Основные методы автоматизированного дешифрирования снимков.
Методы автомат.деш.сн-в позволяют выполнить классификацию объектов на изобр-и, т.е. отнести изображенные на снимке объекты к тому или иному виду класса на основе критериев, кот.наз-ся решающими правилами.
Классификация – это процесс разбиения пикселей, составляющих непрерывное растровое изображение, на несколько категорий на основании их файловых спектральных значений.
Алгоритмы классификации:
1) управляемая класс-я - с обучением (обучение по тестовым объектам + решающее правило Байеса):
- параметрическая;
- непараметрическая
Баесовский классификатор:
Задача класс-и – выделить на изображении заданные классы, основываясь на вероятностные характеристики объектов и вероятностные хар-ки признаков этих объектов.
 -это априорная вероятность появления события ωi на изображении;
-это априорная вероятность появления события ωi на изображении;  -условная вероятность появления события
-условная вероятность появления события  , если имеет место признак ωi;
, если имеет место признак ωi;
 -апостериорнаяусловная вероятность появления события ωi, при условии, что имеет место .
-апостериорнаяусловная вероятность появления события ωi, при условии, что имеет место .
Функция рапределения условной плотности вероятности получается в результате обучения, т.е статической оценки парамеров  по обучающей выборке.
по обучающей выборке.
|

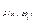
 |
гистограмма  -вода по обучающей выборке(гистограмма распределения яркости в заданном канале).
-вода по обучающей выборке(гистограмма распределения яркости в заданном канале).
Баесовское правило(решающее):
 для каждого объекта вычисляем условную вероятность, затем принимаем решение: если
для каждого объекта вычисляем условную вероятность, затем принимаем решение: если  >
>  , то имеет место событие
, то имеет место событие  . Баесовское правило учитывает априорную вероятность появления объекта на изображении, и вероятность появления объекта при определенном значении признака дешифрирования:
. Баесовское правило учитывает априорную вероятность появления объекта на изображении, и вероятность появления объекта при определенном значении признака дешифрирования:
 ,
,
 -многомерный вектор измерений признаков (
-многомерный вектор измерений признаков ( ,
,  )
)
Метод классификации с обучением основан на использовании готовых эталонов, спектральные характеристики которых обычно соответствуют спектральным характеристикам реальных объектов. Эталоны создаются пользователем путем распознавания характерных объектов непосредственно на изображении. Таким образом, процесс классификации с обучением можно разделить на два основных этапа: создание набора эталонов (обучение) и непосредственно классификация. Создание набора эталонов заключается в идентификации объектов, характерных для данного изображения, и сохранении их спектральных характеристик, которые позволяют в дальнейшем осуществлять автоматическую классификацию. Среди всех классификаций с обучением наиболее широко используются следующие методы: эллипсов (Ellipse), параллелепипедов (Parallelepiped), минимальной спектрального растояния (Minimum Distance), растояния бинарного кодирования (Binary Encoding), спектрального угла (Spectral Angle Mapper). Махаланобиса (Mahalanobis Distance), максимального правдоподобия (Maximum Likelihood), метод главных компонент (сущность метода: спектральные яркости объектов в разных спектральных зонах для большинства объектовсильно коррелированны м/у собой, поэтому нужно выполнить преобразование исх. Яркостей чтобы получить новый вектор яркостей в кот. Яркости не коррелированны м/у собой.выполняется разложение корена-лоэва(вычисляется ковариационная матрица для спектр. Векторов для каждого Эл-та -  ). Находятся собственные векторы и собст-е значеня, каждый Эл-т новой матрицы есть произведение совств-о вектора на соотв-е собственное значение. После преобразованя находится сист. Координат в которой измерения независимы. в результате применения метода снижается размерность вектора измерений; первые компоненты несут глав-ю нагрузку, а последние содержат в основном шумы).
). Находятся собственные векторы и собст-е значеня, каждый Эл-т новой матрицы есть произведение совств-о вектора на соотв-е собственное значение. После преобразованя находится сист. Координат в которой измерения независимы. в результате применения метода снижается размерность вектора измерений; первые компоненты несут глав-ю нагрузку, а последние содержат в основном шумы).
2) неуправляемая класс-я (без обучения):
Классификация без обучения представляет собой автоматический метод нахождения категорий данных. Она позволяет пользователю задать основные руководящие принципы для определения модели классификации, но само определение классов и отнесение пикселей изображения к тому или другому классу происходит полностью автоматически. Наиболее широкое применение получили две неконтролируемые классификации: K-Means и Isodata.
К неуправляемой класс-и (без обучения) относится:
- сегментация (выделение границ, контуров+визуальное деш-ие);
- кластерный анализ (выбор кол-ва классов, критерий близости м/у классами, критерий принадлежности точки классу).
Кластерный анализ.
Выделяем центр кластера. Кластеризация – разделение изобр-я на области, обладающие определенными св-ми в соот-ии с заданными критериями. Если изменяется критерий и св-ва, то на одном и том же изобр-и можно выделить несколько уч-в.
1. Выделяем кол-во классов, кот. хотим выделит на изобр-и.
2. Выбор критерия, по кот. данный эл-т принадлежит даннму классу. Критерием является расстояние в пространстве признаков.
Ч/б изобр-е хар-ся яркостью:
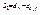 ; i= 1 …n,j= 1 …m;
; i= 1 …n,j= 1 …m;  .
.

Евклидово расстояние:
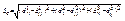 .
.
Следующие шаги в алгоритме м.б. реализованы по разному:
Пример в Isodata:
3) Вычисление нового значения центра кластера, кот. имеет среднее значение признаков по всем точка заданного кластера.
4) Повторение шагов 3,4 до тех пор, пока значение признаков центра кластера, полученного из j и j +1 итерации не будет отличаться больше, чем на заданное значение (кот. задаем сами).
Второй вариант: оператор сам оценивает выделенные классы и сам объединяет его в новый кластер, выч-ся центр кластера и повтор-ся шаги 1,2–интерактивный анализ.
Дата добавления: 2015-12-18; просмотров: 67; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!