Адаптивное арифметическое кодирование.
Для арифметического кодирования, как и для кодирования методом Хаффмана, существуют адаптивные алгоритмы. Реализация одного из них запатентована фирмой IBM.
Построение арифметического кода для последовательности символов из заданного множества можно реализовать следующим алгоритмом. Каждому символу сопоставляется его вес: вначале он для всех равен 1. Все символы располагаются в естественном порядке, например, по возрастанию. Вероятность каждого символа устанавливается равной его весу, деленному на суммарный вес всех символов. После получения очередного символа и постройки интервала для него, вес этого символа увеличивается на 1 (можно увеличивать вес любым регулярным способом).
Заданное множество символов - это, как правило, ASCII+. Для того, чтобы обеспечить остановку алгоритма распаковки вначале сжимаемого сообщения надо поставить его длину или ввести дополнительный символ-маркер конца сообщения. Если знать формат файла для сжатия, то вместо начального равномерного распределения весов можно выбрать распределение с учетом этих знаний. Например, в текстовом файле недопустимы ряд управляющих символов и их вес можно занулить.
Пример. Пусть заданное множество это символы А, В, С. Сжимаемое сообщение АССВСАААВС. Введем маркер конца сообщения Е. Кодирование согласно приведенному алгоритму можно провести согласно схеме, приведенной на рис. 7.
|
|
|

Вследствие того, что

Поэтому L1(ACCBCAAABC) = 2.2 бит/сим. Результат, полученный адаптивным алгоритмом Хаффмана - 4.1 бит/сим, но если кодировать буквы не 8битами, а 2, то результат будет 2.3 бит/сим. В первой строчке схемы выписаны суммарные веса символов, а во второй длины текущих отрезков.
Способ распаковки адаптивного арифметического кода почти аналогичен приведенному для неадаптивного. Отличие только в том, что на втором шаге после получения нового кода нужно перестроить разбиение единичного отрезка согласно новому распределению весов символов. Получение маркера конца или заданного началом сообщения числа символов означает окончание работы.
Пример. Распакуем код 0010111001010011101101, зная, что множество символов сообщения состоит из А, В, С и Е, причем последний это маркер конца сообщения. 0.00101110010100111011012 = 
| Веса | Число-код и его интервал Символ | Длина интервала | |||
| А | В | С | Е | ||
| 1 | 1 | 1 | 1 | 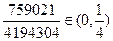 А А
| 
|
| 2 | 1 | 1 | 1 |  С С
| 
|
| 2 | 1 | 2 | 1 |  С С
| 
|
| 2 | 1 | 3 | 1 |  В В
| 
|
| 2 | 2 | 3 | 1 | 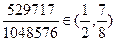 С С
| 
|
| 2 | 2 | 4 | 1 |  А А
| 
|
| 3 | 2 | 4 | 1 | 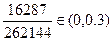 А А
| 0.3 |
| 4 | 2 | 4 | 1 | 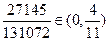 А А
| 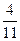
|
| 5 | 2 | 4 | 1 |  В В
| 
|
| 5 | 3 | 4 | 1 | 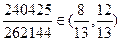 С С
| 
|
| 5 | 3 | 5 | 1 |  Е Е
| |
Лекция 7. Словарно-ориентированные алгоритмы сжатия.
|
|
|
Метод Лемпела-Зива LZ77.
Методы Шеннона-Фано, Хаффмана и арифметическое кодирование обобщающе называются статистическими методами. Словарные алгоритмы носят менее математически обоснованный, но более практичный характер.
Алгоритм LZ77 был опубликован в 1977 г. Разработан израильскими математиками Якобом Зивом (Ziv) и Авраамом Лемпелом (Leiupel). Многие программы сжатия информации используют ту или иную модификацию LZ77, Одной из причин популярности алгоритмов LZ является их исключительная простота при высокой эффективности сжатия.
Основная идея LZ77 состоит в том, что второе и последующие вхождения некоторой строки символов в сообщении заменяются ссылками на ее первое вхождение.
