Прогноз по данным временного ряда с учетом сезонной компоненты.
Nbsp;
Метод XYZ.
XYZ-анализ позволяет произвести классификацию ресурсов компании в зависимости от характера их потребления и точности прогнозирования изменений в их потребности в течение определенного временного цикла. Алгоритм проведения можно представить в четырёх этапах:
Определение коэффициентов вариации для анализируемых ресурсов;
Группировка ресурсов в соответствии с возрастанием коэффициента вариации;
Распределение по категориям X, Y, Z.
Графическое представление результатов анализа.
Категория X — ресурсы характеризуются стабильной величиной потребления, незначительными колебаниями в их расходе и высокой точностью прогноза. Значение коэффициента вариации находится в интервале от 0 до 10 %.
Категория Y — ресурсы характеризуются известными тенденциями определения потребности в них (например, сезонными колебаниями) и средними возможностями их прогнозирования. Значение коэффициента вариации — от 10 до 25 %.
Категория Z — потребление ресурсов нерегулярно, какие-либо тенденции отсутствуют, точность прогнозирования невысокая. Значение коэффициента вариации — свыше 25 %.
Реальное значение коэффициента вариации для разных групп может отличаться по следующим причинам:
сезонность продаж,
тренд,
акции,
дефицит и т. д.
Есть несколько разновидностей XYZ-анализа, например анализ плановых данных с фактическими, что дает более точный % отклонения от прогноза. Очень часто XYZ-анализ проводят совместно с ABC-анализом позволяя выделять более точные группы, относительно их свойств.
|
|
|
Коэффициент вариации — это отношение среднеквадратичного отклонения к среднеарифметическому значению измеряемых значений ресурса.
Метод АВС.
ABC-анализ — метод, позволяющий классифицировать ресурсы фирмы по степени их важности. Этот анализ является одним из методов рационализации и может применяться в сфере деятельности любого предприятия. В его основе лежит принцип Парето — 20 % всех товаров дают 80 % оборота. По отношению к ABC-анализу правило Парето может прозвучать так: надёжный контроль 20 % позиций позволяет на 80 % контролировать систему, будь то запасы сырья и комплектующих, либо продуктовый ряд предприятия и т. п. Часто ABC-анализ путают с ABC-методом, расшифровывая ABC как Activity Based Costing, что в корне не верно.
ABC-анализ — анализ товарных запасов путём деления на три категории:
А — наиболее ценные, 20 % — тов.запасов; 80 % — продаж
В — промежуточные, 30 % — тов.запасов; 15 % — продаж
С — наименее ценные, 50 % — тов.запасов; 5 % — продаж
В зависимости от целей анализа может быть выделено произвольное количество групп. Чаще всего выделяют 3, реже 4-5 групп.
|
|
|
По сути, ABC-анализ — это ранжирование ассортимента по разным параметрам. Ранжировать таким образом можно и поставщиков, и складские запасы, и покупателей, и длительные периоды продаж — всё, что имеет достаточное количество статистических данных. Результатом АВС анализа является группировка объектов по степени влияния на общий результат.
АВС-анализ основывается на принципе дисбаланса, при проведении которого строится график зависимости совокупного эффекта от количества элементов. Такой график называется кривой Парето, кривой Лоренца или ABC-кривой. По результатам анализа ассортиментные позиции ранжируются и группируются в зависимости от размера их вклада в совокупный эффект. В логистике ABC-анализ обычно применяют с целью отслеживания объёмов отгрузки определённых артикулов и частоты обращений к той или иной позиции ассортимента, а также для ранжирования клиентов по количеству или объёму сделанных ими заказов.
Метод дерево решений (есть проблема - да/нет, если да, то - решается/не решается; вообще ты должен помнить, как гендальф решает свои проблемы).
|
|
|
Дерево принятия решений (также могут назваться деревьями классификации или регрессионными деревьями) — используется в области статистики и анализа данных для прогнозных моделей. Структура дерева представляет собой следующее: «листья» и «ветки».
На ребрах («ветках») дерева решения записаны атрибуты, от которых зависит целевая функция, в «листьях» записаны значения целевой функции, а в остальных узлах — атрибуты, по которым различаются случаи. Чтобы классифицировать новый случай, надо спуститься по дереву до листа и выдать соответствующее значение.
Подобные деревья решений широко используются в интеллектуальном анализе данных. Цель состоит в том, чтобы создать модель, которая предсказывает значение целевой переменной на основе нескольких переменных на входе.
Среди прочих методов Data Mining, метод дерева принятия решений имеет несколько достоинств:
1. Прост в понимании и интерпретации. Люди способны интерпретировать результаты модели дерева принятия решений после краткого объяснения
2. Не требует подготовки данных. Прочие техники требуют нормализации данных, добавления дамми-переменных, а также удаления пропущенных данных.
