеров по значимым признакам.
Индуктивный вывод (от частного к общему) – вывод (обобщение) общих утверждений на основе множества частных утверждений. Обобщение примеров на основе этого принципа сводится к выбору классификационного признака из множества заданных; выявлению множества примеров по значению выбранного признака; определению принадлежности данных примеров одному из классов
Процесс классификации может быть представлен в виде дерева решений, в котором в промежуточных узлах находятся значения признаков последовательной классификации, а в конечных узлах – значения признака принадлежности определенному классу.
Например, фрагмент дерева решений:

 [спрос] высокий [цена высокая]
[спрос] высокий [цена высокая]

 низкий_[издержки] большие [цена высокая]
низкий_[издержки] большие [цена высокая]

 маленькие [цена низкая]
маленькие [цена низкая]
Анализ новой ситуации сводится к выбору ветви дерева, которая полностью определяет эту ситуацию. Поиск решения осуществляется в результате последовательной проверки признаков классификации. Каждая ветвь дерева соответствует одному правилу решения: Если Спрос=низкий и Издержки=маленькие То Цена=низкая.
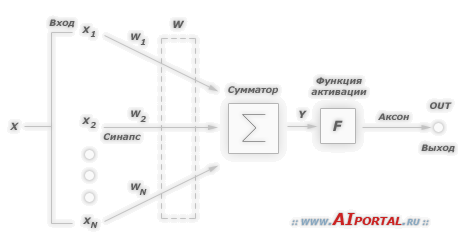
2) Нейронные сети – это самообучающиеся ИИС, которые на основе обучения по реальным примерам строят ассоциативную сеть понятий (нейронов) для параллельного поиска на ней решений. В результате обучения на примерах строятся математические решающие функции (передаточные функции или функции активации), которые определяют зависимости между входными (Xi) и выходными (Yj) признаками (сигналами).
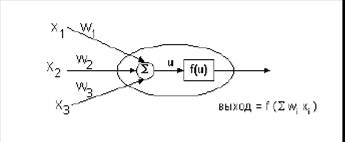 Рисунок 3 – Решающая функция – нейрон.
Рисунок 3 – Решающая функция – нейрон.
Здесь Xi – входные признаки; Wi – степень влияния входного признака на выходной; U – взвешенная сумма значений входных признаков; f(u) – решающая функция; Y – выходные признаки (сигналы).
Каждая такая функция, называемая по аналогии с элементарной единицей человеческого мозга – нейроном, отображает зависимость значения выходного признака (Y) от взвешенной суммы (U) значений входных признаков (Xi), в которой вес входного признака (Wi) показывает степень влияния входного признака на выходной: . 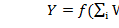
Решающие функции используются в задачах классификации на основе сопоставления их значений при различных комбинациях значений входных признаков с некоторым пороговым значением. В случае превышения заданного порога считается, что нейрон сработал и, таким образом, распознал некоторый класс ситуаций. Нейроны используются и в задачах прогнозирования, когда по значениям входных признаков после их подстановки в выражение решающей функции получается прогнозное значение выходного признака.
Нейроны могут быть связаны между собой, когда выход одного нейрона является входом другого. Таким образом, строится нейронная сеть, в которой нейроны, находящиеся на одном уровне, образуют слои.
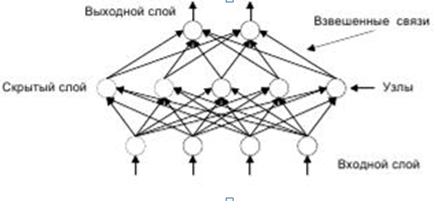 Рисунок 4 – Нейронная сеть.
Рисунок 4 – Нейронная сеть.
Обучение нейронной сети сводится к определению связей (синапсов) между нейронами и установлению силы этих связей (весовых коэффициентов). Алгоритмы обучения нейронной сети упрощенно сводятся к определению зависимости весового коэффициента связи двух нейронов от числа примеров, подтверждающих эту зависимость.
Наиболее распространенным алгоритмом обучения нейронной сети является алгоритм обратного распространения ошибки. Целевая функция по этому алгоритму должна обеспечить минимизацию квадрата ошибки в обучении по всем примерам:
f(u) = min å(Ti - Yi)2,
здесь Ti – заданное значение выходного признака по i-му примеру; Yi – вычисленное значение выходного признака по i-му примеру.
Достоинство нейронных сетей перед индуктивным выводом заключается в решении еще и прогнозирующих задач. Возможность нелинейного характера функциональной зависимости выходных и входных признаков позволяет строить более точные классификации. Сам процесс решения задач в силу проведения матричных преобразований проводится очень быстро. Фактически имитируется параллельный процесс прохода по нейронной сети в отличие от последовательного в индуктивных системах. Нейронные сети могут быть реализованы и аппаратно в виде нейрокомпьютеров с ассоциативной памятью.
Последнее время нейронные сети получили стремительное развитие и очень активно используются в финансовой области. В качестве примеров внедрения нейронных сетей можно назвать:
• Система прогнозирования динамики биржевых курсов для Chemical Bank (фирма Logica);
3) Системы, основанные на прецедентах (Case-based reasoning) – это самообучающиеся ИИС, которые в качестве единиц знаний хранят прецеденты решений (примеры) и позволяют по запросу подбирать и адаптировать наиболее похожие прецеденты. В этих системах база знаний содержит описания не обобщенных ситуаций, а собственно сами ситуации или прецеденты. Тогда поиск решения проблемы сводится к поиску по аналогии (абдуктивному выводу). Абдуктивный вывод (от частного к частному) – вывод частных утверждений на основе поиска других аналогичных утверждений (прецедентов). Он включает следующие этапы:
1. Получение подробной информации о текущей проблеме;
2. Сопоставление полученной информации со значениями признаков прецедентов из базы знаний;
3. Выбор прецедента из базы знаний, наиболее близкого к рассматриваемой проблеме;
4. В случае необходимости выполняется адаптация выбранного прецедента к текущей проблеме;
5. Проверка корректности каждого полученного решения;
6. Занесение детальной информации о полученном решении в базу знаний.
Также как и для индуктивных систем, прецеденты описываются множеством признаков, по которым строятся индексы быстрого поиска. Но в отличие от индуктивных систем допускается нечеткий поиск с получением множества допустимых альтернатив, каждая из которых оценивается некоторым коэффициентом уверенности. Далее наиболее подходящие решения адаптируются по специальным алгоритмам к реальным ситуациям. Обучение системы сводится к запоминанию каждой новой обработанной ситуации с принятыми решениями в базе прецедентов.
4) Информационные хранилища (Data Warehouse) – это самообучающиеся ИИС, которые позволяют извлекать знания из баз данных и создавать специально-организованные базы знаний. Информационные хранилища представляют собой хранилища значимой информации, регулярно извлекаемой из оперативных баз данных и предназначенной для оперативного анализа данных (реализации OLAP-технологии).
