Design and development of databases. Technology of programming of ORM. The distributed, parallel and heterogeneous databases.
Design of databases — process of creation of the database scheme and determination of necessary integrity constraints.
Main objectives of design of databases:
• Support of storage in a DB of all necessary information.
• A data acquisition possibility on all necessary requests.
• Abbreviation of redundance and duplicating of data.
• Support of integrity of the database.
Main design stages of databases
Conceptual design — creation of a semantic domain model, that is information model of the highest level of abstraction. Such model is created without orientation to any specific DBMS and a data model. The terms "semantic model", "conceptual model" are synonyms.
The specific type and the maintenance of conceptual model of the database is defined by the formal device selected for this purpose. Graphic notations, similar to ER charts are usually used.
Most often the conceptual model of the database includes:
• description of information objects or concepts of data domain and communications in between.
• description of integrity constraints, that is requirements to admissible values of data and to communications in between.
Logic design — creation of the database scheme on the basis of a specific data model, for example, a relational data model. For a relational data model data logical model — a set of diagrams of the relations, it is normal with specifying of primary keys, and also the "communications" between the relations representing foreign keys.
Conversion of conceptual model to a logical model is, as a rule, carried out by the formal rules. This stage can be substantially automated.
At a stage of logic design specifics of a specific data model are considered, but specifics of specific DBMS can not be considered.
Physical design — creation of the database scheme for specific DBMS. Specifics of specific DBMS can include restrictions for naming of database objects, restrictions for the supported data types, etc. Besides, specifics of specific DBMS in case of physical design include a choice of the decisions connected to a physical medium of data storage (a choice of methods of management of disk memory, division of a DB according to files and devices, data access methods), creation of indexes etc.
What is ORM?
ORM or Object-relational mappingis a technology of programming which allows to transform incompatible types of models to OOP, in particular, between the data store and subjects to programming. ORM is used for simplification of process of saving objects in a relational database and their extraction, in case of this ORM itself cares for data transformation between two incompatible statuses. The majority of ORM tools considerably rely on meta data of the database and objects so objects need to know nothing about a database structure, and the database — nothing about how data are organized in the application. ORM provides complete division of tasks in well programmed applications in case of which both the database, and the application can work dataful everyone in the root form.
|
|
|
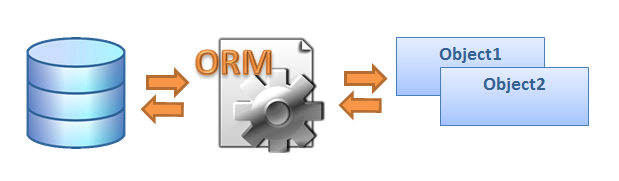
Fugure1- ORM`s work
Principle of operation of ORM-Key feature of ORM is display which is used for an object binding to its data in a DB. ORM as if creates the "virtual" database scheme in memory and allows to manipulate data already at the object level. Display shows as an object and its properties are connected to one or several tables and their fields in the database. ORM uses information of this display for process control of data transformation between a basis and forms of objects, and also for creation of SQL queries for an insertion, up-dating and deleting data in response to changes which the application makes to these objects.
Distributed database – a set of the separated data which are logically connected among themselves (and their descriptions) which are physically distributed on some computer network. The distributed DBMS – the program complex intended for control of distributed databases and allowing to make distribution of information of the transparent for the ultimate user.
Users interact with a distributed database through applications. Applications can be classified as those which don't require data access on other websites (local applications), and those which require similar access (global applications).
One of approaches to integration of object-oriented applications with relational databases consists in development of heterogeneous information systems. Heterogeneous information systems facilitate integration of the heterogeneous information sources structured (with existence of the regular (normalized) diagram), semistructured and sometimes even unstructured. Any heterogeneous information system is constructed on the global database scheme over databases of components so users get advantages of the diagram, that is uniform interfaces of access (for example, the sql-style interface) to the data saved in different databases and rich functional capabilities. Such heterogeneous information system is called system of the integrated multi-databases.
|
|
|
Formation of the database management systems (DMS) matched on time the considerable progress in development of technologies of the distributed computation and parallel processing. Distributed control systems databases and parallel database management systems resulted. These systems become the dominating tools for application creation of intensive data handling.
The parallel computer, or the multiprocessor in itself is the distributed system made of the nodes (processors, memory components) connected by a bystry network in the general casing. The technology of distributed databases can be naturally reconsidered and widespread on parallel database systems, i.e. database systems on parallel computers
The distributed and parallel DBMS provides the same functionality, as host-based DBMSes, except for the fact that they work in the environment where data are distributed on nodes of a computer network or the multiprocessor system.
Questions:
1. Why are relationships a significant aspect of databases?
2. What’s the difference between flat files and other database models?
3. What is ORM?
4. Principle of operation of ORM?
5. ORM or Object-relational mapping?
References
1. June J. Parsons and Dan Oja, New Perspectives on Computer Concepts 16th Edition - Comprehensive, Thomson Course Technology, a division of Thomson Learning, Inc Cambridge, MA, COPYRIGHT © 2014.
2. Lorenzo Cantoni (University of Lugano, Switzerland) James A. Danowski (University of Illinois at Chicago, IL, USA) Communication and Technology, 576 pages.
Lecture №11. Data analysis.
