Эмпирическая функция распределения
Введение При выполнении курсового проекта по математической статистике возникает много вопросов как по поводу теоретического обоснования применяемых процедур, так и по поводу их практической реализации. В данном пособии приводятся подробные схемы вычислений в рамках популярного компьютерного приложения MS Excel. Теоретические основы применяемых процедур даются в пособии [4]. Работу над курсовым проектом следует начать с изучения главы I “Предварительные понятия и определения” теоретического пособия [4]. Эта глава будет весьма полезна при подготовке ответов на контрольные вопросы. Выполнение каждого задания лучше всего начинать с изучения теоретического обоснования тех процедур, которые рассматриваются в этом задании. Причем желательно изучить весь материал заранее, до проведения соответствующего занятия в компьютерном классе. В конце каждого задания приведены варианты контрольных вопросов, которые могут быть заданы студенту при сдаче всего курсового проекта.
Задания
Задание 1.Вычислить выборочные характеристики – среднее, дисперсию, стандартное отклонение, асимметрию, эксцесс.
Задание 2.Построить гистограмму выборки с подогнанной нормальной (равномерной, экспоненциальной) плотностью.
Задание 3.Построить эмпирическую функцию распределения выборки с подогнанной нормальной (равномерной, экспоненциальной) функцией распределения.
|
|
|
Задание 4.Проверить гипотезу нормальности (равномерности, экспоненциальности) выборочных данных.
Задание 5.Проверить гипотезу однородности по одновыборочному критерию Стьюдента.
Задание 6.Проверить гипотезу однородности по критерию знаков.
Задание 7.Проверить гипотезу однородности по двухвыборочному критерию Стьюдента.
Задание 8.Проверить гипотезу однородности по критерию Вилкоксона.
Задание 9.Проверить гипотезу равенства дисперсий.
Задание 10.Проверить гипотезу однородности по критерию хи-квадрат.
Задание 11.Построить доверительные границы для среднего значения нормального распределения.
Задание 12.Построить доверительные границы для дисперсии нормального распределения.
Задание 13.Построить доверительные границы для вероятности успеха.
Задание 14.Проверить гипотезу независимости признаков по критерию сопряженности хи-квадрат.
Задание 15.Проверить гипотезу независимости по критерию Стьюдента.
Задание 16.Построить линии регрессии.
Данные
Все примеры выполнения заданий основаны на следующих данных.
К заданиям 1 – 4, 13.
| 119,3 | 122,1 | 120 | 120,2
| 122,8 | 121,8 | 120,8 | 124,6 | ||
| 121,9 | 120,3 | 120,2 | 120,7 | 120,9 | 120,2 | 121,7 | 119 | ||
| 122,2 | 119,2 | 120 | 121,2 | 120 | 121 | 123 | 124,2 | ||
| 121,5 | 120,7 | 121 | 120,1 | 120,1 | 122 | 119,6 | 120,3 | ||
| 121,5 | 119,6 | 120,6 | 121,4 | 124,1 | 119,4 | 122 | 123,7 | ||
| 122,9 | 121,9 | 121,9 | 119,9 | 121,4 | 122,7 | 118,8 | 123 | ||
| 119,8 | 121,4 | 120,1 | 121 | 120,9 | 120,9 | 121,9 | 121,4 | ||
| 120,8 | 119,4 | 120,1 | 119,9 | 120,3 | 119,9 | 120,8 | 122,6 | ||
| 121,9 | 121,4 | 120 | 120,6 | 122,5 | 119,4 | 119,2 | 120,1 | ||
| 119,3 | 123,4 | 120,1 | 121,1 | 120,2 | 121,3 | 120,6 | 122,1 | ||
| 120,3 | 120,7 | 119,1 | 119,8 | 121,7 | 118 | 122,1 | |||
| 122,7 | 120,3 | 120,9 | 120,4 | 121,5 | 120,7 | 124,2 | |||
| 120,1 | 122,8 | 123,1 | 121,2 | 119,8 | 118,6 | 121,4 |
Число интервалов для гистограммы – 10, первая граница – 117,05, длина интервала – 1.