Типичными задачами оперативного ситуационного анализа являются:
• Определение профиля потребителей конкретного товара;
• Предсказание изменений ситуации на рынке;
• Анализ зависимостей признаков ситуаций (корреляционный анализ) и др.
Для извлечения значимой информации из баз данных используются специальные методы (Data Mining или Knowledge Discovery), основанные или на применении методов математической статистики, индуктивных методов построения деревьев решений или нейронных сетей. Формулирование запроса осуществляется в результате применения интеллектуального интерфейса, позволяющего в диалоге гибко определять значимые признаки анализа.
6.ИНС. Однослойные сети.
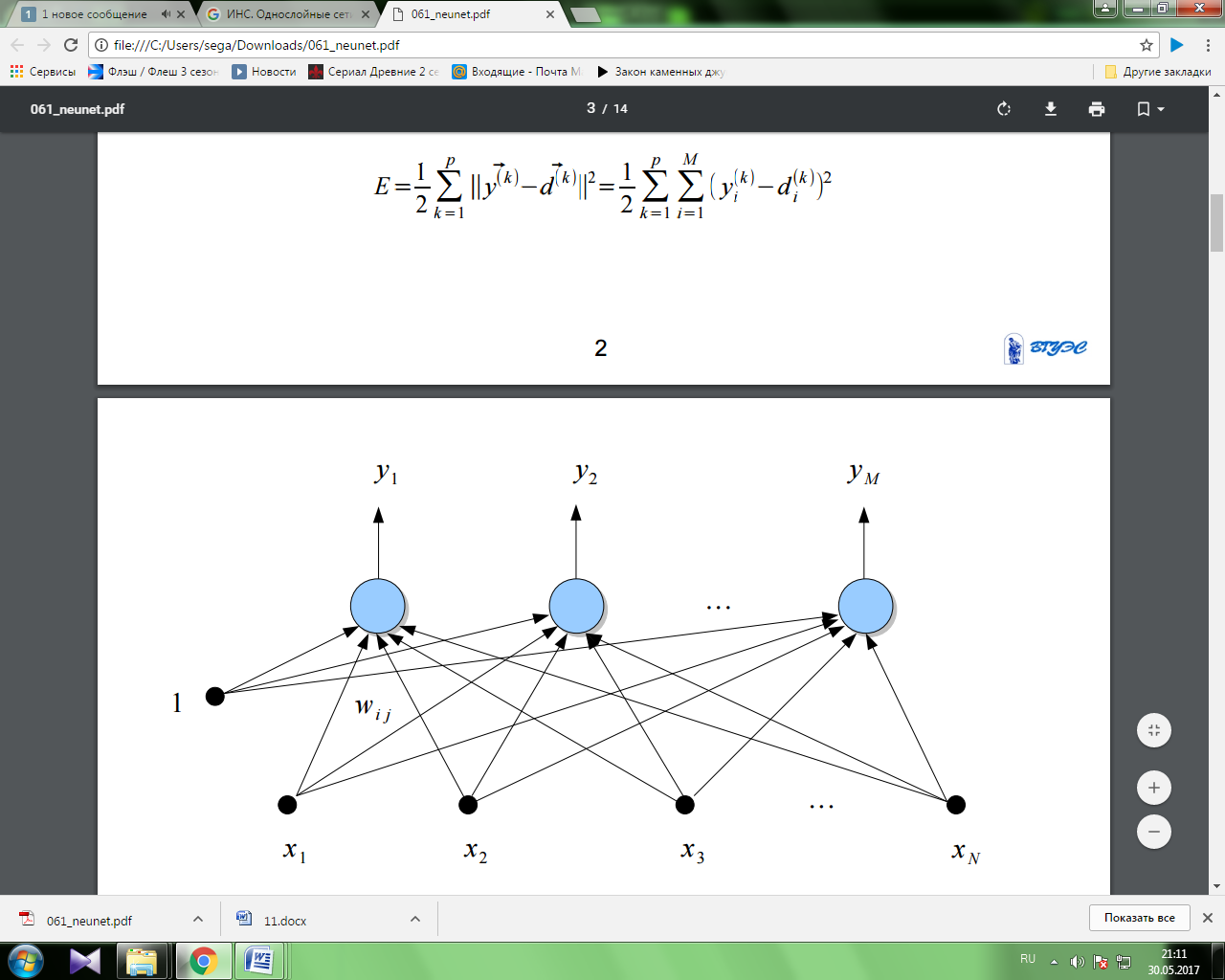
Однослойная сеть Однослойную сеть образуют нейроны, расположенные в одной плоскости. Каждый i-й нейрон имеет поляризацию (сязь с весом , по которой поступает единичный сигнал), а также множество связей с весами , по которым поступают входные сигналы . Значения весов подбираются в процессе обучения сети, заключающемся в приближении выходных сигналов к ожидаемым значениям . Мерой близости считается значение целевой функции . При использовании p обучающих векторов для обучения сети, включающей M выходных нейронов, целевая функция определяется евклидовой метрикой в виде:
Расположенные на одном уровне нейроны функционируют независимо друг от друга, поэтому возможности такой сети ограничиваются свойствами отдельных нейронов. Несмотря на то, что однослойная сеть имеет небольшое практическое применение, её продолжают использовать там, где для решения поставленной задачи задачи достаточно и одного слоя нейронов. Выбор архитектуры такой сети весьма прост. Количество входных нейронов (сенсоров) определяется размерностью входного вектора , а количество выходных нейронов определяется размерностью вектора . Обучение сети производится, как правило, с учителем и является точной копией обучения одиночного нейрона.
