Правило 1. «Накрытие» точки минимума
Если вершина, которой соответствует наибольшее значение целевой функции, построена на предыдущей итерации, то вместо нее берется вершина, которой соответствует следующее по величине значение целевой функции.
Правило 2. Циклическое движение
Если некоторая вершина симплекса не исключается на протяжении более чем M итераций, то необходимо уменьшить размеры симплекса с помощью коэффициента редукции и построить новый симплекс, выбрав в качестве базовой точку, которой соответствует минимальное значение целевой функции. Спендли, Хекст и Химс-ворт предложили вычислять M по формуле
М = 1,65N + 0,05N 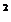 ,
,
где N — размерность задачи, а М округляется до ближайшего целого числа. Для применения данного правила требуется установить величину коэффициента редукции.
Правило 3. Критерий окончания поиска
Поиск завершается, когда или размеры симплекса, или разности между значениями функции в вершинах становятся достаточно малыми. Чтобы можно было применять эти правила, необходимо задать величину параметра окончания поиска.
Реализация изучаемого алгоритма основана на вычислениях двух типов: (1) построении регулярного симплекса при заданных базовой точке и масштабном множителе и (2) расчете координат отраженной точки. Построение симплекса является достаточно простой процедурой, так как из элементарной геометрии известно, что при заданных начальной (базовой) точке х(0) и масштабном множителе α координаты остальных N вершин симплекса в N-мерном пространстве вычисляются по формуле
|
|
|
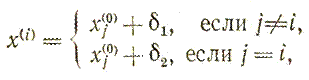 (3.17)
(3.17)
для i и j=1, 2, 3,…,N.
Приращения δ1 и δ2, зависящие только от N и выбранного масштабного множителя α, определяются по формулам
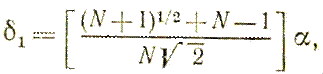 (3.18)
(3.18)
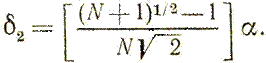 (3.19)
(3.19)
Заметим, что величина масштабного множителя α выбирается исследователем, исходя из характеристик решаемой задачи. При α — 1 ребра регулярного симплекса имеют единичную длину.
Вычисления второго типа, связанные с отражением относительно центра тяжести, также представляют несложную процедуру. Пусть x 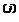 точка, подлежащая отражению. Центр тяжести остальных N точек расположен в точке
точка, подлежащая отражению. Центр тяжести остальных N точек расположен в точке
x 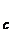 =
= 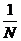
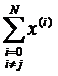 . (3.20)
. (3.20)
все точки прямой, проходящей через x и хc, задаются формулой
х = x + λ(хc – x ). (3.21)
При λ = 0 получаем исходную точку x тогда как значениеλ =1 соответствует центру тяжести хc. Для того чтобы построенный симплекс обладал свойством регулярности, отражение должно быть симметричным. Следовательно, новая вершина получается при λ= 2. Таким образом,
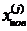 = 2
= 2 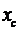 –
– 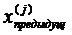 (3.22)
(3.22)
|
|
|
Проиллюстрируем вычислительную схему метода следующим примером.
Пример 3.2. Вычисления в соответствии с методом поиска по симплексу
Минимизировать f(x) = (1 – х1 )2 + (2 – х2 )2.
Решение. Для построения исходного симплекса требуется задать начальную точку и масштабный множитель. Пусть х(0)= [0,0]  и α = 2. Тогда
и α = 2. Тогда
δ  = [
= [ 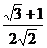 ] α = 1.9318
] α = 1.9318
δ 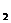 = [
= [ 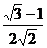 ] α = 0.5176
] α = 0.5176
Используя эти два параметра, вычислим координаты двух остальных вершин симплекса:
х(1) = [0+0,5176, 0+1,9318]T = [0,5176, 1,9318]T,
х(2) = [0+1,9318, 0+0,5176]T = [1,9318, 0,5176]T,
которым соответствуют значения целевой функции, равные f (x(1)) = 0,2374 и f (х(2))= 3,0658. Так как f (x  ) = 5, необходимо отразить точку х(0) относительно центра тяжести двух остальных вершин симплекса
) = 5, необходимо отразить точку х(0) относительно центра тяжести двух остальных вершин симплекса
x  =
= 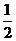
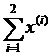 = (х(1) + х(2)).
= (х(1) + х(2)).