К заданиям 5, 6.
| До | 186 | 170,4 | 179,4 | 154,3 | 152,9 | 179,7 |
| После | 157,1 | 152,6 | 149,3 | 156,2 | 159,7 | 154,1 |
|
|
| |||||
| До | 173,3 | 162,9 | 168,8 | 161,8 | 162,3 | 163,2 |
| После | 148,7 | 148,3 | 157,4 | 161 | 151,7 | 168,5 |
|
|
| |||||
| До | 173,3 | 173,1 | 178,8 | 169,8 | 166 | 167,2 |
| После | 164,9 | 168 | 157,7 | 129,9 | 146,7 | 143 |
К заданиям 7, 8, 9.
| 1-я выборка | 159,3 | 158,9 | 163,1 | 169,8 | 161,2 | 158,1 |
| 2-я выборка | 143,4 | 158,8 | 167,3 | 163,4 | 163,8 | 174,9 |
|
|
| |||||
| 1-я выборка | 191 | 151,4 | 143,5 | 166,5 | 173,1 | 184,1 |
| 2-я выборка | 166 | 148,7 | 163,6 | 199,9 | ||
|
|
|
К заданию 10.
| Группы | 1-я | 2-я | 3-я | 4-я | 5-я | 6-я |
| 1-я выборка | 6 | 15 | 28 | 39 | 10 | 2 |
| 2-я выборка | 5 | 11 | 12 | 17 | 13 | 2 |
К заданиям 11, 12.
| 3,9 | 4,1 | 4,19 | 4,09 | 3,9 | 4,87 | 4,51 | 4,52 |
| 4,94 | 4,83 | 4,65 | 3,55 | 4,29 | 4,62 | 3,8 |
|
| 5,26 | 4,58 | 4,7 | 4,32 | 3,49 | 3,81 | 5,13 |
|
К заданиям 14 – 16.
| X | Y | X | Y | X | Y | X | Y | |||||
| 119,3 | 56,1 | 120 | 56,9 | 122,8 | 52 | 120,8 | 49,8 | |||||
| 121,9 | 63,1 | 120,2 | 56,3 | 120,9 | 58,4 | 121,7 | 54,1 | |||||
| 122,2 | 54,2 | 120 | 54,2 | 120 | 54,1 | 123 | 55,3 | |||||
| 121,5 | 55,8 | 121 | 53,7 | 120,1 | 55,8 | 119,6 | 55,7 | |||||
| 121,5 | 56,7 | 120,6 | 55,5 | 124,1 | 53,6 | 122 | 51,5 | |||||
| 122,9 | 54,5 | 121,9 | 56 | 121,4 | 60,8 | 118,8 | 49,5 | |||||
| 119,8 | 57,6 | 120,1 | 55,5 | 120,9 | 54,3 | 121,9 | 52,5 | |||||
| 120,8 | 52,2 | 120,1 | 53,6 | 120,3 | 50,6 | 120,8 | 52,3 | |||||
| 121,9 | 53,7 | 120 | 55,8 | 122,5 | 55,1 | 119,2 | 55,6 | |||||
| 119,3 | 57,6 | 120,1 | 52,1 | 120,2 | 55 | 120,6 | 50,4 | |||||
| 120,3 | 57,1 | 119,1 | 53,7 | 121,7 | 54,5 | 122,1 | 52,3 | |||||
| 122,7 | 56,8 | 120,9 | 56 | 121,5 | 54,9 | 124,2 | 53,2 | |||||
| 120,1 | 58,4 | 123,1 | 57,4 | 119,8 | 53,3 | 121,4 | 57,8 | |||||
| 122,1 | 60,7 | 120,2 | 53,6 | 121,8
| 57,2 | 124,6 | 54,5 | |||||
| 120,3 | 56,9 | 120,7 | 53,5 | 120,2 | 54,4 | 119 | 52,5 | |||||
| 119,2 | 52,7 | 121,2 | 52,7 | 121 | 55,4 | 124,2 | 49,9 | |||||
| 120,7 | 56,8 | 120,1 | 53,9 | 122 | 56,1 | 120,3 | 52,3 | |||||
| 119,6 | 51,8 | 121,4 | 53,7 | 119,4 | 49,8 | 123,7 | 53,5 | |||||
| 121,9 | 58,1 | 119,9 | 53,8 | 122,7 | 54,9 | 123 | 52,8 | |||||
| 121,4 | 55,3 | 121 | 57,9 | 120,9 | 53,4 | 121,4 | 53,3 | |||||
| 119,4 | 60,2 | 119,9 | 56,3 | 119,9 | 51,8 | 122,6 | 48,9 | |||||
| 121,4 | 54,2 | 120,6 | 53,1 | 119,4 | 54,3 | 120,1 | 51,6 | |||||
