Логическая схема дисперсионного анализа. Однофакторный дисперсионный комплекс
Дисперсионный анализ, основы которого были разработаны Фишером в 1920-1930 гг., позволяет устанавливать не только степень одновременного влияния на признак нескольких факторов и каждого в отдельности, но также их суммарное влияние в любых комбинациях и дополнительный эффект от сочетания разных факторов. Разумеется, и в этом случае остается масса неучтенных факторов, но, во-первых, методика позволяет оценить долю их влияния на общую изменчивость признака, а во-вторых, исследователь обычно имеет возможность выделить несколько ведущих факторов и исследовать именно их воздействие на изменчивость признаков.
Дисперсионный анализ позволяет решить множество задач, когда требуется изучить воздействие природных или искусственно создаваемых факторов на интересующий исследователя признак. Дисперсионный анализ принадлежит к числу довольно трудоемких биометрических методов, однако правильная организация опыта или сбора данных в природных условиях существенно облегчает вычисления.
В зависимости от числа учитываемых факторов дисперсионный анализ может быть одно-, двух, трех- и многофакторным. Объем работы с увеличением числа факторов резко возрастает, поэтому уже четырехфакторный анализ следует проводить с помощью ЭВМ.
Идея дисперсионного анализа заключается в разложении общей дисперсии случайной величины на независимые случайные слагаемые, каждое из которых характеризует влияние того или иного фактора или их взаимодействия. Последующее сравнение этих дисперсий позволяет оценить существенность влияния фактора на исследуемую величину. Таким образом, задача дисперсионного анализа состоит в том, чтобы выявить ту часть общей изменчивости признака, которая обусловлена воздействием учитываемых факторов, и оценить достоверность делаемого вывода. Пусть, например, А – исследуемая величина,  – среднее значение величины А, учитываемые факторы мы обозначим буквой х, неучитываемые – z, а все факторы вместе – буквой у (или припиской этих букв к соответствующим символам). Неучитываемые факторы составляют «шум» – помехи, мешающие выделить степень влияния учитываемых факторов. ОтклонениеАот при действии факторов х и z можно представить в виде суммы
– среднее значение величины А, учитываемые факторы мы обозначим буквой х, неучитываемые – z, а все факторы вместе – буквой у (или припиской этих букв к соответствующим символам). Неучитываемые факторы составляют «шум» – помехи, мешающие выделить степень влияния учитываемых факторов. ОтклонениеАот при действии факторов х и z можно представить в виде суммы
|
|
|
(А– )=У=Х+Z, (4.53)
гдеХ– отклонение, вызываемое факторомх,Z– отклонение, вызываемое факторомz,У– отклонение, вызываемое всеми факторами. Кроме того, предположим, чтоХ,У,Z– являются независимыми случайными величинами, обозначим дисперсии через ϭ2Х, ϭ2У, ϭ2Z, ϭ2А. Тогда имеет место равенство
ϭ2А=ϭ2Х+ϭ2Z. (4.54)
Сравнивая дисперсии, можно установить степень влияния факторов х и z на величинуА, т.е. степень влияния учтенных и неучтенных факторов.
|
|
|
Непременным условием дисперсионного анализа является разбивка каждого учитываемого фактора не менее чем на две качественные или количественные градации. Если исследуется влияние одного фактора на изучаемую величину, то речь идет об однофакторном комплексе, если изучается влияние двух факторов, то о двухфакторном комплексе и т.д. Для проведения дисперсионного анализа обязательным условием является нормальное распределение и равные дисперсии совокупности случайных величин.
Для пояснения логической схемы дисперсионного анализа рассмотрим простейший произвольный пример. Предположим, что совокупности возрастающих доз удобрения на разных делянках имеют нормальное распределение и равные дисперсии. Имеется m таких совокупностей (разные делянки), из которых произведены выборки объемом n1,n2,…,nm. Обозначим выборку из i-й совокупности через (хi1,хi2,…хin) – урожайность делянок. Тогда все выборки можно записать в виде табл. 4.17, которая называется матрицей наблюдений.
Таблица 4.17.– Матрица наблюдений однофакторного дисперсионного комплекса
| Кол-во элементов совокупности (n)-дозы удобрения Кол-во совокупностей (m) | 1 | 2 | … | J | … | N |
| 1 | X11 | X12 | … | X1j | … | X1n1 |
| 2 | X21 | X22 | … | X2j | … | X2n2 |
| … | … | … | … | … | … | … |
| I | Xi1 | Xi2 | … | xij | … | xini |
| … | … | … | … | … | … | |
| m | Xm1 | Xm2 | … | xmj | … | xmnm |
|
|
|
Средние этих выборок обозначим через  β1, β2,…, βi,…, βm. Для проверки гипотезы о равенстве средних нулевую гипотезу запишем как Н0: β1=β2=…=βi=…=βm, альтернативную в виде Н1: β1≠β2≠…≠βi≠…≠βm.
β1, β2,…, βi,…, βm. Для проверки гипотезы о равенстве средних нулевую гипотезу запишем как Н0: β1=β2=…=βi=…=βm, альтернативную в виде Н1: β1≠β2≠…≠βi≠…≠βm.
Гипотеза Н0 проверяется сравнением внутригрупповых и межгрупповых дисперсий по F-критерию. Если расхождение между ними незначительно, то нулевая гипотеза принимается. В противном случае нулевая гипотеза отвергается и делается заключение о том, что различия в средних обусловлены не только случайностями выборок, но и действием исследуемого фактора.
Для изучаемого признака характерно три типа изменчивости:
1. Факториальная (или групповая) изменчивость, характеризующаяся тем, что для каждой из совокупностей имеется своя средняя арифметическая (  ). Разница в медиях зависит, очевидно, от разного действия факторов.
). Разница в медиях зависит, очевидно, от разного действия факторов.
2. Остаточная изменчивость, характеризующаяся различными значениями признака внутри каждой градации. Эти различия не зависят от влияния фактора. Видимо, их причина лежит вне опыта, определяется неучитываемыми в данном анализе факторами.
|
|
|
3. Общая изменчивость, заключающаяся в том, что все наблюдения дисперсионного комплекса отличаются друг от друга (или иногда совпадают).
Мерилом изменчивости признака в выборке служит сумма квадратов отклонений его значений от средней арифметической Σ(х-  )2. Эта величина, отнесенная к числу наблюдений, дает меру рассеяния, именуемую дисперсией, которая и применяется в дисперсионном анализе.
)2. Эта величина, отнесенная к числу наблюдений, дает меру рассеяния, именуемую дисперсией, которая и применяется в дисперсионном анализе.
1. Мерой факториальной изменчивости будет сумма квадратов отклонений средних значений групп (  ) от общего среднего
) от общего среднего  :
:
S2x=n 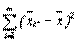 . (4.55)
. (4.55)
Эту величину иногда называют рассеиванием по факторам.
2. Мера остаточной изменчивости выразится суммой квадратов отклонений всех наблюдений в данной совокупности от среднего значения совокупности:
S2z=  . (4.56)
. (4.56)
3. Мерой общей изменчивости является сумма квадратов отклонений в дисперсионном комплексе от общего среднего:
S2y=  2. (4.57)
2. (4.57)
Тогда в соответствии с основной идеей дисперсионного анализа можно записать S2y=S2x+S2z или
S2y=  2= n
2= n 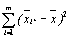 +
+  (4.58)
(4.58)
Вычислим факториальную и остаточную дисперсии как меры соответствующих типов изменчивости признака в дисперсионном комплексе:
 (4.59)
(4.59)
В этих формулах фигурируют степени свободы (νх, νz, νу), т.к. дисперсия ϭ2 и есть сумма квадратов отклонений в расчете на одну степень свободы. Число степеней свободы есть количество значений, необходимых для восстановления утерянного. Число степеней свободы для факториальной дисперсии равно числу совокупностей без единицы (m-1), т.к. все группы связаны друг с другом лишь одним общим условием – значением средней арифметической всего дисперсионного комплекса (  ).Число степеней свободы для остаточной дисперсии равно числу наблюдений в комплексе минус число совокупностей (mn-m), ибо все наблюдения связаны наличием в каждой группе своей средней арифметической (
).Число степеней свободы для остаточной дисперсии равно числу наблюдений в комплексе минус число совокупностей (mn-m), ибо все наблюдения связаны наличием в каждой группе своей средней арифметической ( 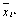 ).Число степеней свободы для вычисления общей дисперсии всего комплекса равно числу наблюдений в комплексе без единицы (mn-1), ибо все наблюдения связаны только одним общим условием – наличием общей средней (
).Число степеней свободы для вычисления общей дисперсии всего комплекса равно числу наблюдений в комплексе без единицы (mn-1), ибо все наблюдения связаны только одним общим условием – наличием общей средней (  ).
).
Затем необходимо рассчитать доли влияния учтенного и неучтенного факторов как отношения соответствующих сумм квадратов отклонений:
 . (4.60)
. (4.60)
Эти величины представляют собой не что иное, как квадраты корреляционных отношений. В сумме эти показатели должны всегда составлять 1 (100%). Теперь можно ответить на интересующий вопрос: насколько учитываемый фактор ответственен за изменчивость результативного признака и сколько процентов падает на долю неучтенных факторов. Для проверки достоверности полученного вывода необходимо провести проверку по F-критерию. Определяют значение критерия Фишера (F), представляющего собой отношение двух дисперсий – факториальной и остаточной –  , и сравнивают его с табличным в зависимости от числа степеней свободы ν1=m-1 и ν2=mn-m. Для того чтобы отвергнуть нулевую гипотезу, необходимо, чтобы полученное значение критерия было больше табличного.