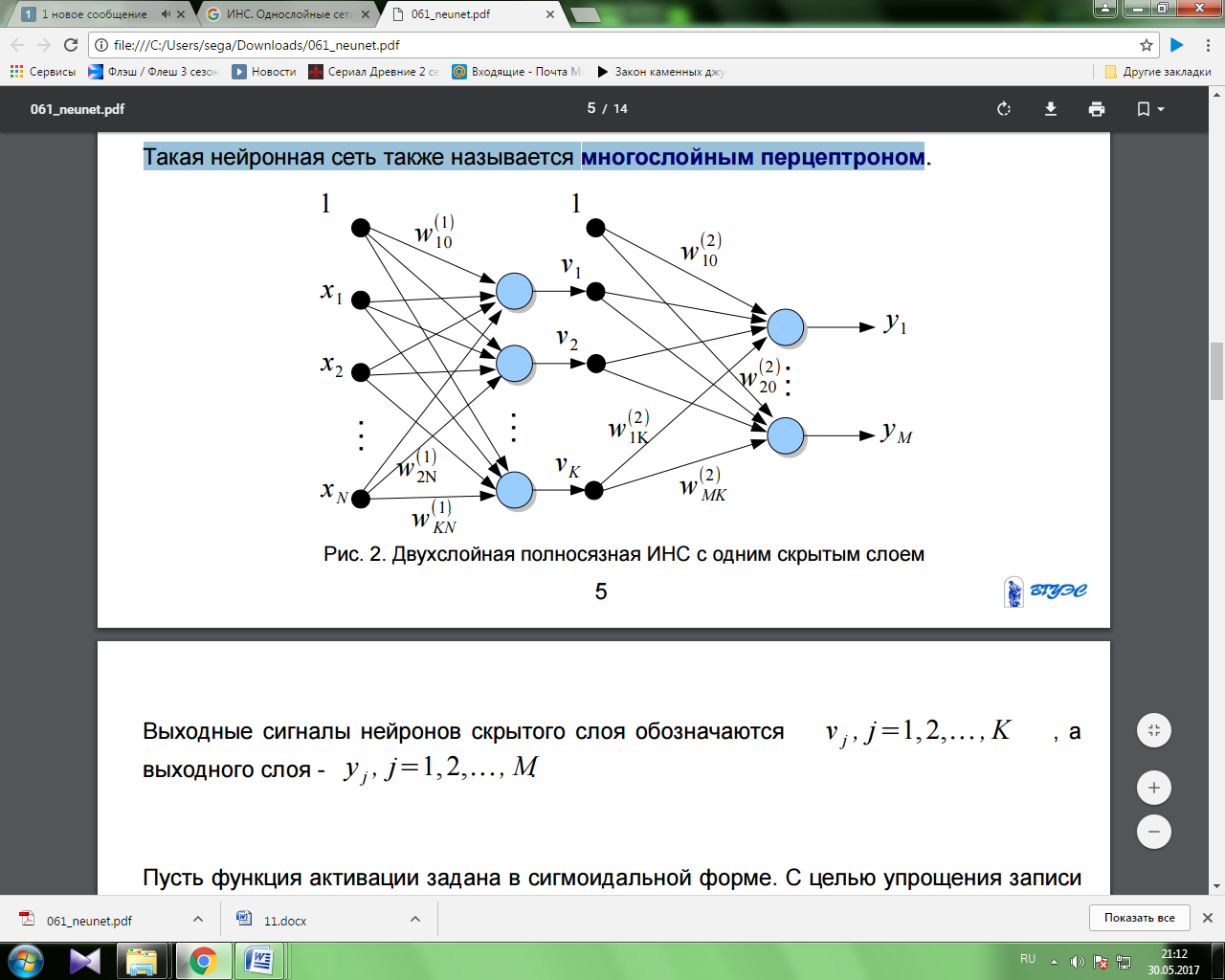
Многослойные сети.
Многослойная сеть состоит из нейронов, расположенных на разных уровнях, причём, помимо входного и выходного слоёв, имеется ещё, как минимум, один внутренний, т. е. скрытый, слой. Такая нейронная сеть также называется многослойным перцептроном.

Активационная функция.
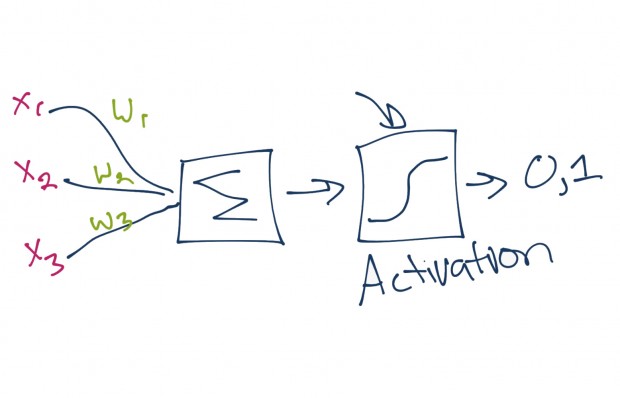
Для того, чтобы определиться с условными обозначениями, приведем ниже следующую модель нейрона:
Функция активации (активационная функция, функция возбуждения) – функция, вычисляющая выходной сигнал искусственного нейрона. В качестве аргумента принимает сигнал 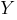 , получаемый на выходе входного сумматора
, получаемый на выходе входного сумматора  . Наиболее часто используются следующие функции активации.
. Наиболее часто используются следующие функции активации.
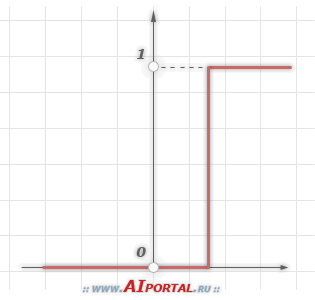
1. Единичный скачок или жесткая пороговая функция
Простая кусочно-линейная функция. Если входное значение меньше порогового, то значение функции активации равно минимальному допустимому, иначе – максимально допустимому.
2. Линейный порог или гистерезис
Несложная кусочно-линейная функция. Имеет два линейных участка, где функция активации тождественно равна минимально допустимому и максимально допустимому значению и есть участок, на котором функция строго монотонно возрастает.
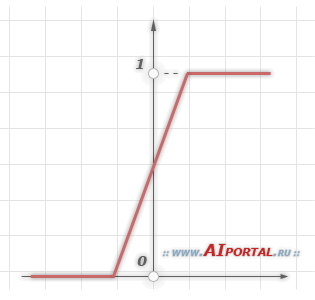
3. Сигмоидальная функция или сигмоид
Монотонно возрастающая всюду дифференцируемая 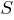 -образная нелинейная функция с насыщением. Сигмоид позволяет усиливать слабые сигналы и не насыщаться от сильных сигналов. Гроссберг (1973 год) обнаружил, что подобная нелинейная функция активации решает поставленную им дилемму шумового насыщения.
-образная нелинейная функция с насыщением. Сигмоид позволяет усиливать слабые сигналы и не насыщаться от сильных сигналов. Гроссберг (1973 год) обнаружил, что подобная нелинейная функция активации решает поставленную им дилемму шумового насыщения.
Слабые сигналы нуждаются в большом сетевом усилении, чтобы дать пригодный к использованию выходной сигнал. Однако усилительные каскады с большими коэффициентами усиления могут привести к насыщению выхода шумами усилителей, которые присутствуют в любой физически реализованной сети. Сильные входные сигналы в свою очередь также будут приводить к насыщению усилительных каскадов, исключая возможность полезного использования выхода.
Примером сигмоидальной функции активации может служить логистическая функция, задаваемая следующим выражением:
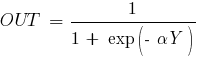
где 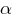 – параметр наклона сигмоидальной функции активации. Изменяя этот параметр, можно построить функции с различной крутизной.
– параметр наклона сигмоидальной функции активации. Изменяя этот параметр, можно построить функции с различной крутизной.