| 123,4 | 55 | 121,1 | 54,2 | 121,3 | 54,7 | 122,1 | 51,8 | |||||
| 120,7 | 53,3 | 119,8 | 50,4 | 118 | 51,5 | |||||||
| 120,3 | 56,4 | 120,4 | 55,4 | 120,7 | 56,2 | |||||||
| 122,8 | 55,3 | 121,2 | 53,6 | 118,6 | 50,4 |
Первая граница для признака X – 119,65, шаг – 1,6;
для признака Y – 52,55, шаг – 1,5.
Задание 0.
Основы математической статистики.
Постановка задачи.
Изучите основные понятия и методы, необходимые для выполнения курсового проекта по математической статистике.
Вероятностные характеристики: функция распределения, функция плотности, квантиль распределения, верхняя квантиль распределения, нормальная модель, экспоненциальная модель, модель равномерного распределения, биномиальная модель.
Основные понятия математической статистики: выборка, статистика, оценка, решающая функция, состоятельность, несмещенность, задача проверки гипотезы, вероятности ошибок 1-го и 2-го рода, размер критерия, уровень значимости, критический уровень значимости.
Теоретические основы.
См. стр. 5-22 пособия [4].
Контрольные вопросы.
1. Что такое функция распределения (функция плотности)?
Ответ: см. [4] стр. 14.
2. Что такое функция надежности?
Ответ: см. [4] стр. 14.
3. Какая случайная величина имеет нормальное распределение (показательное, равномерное, биномиальное, хи-квадрат, Стьюдента)?
Ответ: см. [4] стр. 16-22.
4. Запишите формулу нормального закона распределения (экспоненциального, равномерного, биномиального).
Ответ: см. [4] стр. 16-22.
5. Какой смысл несут параметры нормального распределения (экспоненциального, биномиального, хи-квадрат, Стьюдента)?
Ответ: см. [4] стр. 16-22.
6. Чему равны среднее значение и дисперсия экспоненциального распределения (нормального, биномиального)?
Ответ: см. [4] стр. 16-22.
7. Что такое квантиль распределения (верхняя квантиль)?
Ответ: см. [4] стр. 15.
8. Как связаны функция распределения и её верхняя квантиль?
Ответ: см. [4] стр. 15.
9. Найдите по таблице значение верхней 7%-й квантили для распределения хи-квадрат при 15 степенях свободы (для нормального распределения, для распределения Стьюдента).
Ответ: см. [4] стр. 17-20.
10. Что такое выборка?
Ответ: см. [4] стр. 5.
11. Что такое оценка?
Ответ: см. [4] стр. 10.
12. Дайте определение состоятельности оценки и проинтерпретируйте смысл этого определения.
Ответ: см. [4] стр. 12.
13. Можно ли сказать, что состоятельная оценка лучше не состоятельной оценки?
14. Дайте определение несмещенности оценки и проинтерпретируйте смысл этого определения.
Ответ: см. [4] стр. 10.
