Глава 3. ОЦЕНКА КАЧЕСТВА СПЕЦИФИКАЦИИ МОДЕЛИ
Анализ погрешностей исходной информации
Значения экономических показателей обычно известны неточно, с некоторой погрешностью. Рассмотрим основные правила обработки данных, содержащих погрешности, или ошибки измерений. Пусть число a представляет точное (неизвестное нам) значение некоторой величины, а xi ( i=1,2,…, n) – известные приближенные значения той же величины, при этом
xi= a+e i , (12.1)
где e i – погрешность i-го измерения. Значения погрешностей e i нам неизвестны, т.к. неизвестно точное значение a, но, как правило, удается оценить модуль разности
| xi – a|<e . (12.2)
Величину e > 0 называют предельной абсолютной погрешностью, или короче, абсолютной погрешностью. Если a≠0 , то можно ввести относительную погрешность
δ=e /| a|. На практике величину относительной погрешности вычисляют по формуле
δ =e /| 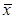 |, полагая
|, полагая
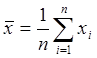 . (12.3)
. (12.3)
Принято использовать запись a= x ±e как условную запись неравенства
x-e< a< x+e (12.4)
и запись a= x(1 ±δ) как сокращенную запись неравенств
x(1-δ)< a< x(1+δ) . (12.5)
|
|
|
Величина относительной погрешности δ связана с числом верных десятичных знаков числа x. Рассмотрим этот вопрос на простых примерах. Число a=51.0±0.5 имеет два верных десятичных знака. Поэтому относительная погрешность δ=0.5/51≈0.01 или 1%. Число b=0.51±0.005 также имеет два верных знака и ту же относительную погрешность δ=1%. Если число задается с тремя верными знаками, то относительная погрешность будет иметь порядок 0.1%. Например, если a=510±0.5, то δ=0.001 или 0.1%. Рассматривая в качестве примеров числа 110 и 910 (с тремя верными знаками), нетрудно проверить, что относительная погрешность δ этих величин будет меняться в пределе от 0.05% до 0.5%. При двух верных десятичных знаках относительная погрешность изменяется в диапазоне 0.5% ¸5%.
Различают погрешности (ошибки) систематические и случайные. Если часы спешат или отстают, то они показывают время с некоторой систематической ошибкой. Для ее устранения нужно узнать точное время и выставить часы правильно. В общем случае для устранения систематической ошибки либо заменяют измерительный прибор на более точный, либо вводят поправку на систематическую ошибку (в астрономии, навигации и т.п.).
|
|
|
Анализ случайных ошибок проводится с применением методов теории вероятности и математической статистики. Пусть величина e i в равенстве (12.1) является случайной величиной, распределенной по нормальному закону с математическим ожиданием Ee i=0 и дисперсией De i =s 2, что принято записывать как e i Î N(0, s 2).
Измеренные значения xi также являются случайными величинами, при этом Exi= a, Dxi=s 2. Интуиция подсказывает нам, что среднее арифметическое (12.3) является лучшей оценкой для величины a, чемотдельные наблюдения xi . Действительно, 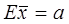 - оценка является несмещенной, а дисперсия среднего
- оценка является несмещенной, а дисперсия среднего 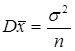 при n®∞ стремится к нулю. Величину дисперсии измерений s 2 можно оценить по данным xi известными формулами
при n®∞ стремится к нулю. Величину дисперсии измерений s 2 можно оценить по данным xi известными формулами
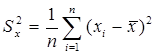 (12.5)
(12.5)
или
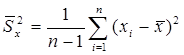 (12.6)
(12.6)
При этом оценка (12.5) является смещенной оценкой дисперсии s 2, так как известно [3], что 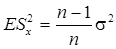 . Оценка (12.6) несмещенная:
. Оценка (12.6) несмещенная: 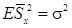 . В теории ошибок величина
. В теории ошибок величина 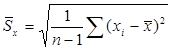 называют средней квадратичной ошибкой серии наблюдений {xi}, а величина
называют средней квадратичной ошибкой серии наблюдений {xi}, а величина 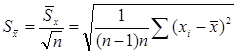 - средней квадратичной ошибкой среднего арифметического.
- средней квадратичной ошибкой среднего арифметического.
Доверительные интервалы
|
|
|
Введем случайную величину
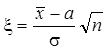 . (13.1)
. (13.1)
Нетрудно проверить, что x ÎN(0,1), вследствие чего
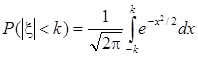 .