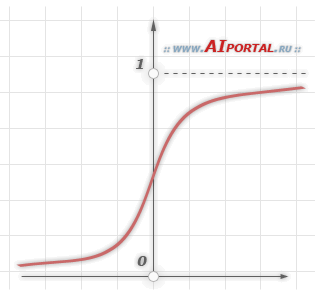
Еще одним примером сигмоидальной функции активации является гиперболический тангенс, задаваемая следующим выражением:

где – это также параметр, влияющий на наклон сигмоидальной функции.
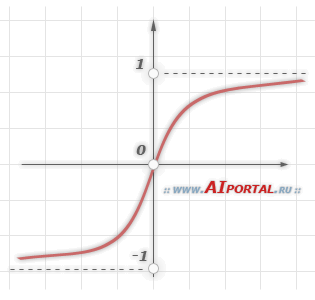
В заключение отметим, что функции активации типа единичного скачка и линейного порога встречаются очень редко и, как правило, используются на учебных примерах. В практических задач почти всегда применяется сигмоидальная функция активации.
7.ИНС. Сети обратного распространения.
Обучение алгоритмом обратного распространения ошибки предполагает два прохода по всем слоям сети: прямого и обратного.
При прямом проходе входной вектор подается на входной слой нейронной сети, после чего распространятся по сети от слоя к слою. В результате генерируется набор выходных сигналов, который и является фактической реакцией сети на данный входной образ. Во время прямого прохода все синаптические веса сети фиксированы.
Во время обратного прохода все синаптические веса настраиваются в соответствии с правилом коррекции ошибок, а именно: фактический выход сети вычитается из желаемого, в результате чего формируется сигнал ошибки. Этот сигнал впоследствии распространяется по сети в направлении, обратном направлению синаптических связей. Отсюда и название – алгоритм обратного распространения ошибки. Синаптические веса настраиваются с целью максимального приближения выходного сигнала сети к желаемому.
Алгоритм обучения по дельта-правилу:
1 шаг:инициализация матриц весов случайным образом (в циклах).
2 шаг:предъявление нейронной сети образа (на вход подаются значения из обучающей выборки – вектор Х) и берется соответствующий выход (вектор D).
3 шаг (прямой проход):вычисление в циклах выходов всех слоев и получение выходных значений нейронной сети (вектор Y).
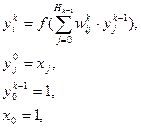
где 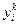 - выход i-нейрона k-слоя,
- выход i-нейрона k-слоя, 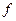 - функция активации,
- функция активации, 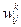 - синаптическая связь между j-нейроном слоя k-1 и i-нейроном слоя k,
- синаптическая связь между j-нейроном слоя k-1 и i-нейроном слоя k, 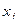 - входное значение.
- входное значение.
4 шаг (обратный проход):изменение весов в циклах по формулам:
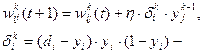
для последнего (выходного) слоя,
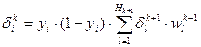 -
-
для промежуточных слоев, где t-номер текущей итерации цикла обучения (номер эпохи), 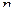 - коэффициент обучения задается от 0 до 1, - выход i-нейрона k-слоя,
- коэффициент обучения задается от 0 до 1, - выход i-нейрона k-слоя,
- синаптическая связь между j-нейроном слоя k-1 и i-нейроном слоя k,di– желаемое выходное значение на i-нейроне,yi- реальное значение на i-нейроне выходного слоя.
5 шаг:проверка условия продолжения обучения (вычисление значения ошибки и/или проверка заданного количества итераций). Если обучение не завершено, то 2 шаг, иначе заканчиваем обучение. Среднеквадратичная ошибка вычисляется следующим образом:
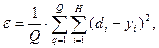
гдеQ– общее число примеров,H- количество нейронов в выходном слое,di– желаемое выходное значение на i-нейроне,yi- реальное значение на i-нейроне выходного слоя.
9.Распознавание образов с учителем и без учителя.
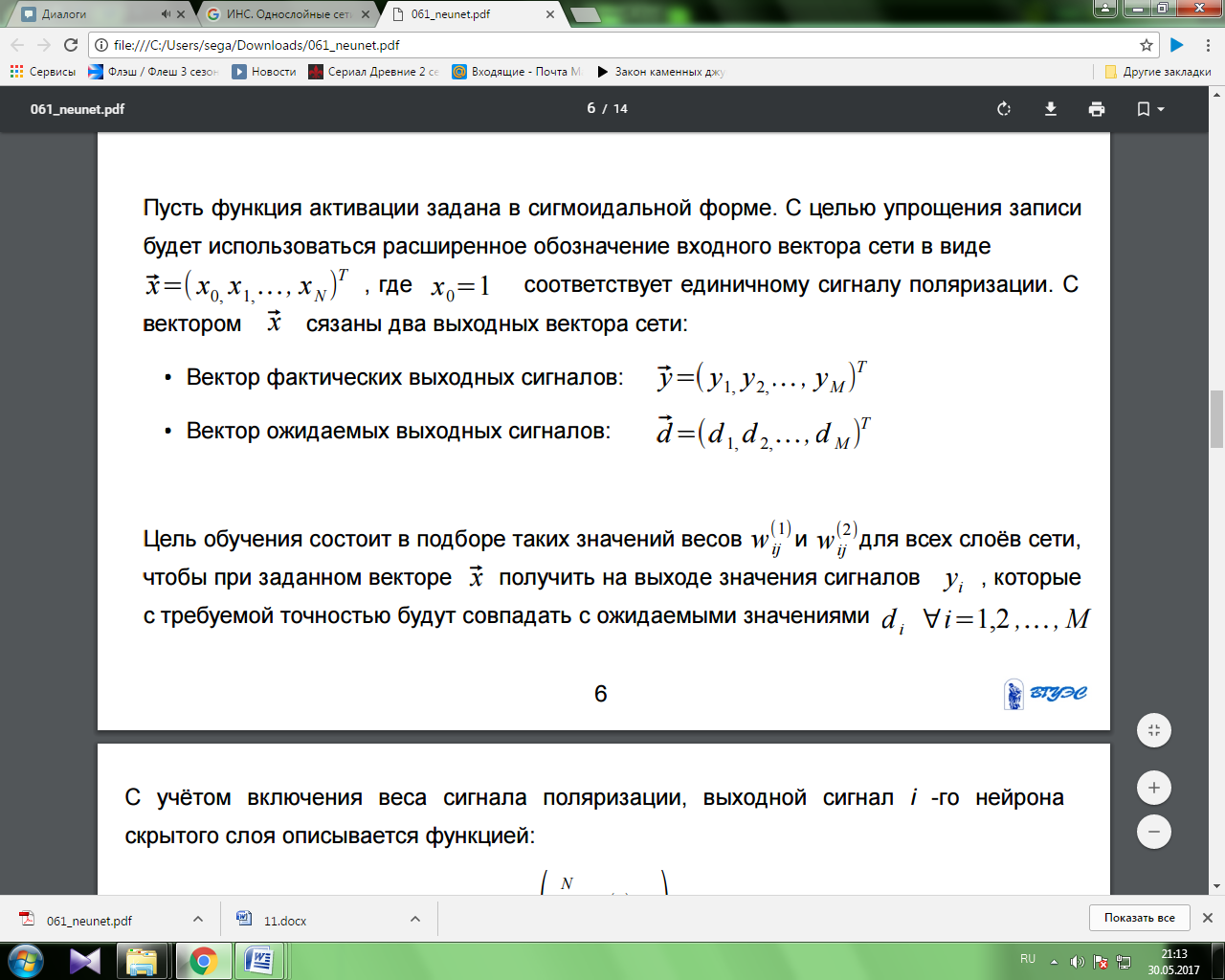
Технология обучения ''с учителем'' искусственной нейронной сети обычно предполагает наличие двух однотипных множеств:
Множества учебных примеров, которое используется для ''настройки'' сети.