15. Можно ли сказать, что несмещенная оценка лучше смещенной оценки?
16. Как следует выбирать нулевую гипотезу?
Ответ: см. [4] стр. 7.
17. Как определяется вероятность ошибки 1-го рода? Что такое размер критерия?
Ответ: см. [4] стр. 7.
18. Что такое уровень значимости?
Ответ: см. [4] стр. 7.
19. Какой уровень значимости лучше выбрать – 5% , 10% или 1%?
Ответ: см. [4] стр. 7-8.
20. Как часто мы будем ошибаться, если будем применять критерий уровня  .
.
Ответ: см. [4] стр. 7.
21. Как построить критерий заданного уровня, основываясь на значениях некоторой статистики 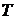 ?
?
Ответ: см. [4] стр. 8.
22. Можно ли признать новый метод лечения лучше старого, если при клинических испытаниях результативность нового метода составила 85%, а старого – 70%? Что ещё нужно знать, что бы правильно ответить на этот вопрос?
Ответ: см. [4] стр. 8.
23. Что такое критический уровень значимости? Чем он отличается от уровня значимости?
Ответ: см. [4] стр. 7, 9.
24. Следует ли принять гипотезу, если критический уровень значимости равен  ?
?
Ответ: см. [4] стр. 9.
Задание 1.
Выборочные характеристики.
Постановка задачи.
Вычислить основные статистические характеристики выборочных данных:
1. Среднее арифметическое.
2. Дисперсию.
3. Стандартное отклонение.
4. Коэффициент асимметрии.
5. Коэффициент эксцесса.
Вычисления.
В пакете Excel имеется возможность вычисления всех четырех выборочных моментов. Для этого можно использовать встроенные функции СРЗНАЧ, ДИСПР, СКОС и ЭКСЦЕСС, вызываемые либо посредством мастера функций (кнопка  – категория «Статистические»), либо введенные непосредственно в ячейку листа Excel. Формат вызова всех функций одинаков:
– категория «Статистические»), либо введенные непосредственно в ячейку листа Excel. Формат вызова всех функций одинаков:
=ФУНКЦИЯ(x1; x2 ;…) или =ФУНКЦИЯ(Массив данных).
Второй способ вызова, конечно, удобнее. Здесь Массив данных – это область листа Excel вида A1:B43, содержащая обрабатываемые данные.
Функция ДИСПР дает смещенную оценку дисперсии, для подсчета несмещенной оценки предназначена функция ДИСП. Стандартное отклонение вычисляется посредством функций СТАНДОТКЛОНП и СТАНДОТКЛОН, квадраты которых суть функции ДИСПР и ДИСП, соответственно.
Функции СКОС и ЭКСЦЕСС вычисляют почти несмещенные оценки соответствующих характеристик. Для наших целей эти функции не совсем подходят. Мы будем вычислять эти коэффициенты исходя из определений.
Пример.
Лист “Моменты” с выборочными характеристиками может выглядеть следующим образом.
| A | B | C | D | E | F | G | H | |
| 1 | Выборочные моменты | 1,1950 | 0,2687 | |||||
| 2 | ||||||||
| 3 | Объем выборки n | 101 | -4,9302 | 8,3911 | ||||
| 4 | Среднее 
| 121,00 | 0,7242 | 0,6503 | ||||
| 5 | Дисперсия S 2 | 1,773 | 1,7195 | 2,0599 | ||||
| 6 | Ст.Отклонение S | 1,33 | 0,1235 | 0,0615 | ||||
| 7 | Асимметрия g1 | 0,506 | Значимо | 6,8376 | 12,9778 | |||
| 8 | Эксцесс g2 | 0,051 | Не значимо | -1,7366 | 2,0873 | |||
| 9 | … | |||||||
Если выборочные данные хранятся на листе “Данные” в области “B3:B103”, то для заполнения листа можно использовать следующий
a Порядок вычислений.