, и сравнивают его с табличным в зависимости от числа степеней свободы ν1=m-1 и ν2=mn-m. Для того чтобы отвергнуть нулевую гипотезу, необходимо, чтобы полученное значение критерия было больше табличного.
Однофакторный дисперсионный анализ удобно представить в виде табл. 4.18.
Пример построения простейшего дисперсионного комплекса
Предположим, что изучается влияние возрастающих доз удобрения определенного типа на урожайность какой-либо культуры. Пусть имеются четыре дозы удобрения (А1…А4, причем А1<A2<A3<A4), которое использовали на пяти делянках по каждой дозе (m=4, n=5). Требуется выяснить, влияет ли повышение дозы удобрения на урожайность и если да, то достоверен ли этот вывод настолько, чтобы можно было рекомендовать этот опыт сельскому хозяйству. Результаты наблюдений приведены в табл. 4.19.
Таблица 4.18.– Логическая схема однофакторного дисперсионного комплекса
| Компоненты дисперсии | Сумма квадратов | Число степеней свободы | Дисперсии | Степень влияния фактора |
| Факториальная (межгрупповая) | п 
| m-1 | 
| 
|
| Остаточная (внутригрупповая) | 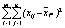
| m(n-1) | 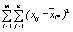 
| 
|
| Полная (общая) | 
| mn-1 | 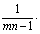 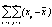
|
Таблица 4.19.– Исходные данные для расчета однофакторногодисперсионного комплекса
| Доза удобрения | Урожайность, ц/га | ||||
| № делянки 1 | 2 | 3 | 4 | 5 | |
| А1 | 150 | 140 | 150 | 145 | 150 |
| А2 | 190 | 150 | 170 | 150 | 165 |
| А3 | 200 | 170 | 200 | 170 | 180 |
| А4 | 230 | 190 | 210 | 190 | 200 |
Рассчитываем средние  Средняя арифметическая всех совокупностей = 3500/20=175.
Средняя арифметическая всех совокупностей = 3500/20=175.

По расчетным данным составляем табл. 4.20.
Таблица 4.20.– Результаты-расчеты однофакторного дисперсионного комплекса
| Компоненты дисперсии | Суммы квадратов | Число степеней свободы | Дисперсии | Степень влияния фактора |
| Факториальная | 9030 | 3 | 3010 | 0,74 |
| Остаточная | 3220 | 16 | 201,25 | 0,26 |
| Общая | 12250 | 19 | 644,7 |
Значение критерия Фишера равно F=14,95; при ν1=16 и ν2=3 степенях свободы и уровне значимости 0,01 табличное значения критерия составляетFst=9,01. Вычисленное значение больше стандартного, поэтому нулевую гипотезу отвергаем, а это значит, что повышенные дозы удобрения влияют на урожайность достоверно. Но необходимо помнить, что на долю неучтенных факторов приходится 26% изменчивости, т.е. урожайность зависит еще и от других факторов.
Двухфакторный комплекс
Если исследуют влияние двух, трех и т.д. факторов, то структура дисперсионного анализа остается той же, что и при однофакторном комплексе, усложняются лишь вычисления. Рассмотрим задачу оценки действия двух одновременно действующих факторов. Но прежде всего введем некоторые ограничения. Основное из них состоит в том, что включаемые в дисперсионный анализ факторы должны быть независимы друг от друга, корреляция между ними не допустима. Нельзя, например, изучать одновременное влияние температуры и влажности воздуха на урожайность какой-либо культуры, ибо температура и влажность воздуха обычно сильно коррелируют. Крайне желательно, чтобы число наблюдений по совокупностям было одинаковым или хотя бы пропорциональным. Пусть имеется несколько однотипных участков земли и несколько видов удобрения. Требуется выяснить, значимо ли влияние качества различных участков земли и качество удобрений на урожайность зерновой культуры. Это типичная задача двухфакторного дисперсионного анализа. Пусть фактор А – влияние земли; фактор В – влияние качества удобрения. Урожайность обозначим через хij. Для простоты сначала рассмотрим случай, когда для каждого участка земли и для каждого удобрения сделано одно наблюдение. Тогда матрица наблюдений будет следующей
Таблица 4.21.– Матрица наблюдений для двухфакторного дисперсионногокомплекса (с одним наблюдением в ячейке)
| Вид удобрения (j) Участки земли (i) | В1 | В2 | … | Вv |
|
| A1 | X11 | X12 | … | X1v | 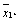
|
| A2 | X21 | X22 | … | X2v | 
|
| … | … | … | … | … | … |
| Ar | Xr1 | Xr2 | … | xrv | 
|

| 
| 
| … | 
|
|
То есть мы имеем r участков земли и v видов удобрения. В матрице им соответствуют r строк– уровни фактора А и v столбцов– уровни фактораВ.
По каждому столбцу и строке рассчитаем среднее значение, а также общее среднее. В двухфакторном анализе изучается раздельное влияние на признак фактора А, фактора В, в связи с этим факториальная сумма квадратов отклонений распадается на две части:
S2x=S2A+S2B, (4.61)
а сама основная формула приобретает вид
S2y= S2A+S2B+S2z, (4.62)
где
 (4.63)
(4.63)
Произведем оценку дисперсий:
 . (4.64)
. (4.64)
В двухфакторном анализе для выяснения значимости влияния факторов А и В на исследуемый признак сравнивают дисперсии по факторам с остаточной дисперсией, т.е. оценивают отношения  и
и  , находя таким образом значенияFAиFB. Полученные значения сравнивают с табличными значениями при выбранном уровне значимости α. При FA<Fα и FB<Fα нулевая гипотеза о равенстве средних не отвергается, т.е. влияние факторов А и В на исследуемый признак незначительно.
, находя таким образом значенияFAиFB. Полученные значения сравнивают с табличными значениями при выбранном уровне значимости α. При FA<Fα и FB<Fα нулевая гипотеза о равенстве средних не отвергается, т.е. влияние факторов А и В на исследуемый признак незначительно.
Результаты двухфакторного дисперсионного анализа также удобно представить в виде табл. 4.22.
Таблица 4.22.– Логическая схема двухфакторного дисперсионного комплекса(с одним наблюдением в ячейке)
| Компоненты дисперсии | Сумма квадратов | Число степеней свободы | Дисперсии |
| Между средними по строкам (факториальная по А) | 
| r-1 | ϭ2A=S2A/r-1 |
| Между средними по столбцам (факториальная по В) | 
| v-1 | ϭ2В=S2B/v-1 |
| Остаточная | 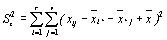
| (r-1)(v-1) | ϭ2z=S2z /((r-1)(v-1)) |
| Полная | 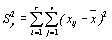
| rv-1 | ϭ2y=S2y/ (rv-1) |
При одном наблюдении в ячейке схема вычислений довольно проста, однако в этом случае достоверность выводов, полученных на основании проведенного анализа, недостаточна. Поэтому при решении практических задач желательно иметь несколько наблюдений в одной ячейке. Рассмотрим схему двухфакторного дисперсионного анализа с несколькими (но равными количествами – k) наблюдениями в каждой ячейке. Матрицу наблюдений можно представить в виде табл. 4.23.
Таблица 4.23.– Матрица наблюдений двухфакторного дисперсионного комплекса
с несколькими, но равными наблюдениями в ячейке
| А В | В1 | В2 | … | Вv | 
|
| A1 |  (х111,х112,…,х11k) (х111,х112,…,х11k)
|  (x121,x122,…,x12k) (x121,x122,…,x12k)
| … | 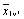 (x1v1,x1v2,…,x1vk) (x1v1,x1v2,…,x1vk)
| 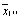
|
| A2 |  (x211,x212,…,x21k) (x211,x212,…,x21k)
|  (x221,x222,…,x22k) (x221,x222,…,x22k)
| … |  (x2v1,x2v2,…,x2vk) (x2v1,x2v2,…,x2vk)
| 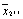
|
| … | … | … | … | … | … |
| Ar | 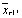 (xr11,xr12,…,xr1k) (xr11,xr12,…,xr1k)
|  (xr21,xr22,…,xr2k) (xr21,xr22,…,xr2k)
| … |  (xrv1,xrv2,…,xrvk) (xrv1,xrv2,…,xrvk)
| 
|

| 
| 
| … | 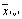
| 
|
Для каждой ячейки имеется свое среднее значение, из которого находятся средние по строкам и столбцам, а затем общее среднее.
В табл.4.23 r– число уровней фактораА, v – число уровней фактораВ. Порядок проведения расчетов такой же, как и прежде. Схема анализа и порядок расчетов приведены в табл. 4.24.
Таблица 4.24.– Логическая схема двухфакторного дисперсионного комплексас несколькими, но равными наблюдениями в ячейке
| Компонента дисперсии | Суммы квадратов | Число степеней свободы | Дисперсии |
| Между средними по строкам (по фактору А) | 
| v-1 | ϭ2A=S2A/(v-1) |
| Между средними по столбцам (по фактору В) | 
| r-1 | ϭ2В=S2B/(r-1) |
| Взаимодействие | 
| (v-1)(r-1) | ϭ2АВ=S2AB/ ((v-1)(r-1)) |
| Остаточная | 
| Rv(k-1) | ϭ2z=S2z/ (rv(k-1)) |
| Полная | 
| Rvk-1 | ϭ2y=S2y/(rvk-1) |
Проверка достоверности нулевой гипотезы делается точно так же, как и при одном наблюдении в ячейке.