Множества контрольных примеров, которое используется для оценки качества работы сети.
Элементами этих двух множеств есть пары ( X, YI ), где
X - вход, для обучаемой нейронной сети;
YI - идеальный (желаемый) выход сети для входа X;
Так же определяется функция ошибки E. Обычно это средняя квадратичная ошибка [3]:
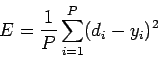
Где P - количество обработанных нейронной сетью примеров;
yi - реальный выход нейронной сети;
di - желаемый (идеальный) выход нейронной сети;
Процедура обучения искусственной нейронной сети сводится к процедуре коррекции весов её связей. Целью процедуры коррекции весов есть минимизация функции ошибки E.
Общая схема обучения "с учителем" выглядит так :
Весовые коэффициенты нейронной сети устанавливаются некоторым образом, обычно - малыми случайными значениями.
На вход нейронной сети в определенном порядке подаются учебные примеры. Для каждого примера вычисляется ошибка EL (ошибка обучения) и по определенному алгоритму производится коррекция весов. Целью процедуры коррекции весов есть минимизация ошибки EL.
Проверка правильности работы сети -- на вход в определенном порядке подаются контрольные примеры. Для каждого примера вычисляется ошибка EG (ошибка обобщения). Если результат неудовлетворительный то, производится модификация множества учебных примеров или архитектуры сети и повторение цикла обучения.
Если после нескольких итераций алгоритма обучения ошибка обучения EL падает почти до нуля, в то время как ошибка обобщения EG в начале спадает а затем начинает расти, то это признак эффекта переобучения. В этом случае обучение необходимо прекратить.
Обучение без учителя
Для методов обучения ''без учителя'', так же как и методов обучения ''с учителем'', требуется множество учебных примеров. Процесс обучения, как и в случае обучения ''с учителем'', сводится к подстраиванию весовых коэффициентов. Но в отличии от обучения ''с учителем'', здесь нет эталонных выходов и веса изменяются по алгоритму, учитывающему только входные и производные от них сигналы.
Метод Хебба основывается на биологическом феномене обучения путем повторения и привыкания. Этот феномен еще известен как эффект проторения
При обучении искусственной нейронной сети сигнальным методом Хебба[8] усиливаются связи между возбужденными нейронами, в данном случае веса изменяются по следующему правилу:
| wij(t+1)=wij(t)+a * yi[n-1] * yj[n] | (13) |
Где yi[n-1] выходное значение нейрона i слоя n-1;
yj[n] выходное значение нейрона j слоя n;
wij(t) и wij(t-1) весовой коэффициент синапса, соединяющего эти нейроны, на итерациях t и t-1 соответственно;
a - коэффициент скорости обучения.
Существует также дифференциальный метод обучения Хебба.
| wij(t+1)=wij(t) + a * ( yi[n-1](t) - yi[n-1](t-1) ) * ( yj[n](t) - yj[n](t-1) ) | (14) |
Здесь
yi[n-1](t) и yi[n-1](t-1) выходное значение нейрона i слоя n-1 соответственно на итерациях t и t-1;
yj[n](t) и yj[n](t-1) то же самое для нейрона j слоя n.
Как видно из (14), сильнее всего обучаются синапсы, соединяющие те нейроны, выходы которых наиболее динамично изменились в сторону увеличения.
10.Статистические методы принятия решений.
Статистические методы основаны на сборе, обработке и анализе статистических данных, полученных как в результате фактических действий, так и выработанных искусственно, путем статистического моделирования. К этим методам относятся последовательный анализ и метод статистических испытаний.
Метод статистических испытаний (метод Монте-Карло) заключается в том, что ход операций проигрывается (моделируется) на ЭВМ со всеми присущими операции случайностями.метод основан на использовании связи между вероятностными характеристиками различных случайных процессов и величинами, являющимися решениями задач математического анализа.
Статистический последовательный анализ изучает статистические методы, основанные на последовательной выборке, формируемой в ходе статистического эксперимента. Наблюдения производятся по одному (или группами) и анализируются в ходе самого эксперимента с тем, чтобы на каждом этапе решить, требуются ли ещё наблюдения. Когда эксперимент остановлен, заключительное статистическое решение принимается на основе всех наблюденных в эксперименте данных. Таким образом, объём последовательной выборки является случайной величиной. Широко известным примером эффективного последовательного метода является последовательный критерий отношения вероятностей (критерий Вальда) в проверке гипотез.
При статистическом моделировании для получения достоверных вероятностных характеристик процессов функционирования системы требуется их многократное воспроизведение с различными конкретными значениями случайных факторов и статистической обработкой результатов измерений.
Критерий Байеса.

