Семантическая информация в системах.
Одно и то же сообщение может по разному восприниматься в разных системах управления, разными приемниками информации. Для описания этих ситуаций полезно понятие о тезаурусе приемника, от состояния которого зависит возможность воспринять тот или иной фрагмент информации из данного сообщения и дать ему определенную интерпретацию в рамках данного тезауруса.
Семантическая информация возникает в процессе взаимодействия сообщения с данным тезаурусом. Тезаурус - одноязыковый толковый словарь. Тезаурус системы возникает как система репрезентаторов - способов представления сведения о действительности, в которой функционирует данная система. Он задает систему семантических связей понятий, объясняя каждое понятие через набор других.
При восприятии текста тезаурус человека может меняться. Человек с малыми предварительными знаниями получает мало информации. Человек, знающий почти все в данной предметной области, почти не получает новой информации. Различают не только количество воспринятого смысла, но и качество - уровень восприятия. Это тоже зависит от тезауруса.
Самый низкий уровень:
1). Синтаксический - понимание структуры текста (без смысла);
2). Поверхностно-семантический - буквальный смысл текста;
3). Глубинно-семантический метафорический смысл текста, его замысел, его ценностное
восприятие сообщения - художественные тексты;
4). Диалоговый - здесь понимание - процесс общения
|
|
|
В 50-х годах XX века появились первые попытки определения абсолютного информационного содержания предложений естественного языка. Стоит отметить, что сам Шеннон однажды заметил, что смысл сообщений не имеет никакого отношения к его теории информации, целиком построенной на положениях теории вероятностей. Но его способ точного измерения информации наводил на мысль о возможности существования способов точного измерения информации более общего вида, например, информации из предложений естественного языка. Примером одной из таких мер является функция lnf ( s )= - log2р(s), где s - это предложение, смысловое содержание которого измеряется, ( s ) вероятность истинности s.
Вот некоторые свойства этой функции-меры:
1) если 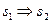 (из s1следует s 2)истинно, то inf ( s 1 ) ≥ inf ( s 2 );
(из s1следует s 2)истинно, то inf ( s 1 ) ≥ inf ( s 2 );
2) inf ( s ) ≥ 0;
3)если s истинно, то inf ( s ) = 0;
4) inf (s1 s2) = inf (s1)+inf (s2)  p (s1) p (s2) т.е.независимости s1 и s2..
p (s1) p (s2) т.е.независимости s1 и s2..
Значение этой функции-меры больше для предложений, исключающих большее количество возможностей.
Пример: из s1 “a>3” и s2 “a= 7" следует, что s2 s1или inf(s2) ≥ inf(s1); ясно, что s2 исключает больше возможностей, чем s1.
Для измерения семантической информации также используется функция-мера cont ( s ) = 1 – p (s).Ясно что cont (s) = 1-2-inf(s) или inf ( s ) =- log 2(1- cont ( s )).
|
|
|
Лекция 4. Сжатие информации.
Необратимое сжатие.
Сжатие информациипредставляет собой операцию, в результате которой данному коду или сообщению ставится в соответствие более короткий код или сообщение. Сжатие информации имеет целью - ускорение и удешевление процессов механизированной обработки, хранения и поиска информации, экономия памяти ЭВМ. При сжатии следует стремиться к минимальной неоднозначности кодов при максимальной простоте алгоритма сжатия. Таким образом, сжатие сокращает объем пространства, требуемого для хранения файлов в ЭВМ, и количество времени, необходимого для передачи информации по каналу установленной ширины пропускания. Это есть форма кодирования. Другими целями кодирования являются поиск и исправление ошибок, а также шифрование. Процесс поиска и исправления ошибок противоположен сжатию - он увеличивает избыточность данных, когда их не нужно представлять в удобной для восприятия человеком форме. Удаляя из текста избыточность, сжатие способствует шифрованию, что затрудняет поиск шифра доступным для взломщика статистическим методом.
Необратимое или ущербное сжатие используется для цифровой записи аналоговых сигналов, таких как человеческая речь или рисунки. Обратимое сжатие особенно важно для текстов, записанных на естественных и на искусственных языках, поскольку в этом случае ошибки обычно недопустимы. Хотя первоочередной областью применения рассматриваемых методов есть сжатие текстов, однако, эта техника может найти применение и в других случаях, включая обратимое кодирование последовательностей дискретных данных.
|
|
|
Существует много веских причин выделять ресурсы ЭВМ в расчете на сжатое представление, т.к. более быстрая передача данных и сокращение пространства для их хранения позволяют сберечь значительные средства и зачастую улучшить показатели ЭВМ. Сжатие, вероятно, будет оставаться в сфере внимания из-за все возрастающих объемов хранимых и передаваемых в ЭВМ данных, кроме того, его можно использовать для преодоления некоторых физических ограничений, таких как, например, сравнительно низкая ширину пропускания телефонных каналов.
Рассмотрим наиболее характерные методы сжатия информации.