Используя формулу (3.22), получаем
x 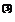 = x
= x 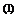 + x
+ x 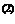 – x
– x 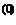
x = [2,4494, 2,4494]T.
В полученной точке f (х3)= 2,3027, т. е. наблюдается уменьшение целевой функции. Новый симплекс образован точками х(1), х(2),и х(3).В соответствии с алгоритмом следует отразить точку х(2), которой соответствует наибольшее значение целевой функции, относительно центра тяжести точек х(1) и х(3). Итерации продолжаются до тех пор, пока не потребуется применение правил 1, 2 и 3, которые были сформулированы выше.
Изложенный выше алгоритм S2-метода имеет несколько очевидных преимуществ.
|
|
|
1. Расчеты и логическая структура метода отличаются сравнительной простотой, и, следовательно, соответствующая программа для ЭВМ оказывается относительно короткой.
2. Уровень требований к объему памяти ЭВМ невысокий, массив имеет размерность (N + 1, N + 2).
3. Используется сравнительно небольшое число заранее установленных параметров: масштабный множитель α, коэффициент уменьшения множителя α (если применяется правило 2) и параметры окончания поиска.
4. Алгоритм оказывается эффективным даже в тех случаях, когда ошибка вычисления значений целевой функции велика, поскольку при его реализации оперируют наибольшими значениями функции в вершинах, а не наименьшими.
Перечисленные факторы характеризуют метод поиска по симплексу как весьма полезный при проведении вычислений в реальном времени.
Алгоритм обладает также рядом существенных недостатков.
1. Не исключено возникновение трудностей, связанных с масштабированием, поскольку все координаты вершин симплекса зависят от одного и того же масштабного множителя α. Чтобы обойти трудности такого рода, в практических задачах следует промасштабировать все переменные с тем, чтобы их значения были сравнимыми по величине.
|
|
|
2. Алгоритм работает слишком медленно, так как полученная на предыдущих итерациях информация не используется для ускорения поиска.
3. Не существует простого способа расширения симплекса, не требующего пересчета значений целевой функции во всех точках образца. Таким образом, если ос по какой-либо причине уменьшается (например, если встречается область с узким «оврагом» или «хребтом»), то поиск должен продолжаться с уменьшенной величиной шага.
Модифицированная процедура поиска по симплексу, разработанная Нелдером и Мидом [6], частично устраняет некоторые из перечисленных недостатков.

Рис. 3.6. Растяжение и сжатие симплексов
a — нормальное сжатие (θ = α = 1), f 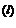 < f(x
< f(x 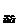 ) < f
) < f 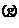 ; б — растяжение (θ = γ > 1), f(x ) < f ,
; б — растяжение (θ = γ > 1), f(x ) < f ,
в — сжатие (θ = β < 0), f(x ) > f , f(x ) ≥ f 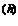 ; г — сжатие (θ = β > 0) f < f(x ) < f .
; г — сжатие (θ = β > 0) f < f(x ) < f .
Нетрудно заметить, что хотя формула для определения вершин регулярного симплекса оказывается весьма удобной при построении исходного образца, однако веских оснований для сохранения свойства регулярности симплекса в процессе поиска нет. Следовательно, при отражении симплекса существует возможность как его растяжения, так и сжатия 1). При расчетах по методу Нелдера и Мида используются вершины симплекса x(h) (которой соответствует наибольшее значение целевой функции f(h) ), х(g) (которой соответствует следующее по величине значение целевой функции f(g) )и х(l) (которой соответствует наименьшее значение целевой функции f(l) ) - Напомним, что отражение вершины симплекса осуществляется по прямой
х = x 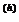 + λ(хc – x ).
+ λ(хc – x ).
или х = x + (1 + θ)(хc – x ). (3.23)
При θ = 1 имеет место так называемое нормальное отражение симплекса, поскольку точка хнов располагается на расстоянии || хс – x(j) || от точки хс.Если –1 ≤ θ < 1, то наблюдается сжатое отражение, или сжатие симплекса, тогда как выбор θ >1 обеспечивает растянутое отражение, или растяжение симплекса. На рис. 3.6 приведены возможные варианты отражения. Три значения параметра θ, используемые при нормальном отражении, сжатии и растяжении, обозначаются через α,βиγсоответственно. Реализация метода начинается с построения исходного симплекса и определения точек x(h), х(g), х(l), хc. После нормального отражения осуществляется проверка значений целевой функции по критерию окончания поиска в точках отраженного симплекса. Если поиск не закончен, то с помощью тестов, приведенных на рис. 3.6, выбирается одна из операций —нормальное отражение, растяжение или сжатие. Итерации продолжаются, пока изменения значений целевой функции в вершинах симплекса не станут незначительными. В качестве удовлетворительных значений параметров α, β иγ Нелдер и Мид рекомендуют использовать α = 1, β = 0,5 и γ= 2.