.
Полагая 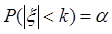 , получим после элементарных преобразований, что с
, получим после элементарных преобразований, что с
вероятностью a выполняется неравенство
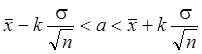 . (13.2)
. (13.2)
Интервал 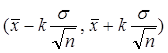 называется доверительным интервалом, отвечающим доверительной вероятности a . Если, к примеру, k=2, доверительная вероятность a=0.955. Значению k=3 отвечает вероятность a = 0.997 (правило «трех сигм»). Но для использования указанных доверительных интервалов на практике нужно знать стандартное отклонение s. Если значение s неизвестно, для его оценки используется величина
называется доверительным интервалом, отвечающим доверительной вероятности a . Если, к примеру, k=2, доверительная вероятность a=0.955. Значению k=3 отвечает вероятность a = 0.997 (правило «трех сигм»). Но для использования указанных доверительных интервалов на практике нужно знать стандартное отклонение s. Если значение s неизвестно, для его оценки используется величина 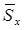 . В этом случае можно ввести случайную величину
. В этом случае можно ввести случайную величину
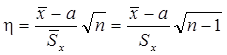 ,
,
которая имеет распределение Стьюдента с n-1 степенью свободы [3]. Не выписывая здесь соответствующей функции распределения, приведем несколько значений доверительной вероятности a( k, n), отвечающих доверительному интервалу
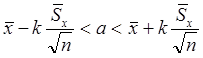 . (13.3)
. (13.3)
При k=2 и n=3 имеем a=0.817; при k=2 и n=7 вероятность a=0.908 ;
a(3,3)=0.905; a(3,5)=0.96. С ростом n различие между распределением Стьюдента и Гауссовым распределением становится меньше, при n=20 этим различием в большинстве случаев можно пренебречь.
|
|
|
Регрессионные модели мы строим по данным наблюдениям (x i, yi), i = 1,2,....n. Пусть значения x = x* не совпадают с x i. Чему будет равна величина y = y* и с какой погрешностью ее можно найти?
Попытаемся ответить на этот вопрос для случая парной линейной регрессии с нулевым свободным членом
yi = bxi + ei ,
где ei Î N(0,s), i = 1,2...n.
Параметр b оцениваем методом наименьших квадратов:
Sei2 = S(bxi – yi)2 ® min,
S(bxi – yi)xi = 0,
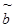 =
= 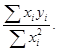 (13.4)
(13.4)
Из формулы (13.4) следует, что оценка 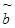 является гауссовой случайной величиной с математическим ожиданием
является гауссовой случайной величиной с математическим ожиданием
E 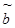 =
= 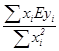 =
= 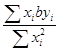 = b
= b
(оценка несмещенная) и дисперсией
D = 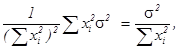 (13.5)
(13.5)
Величина σ2 , как правило, неизвестна и ее следует оценить. Для этого составим сумму квадратов ошибок
Sei2 = S(bxi – yi)2 = S(bxi – xi + xi - yi)2 =
= Sxi2(b- )2 + Σ( xi –yi)2+ 2Sxi(b- )( xi- yi). (13.6)
Математическое ожидание ESei2 = SЕei2 = nσ2.
Вычисление математического ожидания в правой части равенства (13.6) дает
Sxi2 D + EΣ( xi –yi)2,
так как математическое ожидание последнего слагаемого равно нулю. Поэтому
nσ2 = Sxi2 D 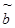 + EΣ( xi –yi)2.
+ EΣ( xi –yi)2.
С учетом формулы (13.5) получим
(n-1)σ2 = EΣ( xi –yi)2 .
Теперь ясно, что величина
S 2 = 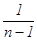 Σ( xi –yi)2 (13.7)
Σ( xi –yi)2 (13.7)
будет несмещенной оценкой для σ2. Множитель (n-1) указывает на то, что, располагая только одним наблюдением (x1, y1), нельзя получить оценку S 2, так как возникает неопределенность вида 0/0.
Для определения доверительного интервала оценки , отвечающего доверительной вероятности α, рассмотрим случайную величину
ξ = ( b- ) 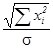 ,
,
имеющую нормальное распределение N(0,1). Заменив σ оценкой S , придем к случайной величине
η = ( b- ) 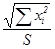 ,
,
имеющей распределение Стьюдента с (n-1) степенями свободы. Для прогнозируемого значения y* регрессионная модель дает значение
y* = x* + e,
при этом Ey* = bx*, Dy*=( x*)2D + De = σ2 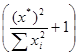 .