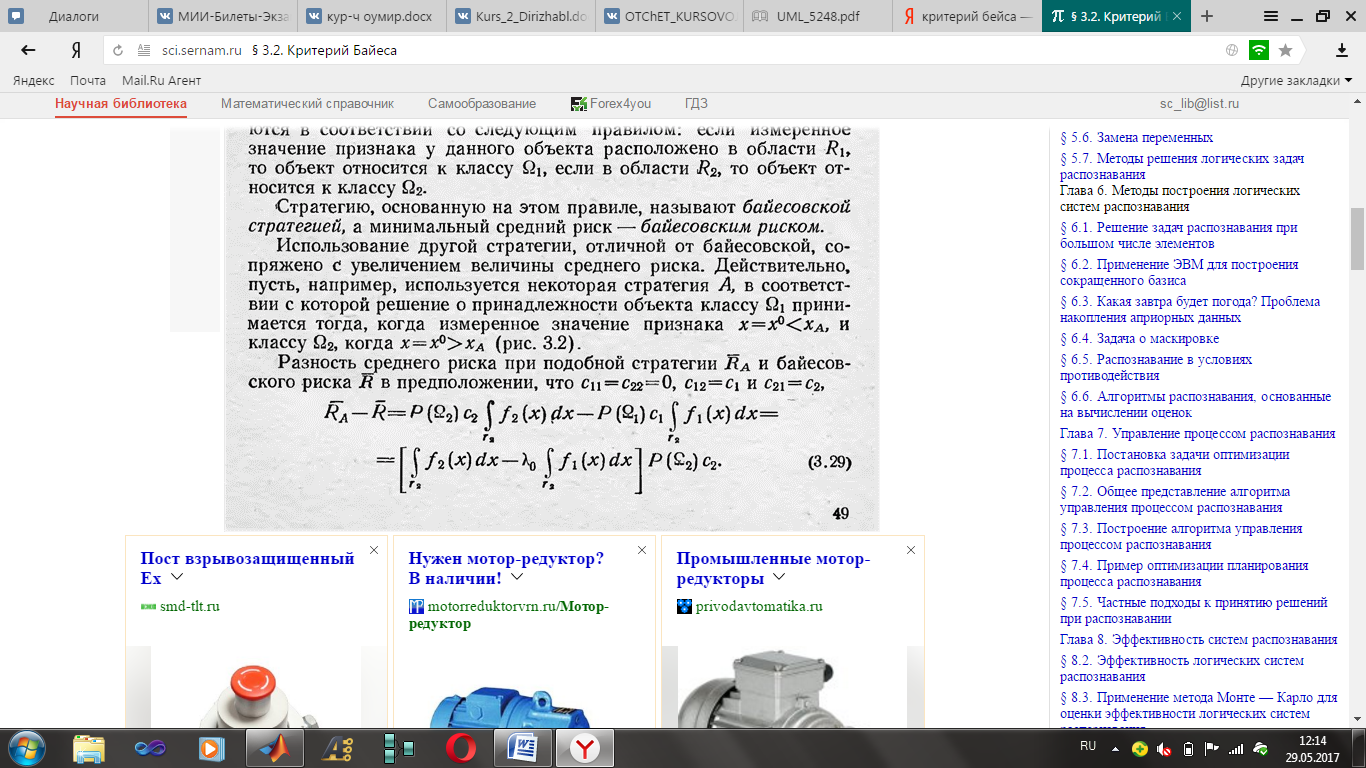

Этот критерий используется в предположении, что вероятность qj состояний природы Пj известны. В качестве показателя эффективности чистой стратегии Аi используется средневзвешенный выигрыш при стратегии Аi с весами q1, q2, …qn, т.е. величина
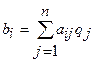
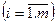
Оптимальной по Байесу чистой стратегией является стратегия с максимальным показателем эффективности. Цена игры в этом случае определяется по формуле:
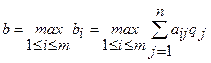
Аналогично можно найти оптимальную по Байесу стратегию, используя формулу
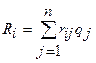
Стратегия, максимизирующая средний выигрыш совпадает со стратегией, минимизирующей средний риск.
11. Статистические методы принятия решений. Критерий минимакса. Критерий максимального правдоподобия.
Критерий минимакса.
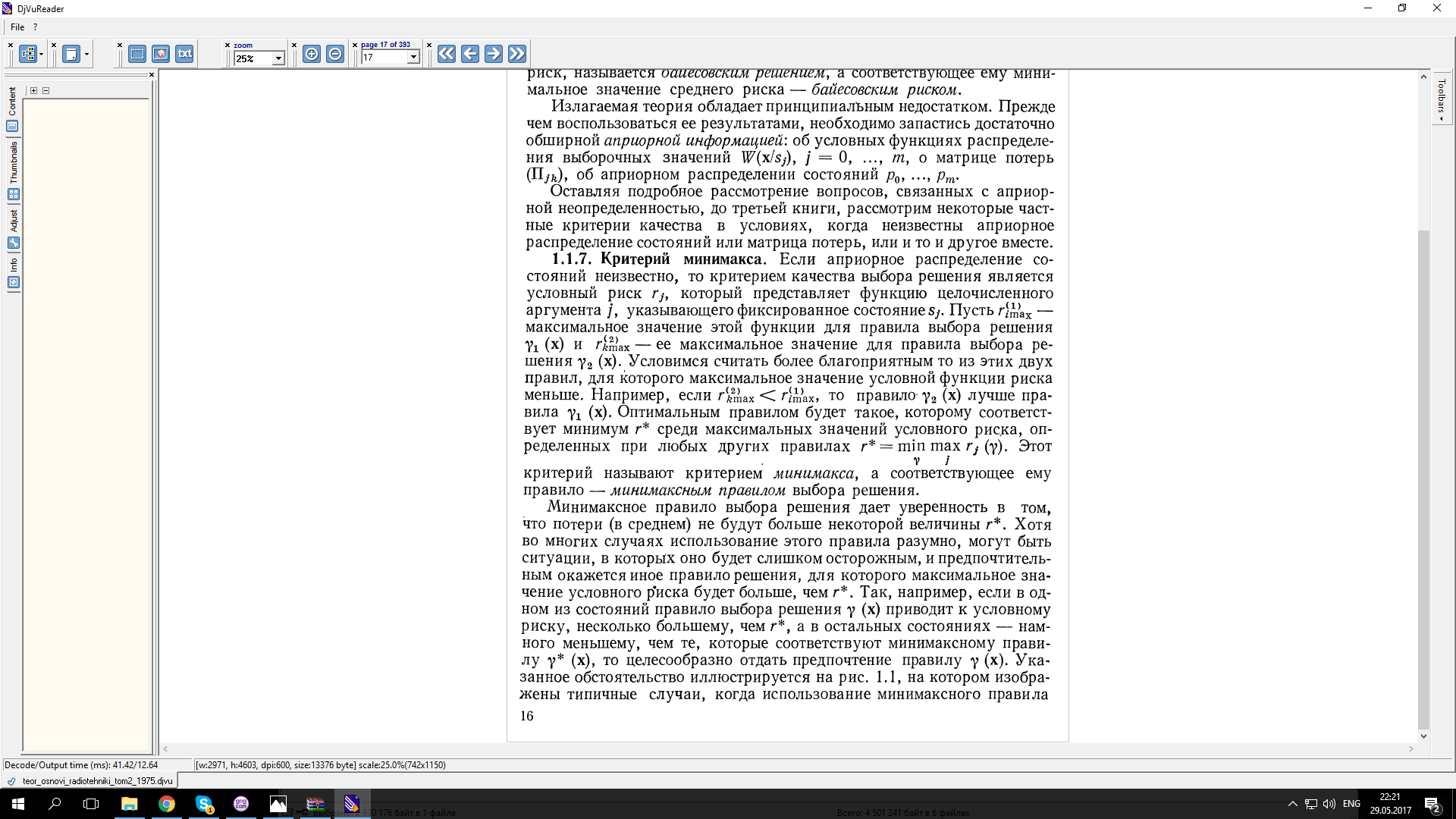
Критерий максимального правдоподобия.