3. Способен работать, как с категориальными, так и с интервальными переменными. Прочие методы работают лишь с теми данными, где присутствует лишь один тип переменных. Например, метод отношений может быть применен только на номинальных переменных, а метод нейронных сетей только на переменных, измеренных по интервальной шкале.
|
|
|
4. Использует модель «белого ящика». Если определенная ситуация наблюдается в модели, то её можно объяснить при помощи булевой логики. Примером «черного ящика» может быть искусственная нейронная сеть, так как результаты данной модели поддаются объяснению с трудом.
5. Позволяет оценить модель при помощи статистических тестов. Это дает возможность оценить надежность модели.
6. Является надежным методом. Метод хорошо работает даже в том случае, если были нарушены первоначальные предположения, включенные в модель.
7. Позволяет работать с большим объемом информации без специальных подготовительных процедур. Данный метод не требует специального оборудования для работы с большими базами данных.
Недостатки:
1. Проблема получения оптимального дерева решений является NP-полной с точки зрения некоторых аспектов оптимальности даже для простых задач[7][8]. Таким образом, практическое применение алгоритма деревьев решений основано на эвристических алгоритмах, таких как алгоритм «жадности», где единственно оптимальное решение выбирается локально в каждом узле. Такие алгоритмы не могут обеспечить оптимальность всего дерева в целом.
2. Те, кто изучает метод дерева принятия решений, могут создавать слишком сложные конструкции, которые не достаточно полно представляют данные. Данная проблема называется проблемой «чрезмерной подгонки»[9] Для того, чтобы избежать данной проблемы, необходимо использовать Метод «регулирования глубины дерева».
3. Существуют концепты, которые сложно понять из модели, так как модель описывает их сложным путем. Данное явление может быть вызвано проблемами XOR, четности или мультиплексарности. В этом случае мы имеем дело с непомерно большими деревьями. Существует несколько подходов решения данной проблемы, например, попытка изменить репрезентацию концепта в модели (составление новых суждений)[10], или использование алгоритмов, которые более полно описывают и репрезентируют концепт (например, метод статистических отношений, индуктивная логика программирования).
4. Для данных, которые включают категориальные переменные с большим набором уровней (закрытий), больший информационный вес присваивается тем атрибутам, которые имеют большее количество уровней.[11]
Метод экстраполяции тренда.
Суть данного метода состоит в том, что закономерность, действующая внутри анализируемого периода, выступающего в качестве базы прогнозирования. Прогнозирование в этом случае сводится к подбору аналитически выраженных моделей тренда типа y=f(t). По данным пред прогнозного периода и экстраполяции полученных трендов на интервале прогноза. Расчетная формула для получения прогноза записывается в аддитивном или мультипликативном виде.
Аддитивная модель прогноза имеет вид – y1t=yt+St+Vt+dt+Et (1),y1t- прогнозное значение временного ряда, yt – среднее значение прогноза, St – составляющая прогноза, отражающая периодические колебания (сезонные колебания), Vt – составляющая прогноза, отражающая периодические колебания, повторяющиеся в течении длительного промежутка времени, dt – составляющая, позволяющая учесть другие важные для конкретного прогноза факторы, Et – случайная величина отклонения прогноза, обусловленного стохастическим характером социально-экономических процессов.
Мультипликативная модель прогноза имеет вид - y1t=yt+JS*JV*Jd+Et (2) - JS – коэффициент, учитывающий сезонные колебания, JV – коэффициент учитывающий циклические колебания, Jd – коэффициент учитывающий другие для конкретного прогноза факторы.
В частных случаях количество составляющих данной модели может быть меньше или больше, если необходимо выделить сезонные составляющие применительно к часам суток, дням недели, месяцам.
Рассмотрим простой вариант, когда данные модели содержат 2 составляющих.
Процедура прогнозирования представляется в следующей последовательности:
1. Подбор зависимости для описания уравнения тренда yt1=ao+a1*t (3). Расчет коэффициентов уравнения производится по формуле ao= 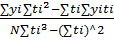 (4), a1=
(4), a1= 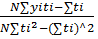 (5)
(5)
2. Продолжение полученного тренда за интервал значений, по которым строилась зависимость или определение точечного прогноза. Для получения значения прогноза на tгод в уравнение трендов подставляется конкретно значение t. При этом соотношение длины предпрогнозного периода и периода прогноза должно быть не менее чем 3 к 1
3. Расчет ошибки прогноза (погрешность прогноза) – Sy= 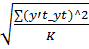 (6) - Sy – погрешность прогноза,
(6) - Sy – погрешность прогноза, 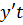 – расчетное значение,
– расчетное значение, 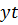 – фактическое значение, К – число степеней свободы, определяющее зависимости от числа наблюдений и числа оцениваемых параметров – К=N-r (7) – N – число наблюдений, r – число параметров.