Результаты отдельных численных экспериментов показывают, что метод Нелдера — Мида обладает достаточной эффективностью и высокой надежностью в условиях наличия случайных возмущений или ошибок при определении значений целевой функции. В 1969 г. Бокс и Дрейпер [7]утверждали, что этот метод является «наиболее эффективным из всех известных методов последовательной оптимизации». В 1972 г. Паркинсон и Хатчинсон [8] исследовали влияние выбора параметров α,β иγ и способа построения исходного симплекса на эффективность поиска. Они установили, что ориентация исходного симплекса в отличие от его формы является существенным фактором, влияющим на процедуру поиска, и предложили использовать значения параметров (α, β, γ) = (2, 0,25, 2,5). Такой выбор параметров позволил обеспечить хорошую работу алгоритма при повторении последовательных растяжений симплекса.
1) По этой причине процедуру Нелдера и Мида иногда называют методом поиска по деформируемому многограннику. — Прим.. перев.
Метод поиска Хука — Дживса
Изложенные выше методы поиска основаны на различных операциях над образцами, составленными из пробных точек. Несмотря на то что в предыдущем подразделе основное внимание было уделено-геометрическому расположению пробных точек, совершенно ясно,. что основная цель построения множества таких точек заключается в определении направления, в котором должен вестись поиск. Расположение пробных точек влияет лишь на чувствительность направления поиска к изменениям топологических свойств целевой функции. В частности, уравнение для вычисления координат отраженной точки
x 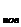 = x
= x  + λ( x
+ λ( x  – x
– x 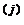 )
)
четко устанавливает, что множество отраженных точек описывается. вектором, определяющим некоторое направление в пространстве управляемых переменных. Остальные элементы логической структуры поиска связаны лишь с выбором такой величины шага λ, которая позволяет достигнуть заметного «улучшения» значений целевой функции. Если же главная задача работы с образцом, составленным из пробных точек, состоит в определении направления поиска, то стратегию поиска по симплексу можно усовершенствовать путем непосредственного введения множества векторов, задающих направления поиска. Простейший подход заключается в том, что поиск ведется на основе рекурсивного перебора направлений из произвольно заданного множества. С другой стороны, можно построить стратегию поиска, в рамках которой одно или несколько направлений поиска уточняются на каждой итерации, что позволяет согласовать систему направлений поиска с глобальной топологией целевой функции. Для того чтобы гарантировать возможность проведения поиска по всей рассматриваемой области, в обоих случаях целесообразно наложить требование линейной независимости направлений поиска, которые должны образовывать базис в допустимой области определения f(x). Например, легко убедиться в том, что нельзя вести поиск оптимума функции трех переменных с использованием двух направлений поиска. Отсюда следует, что все рассматриваемые методы прямого поиска используют по меньшей мере N независимых направлений поиска, где N— размерность вектора х.
Элементарным примером метода, в рамках которого реализуется процедура рекурсивного перебора на множестве направлений поиска, является метод циклического изменения переменных, в соответствии с которым каждый раз меняется только одна переменная. При таком подходе множество направлений поиска выбирается в виде множества координатных направлений в пространстве управляемых переменных задачи. Затем вдоль каждого из координатных направлений последовательно проводится поиск точки оптимума на основе методов решения задач оптимизации с одной переменной. Если целевая функция обладает свойством сферической симметрии, такой поиск обеспечивает получение решения исходной задачи. Однако если линии уровня функции искривлены или растянуты (что весьма часто имеет место в возникающих на практике задачах), то итерации могут превратиться в бесконечную последовательность уменьшающихся шагов и процедура поиска становится неэффективной. Кроме того, как показал Пауэлл [9], изменение координатных направлений поиска (или направлений поиска из любого заданного множества) в циклическом порядке может не только оказаться неэффективным, но и привести к отсутствию сходимости к точке локального оптимума даже при бесконечном числе итераций.