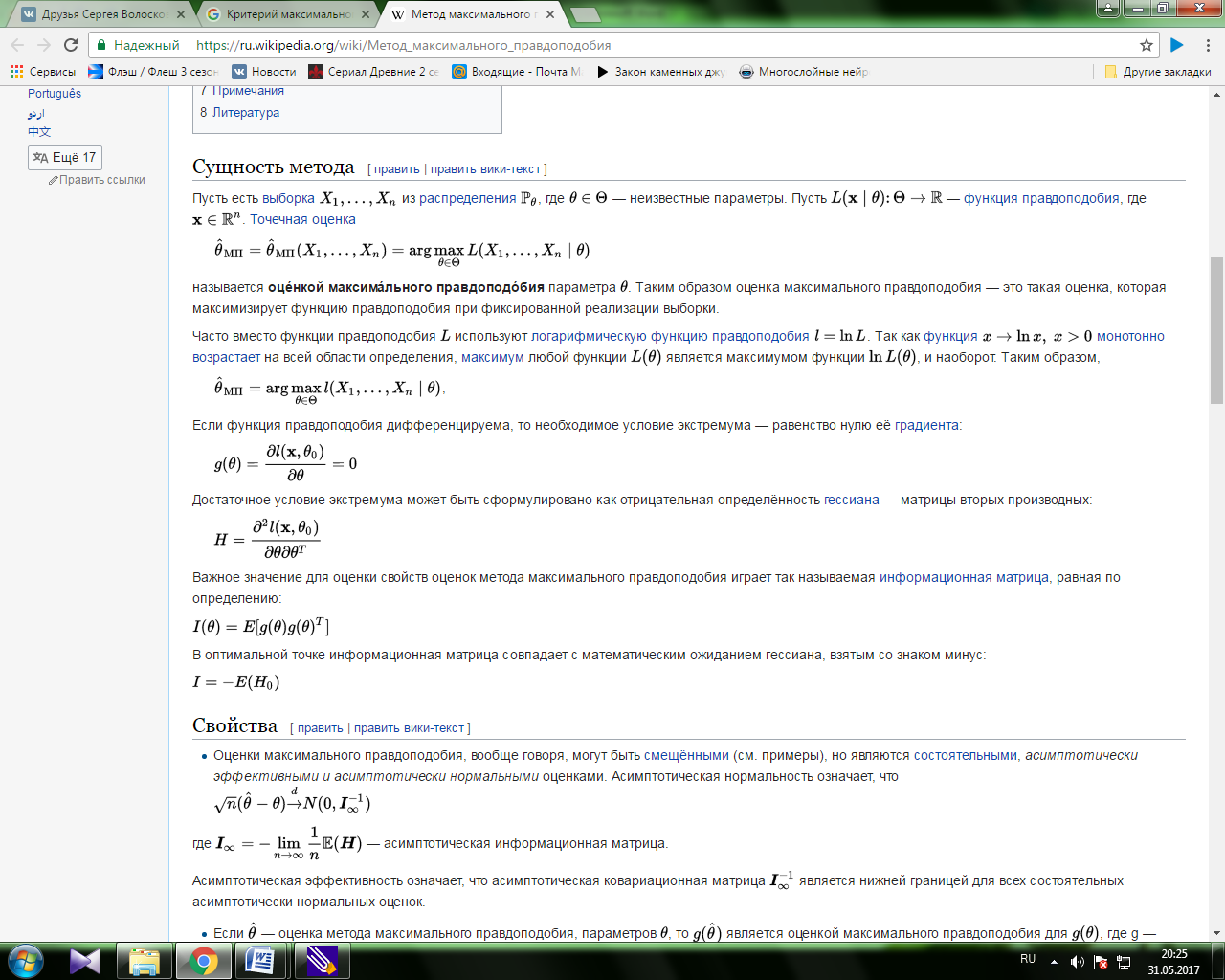
Ме́тод максима́льного правдоподо́бия или метод наибольшего правдоподобия в математической статистике — это метод оценивания неизвестного параметра путём максимизации функции правдоподобия[1]. Основан на предположении о том, что вся информация о статистической выборке содержится в функции правдоподобия. Метод максимального правдоподобия был проанализирован, рекомендован и значительно популяризирован Р. Фишером между 1912 и 1922 годами (хотя ранее он был использован Гауссом, Лапласом и другими).
Оценка максимального правдоподобия является популярным статистическим методом, который используется для создания статистической модели на основе данных и обеспечения оценки параметров модели.
Метод максимального правдоподобия соответствует многим известным методам оценки в области статистики. Например, вы интересуетесь таким антропометрическим параметром, как рост жителей России. Предположим, у вас имеются данные о росте некоторого количества людей, а не всего населения. Кроме того, предполагается, что рост является нормально распределённой величиной с неизвестной дисперсией и средним значением. Среднее значение и дисперсия роста в выборке являются максимально правдоподобными к среднему значению и дисперсии всего населения.
Для фиксированного набора данных и базовой вероятностной модели, используя метод максимального правдоподобия, мы получим значения параметров модели, которые делают данные «более близкими» к реальным. Оценка максимального правдоподобия даёт уникальный и простой способ определить решения в случае нормального распределения.
Метод оценки максимального правдоподобия применяется для широкого круга статистических моделей, в том числе:
линейные модели и обобщённые линейные модели;
факторный анализ;
моделирование структурных уравнений;
многие ситуации, в рамках проверки гипотезы и доверительного интервала формирования;
дискретные модели выбора.
Сущность метода
12.Критерий Неймана-Пирсона.