Анализ главных компонент
Анализ главных компонент является одним из самых простых способов изучения многомерных вариаций. Этот метод можно применять к любым данным, отвечающим следующим основным требованиям.
1. В каждой из выборок индивидов измеряются значения одних и тех же переменных. Индивиды, для которых измерения проведены не полностью, исключаются из рассмотрения.
2. Предполагается, что выбранные для анализа переменные непрерывны, а если они дискретны, то изменяются с такими приращениями, которые достаточно малы, чтобы величины можно было приближенно считать непрерывными.
3. К отношениям между переменными или их линейным функциям не добавляется никаких других отношений или линейных функций, так же как исходные переменные не заменяются их отношениями или линейными функциями.
В задачу анализа главных компонент может входить исследование одного или нескольких следующих вопросов:
1. Анализ корреляций между отдельными переменными.
2. Сведение исходной размерности вариабельности к наименьшему числу существенных для анализа измерений вариабельности.
3. Исключение тех переменных, которые несут сравнительно мало дополнительной информации по изучаемой проблеме.
4. Выявление наиболее информативных сочетаний отдельных выборок или какой-либо структуры.
5. Установление подлинности тех выборок, происхождение которых неизвестно или вызывает сомнения.
То есть сущность метода главных компонент состоит в переходе от описания некоторого множества изучаемых объектов, заданных большим числом косвенно измеряемых признаков, к описанию меньшим числом максимально информативных переменных, отражающих наиболее информативные свойства явления.
Пусть имеетсяmслучайных переменныхХ1, …, Хmс многомерным распределением. Требуется определить взаимосвязь между переменными. Эта взаимосвязь называется структурой зависимости и может быть измерена ковариациями, дисперсиями или корреляциями между исходными переменными (Ковариация– математическое ожидание (средняя) произведения отклонений двух признаков от их средних:  ,т.е. сопряженное варьирование двух признаков;
,т.е. сопряженное варьирование двух признаков;  ). Задача состоит в нахождении переменных Y1,…,Yn, являющихся линейными комбинациями переменных Хi(n<m), по которым можно получить сжатую структуру зависимости между исходными переменными, несущую почти всю информацию, содержащуюся в них. Метод главных компонент является одним из наиболее простых методов анализа структуры зависимости.
). Задача состоит в нахождении переменных Y1,…,Yn, являющихся линейными комбинациями переменных Хi(n<m), по которым можно получить сжатую структуру зависимости между исходными переменными, несущую почти всю информацию, содержащуюся в них. Метод главных компонент является одним из наиболее простых методов анализа структуры зависимости.
Суть метода состоит в том, что ищутся такие линейные комбинации Y1,Y2,…Ym (называемые главными компонентами) исходных переменныхХ1,Х2,…Хm:
 ,
,  , k=1,…,m, (4.65)
, k=1,…,m, (4.65)
что новые переменные Yk не коррелированы и упорядочены по возрастанию дисперсии (k – номер компоненты). То есть Y1 определяется условием максимальности дисперсии всех переменных; Y2определяется условием максимальности дисперсии среди всех нормированных комбинаций Хi, i=1,…,m, не коррелирующих с Y1; Y3 – условием максимальности дисперсии всех нормированных комбинаций Хi, не коррелирующих с Y1 и Y2, и т.д. (Нормирование х и у – переход к новым величинам x’ и y’, в которых средние равны 0, а дисперсии равны 1: 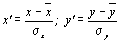 ). Таким образом, подмножество qпервых главных компонент будет объяснять большую часть общей дисперсии исходных признаков.
). Таким образом, подмножество qпервых главных компонент будет объяснять большую часть общей дисперсии исходных признаков.
Обозначим дисперсии главных компонент v21,…,v2m, а дисперсии исходных признаков – s21,…,s2m. Из вышесказанного следует, что  . При этом справедливо равенство
. При этом справедливо равенство  . Это равенство означает, что исходно заложенная в данных дисперсия не меняется при переходе к новым переменным, а перераспределяется. Кроме того, новые переменные в отличие от исходных признаков приобрели такое ценное качество, как отсутствие корреляции друг с другом.
. Это равенство означает, что исходно заложенная в данных дисперсия не меняется при переходе к новым переменным, а перераспределяется. Кроме того, новые переменные в отличие от исходных признаков приобрели такое ценное качество, как отсутствие корреляции друг с другом.
Решение поставленной задачи сводится к нахождению коэффициентов αki. Для этого необходимо построить исходную матрицу ковариаций или корреляций признаков, для которой находятся ее собственные значения и собственные векторы. Собственные значения матрицы равны дисперсии компоненты v2k. Упорядоченные по убыванию собственных значений матрицы собственные векторы и будут являться искомыми коэффициентами αki (т.е. собственный вектор есть не что иное, как набор коэффициентов αki).
Линейная комбинация  называется первой главной компонентой переменных Х1,Х2,…,Хm. Она объясняет 100v2(Y1)/S2общпроцентов общей дисперсии. Вторая главная компонента, которая определяется линейной комбинацией
называется первой главной компонентой переменных Х1,Х2,…,Хm. Она объясняет 100v2(Y1)/S2общпроцентов общей дисперсии. Вторая главная компонента, которая определяется линейной комбинацией  , соответствует второму по величине собственному значению. Первая и вторая главных компоненты объясняют вместе 100[v2(Y1)+ v2(Y2)]/S2общпроцентов общей дисперсии и т.д. Последний собственный вектор определяет последнюю компоненту
, соответствует второму по величине собственному значению. Первая и вторая главных компоненты объясняют вместе 100[v2(Y1)+ v2(Y2)]/S2общпроцентов общей дисперсии и т.д. Последний собственный вектор определяет последнюю компоненту  , и все главные компоненты в совокупности объясняют
, и все главные компоненты в совокупности объясняют 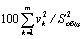 процентов общей дисперсии и равны 100%.
процентов общей дисперсии и равны 100%.
Для получения главных компонент можно вместо ковариационной матрицы использовать корреляционную. Когда переменные измеряются в различных единицах, не имеющих между собой ничего общего, линейные комбинации бывает трудно интерпретировать. В этом случае необходимо провести стандартизацию (или нормирование) переменных. При этом общая дисперсия будет равна числу переменных. Надо отметить, что главные компоненты, получаемые из ковариационной и корреляционной матрицы, различны.
Корреляция между главными компонентами Yk и переменной Хi задается величиной  , где si – стандартное отклонение переменнойх. Следовательно, для сравнения вкладов переменныхХi в Ykнеобходимо сравнить величины αki/si. Когда известна корреляционная матрица, достаточно сравнить коэффициенты αki. В этом случае самый большой коэффициент показывает, какая переменная внесла наибольший вклад в k-ю главную компоненту.
, где si – стандартное отклонение переменнойх. Следовательно, для сравнения вкладов переменныхХi в Ykнеобходимо сравнить величины αki/si. Когда известна корреляционная матрица, достаточно сравнить коэффициенты αki. В этом случае самый большой коэффициент показывает, какая переменная внесла наибольший вклад в k-ю главную компоненту.
Можно привести следующую геометрическую интерпретацию метода главных компонент (рис. 4.7). Переменные х1,…,хm могут быть представлены координатными осями, начало координат находится в точке  – вектор средних. Таким образом в m мерном пространстве каждая реализация вектора х=(х1,…,хm) представляется точкой с координатами Х1=х1,…,Хm=хm.
– вектор средних. Таким образом в m мерном пространстве каждая реализация вектора х=(х1,…,хm) представляется точкой с координатами Х1=х1,…,Хm=хm.

Рисунок 4.7 – Геометрическая интерпретация метода главных компонент
В анализе главных компонент ищется такой поворот системы координат, чтобы переменная у1, соответствующая одной из новых осей, имела максимальную дисперсию (наибольшую вытянутость облака точек вдоль оси), а переменная у2, соответствующая другой оси, была ортогональна (не коррелирована) с у1 и имела бы при этом максимальную дисперсию. Переменная уq, должна быть ортогональна у1,…,уq-1 и иметь максимальную дисперсию. Область m-мерного пространства называется эллипсоидом концентрации. Переменные х1, х2 порождают двухмерное пространство – эллипс. Первая главная компонента определяет направление большой оси эллипса, вторая – малой. Если найдено пространство главных компонент, то с помощью поворота осей можно получить бесконечно много решений. Задача состоит в том, чтобы подобрать оси таким образом, чтобы можно было дать новым переменным конкретный биологический смысл.
Практически довольствуются выделением 3–5 главных компонент. Дело в том, что объем информации, извлекаемый каждой последующей главной компонентой, быстро убывает, а биологическая интерпретация факторов становится все более затруднительной. В обычных исследованиях можно ограничиться тем числом главных компонент, которое обеспечивает извлечение 80–90% общей дисперсии признаков: гораздо важнее правильно истолковать смысл небольшого числа ведущих главных компонент, чем пытаться интерпретировать последующие, исходя из ничтожной доли привносимой ими информации.
Подводя итог, можно сказать, что смысл способа главных компонент состоит в последовательном устранении влияния каждого выделенного фактора на систему связи между признаками. В сущности анализ главных компонент основан на отыскании собственных чисел и соответствующих собственных векторов матрицы коэффициентов корреляции или ковариации между исходными переменными. Получающиеся собственные числа и собственные векторы определяют компоненты полной вариабельности (заложенной в исходных переменных) как линейные функции этих переменных с коэффициентами, выбранными так, что функции оказываются математически независимыми, или ортогональными друг другу.
Лучше всего проиллюстрировать этот метод простым примером Джефферс, 1981).
