Тема 4.МНОГОМЕРНЫЕ МОДЕЛИ И МЕТОДЫ ИССЛЕДОВАНИЯ ПОПУЛЯЦИЙ И ЭКОСИСТЕМ
В экологических исследованиях и других приложениях системного анализа, как правило, решение различных проблем и разработка моделей связаны с анализом множества переменных. Такие модели называются «многомерными», и они связаны с методами, которые в совокупности именуются «многомерным анализом» – выражение, достаточно широко используемое для обозначения методов обработки данных, которые являются многомерными в том смысле, что каждый представитель (индивидуум или группа) порождает значения р переменных. Математический аппарат, основанный на многомерных нормальных распределениях, был разработан в 30-е годы прошлого столетия и методы, разработанные в то время, служат основой большинства многомерных методов, применяемых и по сей день. Как правило, вычисления, необходимые для многомерного анализа и построения многомерных моделей, довольно громоздки и зависят от количества рассматриваемых переменных (р) и требуют значительных вычислительных ресурсов. В данной главе мы рассмотрим основные многомерные модели, которые применяются в настоящее время и имеются в современных статистических пакетах для ПЭВМ с примерами для анализа биосистем.
Прежде всего эти модели можно разделить на две основные категории, а именно: модели, в которых одни случайные величины используются для предсказания значений других, и модели, где переменные одного типа и не делается попыток предсказать одно множество значений по другому. Последнюю категорию моделей, которые в целом называются описательными, можно далее подразделить на модели, у которых все входы количественные и которые используют анализ главных компонент и кластерный анализ, и модели, у которых, по крайней мере, некоторые из входов не количественные, а качественные. Для последних больше подходит модель взаимного осреднения. Прогностические модели, в свою очередь, могут быть подразделены по числу предсказываемых случайных величин, а затем по тому, являются ли все прогнозы количественными. Если предсказывается несколько величин, наиболее приемлемой оказывается модель канонического анализа. Если же предсказываемая величина только одна и a priori имеется две группы индивидов, наиболее подходящей из имеющихся моделей оказывается модель дискриминантного анализа, в то время как более чем для двух априорных групп индивидов наиболее плодотворным оказывается подход, основанный на применении канонических переменных, хотя это и не исключает использование попарных дискриминантных функций.
|
|
|
Линейный корреляционный анализ
Корреляционный анализ – один из методов исследования взаимосвязи между двумя или более переменными. Многие многомерные модели основаны на анализе корреляционных или связанных с ними ковариационных таблиц, построенных для множества переменных.
|
|
|
Термин «корреляция», буквально означающий «соотношение» или «взаимосвязь», имеет следующий смысл: корреляция есть наличие взаимной согласованности в изменчивости двух или нескольких признаков, явлений. Корреляционный анализ изучает сопряженную изменчивость двух или нескольких признаков. Работа по проведению корреляционного анализа начинается с построения корреляционных решеток (табл. 4.1). Пусть имеется выборка наблюдений (х, у) из популяции W. Причем х и у – случайные величины. Корреляционная решетка для двух переменных (признаков) представляет собой таблицу из m×к клеток, где m и к – число значений признаков х и у. Значения признаков удобно располагать в возрастающем порядке слева направо для х и сверху вниз для у. В клетках таблицы производят разноску сопряженных частот fxy (число наблюдений со значениями признаков х и у) в зависимости от значений двух признаков одновременно.
Таблица 4.1.– Схема корреляционной решетки
| х У | Х1 | Х2 | Х3 | … | Хk | fy |
| Y1 Y2 Y3 … ym | F11 F21 F31 Fm1 | F12 F22 F32 Fm2 | F13 F23 F33 Fm3 | … … … … | F1k F2k F3k Fmk | Fy1 Fy2 Fy3 Fym |
| fx | Fx1 | Fx2 | Fx3 | … | Fxk | n |
fx , ,fy – частоты вариационных рядов,fij– сопряженные частоты,
n– объем выборки, х, у – значения признаков:
|
|
|
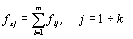 (4.1)
(4.1)
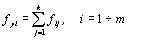 (4.2)
(4.2)
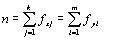 (4.3)
(4.3)
Для расчета коэффициента корреляции необходимо предварительно рассчитать некоторые статистики (средние значения, дисперсию, среднеквадратичное отклонение, корреляционный момент) по следующим формулам:
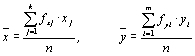 – средние (4.4)
– средние (4.4)

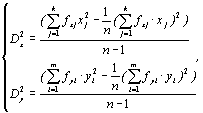 – дисперсии (4.5)
– дисперсии (4.5)
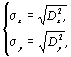 – среднеквадратичные отклонения (4.6)
– среднеквадратичные отклонения (4.6)
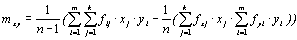 , (4.7)
, (4.7)
mxy – корреляционный момент.
Для удобства расчетов рекомендуется заполнить табл. 4.2
Таблица 4.2.– Таблица для расчета коэффициента линейной корреляции
| Х у | Х1 | Х2 | … | Хк | fyi | fyiyi | 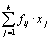
| Y2i*fyi | 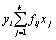
|
| Y1 | f11 | f12 | … | f1k | |||||
| Y2 | f21 | f22 | … | f2k | |||||
| … | … | … | … | … | |||||
| ym | fm1 | fm2 | … | fmk | |||||
| fxj | |||||||||
| fxj · xj | |||||||||
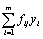
| |||||||||
| fxj · x2j | |||||||||
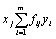
|
Коэффициент линейной корреляции рассчитывается по формулам:

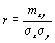 (4.8)
(4.8)
или 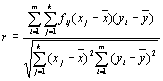 . (4.9)
. (4.9)
|
|
|
Вычисления по второй формуле более громоздки, т.к. отклонения от средней находятся для каждой сопряженной частоты.
Значение коэффициента корреляции заключено в пределах от -1 до 1. Положительное значение коэффициента указывает, что У имеет тенденцию возрастать совместно сХ, отрицательное наоборот – Ууменьшается с возрастаниемХ. Экстремальное значение (-1 или +1) соответствует полной линейной зависимости между Х и У. Чем ближе коэффициент корреляции к 1, тем ближе зависимость к линейной.
Дата добавления: 2018-04-15; просмотров: 570; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!