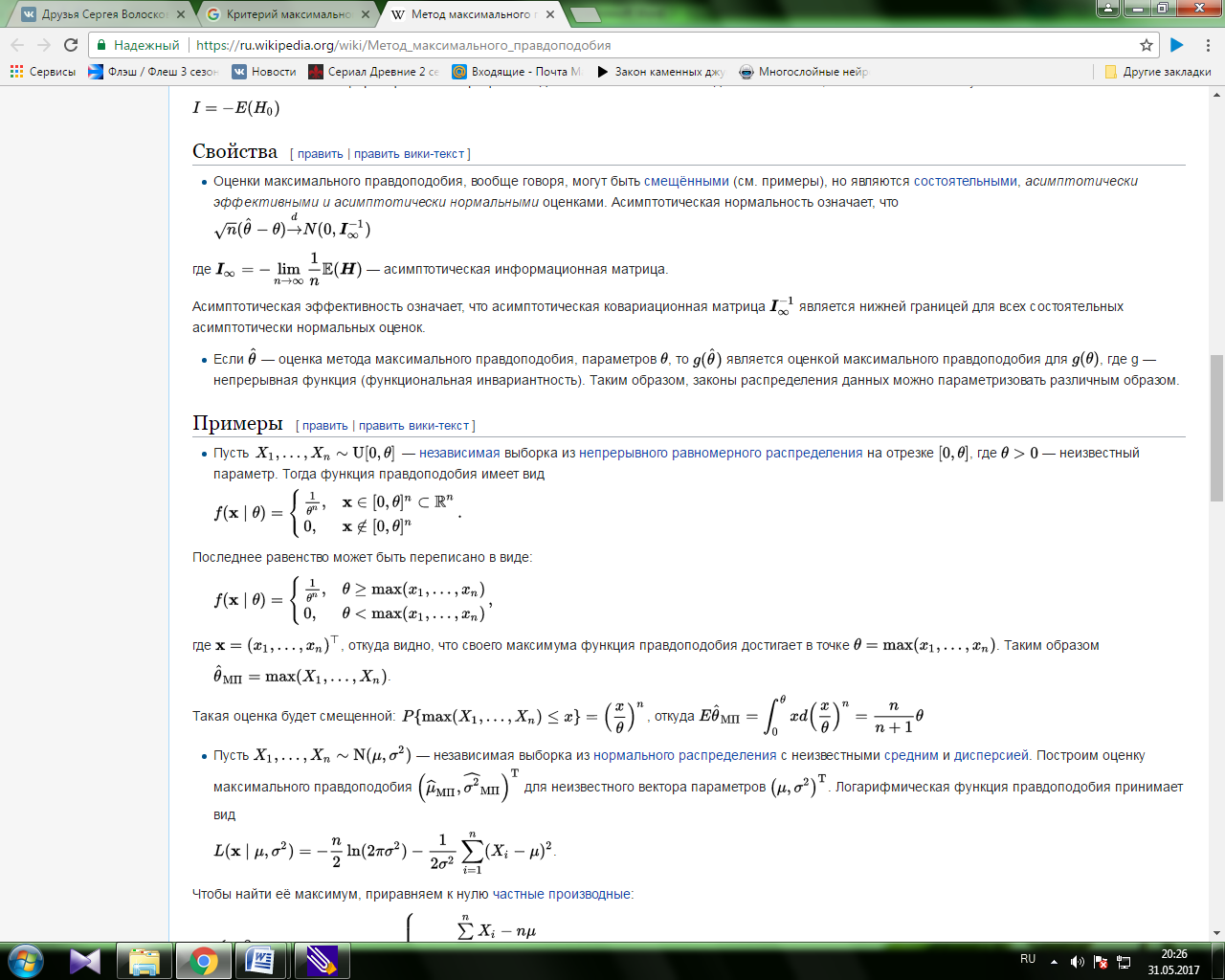
Одним из существенных недостатков байесовского правила обнаружения сигналов является большое количество априорной информации о потерях и вероятностях состоянии объекта, которая должна быть в распоряжении наблюдателя. Этот недостаток наиболее отчетливо проявляется при анализе радиолокационных задач обнаружения цепи, когда указать априорные вероятности наличия цели в заданной области пространства и потери за счет ложной тревоги или пропуска цели оказывается весьма затруднительным. Поэтому в подобных задачах вместо байесовского критерия обычно используется критерий Неймана-Пирсона. Согласно этому критерию выбирается такое правило обнаружения, которое обеспечивает минимальную величину вероятности пропуска сигнала (максимальную вероятность правильного обнаружения) при условии, что вероятность ложной тревоги не превышает заданной величины  . Таким образом, оптимальное, в смысле критерия Неймана-Пирсона, правило обнаружения минимизирует
. Таким образом, оптимальное, в смысле критерия Неймана-Пирсона, правило обнаружения минимизирует
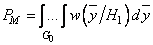 (3.12)
(3.12)
при дополнительном ограничении
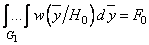 . (3.13)
. (3.13)
Для поиска оптимальной процедуры обработки данных преобразуем задачу на условный экстремум (3.12) при условии (3.13) к задаче на безусловный экстремум. С этой целью воспользуемся методом множителей Лагранжа [27]. Введем множитель Лагранжа  и запишем функцию Лагранжа
и запишем функцию Лагранжа
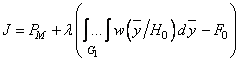 . (3.14)
. (3.14)
После преобразований, аналогичных выводу формулы (3.5), соотношение (3.14) можно переписать в виде:
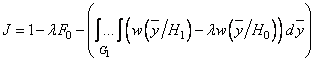 .
.
Сравнение полученного выражения с формулой (3.5) показывает, что минимум функции Лагранжа достигается, если в качестве критической области выбрать совокупность точек 
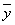 , удовлетворяющих неравенству
, удовлетворяющих неравенству
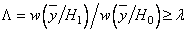 . (3.15)
. (3.15)
При этом множитель , являющийся пороговым значением, должен находиться из условия (3.13) равенства вероятности ложной тревоги заданной величине .
Из сравнения (3.15) и (3.8) можно заключить, что оптимальное, в смысле критерия Неймана-Пирсона, правило обнаружения отличается от байесовского лишь величиной порогового уровня, с которым производится сравнение отношения правдоподобия.
В качестве примера построения обнаружителя (3.15) рассмотрим задачу проверки гипотезы 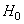 :
:
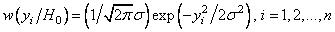 ,
,
при альтернативе
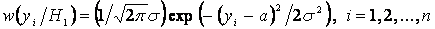 .
.
Такая задача возникает в тех случаях, когда появление полезного сигнала вызывает изменение среднего значения нормального шума на величину 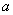 . При независимых отсчётах
. При независимых отсчётах  входного процесса отношение правдоподобия может быть записано в виде
входного процесса отношение правдоподобия может быть записано в виде
 .
.
После логарифмирования получаем следующий алгоритм обнаружения сигнала:
 (3.16)
(3.16)
причем пороговый уровень 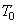 выбирается из условия
выбирается из условия
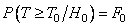 . (3.17)
. (3.17)
Поскольку сумма 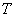 нормальных случайных величин (СВ) подчиняется нормальному закону распределения, то при отсутствии сигнала можно записать следующее выражение для условной ПРВ
нормальных случайных величин (СВ) подчиняется нормальному закону распределения, то при отсутствии сигнала можно записать следующее выражение для условной ПРВ 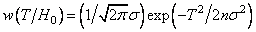 . С учетом формул табл.1 соотношение (3.17) перепишется в форме
. С учетом формул табл.1 соотношение (3.17) перепишется в форме  . Из этого равенства по таблицам функции Лапласа
. Из этого равенства по таблицам функции Лапласа 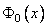 [1–4] можно определить величину порогового уровня . Так, при
[1–4] можно определить величину порогового уровня . Так, при  получим
получим  ; при
; при 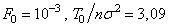 .
.
Щенятский
Дата добавления: 2018-06-01; просмотров: 1158; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!