Сжатие информации делением кода на части, меньшие некоторой наперед заданной величины А, заключается в том, что исходный код делится на части, меньшие А, после чего полученные части кода складываются между собой либо по правилам двоичной арифметики, либо по модулю 2. Например, исходный
|
|
|

Сжатие информации с побуквенным сдвигом в каждом разряде, как и предыдущий способ, не предусматривает восстановления сжимаемых кодов, а применяется лишь для сокращения адреса либо самого кода сжимаемого слова в памяти ЭВМ.
Предположим, исходное слово «газета» кодируется кодом, в котором длина кодовой комбинации буквы l = 8:
Г – 01000111; а – 11110000; з – 01100011; е – 00010111; т – 11011000.
Полный код слова «Газета» 010001111111000001100011000101111101100011110000.
Сжатие осуществляется сложением по модулю 2 двоичных кодов букв
сжимаемого слова с побуквенным сдвигом в каждом разряде.
11110000 а
11011000 т
00010111 е
01100011 з
11110000 а
01000111 г
___________________
1001100010 011 – сжатый код
Допустимое количество разрядов сжатого кода является вполне определенной величиной, зависящей от способа кодирования и от емкости ЗУ. Количество адресов, а соответственно максимальное количество слов в выделенном участке памяти машины определяется из следующего соотношения
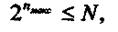
где nмакс- максимально допустимая длина (количество двоичных разрядов)
сжатого кода; N - возможное количество адресов в ЗУ.
Если представить процесс побуквенного сдвига в общем виде, то длина сжатого кода
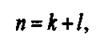
где к - число побуквенных сдвигов; l - длина кодовой комбинации буквы.
Так как сдвигаются все буквы, кроме первой, то и число сдвигов к = L -1, где L
- число букв в слове. Тогда
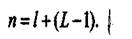
В русском языке наиболее длинные слова имеют 23 - 25 букв. Если принять L макс = 23, с условием осуществления побуквенного сдвига с каждым шагом ровно на один разряд, для пи/ могут быть получены следующие соотношения
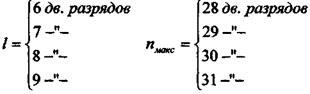
Если значение пмакс не удовлетворяет неравенству, можно конечные буквы слова складывать по модулю 2 без сдвига относительно предыдущей буквы.
Например, если для предыдущего примера со словом "Газета" nмакс =11, сжатый код будет иметь вид:

Метод сжатия информации на основе исключения повторения в старших разрядах последующих строк, массивов одинаковых элементов старших разрядов предыдущих строк массивов основан на том, что в сжатых массивах повторяющиеся элементы старших разрядов заменяются некоторым условным символом.
Очень часто обрабатываемая информация бывает представлена в виде набора однородных массивов, в которых элементы столбцов или строк массивов расположены в нарастающем порядке. Если считать старшими разряды, расположенные левее данного элемента, а младшими - расположенные правее, то можно заметить, что во многих случаях строки матриц отличаются друг от друга в младших разрядах. Если при записи каждого последующего элемента массива отбрасывать все повторяющиеся в предыдущем элементы, например в строке стоящие подряд элементы старших разрядов, то массивы могут быть сокращены от 2 до 10 и более разрядов.
Обратимое сжатие.
Алгоритмы обратимого сжатия могут повышать эффективность хранения и передачи данных посредством сокращения количества их избыточности. Алгоритм сжатия берет в качестве входа текст источника и производит соответствующий ему сжатый текст, когда как разворачивающий алгоритм имеет на входе сжатый текст и получает из него на выходе первоначальный текст источника. Большинство алгоритмов сжатия рассматривают исходный текст как набор строк, состоящих из букв алфавита исходного текста.
Избыточность в представлении строки S есть L(S) - H(S), где L(S) есть длина представления в битах, a H(S) - энтропия - мера содержания информации, также выраженная в битах. Алгоритмов, которые могли бы без потери информации сжать строку к меньшему числу бит, чем составляет ее энтропия, не существует.
Цель сжатия - уменьшение количества бит, необходимых для хранения или передачи заданной информации, что дает возможность передавать сообщения более быстро и хранить более экономно и оперативно (последнее означает, что операция извлечения данной информации с устройства ее хранения будет проходить быстрее, что возможно, если скорость распаковки данных выше скорости считывания данных с носителя информации). Сжатие позволяет, например, записать больше информации на дискету, "увеличить" размер жесткого диска, ускорить работу с модемом и т.д. При работе с компьютерами широко используются программы-архиваторы данных формата ZIP, GZ, ARJ и других. Методы сжатия информации были разработаны как математическая теория, которая долгое время (до первой половины 80-х годов), мало использовалась в компьютерах на практике.
Сжатие данных не может быть большим некоторого теоретического предела. Для формального определения этого предела рассматриваем любое информационное сообщение длины nкак последовательность независимых, одинаково распределенных д.с.в. Xi, или как выборки длины п значений одной д.с.в. X.