1) В ячейке B3 найти количество данных
Ø =СЧЁТ(Данные!B3:B103)
2) в ячейке B4 вычислить среднее арифметическое
Ø =СРЗНАЧ(Данные!B3:B103)
3) в ячейке B5 вычислить дисперсию
Ø =ДИСПР(Данные!B3:B103)
4) в ячейке B6 вычислить стандартное отклонение
Ø =СТАНДОТКЛОНП(Данные!B3:B103)
Для отыскания асимметрии и эксцесса провести вспомогательные вычисления в столбцах G и H:
5) в ячейках G3 и H3 ввести формулы вычисления 3-ей (  ) и 4-ой (
) и 4-ой ( 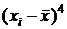 ) степеней отклонения выборочных данных от среднего
) степеней отклонения выборочных данных от среднего
Ø =(Данные!B3-$B$3)^3
Ø =(Данные!B3-$B$3)^4
(обратите внимание на знаки $);
6) скопировать ячейки G3 и H3 до 103-й строки (параллельно выборочным данным);
7) в ячейках G1 и H1 вычислить средние арифметические столбцов G и H
Ø =СРЗНАЧ(G3:G104)
Ø =СРЗНАЧ(H3:H104)
8) в ячейке B7 вычислить асимметрию
Ø =G1/B6^3
9) в ячейке B8 вычислить эксцесс
Ø =H1/B6^4-3
10) в ячейки C7 и C8 занести результаты сравнений асимметрии и эксцесса с критическими значениями (см. пособие [4], стр. 26). В нашем случае асимметрия не попадает (– значимо отличается от нуля), а эксцесс попадает в допустимый интервал (– не значимо отличается от нуля). Таким образом, имеются некоторые основания сомневаться в нормальности распределения данных.
Замечание. Вычисленные посредством функций СКОС и ЭКСЦЕСС, выборочные асимметрия и эксцесс равны 0,5147 и 0,0144.
Контрольные вопросы.
1. Сформулируйте статистическую задачу.
2. Является ли выборочное среднее (дисперсия, стандартное отклонение, коэффициент асимметрии, эксцесс) несмещенной оценкой?
Ответ: см. [4] стр. 11.
3. Является ли выборочное среднее (дисперсия, стандартное отклонение, коэффициент асимметрии, эксцесс) состоятельной оценкой?
Ответ: см. [4] стр. 12.
4. Что такое состоятельность и несмещенность?
Ответ: см. [4] стр. 10, 12.
5. Как можно исправить смещение выборочной дисперсии? Будет ли после такого исправления несмещенным стандартное отклонение? Будет ли состоятельной несмещенная оценка дисперсии?
Ответ: см. [4] стр. 11.
6. Какую информацию несет коэффициент эксцесса (среднее значение, дисперсия, асимметрия, коэффициент корреляции)?
Ответ: см. [4] стр. 25-27.
7. По какой формуле вычисляется дисперсия (среднее, асимметрия, эксцесс)?
Ответ: см. [4] стр. 25-26.
8. Что означают слова “значимо” и “не значимо” в представленном отчете?
Ответ: см. [4] стр. 26-27.
9. На каком принципе основан выбор границ, по которым проверялась гипотеза нормальности?
Ответ: см. [4] стр. 27.
Задание 2.
Гистограмма выборки.
Постановка задачи.
Построить график гистограммы выборки с подогнанной ожидаемой функцией плотности.
Теоретические основы.
См. стр. 28-30 пособия [4].
Вычисления.
Пакет Excel располагает функцией ЧАСТОТА, предназначенной для подсчета количеств попаданий в заданные интервалы разбиения числовой прямой. Это не совсем обычная функция. Она относится к классу так называемых функций массива. Для её вызова необходимо
1) в столбце, например, A2:A10 указать интервалы группировки;
2) напротив первой границы, например, в ячейку B2 ввести формулу вычисления частоты
Ø =ЧАСТОТА(Данные; Область границ)
область границ должна содержать ссылку на ячейки с границами + дополнительная ячейка для крайнего правого интервала, например, A2:A11;
3) выделить вертикальный диапазон ячеек, начиная с ячейки, содержащей формулу вычисления частоты, и заканчивая дополнительной ячейкой, соответствующей правой крайней границе (например, B2:B11);
4) ввести формулу как формулу массива
Ø последовательно нажать сочетания клавиш
 –
– 
в результате формула {заключенная в фигурные скобки} будет введена во все ячейки диапазона.