Purpose: to give a common concepts of correlation, regression, and also to become acquainted with descriptive statistics.
|
|
|
Plan:
1. Data analysis bases.
2. Methods of collection, classification and prediction. Decision trees.
Data analysis bases.
Data miningis process of performing automated extraction and genariting predictive information from large data banks. DM includes analysis of observational data sets to find unsuspected, previously unknown relationships and summarize the data in new ways that are both understandable and useful for the data owner.
Relationships and summaries derived through a data mining are often reffered to as models or patterns. Examples include linearequations, rules, clusters, graphs, tree structures, and recurrent patterns in time series. It should be noted that the discripline typically deals with data thst have alreadybeen collected for some purpose other than the data mining analysis (for example, they may have been collected inorder to maintain up-to-date record of all transactions in a bank). This means that the objectibes of the data mining ususlly play no role in the data collection strategy. This is one of the ways in which it differs from many statistics in which data are often collected by using efficient strategies to answer sfecific questions.
DM, populary referred to Knowladge Discovery in Databases (KDD), is an automated or convenient extraction of patterns representing knowledge implicitly stored or captured in large databases which can contain millions of rows related to Database subject, Data Warehouses, Web, other massive information repositories or data streams.
So, readers (who we suppose know about Database system structure ) can recognize main differences between conventional Database System and DWH which include Data mining, Analysis (as parts of knowledge discovery in databases), OLAP Engine (Online Analytics Processes instead of or additionally to Online Transaction Processes) DW/Marts servers (setof servers for different departments of enterprises), Back Ground process/preprocessing (e.g. Cleaning – solving problem with missing data, noise data) and etc.
Remark about the history of terms
[fromhttps://en. wikipedia.org/wiki/Data_mining]:
|
|
|
Gregory Piatetsky-Shapiro coined the term “Knowledge Discovery in Databases” for the first workshop on the same topic (KDD-1989) and this term became more popular in AI and Machine Learning Community. However, the term Data mining (1990) became more popular in the business and press communities. Currently, Data Mining and Knowledge Discovery are used interchangeably. The terms “Predictive Analytics” (since 2007) and “Data Science” (since 2011) have also been used to describe this field.
Actually, we can say that DM is a step in the KDD process concerned with the algorithms, variety of techniques to identify decision supports, prediction, forecasting and estimation using pattern recognition techniques as well as statistical and mathematical techniques.
Basic Data Mining Models and Tasks
DM involves many different algorithms to accomplish different tasks. All these algorithms attempt to fit a model to the data. The model that is created can be either predictive or descriptivein nature. Figure 6.2 represents the main DM tasks used by that type of model.
Predictive model enables to predict the values of data by using known results from different sets of sample data.
Classification enables to classify data from a large data bank into predefined set of classes. The classes are defined before studying or examining data in the data bank. Classification tasks enable not only to study and examine the existing sample data but also to predict the future behavior of that sample data. For example, the fraud detection in credit card related transaction to prevent material losses; estimation of the probability of an employee to leave an organization before project’s end are some of the tasks that you determine by applying the technique of classification.
Regressionis one of statistical techniques which enable to forecast future data values based on the present and past data values. Regression task examines the values of data and develops a mathematical formula. The result produced on using this mathematical formula enables to predict future value of existing or even missed data. The major drawback of regression is that you can implement regression on quantitative data such as speed and weight to predict future behavior of them.
Time series analysisis a part of Temporal miningenabling to predict future values for the current set of values which are time dependent. Time series analysis makes to use current and past sample data to predict the future values. The values that you use for time series analysis are evenly distributed hourly, daily, weekly, monthly, yearly and so on. You can draw a time-series plot to visualize the amount of changes in data for specific changes in time. You can use time series analysis for examining the trends in the stock market for various companies for as specific period and making investments accordingly.
Essence of a descriptive modelsis a determination of the pattern and relationships in a sample data:
Clusteringis a data processing in some sense opposite to classifications which enables you to create new groups and classes based on the study of patterns and relationship between values of data in a data bank. It is similar to classification but does not require predefining the groups or classes. Clustering technique is otherwise known as unsupervised learningor segmentation.All these data items that resemble more closely with each other are clubbed together in a single group, also known as clusters. Examples include groups of companies producing similar products, or soils having the same properties (e.g., black soil), a group of people with the same habits, etc.
Summarizationis a technique which enables to summarize a large chunk of data contained in a Web page or a document. The study of this summarized Data enables to get the gist of the entire Web page or the document. Thus, summarization is also known as characterization or generalization. Summarization searches for specific characteristics and attributes of data in the large set of the given data and then summarizes the same. An example of the use of summarization technology is search engines such as Google. Other examples include document summarization, image collection summarization and video summarization. Document summarization tries to automatically create a representative summary or abstract of the entire document, by finding the most informative sentences.
Association rules enable to establish association and relationships between large unclassified data items based on certain attributes and characteristics. Associaton rules define certain rules of associativity between data items and then use these rules to establish relationships.Sequence discovery determines the sequential patterns that might existin a large and unorganized data bank. You discover the sequence in a data bank by using the time factor i.e., you associate the data items with the time at which it is generated. The study of sequence of events in crime detection and analysis enables security agencies and polise organizations to solve a crime mystery and take preventative measures that can be taken against such strange and unkown diseases.
Дата добавления: 2018-04-15; просмотров: 7259; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!