LZ77 использует уже просмотренную часть сообщения как словарь. Чтобы добиться сжатия, он пытается заменить очередной фрагмент сообщения на указатель в содержимое словаря.
|
|
|
LZ77 использует "скользящее'' по сообщению окно, разделенное на две неравные части. Первая, большая по размеру, включает уже просмотренную часть сообщения. Вторая, намного меньшая, является буфером, содержащим еще незакодированные символы входного потока. Обычно размер окна составляет несколько килобайт, а размер буфера не более ста байт. Алгоритм пытается найти в словаре (большей части окна) фрагмент, совпадающий с содержимым буфера.
Алгоритм LZ77 выдает коды, состоящие из трех элементов:
- смещение в словаре относительно его начала подстроки, совпадающей с началом содержимого буфера:
- длина этой подстроки:
- первый символ буфера, следующий за подстрокой.
Пример. Размер окна 20 символ, словаря 12 символов, а буфера 8. Кодируется сообщение ''ПРОГРАММНЫЕ ПРОДУКТЫ ФИРМЫ MICROSOFT". Пусть словарь уже заполнен. Тогда он содержит строку ''ПРОГРАММНЫЕ'' а буфер строку "ПРОДУКТЫ''. Просматривая словарь, алгоритм обнаружит, что совпадающей подстрокой будет "ПРО"; в словаре она расположена со смещением 0 и имеет длину 3 символа, а следующим символом в буфере является "Д", Таким образом, выходным кодом будет тройка (0,3,'Д'). После этого алгоритм сдвигает влево все содержимое окна на длину совпадающей подстроки + 1 и одновременно считывает столько же символов из входного потока в буфер). Получаем в словаре строку "РАММНЫЕ ПРОД", в буфере "УКТЫ ФИР". В данной ситуации совпадающей подстроки обнаружить не удаться и алгоритм выдаст код (0,0,'У'), после чего сдвинет окно на один символ. Затем словарь будет содержать "АММНЫЕ ПРОДУ", а буфер ''КТЫ ФИРМ'' и т.д.
|
|
|
Декодирование кодов LZ77 проще их получения, т.к. не нужно осуществлять поиск в словаре.
Недостатки LZ77:
1) с ростом размеров словаря скорость работы алгоритма-кодера пропорционально замедляется:
2) кодирование одиночных символов очень неэффективно.
Пример. Закодировать по алгоритму LZ77 строку "КРАСНАЯ КРАСКА",
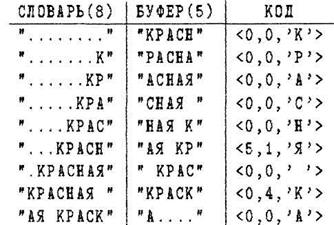
В последней строчке, буква "А" берется не из словаря, т.к. она последняя.
Длина кода вычисляется следующим образом: длина подстроки не может быть больше размера буфера, а смещение не может быть больше размера словаря —1. Следовательно, длина двоичного кода смещения будет округленным в большую сторону lоg2(размер словаря), а длина двоичного кода для длины подстроки будет округленным в большую сторону log2 (размер буфера+1). А символ кодируется 8 битами (например, ASCII+).
В последнем примере длина полученного кода равна 9*(3+3+8) = 126 бит, против 14 *8 = 112 бит исходной длины строки.
Метод LZ SS .
В 1982 г. Сторером (Storei) и Шиманским (Shimanski) на базе LZ77 был разработан алгоритм LZSS. который отличается от LZ77 производимыми кодами.
Код, выдаваемый LZSS, начинается с однобитного префикса, различающего собственно код от незакодированного символа. Код состоит из пары: смещение и длина, такими же как и для LZ77. В LZSS окно сдвигается ровно на длину найденной подстроки или на 1, если не найдено вхождение подстроки из буфера в словарь. Длина подстроки в LZSS всегда больше нуля, поэтому длина двоичного кода для длины подстроки это округленный до большего целого двоичный логарифм от длины буфера.
Пример. Закодировать по алгоритму LZSS строку "КРАСНАЯ КРАСКА".

Здесь длина полученного кода равна 7*9+ 4*7= 91 бит, LZ77 и LZSS обладают следующими очевидными недостатками:
1) невозможность кодирования подстрок, отстоящих друг от друга на расстоянии, большем длины словаря:
2) длина подстроки, которую можно закодировать. ограничена размером буфера.
Если механически чрезмерно увеличивать размеры словаря и буфера, то это приведет к снижению эффективности кодирования, т.к. с ростом этих величин будут расти и длины кодов для смещения и длины, что сделает коды для коротких подстрок недопустимо большими. Кроме того, резко увеличится время работы алгоритма-кодера.
