Помехозащитное кодирование в двоичном симметричном канале.
Простейший код для борьбы с шумом это контроль четности, он, в частности, широко используется в модемах. Кодирование заключается в добавлении к каждому байту девятого бита таким образом, чтобы дополнить количество единиц в байте до заранее выбранного для кода четного (even) или нечетного (odd) значения. Используя этот код, можно лишь обнаруживать большинство ошибок.
Простейший код, исправляющий ошибки, это тройное повторение каждого бита. Если с ошибкой произойдет передача одного бита из трех, то ошибка будет исправлена, но если случится двойная или тройная ошибка, то будут получены неправильные данные. Часто коды для исправления ошибок используют совместно с кодами для обнаружения ошибок. При тройном повторении для повышения надежности три бита располагают не подряд, а на фиксированном расстоянии друг от друга. Использование тройного повторения значительно снижает скорость передачи данных.
Двоичный симметричный канал изображен на рис, 13, где р это вероятность безошибочной передачи бита, a q вероятность передачи бита с ошибкой. Предполагается, что в таком канале ошибки происходят независимо. Далее рассматриваются только такие каналы.
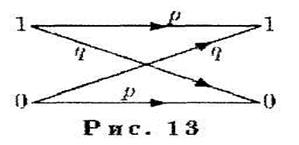
Двоичный симметричный канал реализует схему Бернулли, поэтому вероятность передачи nбит по двоичному симметричному каналу с kошибками равна 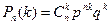 .
.
Пример. Вероятность передачи одного бита информации с ошибкой равна q= 0.01 и нас интересует вероятность безошибочной передачи 1000 бит (125 байт). Искомую вероятность можно подсчитать по формуле Р1000(0) = 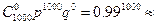 4.32* 10-5, т.е. она ничтожно мала.
4.32* 10-5, т.е. она ничтожно мала.
|
|
|
Добиться минимальности вероятности ошибки при передаче данных можно используя специальные коды. Обычно используют систематические помехозащитные коды. Идея систематических кодов состоит в добавлении к символам исходных кодов, предназначенных для передачи в канале, нескольких контрольных символов по определенной схеме кодирования. Принятая такая удлиненная последовательность кодов декодируется по схеме декодирования в первоначально переданную. Приемник способен распознавать и/или исправлять ошибки, вызванные шумом, анализируя дополнительную информацию, содержащуюся в удлиненных кодах.
Коды делятся на два больших класса. Коды с исправлением ошибок имеют целью восстановить с вероятностью, близкой к единице, посланное сообщение. Коды с обнаружением ошибок имеют целью выявить с вероятностью, близкой к единице, наличие ошибок.
Простой код с обнаружением ошибок основан на схеме проверки четности, применимой к сообщениям а1 ... а т любой фиксированной длины т.. Схема кодирования определяется следующими формулами:
|
|
|
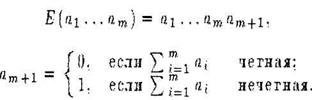
таким образом, 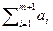 должна быть четной.
должна быть четной.
Соответствующая схема декодирования тривиальна:
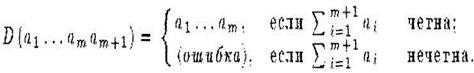
Разумеется, что четность не гарантирует безошибочной передачи.
Пример. Проверки четности при т = 2 реализуется следующим кодом (функцией Е): 00→000, 01→011, 10→101, 11→110. В двоичном симметричном канале доля неверно принятых сообщений для этого кода (хотя бы с одной ошибкой) равна q 3 +3 pq 2+3p2q (три, две или одна ошибка соответственно). Из них незамеченными окажутся только ошибки точно в двух битах, не изменяющие четности. Вероятность таких ошибок 3 pq 2 . Вероятность ошибочной передачи сообщения из двух битов равна 2 pq + q 2 . При малых q верно, что 3 pq 2 « 2 pq +q2.
Рассмотрим (m,Зm)-код с тройным повторением. Коды с повторениями очень неэффективны, но полезны в качестве теоретического примера кодов, исправляющих ошибки. Любое сообщение разбивается на блоки длиной mкаждое и каждый блок передается трижды что определяет функцию E. Функция D определяется следующим образом. Принятая строка разбивается на блоки длиной 3m. Бит с номером i (1 ≤ i ≤ m) в декодированном блоке получается из анализа битов с номерами i, i+m, i +2 m в полученном блоке: берется тот бит из трех, который встречается не менее двух paз. Вероятность того, что бит в данной позиции будет принят трижды правильно равна р3. Вероятность одной ошибки в тропке равна 3p 2 q . Поэтому вероятность правильного приема одного бита равна р3 + 3 p 2 q . Аналогичным образом получается, что вероятность приема ошибочного бита равна q3 + 3 pq 2 .
|
|
|
Пример. Предположим q = 0,1. Тогда вероятность ошибки при передачи одного бита 0,028, т.е. этот код снижает вероятность ошибки с 10% до 2,8%. Подобным образом организованная передача с пятикратным повторением даст вероятность ошибки на бит
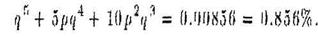
т.е. менее 1%. В результате вероятность правильной передачи строки длиной 10 возрастет с 0,910 ≈ 35% до 0,97210 ≈ 75% при тройных повторениях и до 0,9914410 ≈ 92% при пятикратных повторениях.