. 
Заменим дисперсию σ2 оценкой S2 из (13.7):
( Sy*)2 = S 2 .
Доверительный интервал для прогнозируемых величин y* будет определяться распределением Стьюдента. Его границы вычисляются по формуле
y = y* ± Sy* t( n-1, 1-a/2),
где a - доверительная вероятность (например, a = 0,95), (n-1) – число степеней свободы. Статистические пакеты вычисляют эти границы и дают их графическое представление.
Совершенно аналогично рассматривается общий случай множественной линейной регрессии
y = Fq + e.
Можно показать, что
Dy* = ( x*) T Q x* + s2,
где xi = (x1,x2,...xn)*; Q = cov q = s2(FTF)-1. Поэтому
Dy* = s2[( x*) T (FTF)-1x* +1].
Несмещенной оценкой для s 2 является число
S 2 = 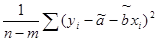 . (13.8)
. (13.8)
Поэтому оценка среднеквадратичного отклонения y* будет
Sy* = S[( x*) T (FTF)-1x* +1]1/2,
а граница доверительного интервала
y = y* ± Sy* t( n- m, 1-a/2).
Расчет погрешностей
Эмпирические данные часто подвергаются математической обработке – над ними
выполняются арифметические операции сложения, вычитания, умножения и деления, в некоторых случаях производится логарифмирование, возведение в степень и др. Как это может сказаться на погрешности результата?
Покажем, что абсолютная погрешность суммы не превосходит суммы абсолютных погрешностей слагаемых. Пусть S= x+ y, причем слагаемые x, y известны с абсолютной погрешностью ex,ey, так что
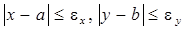 ,
,
где a и b – точные значения слагаемых. Для вычисления абсолютной погрешности суммы S оценим разность:
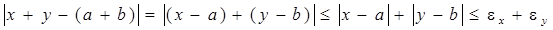 .
.
Ясно, что в качестве предельной абсолютной погрешности суммы можно принять величину
eS = ex+ey . (14.1)
Аналогично проверяется, что абсолютная погрешность разности двух чисел d= x- y равна сумме абсолютных погрешностей уменьшаемого и вычитаемого: ed = ex+ey. Заметим, что если числа x и y мало отличаются между собой, относительная погрешность их разности dd=ed / | x- y| может оказаться весьма большой.
При вычислении суммы S= x1+ x2+…+ xn большого числа слагаемых, имеющих одинаковую абсолютную погрешность e, в соответствии с формулой (14.1) имеем
eS = ne . (14.2)
При n>>1 величина eS может оказаться довольно большой. Но эта оценка получается в
предположении, что ошибки всех слагаемых максимальны и имеют одинаковый знак, что представляется мало вероятным. Более естественным выглядит предположение, что ошибка e является случайной и распределена по нормальному закону 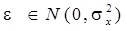 , причем ошибки отдельных слагаемых являются независимыми случайными величинами. По правилу вычисления дисперсии сумма независимых случайных величин находим, что:
, причем ошибки отдельных слагаемых являются независимыми случайными величинами. По правилу вычисления дисперсии сумма независимых случайных величин находим, что: 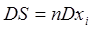 или
или 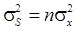 , так что
, так что 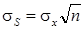 .
.
При больших n (например, n=100) статистическая оценка дает значительно меньшее значение, чем предельная (14.2). Напомним, что отклонение случайной величины S от истинного значения более чем на 2 s S возможно с вероятностью 0,045 (4,5%), а на 3sS – с вероятностью 0,003 или 0,3%.
Для вычисления погрешности произведения и частного двух положительных чисел x, y рассмотрим сначала общий случай функции двух переменных u= f( x, y) (аналогично рассматривается случай функций многих переменных). Пусть переменная x известна с погрешностью ex, переменная y – с погрешностью ey. Приращение функции Du заменим дифференциалом
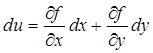 , (14.3)
, (14.3)
полагая величины e x и e y достаточно малыми. Отсюда следует, что абсолютная погрешность e u функции u оценивается по формуле:
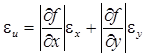 . (14.4)
. (14.4)
В статистической теории предполагают ошибки ex и ey независимыми случайными величинами. Для дисперсии величины du имеем формулу
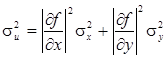 . (14.5)
. (14.5)
В случае произведения двух положительных чисел u= xy формула (14.4) дает оценку
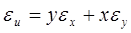 , (14.6)
, (14.6)
а по формуле (14.5) получим
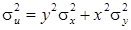 . (14.7)
. (14.7)
Для относительной погрешности произведения d u= e u / xy из формулы (14.6) следует, что
du=dx+dy , (14.8)
а из формулы (14.7) :
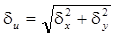 . (14.9)
. (14.9)
Пусть надо перемножить n положительных чисел x1, x2, …, xn, заданных с одинаковой относительной погрешностью d. Формула (14.8) дает оценку du= nd , а по формуле (14.9) получаем  .