В ходе исследования возможных последствий для окружающей среды, к которым могло привести возведение дамбы в заливе, был предпринят ряд наблюдений. В каждой из 274 выборочных точек в различных частях залива было взято по десять 10-сантиметровых колонок грунта; выборочный материал тут же обрабатывали. Для каждой из выборок определяли значение восьми переменных:
1. Долю частиц размером >250 мкм.
2. Долю частиц размером 125–250 мкм.
3. Долю частиц размером 62,5–125 мкм.
4. Долю частиц размером<62,5 мкм.
5. Потери в результате прокаливания при 5500С.
6. Содержание кальция.
7. Содержание фосфора.
8. Содержания азота.
Ставилась задача по исходным данным определить свойства грунта в заливе. В табл. 4.25 подытожены основные результаты наблюдений для 274 выборочных точек.
Таблица 4.25.– Переменные, характеризующие свойства среды в заливе Моркам
| Переменная | Минимум, % | Среднее, % | Максимум, % | Стандартное отклонение |
| 1. Доля частиц размером >250 мкм. 2. Доля частиц размером 125–250 мкм. 3. Доля частиц размером 62,5–125 мкм. 4. Доля частиц размером<62,5 мкм. 5. Потери в результате прокаливания при 5500С. 6. Содержание кальция. 7. Содержание фосфора. 8.Содержание азота. | 0,1 0,05 0,1 0,5 0,44 1,5 0,016 0,001 | 1,207 20,31 53,67 24,74 1,504 2,401 0,028 0,013 | 43 94 97 88 3,72 9 0,048 0,054 | 4,479 23,27 21,36 20,77 0,555 0,704 0,0056 0,0093 |
В табл. 4.26 приведены коэффициенты корреляции между исходными переменными. Исследование таблицы корреляций показало, что доли частиц крупнее 250 мкм и частиц размером 125–250 мкм значимо и положительно коррелируют между собой и отрицательно коррелируют с долей частиц размером 62,5–125 и мельче 62,5 мкм. Последние показатели также значимо и отрицательно коррелируют между собой. В противоположность этому все четыре переменные, характеризующие химические свойства грунта, были значимо и положительно взаимно коррелированы. Потери при прокаливании положительно коррелировали с долями частиц размером 62,5–125 и мельче 62,5 мкм и отрицательно коррелировали с долей частиц размером 125–250 мкм. Содержание кальция положительно коррелировало с долей частиц крупнее 50 мкм и мельче 62,5 мкм и отрицательно коррелировало с долей частиц размером от 125 до 250 мкм. Содержание фосфора положительно коррелировало с долей частиц менее 125 мкм и отрицательно коррелировало с долей частиц размером более 125 мкм. Содержание азота положительно коррелировало с долей частиц мельче 62,5 мкм и отрицательно коррелировало с долей частиц размером от 125 до 250 мкм.
Таблица 4.26.– Коэффициенты корреляции между переменными среды
| Х1 | |||||||
| 0,1471 | Х2 | ||||||
| -0,283 | -0,5651 | Х3 | |||||
| -0,095 | -0,5721 | -0,331 | Х4 | ||||
| -0,001 | -0,4621 | 0,1272 | 0,3881 | Х5 | |||
| 0,7131 | -0,2531 | -0,051 | 0,1751 | 0,3591 | Х6 | ||
| -0,1482 | -0,4051 | 0,2171 | 0,2641 | 0,5661 | 0,1671 | Х7 | |
| 0,072 | -0,4261 | 0,005 | 0,4531 | 0,7351 | 0,4211 | 0,436 | Х8 |
1 – значимо на уровне 0,01
2 – значимо на уровне 0,05
Из простого рассмотрения корреляционной матрицы, т.е. в сущности, самих данных, трудно извлечь что-либо, кроме утверждения, что между этими восемью переменными существует тесная взаимная корреляция, а уж сделать вывод о свойствах грунта невозможно. Для этого применим метод главных компонент, чтобы изменить структуру исходных признаков таким образом, чтобы можно было сделать соответствующий вывод. Анализ главных компонент начинается с вычисления такой линейной функции восьми переменных, которая дает как можно большую часть всей вариабельности, содержащейся в 274 выборках.
Собственные числа и собственные векторы вычисляются на основе корреляционной матрицы признаков. Собственное число первой компоненты равно 3,12; оно показывает, какую долю полной вариабельности учитывает данная компонента. Аналогично остальные собственные числа отражают те доли вариабельности, которые учитываются соответствующими компонентами, а в сумме они дают кумулятивные доли полной вариабельности, учитываемые независимыми по определению главными компонентами. Из табл. 4.27 видно, что первая линейная функция восьми переменных отвечает за 39 % полной вариабельности, а следующие три компоненты– за 23,4, 15,7 и 10,3 % соответственно. В сумме четыре компоненты дают 88,4 % вариабельности, содержащейся в восьми исходных переменных. Вычислять следующие компоненты, по-видимому, не стоит, так как вряд ли компоненты с собственными числами, меньшими примерно 0,8, будут иметь какое-то практическое значение.
Таблица 4.27.– Собственные числа для первых четырех главных компонент
| Компонента | Собственное число | Доля вариабельности | Кумулятивная доля вариабельности |
| Y1 Y2 Y3 Y4 | 3,12 1,87 1,26 0,83 | 39 23,4 15,7 10,3 | 39 62,4 78,1 88,4 |
В табл. 4.28 приведены собственные векторы, элементы которых есть коэффициенты линейных функций, определяющих компоненты полной вариабельности. Если нанести на график рассеивания имеющиеся данные, то они не будут разбросаны, как до применения метода главных компонент, а сгруппированы в четыре части по числу главных компонент. Их можно использовать для интерпретации экологического смысла компонент, используя знак и относительную величину коэффициентов как показатели веса, которые следует присвоить каждой переменной в этих четырех главных компонентах.
Таблица 4.28.– Собственные векторы первых четырех компонентпеременных среды
| Переменная | Коэффициенты для компонент | |||
| Y1 | Y2 | Y3 | Y4 | |
| Х1 Х2 Х3 Х4 Х5 Х6 Х7 Х8 | 0,05 -0,9 0,25 0,74 1 0,61 0,8 0,97 | 1 0,4 -0,72 0,07 0,01 0,79 -0,27 0,17 | 0,49 -0,23 1 -0,87 -0,03 0,53 0,04 -0,16 | 0,17 -1 0,24 0,84 -0,64 0,24 -0,86 -0,42 |
Первая компонента отражает в основном противоположность фактора Х5 (потери при прокаливании образца) и факторов Х7 и Х8 (содержание фосфора и азота), с одной стороны, и фактора Х2 (доля частиц размером 125–250 мкм) – с другой, и представляет собой некоторую меру общего «плодородия» песка и ила. Вторая компонента является показателем доли самых крупных частиц (т.е. частиц>250 мкм) и содержания кальция и служит мерой количества разбитых раковин. Третья компонента отражает противоположности факторов Х3 (доля частиц размером 62,5-125 мкм) и Х4 (доля частиц, размер которых меньше 62,5 мкм) и рассматривается как мера накопления морского ила. Четвертая компонента вновь отражает противоположности факторов, но в данном случае факторов Х2 (доля частиц размером 125–250 мкм) и Х7 (содержание фосфора), с одной стороны, и фактора Х4 (число частиц мельче 62,5 мкм) – с другой, и интерпретируется как мера речных наносов.
Анализ показывает, что для учета основной изменчивости химических и физических свойств песка и ила в заливе достаточно ограниченного числа измерений вариабельности. В данном случае было достаточно четырех компонент, чтобы учесть 88% полной вариабельности, а сами компоненты легко интерпретировались через вполне конкретные типы изменчивости, поддающиеся определению. В действительности нахождение отдельных компонент для отдельных выборок и нанесение их значений на карту залива помогают выявить области высокой продуктивности, границы распространения морских осадков и речных наносов, а также области с высоким содержанием кальция, указывающим на наличие большого количества разбитых раковин. Получающиеся при этом карты помогают выявить источник вариабельности, который в противном случае остался бы неизвестным.
Помимо определения размера частиц и химического состава песка и ила, проводились выборочные исследования для определения численностей 22 видов или видовых групп беспозвоночных, обитающих в заливе. В табл. 4.29 приведены численности на 1м2 только семи из этих видов, поскольку остальные виды беспозвоночных встречались слишком редко, чтобы анализировать их численность. Общее число выборок, по которым составлена эта таблица, равно 329, т.к. помимо выборок для определения физических и химических свойств среды делались некоторые дополнительные выборки с целью уяснить распределение видов, поскольку считалось, что число видов более вариабельно, чем переменные среды. Как показывает анализ табл. 4.29, это предположение было, несомненно, справедливым, поскольку число отдельных организмов семи видов в выборках ила действительно очень сильно варьировало.