Конструктивные попытки повышения эффективности этого метода были связаны с тем обстоятельством, что поиск, периодически проводимый в направлении d(i) = x(i) – x(i-1) позволяет существенно ускорить сходимость. Это обстоятельство было положено в основу модифицированного метода, разработанного Хуком и Дживсом [10] и являющегося одним из первых алгоритмов, в которых при определении нового направления поиска учитывается информация, полученная на предыдущих итерациях. По существу процедура Хука — Дживса представляет собой комбинацию «исследующего» поиска с циклическим изменением переменных и ускоряющегося поиска по образцу с использованием определенных эвристических правил. Исследующий поиск ориентирован на выявление характера локального поведения целевой функции и определение направлений вдоль «оврагов». Полученная в результате исследующего поиска информация затем используется в процессе поиска по образцу при движении по «оврагам».
Исследующий поиск. Для проведения исследующего поиска необходимо задать величину шага, которая может быть различной для разных координатных направлений и изменяться в процессе поиска. Исследующий поиск начинается в некоторой исходной точке. Если значение целевой функции в пробной точке не превышает значения функции в исходной точке, то шаг поиска рассматривается как успешный. В противном случае необходимо вернуться в предыдущую точку и сделать шаг в противоположном направлении с последующей проверкой значения целевой функции. После перебора всех N координат исследующий поиск завершается. Полученную в результате точку называют базовой точкой.
Поиск по образцу. Поиск по образцу заключается в реализации единственного шага из полученной базовой точки вдоль прямой, соединяющей эту точку с предыдущей базовой точкой. Новая точка образца определяется в соответствии с формулой
x 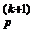 = x
= x  + (x – x
+ (x – x 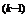 ). (3.24)
). (3.24)
Как только движение по образцу не приводит к уменьшению целевой функции, точка x фиксируется в качестве временной базовой точки и вновь проводится исследующий поиск. Если в результате получается точка с меньшим значением целевой функции, чем в точке x , то она рассматривается как новая базовая точка x 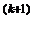 .С другой стороны, если исследующий поиск неудачен, необходимо вернуться в точку x , и провести исследующий поиск с целью выявления нового направления минимизации. В конечном счете возникает ситуация, когда такой поиск не приводит к успеху. В этом случае требуется уменьшить величину шага путем введения некоторого множителя и возобновить исследующий поиск. Поиск завершается, когда величина шага становится достаточно малой. Последовательность точек, получаемую в процессе реализации метода, можно записать в следующем виде:
.С другой стороны, если исследующий поиск неудачен, необходимо вернуться в точку x , и провести исследующий поиск с целью выявления нового направления минимизации. В конечном счете возникает ситуация, когда такой поиск не приводит к успеху. В этом случае требуется уменьшить величину шага путем введения некоторого множителя и возобновить исследующий поиск. Поиск завершается, когда величина шага становится достаточно малой. Последовательность точек, получаемую в процессе реализации метода, можно записать в следующем виде:
x текущая базовая точка,
x предыдущая базовая точка,
x точка, построенная при движении по образцу,
x следующая (новая) базовая точка.
Приведенная последовательность характеризует логическую структуру поиска по методу Хука — Дживса.
Метод поиска Хука — Дживса
Шаг 1. Определить:
начальную точку x 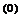
приращения ∆ 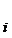 , i = l, 2, 3,..., N,
, i = l, 2, 3,..., N,
коэффициент уменьшения шага α > 1,
параметр окончания поиска ε > 0.
Шаг 2. Провести исследующий поиск.
Шаг 3. Был ли исследующий поиск удачным (найдена ли точка с меньшим значением целевой функции)?
Да: перейти к шагу 5.
Нет: продолжать.
Шаг 4. Проверка на окончание поиска. Выполняется ли неравенство || ∆x || < ε?
Да: прекратить поиск; текущая точка аппроксимирует точку оптимума х*.
Нет: уменьшить приращения по формуле
∆ = ∆ / α, i = 1, 2, 3,…, N,
Перейти к шагу 2.
Шаг 5. Провести поиск по образцу:
x = x + (x – x ).
Шаг 6. Провести исследующий поиск, используя x в качестве базовой точки; пусть x(k+1) — полученная в результате точка.
Шаг 7. Выполняется ли неравенство f(x(k+1})<f(x )?
Да: положить x = x(k), x(k) = x .
Перейти к шагу 5.
Нет: перейти к шагу 4.
Дата добавления: 2018-06-01; просмотров: 515; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!