Тройное повторение обеспечивает исправление одной ошибки в каждой позиции за счет трехкратного увеличения времени передачи.
Рассмотрим (2048, 2313)-код, используемый при записи данных на магнитофонную ленту компьютерами Apple II, К каждому байту исходных данных прибавляется бит четности и, кроме того, после каждых таких расширенных битом четности 256 байт добавляется специальный байт, также расширенный битом четности. Этот специальный байт, который называют контрольной суммой, (check sum), есть результат применения поразрядной логической операции "исключающее ИЛИ" (XOR) к 256 предшествующим расширенным байтам. Этот код способен как обнаруживать ошибки нечетной кратности в каждом из отдельных байтов, так и исправлять до 8 ошибок в блоке длиной 256 байт. Исправление ошибок основано на том, что если в одном из бит одного из байт 256 байтового блока произойдет сбой, обнаруживаемый проверкой четности, то этот же сбой проявится и в том, что результат операции "исключающее ИЛИ" над всеми соответствующими битами блока не будет соответствовать соответствующему биту контрольной суммы. Сбойный бит однозначно определяется пересечением сбойных колонки байта и строки бита контрольной суммы. На рис. 15 изображена схема участка ленты, содержащего ровно 9 ошибок в позициях.
|
|
|
обозначенных р1, р2,.....,р9. Расширенный байт контрольной суммы
обозначен CS,a бит паритета (в данном случае четности) РВ (parity bit). Ошибка в позиции р1 может быть исправлена. Ошибки в по позициях р4, р5, р6, р7 ,можно обнаружить, но не исправить. Ошибки в позициях р2, р3, р8, р9, невозможно даже обнаружить.

Приведенные ранее примеры простейших кодов принадлежат к классу блочных. По определению, блочный код заменяет каждый блок из mсимволов более длинным блоком из nсимволов. Следовательно, (m, n)-коды являются блочными. Существуют также древовидные или последовательные коды, в которых значение очередного символа зависит от всего предшествующего фрагмента сообщения. Работа с древовидным шумозащитным кодом имеет сходство с работой с арифметическим кодом для сжатия информации.
Расстоянием (Хэмминга) между двоичными словами длины nназывается количество позиций, в которых эти слова различаются. Это одно из ключевых понятий теории кодирования. Если обозначить двоичные слова как а=а1…а n и b = b 1 … bn , то расстояние между ними обозначается d ( a , b ).
Весом двоичного слова = а=а1…а n , называется количество единиц в нем. Обозначение u(а). Можно сказать, что 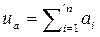
Пример. Пусть а = 1001 и b = 0011, тогда u ( a ) = u ( b ) = 2, d ( a , b ) = 2.
Далее операция + при применении к двоичным словам будет означать поразрядное сложение без переноса, т.е. сложение по модулю 2 или "исключающее ИЛ И" (XOR).
Расстояние, между двоичными словами а и b равно весу их поразрядной суммы, т.е. d ( a , b ) = и(а +b).
Если два слова различаются в каком-либо разряде, то это добавит единицу к весу их поразрядной суммы.
Следовательно, если а и b слова длины,то вероятность того, что слово а будет принято как b,равна 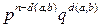
Например, вероятность того, что слово 1011 будет принято как 0011, равна p 3 q .
Для возможности обнаружения ошибки в одной позиции минимальное расстояние между словами кода должно быть большим 1.
Иначе ошибка в одной позиции сможет превратить одно кодовое слово в другое, что не даст ее обнаружить.
Для того, чтобы код давал возможность обнаруживать все ошибки кратности, не большей к, необходимо и достаточно, чтобы наименьшее расстояние между его словами было к + 1.
Достаточность доказывается конструктивно: если условие утверждения выполнено на Е, то в качестве декодирующей функции D следует взять функцию, сообщающую об ошибке, если декодируемое слово отличается от любого из слов из образа Е. Необходимость доказывается от противного: если минимальное расстояние к’ < к + 1, то ошибка в к! позициях сможет превратить одно кодовое слово в другое.