Таблица 4.29.– Численности различных видов беспозвоночных в заливе Моркам
| Вид | Численность на 1м2 | Стандартное отклонение | ||
| минимум | среднее | максимум | ||
| Y1 MacomabalticaY2 Tellinatenuis Y3 Hydrobiaulvae Y4 Corophiumvolutator Y5 Nereisdiversicolor Y6 Arenicola marina Y7 Nephthys hombergii | 0 0 0 0 0 0 0 | 2325 49,2 374,2 540,5 63,5 16,7 4,94 | 56325 9800 8525 8700 750 222 100 | 5966 544 1014 1180 116 26 17 |
В табл. 4.30 приведены коэффициенты корреляции между численностями видов в отдельных выборках. И вновь обычный критерий значимости для коэффициентов корреляции между двумя переменными здесь едва ли применим – не только потому, что мы проверяем несколько коэффициентов одновременно, но и потому, что распределение исходных данных далеко от нормального. Тем не менее, согласно обычному критерию значимости, численность Macoma baltica положительно коррелировала с численностями Hydrobia ulvae, Nereis diversicolor и Arenicola marinaи отрицательно коррелировала с численностью Nephthys hombergii. Численности Hydrobia ulvae, Corophium volutator и Nereis diversicolor взаимно коррелировали, а численность Corophium volutator отрицательно коррелировала с численностью Nephthys hombergii. Численность Tellina tenuis не обнаруживала заметных корреляций с численностями всех остальных видов.
Таблица 4.30.– Коэффициенты корреляции между численностямиразличных видов беспозвоночных
| Y1 -0,028 0,3581 0,051 0,5691 0,1741 -0,171 | Y2 0,032 0,054 0,009 -0,003 -0 | Y3 0,3131 0,3021 0,081 -0,099 | Y4 0,1621 -0,095 -0,1182 | Y5 0,084 -0,092 | Y6 -0,011 | Y7 |
1 – значимо на уровне 0,01,
2 – значимо на уровне 0,05.
Как и прежде, главные компоненты для корреляционной матрицы табл. 4.30 определяются по собственным числам и собственным векторам этой матрицы. Первые пять собственных чисел корреляционной матрицы приведены в табл. 4.31, которая показывает, что пять соответствующих компонент учитывают почти 86% полной вариабельности. Остальные две компоненты, которые можно вычислить, соответствуют, по-видимому, лишь случайным вариациям.
Таблица 4.31.– Собственные числа первых пяти компонент для численностейразличных видов беспозвоночных
| Компонента | Собственное число | Доля вариабельности,% | Кумулятивная доля вариабельности,% |
| W1 W2 W3 W4 W5 | 1,98 1,2 1 0,95 0,85 | 28,3 17,1 14,3 13,6 12,2 | 28,3 45,4 59,7 73,3 85,5 |
Согласно приведенным в табл. 4.32 собственным векторам первая компонента, отвечающая за 28,3 % полной вариабельности численности видов, является показателем численности Macomabaltica, Hydrobiaulvae и Nereisdiversicolor.Вторая компонента, учитывающая 17,1 % вариабельности, отражает противоположность изменений численностейCorophiumvolutatorи Arenicolamarina.Остальные компоненты, отвечающие за 14,3, 13,6 и 12,2 % соответственно, являются прямой мерой численностей Tellinatenuis, Nephthyshombergii и Arenicolamarina соответственно.
Таблица 4.32.– Собственные векторы первых пяти компонентдля численностей различных видов беспозвоночных
| Переменная | Коэффициенты для компонент | ||||
| W1 | W2 | W3 | W4 | W5 | |
| Y1 Y2Y3 Y4 Y5 Y6 Y7 | 1 0,04 0,89 0,51 0,99 0,29 -0,32 | -0,48 0,4 0,32 1 -0,22 -0,86 -0,44 | -0,01 1 0,04 -0,05 -0,01 0,25 0,34 | 0,13 -0,2 0,11 0,13 0,19 -0,54 1 | -0,43 -0,41 0,59 0,71 -0,59 1 0,47 |
Таким образом, с помощью анализа вновь удается представить всю массу информации в относительно простом виде, где пять компонент учитывают около 86% полной вариабельности. Как и при анализе химических и физических свойств песка и ила, вычисление значений отдельных компонент для различных выборок и нанесение этих значений на карту залива дает ясную картину распределения организмов в рамках этих пяти независимых компонент. И вновь получающиеся карты помогают выявить источник вариабельности, который в противном случае оставался бы неизвестным.
Еще более интересным оказалось, однако, рассмотрение корреляций между значениями компонент для среды и для численности беспозвоночных. Эти корреляции были прослежены по тем 272 выборкам, по которым имелись оба набора компонент; соответствующие данные приведены в табл. 4.33.
Таблица 4.33.– Коэффициенты корреляции между компонентами средыи компонентами для численности беспозвоночных
| Компонента для численности беспозвоночных | Коэффициент корреляции с компонентой среды | |||
| Y1 | Y2 | Y3 | Y4 | |
| W1 W2 W3 W4 W5 | 0,4081 -0,047 -0,78 -0,029 -0,004 | -0,029 -0,1641 -0,007 -0,1871 0,042 | 0,039 -0,097 0,122 0,062 0,095 | -0,031 0,1532 0 -0,1 0,1561 |
1 – значимо на уровне 0,01,
2 – значимо на уровне 0,05.
С прежними оговорками по поводу обоснованности обычных критериев значимости для подобных корреляций мы можем сделать вывод, что, судя по данным таблицы, между компонентами для среды и компонентами для численности беспозвоночных существуют интересные взаимосвязи. Первая компонента, относящаяся к популяции беспозвоночных,– показатель численностиMacomabaltica,HydrobiaulvaeиNereis diversicolor–положительно коррелируют с первой из компонент для среды– общей продуктивностью. Противоположность между численностямиCorophium volutatorиArenicola marinaотрицательно коррелирует со второй компонентой для среды и положительно коррелирует с четвертой компонентой, т.е. отрицательнокоррелирует с наличием разбитых раковин и положительно– с речными наносами. ЧисленностьTellina tenuisположительно коррелирует с третьей компонентой для среды, которая служит мерой накопления морского ила, а численностьArenocola marinaотрицательно коррелирует с наличием разбитых раковин. ЧисленностьArenicola marinaположительно коррелирует с количеством осадочного материала морского происхождения. Схематически все эти корреляции изображены на рис. 4.8.
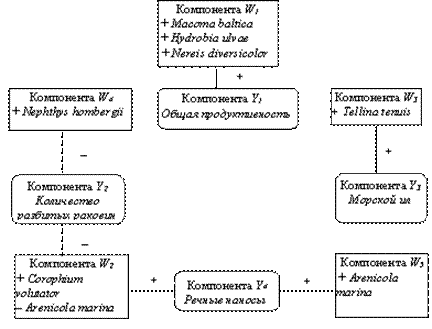
Рисунок 4.8 – Корреляции между численностями беспозвоночных
и свойствами среды обитания
Два рассмотренных выше исследования дают пример интересного описательного анализа взаимосвязей между физико-химическими свойствами песка и ила и численностью популяций беспозвоночных в заливе Моркам. К этому примеру мы вернемся позже при рассмотрении еще одной альтернативной модели– модели канонических корреляций.
Факторный анализ
Факторный анализ во многом напоминает процедуру нахождения главных компонент и представляет собой наиболее общий подход к преобразованию структуры зависимости исходных переменных. В современных пакетах статистической обработки данных на ПЭВМ эти два метода объединены в один, под названием «факторный анализ», в котором метод главных компонент является составной частью, способом выделения факторов.
Пусть имеется р объектов, для которых проведены измерения m признаков. В факторном анализе вводится факторная модель:
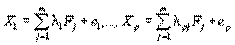 , (4.66)
, (4.66)
гдеλij – постоянные, аm, как правило, меньшер. Переменные F1,…,Fm называются общими (первичными) факторами, поскольку они используются для представления всехрисходных переменных. Предполагается, что общие факторы не коррелированы и имеют единичные дисперсии. Переменныее1,…,еpназываются специфическими (характерными) факторами, поскольку для каждой исходной переменнойХiопределяется своя переменнаяеi, i=1,….р. Предполагается, что характерные факторы также не коррелированы и что  , i=1,….р, где τi– так называемая специфическая дисперсия, или специфичность i–й исходной переменной. ПеременныеFiиeiпредполагаются некоррелированными. Переменные λij называются факторными нагрузками.
, i=1,….р, где τi– так называемая специфическая дисперсия, или специфичность i–й исходной переменной. ПеременныеFiиeiпредполагаются некоррелированными. Переменные λij называются факторными нагрузками.
Дисперсия и ковариация исходных переменных будет равна
 . (4.67)
. (4.67)
Величина  называется общностьюi–й исходной переменной и равна разности ее вариации и специфичности.
называется общностьюi–й исходной переменной и равна разности ее вариации и специфичности.
Таким образом, р компонент модели главных компонент можно рассматривать как р общих факторов, описывающих структуру зависимости р исходных переменных, в то время как m<p общих факторов факторной модели описывают основную часть структуры зависимости, а специфические факторы – оставшуюся часть. Другими словами, в модели главных компонент вся дисперсия приписываетсярглавным компонентам, тогда как в факторном анализе дисперсия каждой исходной переменной делится на две части: дисперсию, обусловленную наличием общих факторов (общность), и дисперсию, обусловленную вариацией каждой исходной переменной (специфичность).
Техника факторного анализа направлена на оценку факторных нагрузок и специфических дисперсий, а также на определение для каждого объекта значений общих факторов с помощью значений исходных переменных, т.е. на вычисление так называемых факторных значений. После того, как факторные нагрузки найдены, остается еще задача лучшей интерпретации общих факторов. Для этого используется метод вращения факторов.
Определение главных факторов
Предполагается наличие случайной выборки  из многомерного нормального распределения с вектором средних
из многомерного нормального распределения с вектором средних  и ковариационной матрицей
и ковариационной матрицей  . ПустьSp*p =(sij)– выборочная ковариационная матрица иRp*p=(rij)– выборочная корреляционная матрица, где rij=sij/(siisij)1/2, i,j=1,…,p.