Доказано, что среднее количество бит, приходящихся на одно кодируемое значение д.с.в. не может быть меньшим, чем энтропия этой д.с.в., т.е. МL(X) ≥ HX для любой д.с.в. X и любого ее кода.
Кроме того, доказано [20] утверждение о том, что существует такое кодирование (Шеннона-Фэно, Fauo), что НХ ≥ М L ( X ) - 1.
Рассмотрим д. с в. Х1и A2, независимые и одинаково распределенные, НХ1= НХ2 и I(X1, X2) = 0, следовательно,
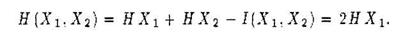
Вместо X1 и X2 можно говорить о двумерной д. с. в. 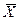 = (X1,X2). Аналогичным образом для n - мерной д. с.в. = (X1,X2 …Xn) можно получить, что H = n Xn
= (X1,X2). Аналогичным образом для n - мерной д. с.в. = (X1,X2 …Xn) можно получить, что H = n Xn
Пусть L 1( )= L ( )/ n , где = (X1,X2 …Xn), т.е. L 1( )это количество бит кода на единицу сообщения . Тогда М L 1 ( ) это среднее количество бит кода на единицу сообщения при передаче бесконечного множества сообщений . Из М L ( ) – 1 ≤ H ≤ М L ( ) для кода Шеннона - Фэно для следует М L 1 ( ) – 1/n ≤ H 1≤ М L 1 ( )для что го же кода.
Таким образом, доказана основная теорема о кодировании при отсутствии помех, а именно то, что с ростом длины п сообщения, при кодировании методом Шеннона - Фэно всего сообщения целиком среднее количество бит на единицу сообщения будет сколь угодно мало отличаться от энтропии единицы сообщения. Подобное кодирование практически не реализуемо из-за того, что сростом длины сообщения трудоемкость построения этого кода становится недопустимо большой. Кроме того, такое кодирование делает невозможным отправку сообщения по частям, что необходимо для непрерывных процессов передачи данных. Дополнительным недостатком этого способа кодирования является необходимость отправки или хранения собственно полученного кода вместе с его исходной длиной, что снижает эффект от сжатия. На практике для повышения степени сжатия используют Метод блокирования.
По выбранному значению е > 0 можно выбрать такое, что если разбить все сообщение на блоки длиной s (всего будет n / s блоков), то кодированием Шеннона-Фэно таких блоков, рассматриваемых как единицы сообщения, можно сделать среднее количество бит на единицу сообщения большим энтропии менее, чем на ε.
Действительно,пусть  и т.д.,
и т.д.,
т.е. Yi = 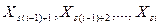 .
.
Тогда Н Y 1 = sHX1 и sML1(Y1)≤HY1+1=sHX1+1, следовательно.
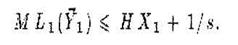
т.е. достаточно брать s =1/ε. Минимум s по заданному ε может быть гораздо меньшим 1/ε.
Пример. Пусть д.с.в. Х1 ,Х2 ,…,Х n независимы и одинаково распределены и могут принимать только два значения Р(Х i = 0) = р = 3/4 и Р(Х i = 1) = q =1/4 при i от 1 до n. Тогда
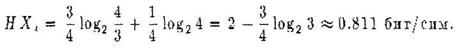
Минимальное кодирование здесь это коды 0 и 1 с длиной 1 бит каждый. При таком кодировании количество бит в среднем на единицу сообщения равно 1. Разобьем сообщение на блоки длины 2. Закон распределения вероятностей и кодирование для 2-мерной д.с.в. Х = (Х1 Х2)
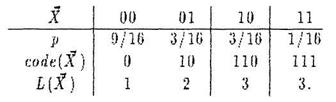
Тогда при таком минимальном кодировании количество бит в среднем на единицу сообщения будет уже

т.е. меньше, чем для неблочного кодирования. Для блоков длины 3 количество бит в среднем на единицу сообщения можно сделать ≈ 0,823, для блоков длины 4 ≈ 0,818 и т.д.
Все изложенное ранее подразумевало, что рассматриваемые д.с.в. кодируются только двумя значениями (обычно 0 и 1). Пусть д.с.в. кодируются m значениями. Тогда для д.с.в. Х и любого ее кодирования верно, что ML (Х) ≥ НХ / log2m и ML1(Х) ≥ HX1 / HX1 / log2m. Кроме того, существует кодирование такое, что ML ( X ) – 1 ≤ HX / log2m и ML 1( X )- 1/ n ≤HX 1 /log2m, где n = dim(X).
Формулы теоретических пределов уровня сжатия, рассмотренные ранее, задают предел для средней длины кода на единицу сообщений, передаваемых много раз, т.е. они ничего не говорят о нижней границе уровня сжатия, которая может достигаться на некоторых сообщениях и быть меньшей энтропии д.с.в., реализующей сообщение.
Дата добавления: 2022-01-22; просмотров: 34; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!