Правильность применения функции можно проконтролировать, сравнив сумму значений выделенного диапазона (указывается в нижней строке состояния окна Excel) с объемом выборки.
Пример.
| A | B | C | D | E | |
| 1 | Границы | Частоты | Плотность | ||
| 2 | 117,05 | 0 | 0,11 | ||
| 3 | 118,05 | 1 | 1,05 | Среднее | 121,00 |
| 4 | 119,05 | 3 | 5,55 | Дисперсия | 1,773 |
| 5 | 120,05 | 20 | 16,70 | Объем | 101 |
| 6 | 121,05 | 34 | 28,57 | ||
| 7 | 122,05 | 23 | 27,80 | ||
| 8 | 123,05 | 13 | 15,39 | ||
| 9 | 124,05 | 3 | 4,85 | ||
| 10 | 125,05 | 4 | 0,87 | ||
| 11 | >125,05 | 0 | 0,09 | ||
| 12 | Всего | 101 | 100,99 | ||
| 13 | |||||
| 14 |
| ||||
| 15 | |||||
| 16 | |||||
| 17 | |||||
| 18 | |||||
| 19 | |||||
| 20 | |||||
| 21 | |||||
| 22 | |||||
| 23 | |||||
| 24 | |||||

a Порядок вычислений.
1) Заполнить ячейки A2, A3 значениями первых двух границ;
2) выделить ячейки A2, A3 и, захватив мышкой точку в правом нижнем углу выделения, протащить мышку до ячейки A10 (число введенных границ будет на 1 меньше необходимого числа групп);
3) в столбце E (ячейки E3, E4, E5) ввести значения среднего, дисперсии и объема выборки, вычисленные в задании 1;
4) в ячейку B2 (напротив 1-ой границы) ввести формулу
Ø =ЧАСТОТА (Данные!B3:B103;А2:А11)
5) скопировать введенную формулу как формулу массива:
Ø выделить диапазон ячеек со 2-ей по 11-ую в столбце B (на одну ячейку больше, чем в столбце A);
Ø последовательно нажать сочетания клавиш
–
– в результате формула {заключенная в фигурные скобки} будет введена во все ячейки выделенного диапазона;
6) для контроля просуммировать все значения во втором столбце
– результат должен равняться объему выборки (в нашем примере см. ячейку B12);
7) в столбце A в ячейке под последней границей (A11) ввести выражение
Ø >125,05
здесь, конечно, нужно указывать свою последнюю границу или символ  ;
;
8) в ячейку C2 ввести формулу вычисления плотности нормального закона (в средней точке интервала)
Ø =E$5*exp(–(A2–1/2–E$3)^2/(2*E$4))/КОРЕНЬ(2*ПИ()* E$4)*1
– число “1” это длина интервала (в случае необходимости заменить другим числом);
не забывайте про знак $, обеспечивающий неизменность ссылки при параллельном копировании;
9) скопировать эту ячейку вниз в столбце C до ячейки C11, соответствующей последнему интервалу (>116,05);
10) исправить формулу для плотности в последнем интервале
Ø заменить выражение A11–1/2 на A10+1/2
– попробуйте самостоятельно объяснить такую замену;
11) просуммировать значения плотности в столбце C
– результат должен быть приблизительно равен объему выборки (ячейка C12).