. ПустьSp*p =(sij)– выборочная ковариационная матрица иRp*p=(rij)– выборочная корреляционная матрица, где rij=sij/(siisij)1/2, i,j=1,…,p.
Первой задачей факторного анализа является определение по матрицеSилиRоценокlijфакторных нагрузок λijи оценокtiспецифических дисперсийϭi,i=1,…,p,j=1,..,m. Следует отметить, что предпочтение отдается корреляционной матрице, поскольку исследователи преимущественно работают со стандартизованными переменными.
Прежде всего определяются оценки р главных компонент:
 (4.68)
(4.68)
Напомним, что р главных компонент взаимно некоррелированы и дисперсияi-й компоненты равнаi-му по величине собственному значению выборочной ковариационной или корреляционной матрицы с соответствующим собственным вектором ai=(ai1,…,aip)’, i=1,..,p. Имеет место следующая система уравнений относительно исходных переменных:

Согласно методу определения главных факторов в качестве общих факторов берется m первых главных компонент, взвешенных следующим образом:
 , (4.69)
, (4.69)
где [V(Yj)]1/2 – средне-квадратичное отклонение
Оценками факторных нагрузок служат величины:
lij=aji[V(Yj)]1/2, i=1,…,p, j=1,…,m, (4.70)
а оценки специфических факторов задаются равенствами:
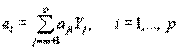 . (4.71)
. (4.71)
Таким образом, получается следующая оценка факторной модели:
 . (4.72)
. (4.72)
Здесь все общие факторы имеют единичные дисперсии и взаимно не коррелированы. Кроме того, они некоррелированы и со специфическими факторами.
Оценки общностейhiи специфичностиti для Xi, i=1,…,p имеют соответственно вид:
 (4.73)
(4.73)
В анализе главных компонент сохраняется дисперсия, содержащаяся в общих факторах (главных компонентах). В факторном анализе часто требуется получить оценки общих факторов, сохраняющие общность 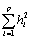 или всю дисперсию общих факторов. Поэтому пользователь может определить начальные оценки общностей всех исходных переменных и максимально допустимое число итераций, обеспечивающее сходимость к суммарной общности. Эти оценки подставляются вместо диагональных элементов матрицы, подлежащей факторному анализу. Получение оценок факторных нагрузок и новых общностей составляет шаг итерации. На следующем шаге диагональные элементы матрицы, подлежащей факторному анализу, заменяются на полученные общности. Затем заново определяются факторные нагрузки и общности. Процесс повторяется, пока не будет превышено максимально допустимое число итераций или пока максимальная разность общностей, полученных на соседних шагах итерации, не станет меньше заданного числа. Пользователь может оставить диагональные элементы без изменений и задать только допустимое число итераций, обеспечивающее сходимость к суммарной общности.
или всю дисперсию общих факторов. Поэтому пользователь может определить начальные оценки общностей всех исходных переменных и максимально допустимое число итераций, обеспечивающее сходимость к суммарной общности. Эти оценки подставляются вместо диагональных элементов матрицы, подлежащей факторному анализу. Получение оценок факторных нагрузок и новых общностей составляет шаг итерации. На следующем шаге диагональные элементы матрицы, подлежащей факторному анализу, заменяются на полученные общности. Затем заново определяются факторные нагрузки и общности. Процесс повторяется, пока не будет превышено максимально допустимое число итераций или пока максимальная разность общностей, полученных на соседних шагах итерации, не станет меньше заданного числа. Пользователь может оставить диагональные элементы без изменений и задать только допустимое число итераций, обеспечивающее сходимость к суммарной общности.
При определении числаmобщих факторов пользователь может руководствоваться следующими критериями:
1) число существенных факторов можно оценить из содержательных соображений;
2) при использовании обычной корреляционной матрицы рекомендуется в качестве m брать число собственных значений, больших либо равных 1;
3) как и в анализе главных компонент, можно выбрать число факторов, объясняющих определенную часть общей дисперсии, или суммарной общности.
Следует помнить, что в зависимости от выбора исходной матрицы могут получаться различные факторы.
Для интерпретации каждого фактора имеет смысл пользоваться переменными с относительно большими по абсолютной величине нагрузками, т.к. они больше всего коррелированы с этим фактором.
Кластерный анализ
Когда все входы количественные, альтернативной многомерной описательной моделью является модель, основанная на кластерном анализе. Кластерный анализ сопутствует самым разнообразным методам обнаружения структур, присущих сложным совокупностям данных. Как и при анализе главных компонент, основу данных чаще всего составляет выборка объектов, каждый из которых описывается набором отдельных переменных. Задача заключается в объединении переменных или элементов данной группы в такие кластеры, чтобы элементы внутри одного кластера обладали высокой степенью «естественной близости» между собой, а сами кластеры были «достаточно отличны» один от другого. И подход к проблеме, и получаемые результаты принципиально зависят от того, какой смысл вкладывает исследователь в выражения «естественная близость» и «достаточно отличны».
В общем случае кластерный анализ предполагает, что о структуре, внутренне присущей совокупности данных ничего не известно или известно лишь немногое. Все, что имеется в нашем распоряжении, это совокупность данных. Целью анализа в данном случае является обнаружение некоторой «категорной» структуры, которая соответствовала бы наблюдениям, и проблема часто формируется как задача отыскания «естественных групп». Сущностью кластерного анализа можно было бы с равным успехом считать и отыскание подходящего смысла для терминов «естественные группы» и «естественные ассоциации».
Кластерный анализ представляет собой попытку сгруппировать выборочные точки многомерного пространства в отдельные множества, которые, как мы надеемся, будут соответствовать наблюдаемым свойствам выборки. Группы точек могут быть, в свою очередь, сгруппированы в более крупные множества, так что в конечном счете все точки оказываются иерархически классифицированными. Эту иерархическую классификацию можно представить схематически, и обычно в такие схемы вводится некий масштаб, чтобы указать степень подобия различных групп. Одним из простейших типов кластерного анализа является анализ по методу «одного звена», который был предложен Снитом как удобный способ представления таксономических связей в форме дендрограмм. Связи между выборками выражаются через таксономические расстояния между каждой парой выборок, измеренные в некотором разумном масштабе. Метод заключается в такой сортировке выборок, которая определяет кластеры по возрастающему набору пороговых расстояний (d1,d2,…dn). Кластеры уровня di строятся следующим образом:
1. Выборки группируются путем объединения всех отрезков длины di или менее. Говорят, что каждое такое множество образует кластер уровня di, а длина всех отрезков, которые соединяют два кластера, определенных на уровне di, будет больше di.
2. После проведения сортировки при пороговом расстоянии di+1> di все кластеры уровня di сохраняются, но некоторые из них могут сливаться в большие кластеры. В действительности два кластера будут сливаться, когда между ними существует хотя бы одно звено такой длины d, что di< d ≤di+1. (Это свойство достаточности лишь одного звена для слияния кластеров и объясняет выражение «кластерный анализ по методу одного звена»).
Дендрограмма показывает, как кластеры уровня d1 объединяются на уровне d2 и т.д. на последующих уровнях, пока все выборки не сольются в единый кластер. На практике кластерный анализ по методу одного звена лучше всего провести, опираясь на понятие «дерева минимальной протяженности», т.е. дерева, соединяющего все точки набором прямолинейных отрезков некоторыми парами точек таким образом, что:
1) не возникает замкнутых петель;
2) каждая точка лежит хотя бы на одной прямой;
3) дерево является связным;
4) сумма длин отрезков минимальна.
На рис. 4.9 показан простой пример дерева с целочисленными длинами отрезков и общей длиной в 22 единицы.

Рисунок 4.9 – Дерево минимальной протяженностис целочисленными длинами отрезков
Применять кластерный анализ данных следует с определенной осторожностью, а сами методы должны опираться на строгую математическую формулировку задачи. Наметившаяся же тенденция рассматривать кластерный анализ как приемлемую альтернативу традиционным методам биологических наук достойна обсуждения, а для обобщения данных вместо самого кластерного анализа и классификации можно применять и другие методы. Но когда кластерный анализ используется лишь как одна из моделей системного анализа, он иногда оказывается весьма полезным и помогает прояснить некоторые свойства исходных данных. И вновь, как и ранее, лучше всего проиллюстрировать метод на простом примере, взятом из монографии Джефферса (1981). Рассмотрим анализ свойств 25 почв из национального парка Лейк-Дистрикт, применявшихся при исследовании реакции платана и березы на содержание питательных веществ в почве. Почвы были выбраны так, чтобы перекрыть как можно более широкий диапазон химических свойств и, в частности, свойств, связанных с содержанием фосфатов. Прежде чем использовать почвы в экспериментах по выяснению реакции платана и березы различного происхождения, необходимо было установить диапазон изменчивости свойств почвы и возможность их объединения в кластеры.
В табл. 4.42 приведены определенные для каждой из 25 почв значения семи переменных, а именно: потерь при прокаливании, количества фосфора, участвующего в изотопном обмене, фосфатазной активности, количества экстрагируемого железа, общего содержания фосфора, общего содержания азота и pH. Далее эти данные обобщены в табл. 4.43.