– фактическое значение, К – число степеней свободы, определяющее зависимости от числа наблюдений и числа оцениваемых параметров – К=N-r (7) – N – число наблюдений, r – число параметров.
4. Определение интервалов прогноза - ∆y=yt 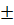 t*Sy (8)
t*Sy (8)
Задача:
Выполнить прогноз на 6 день используя исходные данные
| День | Спрос | Всего с начала цикла |
| 1 | 9 | 9 |
| 2 | 2 | 9+2=11 |
| 3 | 1 | 12 |
| 4 | 3 | 15 |
| 5 | 7 | 22 |
Формула модели Брауна:
Решение: параметр начального условия
В первом приближении примем α=0.4. в качестве начального условия выберем значения спроса в день y1=9/
Формула Y1t+1=αy+(1-α)y1t - выполним прогноз при t=1, подставим в формулу необходимые значения показателя и начальные условия => 0,4*9+(1-0,4)*9=9 единиц
Y’2+1=0,4*2+(1-0,4)*9=6,2 единицы
Y’3+1=0,4*1+(1-0,4)*6,2=4,12 единицы
Y’4+1=0,4*4+(1-0,4)*4,12=3,672
Y’5+1=0,4*7+(1-0,4)*3,672=5,0032
Ошибка прогноза: Sy= 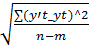 =
= 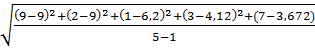 =4,7
=4,7
Найдем интервальный прогноз на основании критерия Стьюдента:
Для уровня значимости 0,1 при К=4 и t0,1=2,132 определим нижнюю границу прогноза
Yнижн=5-4,7*2,132=-5 => так как нижняя граница не может быть отрицательна примем ее = 0
Yверхн=5+4,7*2,132=15
Таким образом методом экспоненциального сглаживания получен прогноз на 6 день: среднее значение реализации 5 единиц, ошибка прогноза 4,7 единиц, с вероятностью 0,9 ожидается реализация в интервале от 0 до 15 единиц
Для α=0,3
Y’1+1=0,3*9+(1-0,4)*9=9
Y’2+1=0,3*2+(1-0,4)*9=6,9 единицы
Y’3+1=0,3*1+(1-0,4)* 6,9 =5,13 единицы
Y’4+1=0,3*4+(1-0,4)*5,13 =4,491 единицы
Y’5+1=0,3*7+(1-0,4)* 4,491 =5,2437 единицы
Ошибка прогноза: Sy= = 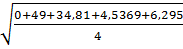 =4,87
=4,87
Yнижн=5-4,87*2,132=-5 => так как нижняя граница не может быть отрицательна примем ее = 0
Yверхн=5+4,87*2,132=15
Таким образом методом экспоненциального сглаживания получен прогноз на 6 день: среднее значение реализации 5 единиц, ошибка прогноза 4,87 единиц, с вероятностью 0,9 ожидается реализация в интервале от 0 до 15 единиц
Прогноз по данным временного ряда с учетом сезонной компоненты.
Алгоритм прогнозирования с учетом сезонной составляющей по трендовым моделям состоит из 5 этапов:
1. Определение структуры сезонных изменений и периода этих колебаний
2. Оценка и исключения тренда
3. Определение сезонной компоненты, зависящей от выбора модели прогноза.
a. Для аддитивной модели рассчитывается оценка сезонной компоненты как разность между фактическим и значением определенной по трендовой модели, или фактическим значением и скользящей средней, или фактическим значением и централизованной средней
b. Для мультипликативной модели находится отношение фактических значений показателя к расчетным, или фактических значений показателя к скользящей средней, или фактических значений и централизованной средней.
c. Для дальнейшего значения сезонной компоненты и коэффициента сезонности находится среднее значение оценок для каждого сезона. Полученное среднее значение корректируется таким образом, чтобы сумма сезонной компоненты для аддитивной модели равнялась 0, а сумма коэффициента сезонности для мультипликативной модели равнялась числу сезонов.
4. Прогнозирование на основе данных, из которых исключена сезонная составляющая. Этот этап выполняется в том случае, если на 2 этапе выбран для оценки тренда метод скользящих средних
5. Вычисление средней ошибки модели прогноза. Из фактического значения вычитаются сезонная компонента и тренд, для полеченных остатков определяется средняя квадратическое отклонение – аддитивная модель. В мультипликативной модели из фактического значения вычитается произведение индекса сезонности и тренда, по полученным остаткам рассчитывается ошибка прогноза.
Дата добавления: 2018-02-18; просмотров: 754; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!