Теперь уже все готово для построения графика:
12) выделить ячейки A2:C11;
13) вызвать “Мастера Диаграмм”;
14) выбрать тип диаграммы «График|гистограмма» из категории “Нестандартные”;
15)  ;
;
16) привести вида графика к стандартному виду:
Ø щелкнуть правой кнопкой мыши по одному из столбиков и, выбрав раздел меню «Формат рядов данных»
– в закладке \\Параметры//, уменьшить зазор до 5;
– в закладке \\Подписи данных//, включить в подписи “значения”;
Ø щелкнуть правой кнопкой мыши по графику плотности и, выбрав раздел меню «Формат рядов данных»
– в закладке \\Вид//, добавить возможность “Сглаживания линии” и убрать “Маркеры” на линиях;
Ø изменить, если очень захочется, остальные параметры диаграммы (например, убрать “Легенду”).
Замечание 1. При сравнении с показательным распределением в пункте 8 данной схемы следует изменить вычисление функции плотности
Ø =exp(–(A2–1/2)/*E$3))/E$3 .
Замечание 2. При сравнении с равномерным на отрезке [0; 1] распределением в пункте 8 данной схемы следует изменить вычисление функции плотности
Ø =1 .
Контрольные вопросы.
1. Сформулируйте статистическую задачу.
2. Как строится гистограмма?
Ответ: см. [4] стр. 28.
3. Каким образом следует выбирать интервалы группировки при построении гистограммы?
Ответ: см. [4] стр. 29.
4. Сколько интервалов нужно выбирать?
Ответ: см. [4] стр. 29.
5. Как связаны значения гистограммы и функции плотности?
Ответ: см. [4] стр. 28.
6. Оцените вероятность попадания в интервал  .
.
7. Почему следует сравнивать гистограмму с нормальной плотностью?
Ответ: см. [4] стр. 30.
8. Выпишите формулу плотности нормального закона (равномерного, экспоненциального)?
Ответ: см. [4] стр. 16-21.
9. Чему полагаются равными параметры нормального закона (равномерного, экспоненциального)?
Ответ: см. [4] стр. 30.
Задание 3.
Эмпирическая функция распределения.
Постановка задачи.
Построить график эмпирической функции распределения с подогнанной ожидаемой функцией распределения.
Теоретические основы.
См. стр. 31-32 пособия [4].
Вычисления.
Если попытаться построить ЭФР средствами Excel, упорядочив сначала данные и сопоставив затем каждому упорядоченному значению x(k) значение 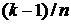 , то вместо горизонтальных получим наклонные ступеньки. Чтобы избежать этого недостатка, можно каждое значение вариационного ряда повторить дважды, при этом первому из этих значений сопоставить ЭФР
, то вместо горизонтальных получим наклонные ступеньки. Чтобы избежать этого недостатка, можно каждое значение вариационного ряда повторить дважды, при этом первому из этих значений сопоставить ЭФР 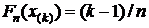 , а второму
, а второму  .
.
Вычисление нормальной функции распределения описано ниже в главе “Встроенные функции Excel”. Здесь кратко только скажем, что для этого можно использовать функции НОРМРАСП и НОРМСТРАСП из категории “Статистические”.
Функция распределения экспоненциального закона вычисляется с помощью простой функции EXP.
Кроме того, предполагается, что уже вычислены среднее значение и дисперсия выборки (задание 1).
Пример.

Рис. 2
a Порядок вычислений.
1) Скопировать исходные данные в буфер обмена;
2) перейти на лист “ЭФР” и, установив курсор в ячейку A3, вставить данные из буфера обмена;
3) повторить процесс восстановления данных, начиная с ячейки A104
Ø установить курсор в ячейку A104;
Ø вставить данные из буфера обмена
– всего получится 202 значения с 3-й по 204-ю ячейки;
4) упорядочить значения в столбце A
Ø кликнуть мышкой по кнопке  ;
;
5) ввести в ячейку B3 формулу
Ø =(СТРОКА(B3)-1)/202-1/101
– функция «СТРОКА» возвращает номер строки указанного аргумента, то есть в данном случае в ячейке B3 получится значение (3-1)/202-1/101 = 0;
6) ввести в ячейку B4 формулу
Ø =(СТРОКА(B3)-1)/202
– получится значение (3-1)/202 = 1/101;
7) выделить обе ячейки B3 и B4 и скопировать их параллельно всем данным до ячейки B204
– в последней ячейке должно получиться значение 1;
8) добавить в ячейку A2 значение, на единицу меньшее значения ячейки A3 и сопоставить ему значение 0 в ячейке B2;
9) добавить в ячейку A205 значение, на единицу большее значения ячейки A204 и сопоставить ему значение 1 в ячейке B205.