Таблица 4.42.– Значение семи переменных для 25 почв Лейк-Дистрикта
| Потери при прокаливании,% сухого веса | Кол-во фосфора, принявшего участие в изотопном обмене, мкг на 1 г сухого веса | Фосфатазная активность | Кол-во экстрагиро-ванного железа, мг на 100 г сухого веса | Общее кол-во фосфора, % сухого веса | Общее кол-во азота, % сухого веса | pH | |
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 1 19 20 21 22 23 24 25 | 15,21 33,27 68,09 32,89 19,87 16,46 10,56 15,63 11,15 16,25 9,94 70,63 9 19,71 26,02 11,84 10,71 8,3 12,67 15,92 12,92 7,54 21,96 88,78 72,19 | 70,6 67,5 1700,3 168,1 102,7 32,5 192,9 118,4 101,4 232,5 51,4 150,3 9,8 297,7 83,9 168,9 127,3 107,4 188,7 203,6 170,6 53,8 104,3 107,6 174,7 | 467,1 1059,8 3309,7 1392,9 71,3 367 352,4 300,2 308,4 306,2 212,3 627,7 129,7 467,9 618,3 375,8 330,3 241,4 516,4 336,9 319,6 315,7 578,8 1156,8 1061,3 | 1400 460 1200 2100 920 1100 1000 1900 1300 1600 1800 590 95 2200 2800 750 910 880 1300 1500 1600 890 1900 290 690 | 0,12 0,15 0,36 0,17 0,14 0,06 0,1 0,11 0,11 0,12 0,1 0,15 0,01 0,08 0,08 0,07 0,13 0,08 0,05 0,08 0,06 0,05 0,12 0,06 0,14 | 0,63 1,19 2,3 1,29 0,73 0,52 0,33 0,61 0,47 0,66 0,37 1,81 0,21 0,63 0,88 0,45 0,43 0,31 0,33 0,52 0,44 0,28 0,81 0,99 2,32 | 4,53 4,9 4,82 4,84 7,93 3,78 4,59 4,16 5,13 4,43 4,7 3,65 3,63 4,04 3,93 5,89 4,56 4,74 4,4 4,13 4,05 4,7 4,11 3,19 3,93 |
Таблица 4.43.– Обобщение данных для почв Лейк-Дистрикта
| Переменная | Минимум | Среднее | Максимум | Стандартное отклонение |
| Потери при прокаливании, % сухого веса Количество фосфора, принявшего участие в изотопном обмене, мкг на 1 г сухого веса Фосфатазная активность, мкг фенола на 1 г сухого веса почвы, 130С, 3ч Количество экстрагируемого железа, мг на 100 г сухого веса Общее содержание фосфора, % сухого веса Общее содержание азота, % сухого веса Ph воды | 7,54 9,8 71,3 95 0,01 0,21 3,19 | 25,5 191,48 608,96 1247 0,108 0,82 4,51 | 88,78 1700,3 3309,7 2800 0,36 2,32 7,93 | 23,26 321,37 653,68 644,44 0,065 0,634 0,909 |
Между каждыми двумя почвами можно вычислить расстояние в евклидовом пространстве по формуле:
dij= [(x1i-x1j)2+(x2i-x2j)2+(x3i-x3j)2+ +(x4i-x4j)2+ +(x5i-x5j)2+ +(x6i-x6j)2+
+(x7i-x7j)]1/2=  (4.74)
(4.74)
где dij– евклидово расстояние между i–й и j-й-почвами, xij – значение k–й случайной переменной для i–й почвы, нормализованное путем вычитания среднего по 25 почвам и деления на величину стандартного отклонения по 25 почвам. Для почв 1 и 2, например, это обобщенное расстояние равно

Поскольку это вычисление нужно проделать для всех возможных пар почв, т.е. для п(п-1)/2 (в данном случае для 300) пар, ясно, что без ЭВМ здесь не обойтись.
По половине матрицы расстояний между каждой парой почв можно найти дерево минимальной протяженности, также с помощью ЭВМ, применяя один из нескольких алгоритмов. Результаты расчетов представлены в табл. 4.44 и схематически изображены на рис. 4.10. Большинство почв несомненно близки по своим свойствам, однако некоторые (и в особенности почва № 3) существенно от них отличаются.
Таблица 4.44.– Дерево минимальной протяженности для почв Лейк-Дистрикта
| № почвы | № почвы, граничащий с данной | Расстояние | № почвы | № почвы, граничащий с данной | Расстояние |
| 2 3 4 5 6 7 8 9 10 11 12 13 | 17 4 23 16 20 9 10 1 1 8 2 22 | 2,09 6,83 1,93 2,62 0,96 0,85 0,68 0,8 0,65 0,82 2,44 1,84 | 14 15 16 17 18 19 20 21 22 23 24 25 | 8 14 18 7 7 21 10 20 18 8 25 12 | 0,92 1,27 1,35 0,55 0,52 0,72 0,75 0,41 0,51 0,62 1,84 1,11 |

Рис. 4.10 – Схематическое представление дерева минимальной протяженности
для почв Лейк-Дистрикта
Метод дерева минимальной протяженности является весьма ценным как сам по себе, так и при интерпретации результатов кластерного анализа, позволяя судить об адекватности кластеров по числу близких соседей, отнесенных к разным кластерам. Особенно полезен он при построении векторных диаграмм, которые иллюстрируют маломерные приближения для конфигураций в пространстве многих измерений. В рассмотренном выше примере вариабельность семимерна и всякая попытка изобразить ее в пространстве меньшей размерности будет неизбежно вносить некоторое искажение – о степени этого искажения можно судить путем наложения дерева минимальной протяженности на маломерное представление вариабельности. Так, на рис. 4.11 показано распределение 25 почв на двумерной плоскости (pH, количество экстрагируемого железа). Видно, что диаграмма дает неверное положение почвы № 3 – можно счесть, что она близка по своим свойствам к почвам № 1,9 и 19.

| Рисунок 4.11 – Проекция дерева минимальной протяженности на двумерную плоскость (рН, количество экстрагируемого железа) | Рисунок 4.12 – Проекция дерева минимальной протяженности на двумерную плоскость (рН, потери при прокаливании |
Еще более убедителен рис. 4.12, изображающий распределение 25почв на двумерной плоскости (pH, потери при прокаливании). Если бы не было дерева минимальной протяженности, можно было бы сделать вывод, что почвы № 2 и 4 сходны между собой, тогда как по всей совокупности признаков почва 2 ближе к почвам 7,12 и 17, а почва 4 – к почве 23.
Результаты кластерного анализа по методу одного звена, полученные выделением кластеров на дереве минимальной протяженности при пороговых расстояниях 0,75, 1,0, 1,25, 1,5 и т.д., приведены на рис. 4.13. Выявляется несколько тесно связанных кластеров (например, почвы 1,8, 10 и 23, почвы 7, 17, 18 и 22 и почвы 19, 20 и 21), сливающихся через отдельные почвы в основную группу почв Лейк-Дистрикта, для которой почва 3 и в меньшей степени почва 5 не типичны. Способ, которым следует выбирать почвы для экспериментального исследования реакции платана и березы на содержание в почве питательных веществ, определяется целями этого исследования. Если нужно, чтобы группы почв были достаточно однородны, используют лишь те почвы, которые связаны на низком уровне пороговых расстояний (т.е. почвы 1, 8, 10, 23, 7, 17, 18, 22, 9, 11, 14, 6, 19, 20 и 21). Если стремятся охватить весь диапазон изменений свойств почвы, то берут лишь некоторые из почв, принадлежащих разным кластерам, почвы, более или менее от них отличающиеся, и, разумеется, почву 3.

Рисунок 4.13 – Дендограмма кластерного анализа почв Лейк-Дистрикта
Дискриминантный анализ
Рассмотрим теперь прогностические модели. Модели, в которых по двум или более переменным предсказывается только одна случайная переменная, отличаются от моделей, где таких случайных переменных несколько. Множественный регрессионный анализ, несомненно, представляет собой один из типов прогностических моделей, позволяя предсказать значение одной случайной величины по значениям двух или более переменных, обычно именуемых регрессионными переменными. Для случаев, когда регрессионные переменные являются на самом деле случайными величинами, т.е. переменными, характеризующимися определенной относительной частотой или вероятностью, можно показать, что математически процедуры оценки остаются эквивалентными; они применимы даже тогда, когда модель оперирует одновременно и регрессионными случайными величинами, и регрессионными переменными. Поэтому при решении практических задач обычно не стоит задаваться вопросом, с какой моделью мы имеем дело – классической регрессионной моделью для переменных, моделью, оперирующей случайными величинами или обоими типами переменных одновременно, – нужно лишь, чтобы эти переменные были достаточно верными измерениями необходимых нам величин.
Таким образом, имея дело с одной предсказываемой случайной величиной, мы будем придерживаться в данной главе классической модели дискриминантного анализа, теоретические основы которой разработаны Фишером. Мы будем отличать модель, позволяющую сделать выбор между двумя группами и известную под названием дискриминантной функции, от модели, дающей разбиение на более чем две группы и именуемой моделью канонических величин.
В классической модели дискриминантной функции Фишера рассматривается задача, как наилучшим образом сделать выбор (дискриминацию) между двумя априорными группами, когда для каждого индивида измеряется несколько показателей (переменных). Модель дает такую линейную функцию измерений по каждой переменной, что индивида можно отнести к той или иной из двух групп с наименьшей вероятностью ошибиться. Дискриминантная функция записывается как
Z=a1x1+ a2x2+ amxm, (4.75)
где А=(а1,…,аm) – вектор дискриминантных коэффициентов, х=(х1,…хm) – вектор наблюдений или измерений, сделанных для индивида, которого нужно отнести к той или иной группе. Заметим, что в этой модели предполагается существование лишь двух групп и не считается, что если данный индивид не может быть с достаточной степенью определенности отнесен ни к одной из двух групп, то существуют еще какие-то группы. И вновь для иллюстрации применения модели лучше всего рассмотреть конкретный пример (Джефферс, 1981).
