Часть таблицы случайных чисел
| 37 | 52 | 35 | 15 | 04 | 80 | 17 |
| 21 | 28 | 31 | 42 | 46 | 72 | 43 |
| 07 | 99 | 95 | 64 | 13 | 06 | 92 |
| 10 | 16 | 69 | 93 | 39 | 08 | 76 |
| 00 | 84 | 65 | 56 | 09 | 29 | 11 |
Если мы имеем, скажем, популяцию (т.е. генеральную совокупность) из 1507 элементов и хотим спроектировать выборку численностью 150 элементов, мы можем выбирать любые два смежных столбца в таблице случайных чисел. Каждый раз, когда будет появляться число от 0001 до 1507, мы будем считать, что оно обозначает номер отбираемого элемента. Если число появляется более чем один раз, этот номер игнорируется после первого раза. Если мы начнем с первых четырех столбцов в табл.3.1, спускаясь по столбцам, то в выборку будут включены элементы под номерами 0799, 1016, 0084, 0480 и 1306. Если же генеральная совокупность насчитывает, например, 10000 элементов, то мы можем не ограничивать номер выбора, полученного комбинацией случайных чисел. Поскольку мы не стремимся умышленно отыскать определенное число, мы можем начать с любого места таблицы и использовать любую систему для движения по таблице. С тем же успехом случайные числа могут генерироваться специальной программой компьютера.
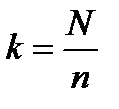
На практике чаще всего используют метод систематической (или механической) выборки, когда из пронумерованного списка через равные интервалы k отбирается заданное число респондентов. При этом шаг выборки k рассчитывается по простой формуле:
где N – численность генеральной совокупности, n – численность выборочной совокупности.
Предположим, например, что нам нужно спроектировать выборку численностью 100 из списка 5000 студентов какого-то вуза. Если мы намерены использовать систематическую выборку, то должны вначале рассчитать интервал выборки путем деления числа элементов в списке на размер выборки. В данном случае, разделив 5000 имен на требуемый размер выборки 100 единиц, мы получим интервал (шаг) выборки 50. Так что мы будем систематически двигаться по списку и отбирать каждого пятидесятого студента (отобрав таким образом 100 имен). Определение того места в списке, с которого мы начнем, проводится случайным образом, по таблице случайных чисел (это называется случайный старт). Таким образом, если случайно выбрана точка старта под номером 31, то в выборку будут включены студенты, стоящие под номерами 31, 81, 131, 181 и т.д.
Несмотря на свои преимущества, систематическая выборка может иногда иметь своим результатом предубежденную выборку. Такая ситуация возникает, например, когда элементы размещены в списке, ранжированном по каким-то заданным характеристикам. В этой ситуации само определение места начала случайного отбора будет влиять на средние характеристики всей выборки. Например, если студенты расставлены в списке в соответствии со средним оценочным баллом от высшего к низшему, систематическая выборка, включающая студентов, стоящих в списке под номерами 1, 51, 101 будет иметь более низкий средний балл, нежели выборка, включающая студентов под номерами 50, 100 и 150. Каждая новая выборка – с иным случайным стартом – будет давать другой средний балл, который представляет собой предубежденную картину студенческой популяции. Можно привести также пример опроса военнослужащих, проведенного американскими социологами во время второй мировой войны. Список солдат был распределен по отделениям, которые, в свою очередь, были ранжированы по званиям. Размеры как шага выборки, так и отделения, были равны десяти. Следовательно, выборка состояла из тех, кто имел одно и то же звание. Ясно, что одни лишь сержанты не могли быть репрезентативны ко всем солдатам, служившим в период второй мировой войны.
Еще одной проблемой, с которой может столкнуться исследователь, производя расчет систематической выборки, – неполнота списка элементов генеральной совокупности. Классический пример, который обычно приводят во многих учебниках по прикладной социологии, – расчет выборки для опроса, проведенного накануне президентских выборов в США, по заказу авторитетного издания Literary Digest в 1936 г. Размеры выборки были гигантскими даже по современным масштабам – 4 миллиона избирателей. Результаты этого опроса предсказывали победу на президентских выборах не Франклину Д. Рузвельту, а его сопернику Альфу Ландону. Этот подсчет голосов был основан (как выяснилось позднее, довольно опрометчиво) на выборке, спроектированной на основе телефонных книг и списков регистрации автомобилей. В то время обладание телефоном и автомобилем не было столь широко распространено среди американцев, как в наши дни. Таким образом, остов выборки существенно завышал репрезентативность по уровню благосостояния. К этой проблеме к тому же добавлялся тот факт, что в разгаре Великой Депрессии в голосовании прияло участие беспрецедентное число бедняков (обычно игнорировавших выборы), и они в подавляющем большинстве голосовали за Рузвельта. А Джордж Гэллап, проводивший опрос по выборке в 40 раз меньшей, сумел предсказать правильный результат.
Для обеспечения однородности (о значении которой для достоверности полученных данных речь пойдет ниже) иногда прибегают к стратифицированной выборке – по-другому ее называют еще районированной, – когда генеральную совокупность разделяют на отдельные страты[46][4], более или менее однородные по своему составу, а затем из каждой страты производится расчет методом простой случайной (систематической) выборки. “Допустим, социолог изучает статистическую зависимость между уровнем дохода и удовлетворенностью жизнью. Для этой цели достаточно взять всего три небольших группы респондентов: с максимально возможным в данном обществе доходом, минимальным и средним. Поскольку таким образом будет учтен весь возможный диапазон уровней дохода, то результаты исследования будут репрезентативны для всего общества”[47][5].
Дата добавления: 2020-12-22; просмотров: 184; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!