Для такого кода вероятность того, что ошибки в сообщении останутся необнаруженными, равна
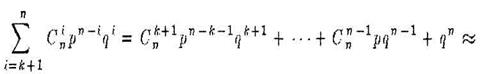
≈ (при малых q и не слишком маленьких k 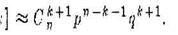
для того чтобы код давал возможность исправлять все ошибки кратности, не большей к, необходимо и достаточно, чтобы наименьшее расстояние между его словами было 2к + 1.
Достаточность доказывается конструктивно: если условие утверждения выполнено на Е, то в качестве декодирующей функции D следует взять функцию, возвращающую ближайшее к декодируемому слово из образа Е. Необходимость доказывается от противного. Пусть расстояние между выбранными словами в коде равно 2k. Тогда если при передаче каждого из этих слов случится к ошибок, которые изменят биты, в которых различаются эти слова, то
приемник получит два идентичных сообщения, что свидетельствует о том, что в данной ситуации исправление kошибок невозможно. Следовательно, минимальное расстояние между словами кода должно быть большим 2 k .
Пример. Рассмотрим (1.3)-код, состоящий из Е, задающей отображение 0→ 000 и 1→111, и D , задающей отображение 000 →0,001→0,010→0,011→1,100→ 0,101→1,110→1,111→1. Этот код (с тройным повторением) исправляет ошибки в одной позиции, т.к. минимальное расстояние между словами кода равно 3.
Если код исправляет все ошибки кратности kи меньшей, то вероятность ошибочного приема слова длины п очевидно не превосходит 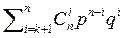 . Вероятность правильного приема в этом случае не меньше, чем
. Вероятность правильного приема в этом случае не меньше, чем
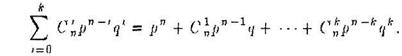
Передачу данных часто удобно рассматривать следующим образом. Пусть исходное сообщение а=а1…а m кодируется функцией Е в кодовое слово b = b 1 … bn .Канал связи при передаче добавляет к нему функцией Т строку ошибок е = е1…е n так, что приемник получает сообщение r = r 1 .. . rn где ri = bi + ei (1≤ i ≤ n ), Система, исправляющая ошибки, переводит rв некоторое (обычно ближайшее) кодовое слово. Система, только обнаруживающая ошибки, лишь проверяет, является ли принятое слово кодовым, и сигнализирует о наличии ошибки, если что не так.
Пример. Пусть передаваемое слово а = 01 кодируется словом b= 0110, а строка ошибок е = 0010. Тогда будет принято слово r = 0100. Система, исправляющая ошибки, переведет его в 0110 и затем восстановит переданное слово 01.
Eсли система только обнаруживает ошибки и расстояние между любыми кодовыми словами k ≥ 2, то любая строка ошибок е с единственной единицей приведет к слову r = b + e . которое не является кодовым.
Пример. Рассмотрим (2, 3)- код с проверкой четности. Множество кодовых слов {000, 011, 101,110}. Ни одна изстрок ошибок 001, 010, 101, 111 не переводит одно кодовое слово в другое. Поэтому однократная и тройная ошибки могут быть обнаружены.
Пример. Следующий (2,5)-код обнаруживает две ошибки:
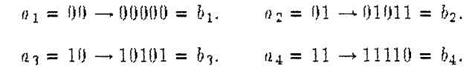
Этот же код способен исправлять однократную ошибку, потому что любые два кодовых слова отличаются по меньшей мере в трех позициях. Из того, что d ( bi , bj ) ≥ 3 при i ≠ j, следует, что однократная ошибка приведет к приему слова, которое находится на расстоянии 1 от кодового слова, которое было передано. Поэтому схема декодирования, состоящая в том, что принятое слово переводится в ближайшее к нему кодовое, будет исправлять однократную ошибку. В двоичном симметричном канале вероятность правильной передачи одного блока будет не меньше чем р5 +5р4 q
Установлено (20), что в (п – r , n )- коде, минимальное расстояние между кодовыми словами которого 2 k +1, числа n , r (число дополнительных разрядов в кодовых словах) и kдолжны соответствовать неравенству
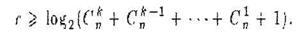
называемому неравенством или нижней границей Хэмминга. Кроме того, если числа n, rи kсоответствуют неравенству
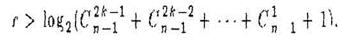
называемому неравенством или верхней границей Варшамова-Гильберта, то существует (п – r , n )- код, исправляющий все ошибки веса kи менее [20].
Нижняя граница задает необходимое условие для помехозащитного кода с заданными характеристиками, т.е. любой такой код должен ему соответствовать, но не всегда можно построить код по подобранным, удовлетворяющим условию характеристикам. Верхняя граница задает достаточное условие для существования помехозащитного кода с заданными характеристиками, т.е. по любым подобранным, удовлетворяющим условию характеристикам можно построить им соответствующий код.
Дата добавления: 2022-01-22; просмотров: 74; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!