В 1978 г. авторами LZ77 был разработан алгоритм LZ78, лишенный названных недостатков.
Метод LZ78.
LZ78 не использует "скользящее" окно, он хранит словарь из уже просмотренных фраз. При старте алгоритма этот словарь содержит только одну пустую строку (строку длины нуль). Алгоритм считывает символы сообщения до тех пор, пока накапливаемая подстрока входит целиком в одну из фраз словаря. Как только эта строка перестанет соответствовать хотя бы одной фразе словаря, алгоритм генерирует код, состоящий из индекса строки в словаре, которая до последнего ввезенного символа содержала входную строку, и символа, нарушившего совпадение. Затем в словарь добавляется введенная подстрока. Если словарь уже заполнен, то из него предварительно удаляют менее всех используемую в сравнениях фразу.
Ключевым для размера получаемых кодов является размер словаря во фразах, потому что каждый код при кодировании по методу LZ78 содержит номер фразы в словаре. Из последнего следует, что эти коды имеют постоянную длину, равную округленному в большую сторону двоичному логарифму размера словаря +8 (это количество бит в байт-коде расширенного ASCII),
Пример. Закодировать по алгоритму LZ78 строку "КРАСНАЯ КРАСКА", используя словарь длиной 16 фраз.
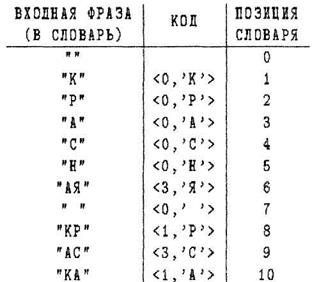
Указатель на любую фразу такого словаря - это число от 0 до 15, для его кодирования достаточно четырех бит.
В последнем примере длина полученного кода равна 10 * (4 + 8) = 120 битам.
Метод LZ W .
Алгоритмы LZ77, LZ78 и LZSS разработаны математиками и могут
использоваться свободно.
В 1984 г, Уэлчем (Welch) был путем модификации LZ78 создан алгоритм LZW.
Пошаговое описание алгоритма - кодера.
Шаг 1. Инициализация словаря всеми возможными односимвольными фразами (обычно 256 символами расширенного ASCII). Инициализация входной фразы w первым символом сообщения.
Шаг 2. Считать очередной символ К из кодируемого сообщения.
Шаг 3. Если КОНЕЦ-СООБЩЕНИЯ
Выдать код для w
Конец
Если фраза wK уже есть в словаре
Присвоить входной фразе значение wK
Перейти к III агу 2
Иначе
Выдать код w
Добавить wK в словарь
Присвоить входной фразе значение К
Перейти к Ш агу 2.
Как и в случае с LZ78 для LZW ключевым для размера получаемых кодов является размер словаря во фразах: LZW-коды имеют постоянную длину, равную округленному в большую сторону двоичному логарифму размера словаря.
Пример. Закодировать по алгоритму LZW строку "КРАСНАЯ КРАСКА". Размер словаря 500 фраз.
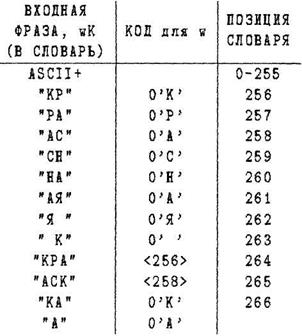
В этом примере длина полученного кода равна 12*9= 108 битам.
При переполнении словаря, т.е. когда необходимо внести новую фразу в полностью заполненный словарь, из него удаляют либо наиболее редко используемую фразу, либо все фразы, отличающиеся от одиночного символа.
Алгоритм LZW является запатентованным и, таким образом, представляет собой интеллектуальную собственность. Его безлицензионное использование особенно на аппаратном уровне может повлечь за собой неприятности.
Любопытна история патентования LZW. Заявку на LZW подали почти одновременно две фирмы сначала IBM и затем Unisys, но первой была рассмотрена заявка Unisys, которая и получила патент, Однако, еще до патентования LZW был использован в широко известной в мире Unix программе сжатия данных compress.
Дата добавления: 2022-01-22; просмотров: 34; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!