.
Нетрудно убедиться в том, что для относительной погрешности частного U= x/ y двух положительных чисел x, y также справедливы формулы (14.8) и (14.9).
Если требуется найти значение функции U= f( x) одной переменной x, то вместо формулы (14.3) имеем (в первом приближении) 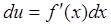 так что
так что  . Такой же результат следует из статистического анализа:
. Такой же результат следует из статистического анализа:
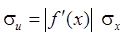 .
.
Коэффициент детерминации
Коэффициент детерминации 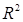 характеризует качество регрессионной модели.
характеризует качество регрессионной модели.
Значения различных величин, полученных расчетами, будем в дальнейшем обозначать «~».
Рассмотрим случай парной регрессии 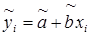 . Имеет место равенство
. Имеет место равенство 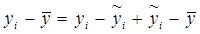 . Для суммы квадратов отклонений yi от среднего
. Для суммы квадратов отклонений yi от среднего 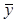
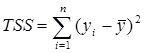 (TSS – total sum of squares)
(TSS – total sum of squares)
имеем TSS = RSS+ESS, где 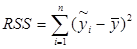 - сумма квадратов отклонений, объясненная регрессией (RSS — regression sum of squares),
- сумма квадратов отклонений, объясненная регрессией (RSS — regression sum of squares), 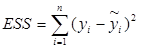 - остаточная сумма квадратов отклонений (ESS – error sum of squares).
- остаточная сумма квадратов отклонений (ESS – error sum of squares).
Коэффициент детерминации определяется по формуле:
. 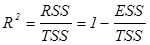 . (15.1)
. (15.1)
Из (15.1) видно, что R2Î[0,1] и чем меньше R2 отличается от 1, тем лучше регрессионная модель.
В математической статистике вводится выборочный коэффициент корреляции 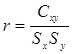 между данными наблюдений ( xi, yi), i=1, 2, …, n. Напомним, что
между данными наблюдений ( xi, yi), i=1, 2, …, n. Напомним, что 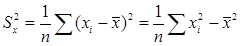 ,
, 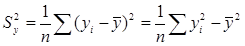 ,
,
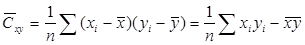 .
.
Поскольку 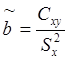 , величину r можно представить в виде
, величину r можно представить в виде 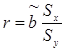 . С другой стороны
. С другой стороны 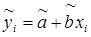 ,
, 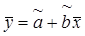 , откуда следует, что
, откуда следует, что
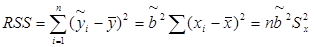 .
.
Поэтому 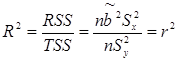 , т.е. коэффициент детерминации равен квадрату выборочного коэффициента корреляции .
, т.е. коэффициент детерминации равен квадрату выборочного коэффициента корреляции .
Средняя ошибка аппроксимации
Фактические значения интересующей нас величины отличаются от рассчитанных по уравнению регрессии. Чем меньше это отличие, чем ближе рассчитанные значения подходят к эмпирическим данным, тем лучше качество модели. Величина отклонений фактических и расчетных значений переменной величины по каждому наблюдению представляет собой ошибку аппроксимации. Так как отклонение может быть величиной как положительной, так и отрицательной, то ошибки аппроксимации для каждого наблюдения принято определять в процентах по модулю.
Отклонения ( 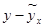 ) рассматриваются как абсолютная ошибка аппроксимации, тогда
) рассматриваются как абсолютная ошибка аппроксимации, тогда 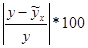 – относительная ошибка аппроксимации.
– относительная ошибка аппроксимации.
Средняя ошибка аппроксимации определяется как среднее арифметическое: 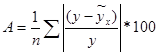 . Иногда пользуются определением средней ошибки аппроксимации, имеющим вид
. Иногда пользуются определением средней ошибки аппроксимации, имеющим вид 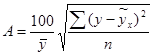 .
.
Дата добавления: 2018-10-26; просмотров: 410; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!