Сигни-Айленд принадлежит к группе Южных Оркнейских островов, расположенных в одном из морских регионов Антарктиды. Ближайшая материковая точка находится на Антарктическом полуострове и удалена примерно на 640 км, но иммиграция животных происходит с острова Южная Георгия, лежащего примерно в 900 км к северо-востоку, и с острова Огненная Земля, расположенного примерно в 1440 км к северо-западу.
При изучении растительности острова на карту Сигни-Айленда масштабом 1:25000 наносили произвольную сетку из квадратов по 500 м2. По картам, составленными научными экспедициями, оценивали переменные, характеризующие свойства среды в квадратах. Далее определяли площади внутри каждого квадрата, занятые различными типами растительности, и, в частности, отмечали, произрастают ли в данном квадрате сосудистые растения.
Предварительная обработка данных по переменным среды показывала, что полная вариабельность данных приблизительно семимерна и что число переменных среды можно поэтому уменьшить до семи без особых потерь информации. Значения этих семи переменных для 104 квадратов сетки сведены в табл. 4.45. Сосудистые растения были обнаружены в 22 квадратах. Возникает интересный вопрос: можно ли использовать семь переменных среды или некое их подмножество для того, чтобы предсказать наличие или отсутствие сосудистых растений в каком-то квадрате?
Таблица 4.45.– Переменные, характеризующие свойства средына острове Сигни-Айленд
| Переменная | Минимум | Среднее | Максимум | Стандартное отклонение |
| 1. Максимальная высота, м 2. Число контуров, разрезанных трансектой восток-запад 3. Склоны, обращенные на юг, % 4. Площадь, занятая озерами, % 5. Площадь, занятая согласно карте скалами 6. Площадь, занятая согласно карте, осыпями и оползнями, % 7. Расстояние до моря на восток, м | 5 0 0 0 0 0 0 | 140 7,5 19,2 1,2 13,3 27,2 1026 | 280 22 100 20 45 91 4100 | 79,3 5,44 25 3,47 9,12 25,8 1084 |
Для обеих групп квадратов измерялись одни и те же переменные, так что исходные данные можно представить в виде двух матриц, одна из которых имеет порядок n1×m, а вторая – n2×m. Так как сосудистые растения были обнаружены на 22 квадратах,
n1=22, n2=82, m=7,
где m – число измеряемых показателей, n1 – число наблюдений, относящихся к первой группе, n2 – число наблюдений, относящихся ко второй группе, n=n1+n2 – общее число наблюдений.
В табл. 4.46 приведена правая верхняя половина симметричной объединенной матрицы ковариаций1 для обеих матриц данных.
Таблица 4.46 – Объединенная матрица ковариаций для наборов данных
| 1 5310,961 | 2 199,8022 26,88293 | 3 194,8896 -25,31391 578,6623 | 4 -32,94015 1,559248 -4,799063 11,96896 | 5 -16,05446 12,8375 -36,08125 3,166493 83,73383 | 6 62,73615 42,83095 -116,5440 15,54125 44,49558 667,5128 | 7 12569,94 4,190566 -315,8835 62,82278 1250,437 2087,470 1175,907 |
Вектор дискриминантных коэффициентов а задается решением совместной системы уравнений, которая в матричной форме записывается какSa=d,где S обозначает объединенную матрицу ковариаций, а d является разностью между векторами средних для двух групп. Это уравнение легко разрешить, умножив слева обе его части на матрицу, обратную ковариационной, т.е.a=S-1d.
Матрица, обратная объединенной матрице ковариаций, приведена в табл. 4.47, где для удобства использована экспоненциальная форма записи чисел; эта матрица также симметрична относительно главной диагонали. Векторы средних, вектор разностей между ними и вектор дискриминантных коэффициентов приведены в табл. 4.48.
Таблица 4.47.– Матрица, обратная объединенной матрице ковариаций
| 3,236548Е-4 | -2,98233Е-3 0,07199744 | -1,895112Е-3 2,899737Е-3 1,965440Е-3 | 9,9986822Е-4 -0,01020711 -4,002193Е-4 0,0897032 | 4,140633Е-4 -9.022103Е-3 2,661735Е-4 -8,298558Е-4 0,01397195 | 8,999152Е-5 -3,144589Е-3 1,602335Е-4 -1,504498Е-3 -2,672139Е-4 1,783831Е-3 | -4,153426Е-6 4,812380Е-6 1,997326Е-6 -1,198577Е-5 -1,866131Е-5 -3,709850Е-6 9,222408Е-7 |
Таблица 4.48.– Векторы средних разностей между нимии вектор дискриминантных коэффициентов
| Переменная | Среднее для площадок, на которых произрастают сосудистые растения | Среднее для площадок, на которых сосудистые растения отсутствуют | Разность | Дискриминант-ная функция |
| 1 2 3 4 5 6 7 | 78,1818 4,2273 5,6818 0,3182 14,2273 30 825 | 123,5096 6,6538 18,0385 1,125 10,2596 20,8558 851,9232 | -45,3278 -2,4265 -12,3567 -0,8068 3,9677 9,1442 -26,9232 | -8,799238Е-3 -0,1421932 -0,0301576 -0,1312235 0,02264888 0,01204919 -1,693091Е-4 |
Далее определяется критерий Хотеллинга Т2 по формуле
 , (4.76)
, (4.76)
а значимость критерия Т2 оценивается по критерию отношения дисперсий согласно выражению
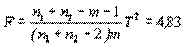 (4.77)
(4.77)
со степенями свободы m=7 и (n1+n2-m-1)=96. Если бы обе группы принадлежали одной и той же популяции, то вероятность получить столь высокое значение F была бы равна примерно 0,00011.
Таким образом, функция
Z= -0,0088x1-0,142x2-0,0302x3-0,131x4+0,0226x5+0,012x6-0,000169x7
дает значимую дискриминацию между квадратами по 500 м2, на которых произрастают сосудистые растения, и квадратами, где они не произрастают. Значение функции Z (дискриминантные показатели) вычисляется для каждого квадрата из двух групп, а центры дискриминантных показателей оказываются равными -0,959 и –3,029 для групп с сосудистыми растениями и без них соответственно.
Разность между дискриминантными центрами групп называется «обобщенным расстоянием» между группами или расстоянием Махаланобиса; его можно вычислить, используя значение Т2, по формуле
 (4.78)
(4.78)
или более прямо из соотношения
D2=d’S-1d=2,07. (4.79)
Мера эффективности, с которой вычисляемая дискриминантная функция может использоваться для классификации произвольного индивида, задается стандартным нормальным отклонением
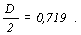
Табличные значения нормального распределения вероятностей, соответствующего такому отклонению, показывают, что примерно 76% индивидов будут правильно отнесены к своим группам с помощью данной дискриминантной функции.
Вычисление дискриминантных показателей позволяет рассматривать исходно выбранные объекты как два класса точек, рассеянных по одной прямой, с центрами, соответствующими центрам дискриминантных показателей. Ценность дискриминантной функции состоит в том, что она, во-первых, позволяет определить влияние основных переменных на дискриминацию, а во-вторых – вычислить дискриминантный показатель для любого нового квадрата и либо отнести последний к одной из двух групп, либо решить, что не принадлежит ни к одной из них. Нам может понадобиться определить, например, какова вероятность того, что в каком-то произвольном квадрате площадью 500 м2, наложенном на карту Сигни-Айленда, будут обнаружены сосудистые растения, с тем чтобы решить, стоит ли затрачивать усилия на поиски этих растений в довольно суровых полевых условиях.
Если две группы, по которым вычислялись дискриминантные коэффициенты, одинаково представлены в популяции, откуда извлечены выборки, то границей, по которой мы будем относить неклассифицированный индивид к одной из двух групп, разумно считать середину расстояния между центрами групп. Так, квадраты, с дискриминантным показателем меньше -1,994, нужно было бы отнести к группе, где сосудистых растений нет, тогда как квадраты с дискриминантным показателем больше -1,994 к группе, где такие растения произрастают.
Когда две группы представлены в популяции неодинаково, граница разбиения должна быть смещена от середины между центрами в сторону меньшей группы на расстояние
 ,
,
где R равно отношению числа индивидов в большей группе к их числу в меньшей группе. Если мы можем считать, что рассматриваемые квадраты представляют собой несмещенную выборку из популяции всевозможных квадратов, то R=п2/п1= 3,727 и 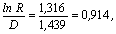 т.е. границу разбиения следует перенести из –1,994 в –1,08.
т.е. границу разбиения следует перенести из –1,994 в –1,08.
Вопросы для самопроверки:
1. Линейный корреляционный анализ.
2. Частные и множественные коэффициенты корреляции.
3. Линейный регрессионный анализ.
4. Эмпирическая линия регрессии.
5. Линейная регрессия.
6. Нелинейный корреляционный и регрессионный анализы.
7. Корреляционное отношение. Критерии нелинейности связи.
8. Нелинейная регрессия.
9. Множественная регрессия.
10. Аллометрическая функция.
11. Дисперсионный анализ.
12. Логическая схема дисперсионного анализа. Составление однофакторного дисперсионного комплекса.
13. Двухфакторный комплекс.
14. Анализ главных компонент.
15. Факторный анализ.
16. Определение главных факторов.
17. Кластерный анализ.
18. Дискриминантный анализ.
Рекомендуемая литература:[4, 5, 9, 13-16, 21].
Дата добавления: 2018-04-15; просмотров: 1062; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!