Ввести формулы вычисления нормального распределения:
10) в ячейки F4, F5 (те, которые скрыты графиком) скопировать среднее и стандартное отклонение, соответственно
Ø =МОМЕНТЫ!B4
Ø =МОМЕНТЫ!B6
11) в ячейку C2 ввести формулу нормального распределения
Ø =НОРМРАСП(A2;$F$4;$F$5;1)
12) в ячейку D2 ввести формулу вычисления расхождения между ЭФР и ожидаемой функцией распределения
Ø =ABS(C2-B2)
13) скопировать обе ячейки C2 и D2 вплоть до 205-й строки;
14) вычислить максимальное расхождение, например, в ячейке F6
Ø =МАКС(D2:D205)
Теперь уже можно рисовать графики:
15) выделить все значения в ячейках A2:C205;
16) вызвать “Мастера Диаграмм”;
17) выбрать «Точечную» диаграмму – без маркеров со сглаживающей линией (третья по порядку среди точечных диаграмм);
18) при выборе представления диаграммы, после двух нажатий кнопки  , удалить “Легенду” и добавить “Заголовок по оси Х”:
, удалить “Легенду” и добавить “Заголовок по оси Х”:
Ø МАКСИМАЛЬНОЕ РАСХОЖДЕНИЕ D=…
(указав здесь полученное значение Δ из ячейки F6);
19) ;
20) установить параметры диаграммы, как в примере.
Замечание. Если бы параметры нормальной модели не оценивались по выборочным данным, а были бы в точности равны этим оценкам, то при полученном здесь расхождении Δ=0,097 гипотезу нормальности следовало бы принять с критическим уровнем значимости > 0,20 (см. таблицу 6.2 сборника таблиц [1]). Это надо воспринимать как хороший знак и не более того. Если неизвестные значения параметров оцениваются по выборке, то критический уровень значимости становится зависящим от неизвестных параметров и трудно ожидать, что даже в предположениях гипотезы критерий будет иметь приемлемый размер.
Контрольные вопросы.
1. Сформулируйте статистическую задачу.
2. Что такое вариационный ряд?
Ответ: см. [4] стр. 31.
3. Дайте определение эмпирической функции распределения?
Ответ: см. [4] стр. 31.
4. Почему некоторые ступеньки ЭФР высокие, а некоторые низкие?
Ответ: см. [4] стр. 31.
5. Почему одни ступеньки ЭФР длинные, а другие короткие?
Ответ: см. [4] стр. 31.
6. Постройте ЭФР по следующим данным: 1; 2; 1; 3; 1; 5; 1; 3.
7. Выпишите формулу для функции распределения нормального закона (равномерного, экспоненциального).
Ответ: см. [4] стр. 16-21.
8. Можно ли утверждать, что ЭФР является состоятельной оценкой истинной функции распределения? Что сие означает?
Ответ: см. [4] стр. 31.
9. Можно ли утверждать, что ЭФР является несмещенной оценкой истинной функции распределения? Что сие означает?
Ответ: см. [4] стр. 31.
10. Докажите несмещенность ЭФР.
11. Можно ли по значению максимального расхождения между ЭФР и ожидаемой функцией распределения принять или отвергнуть гипотезу о виде истинной функции распределения?
Ответ: см. [4] стр. 32.
Задание 4.
Дата добавления: 2018-04-05; просмотров: 1370; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!