Глава 7. Маркетинговые исследования
Выбор понятий и терминов
В рассмотренных выше стохастических моделях применялись понятия и термины из нормативных и статистических источников, причем их состав минимизировался. Ограничения понятийного аппарата пределами необходимости способствует доходчивости и сокращает ошибки в расчётах.
Однако планирование маркетинговых исследований предполагает согласование работ, выполненных разными исполнителями, оперирующих собственной терминологией, а так же составление отчетов, понятных и убедительных для заказчиков или партнеров. С заказчиком должно говорить на языке ''заказанном'' – это заповедь маркетинга. С партнерами можно согласовывать терминологию, выясняя смысл, вкладываемый каждой стороной в основные понятия.
Первичным является понятие статистического ансамбля - множество однородных элементов. Выше это понятие ассоциировалось с партией, объем которой велик, оставаясь конечным, скажем, более 105. В маркетинговых источниках часто путаются понятия математической статистики и теории вероятностей. Критерий для различия – объем. В теории вероятностей оперируют генеральной совокупностью, устремляя объем к бесконечности. У партии объем конечный и статистический ансамбль не обязательно устремлять к бесконечности. Различие весьма существенно, оно определяет корректность моделей. С другой стороны, термин ''партия'' неоднозначен. Применительно к людям, политики и юристы вкладывают в него особый смысл.
|
|
|
Говоря о людях рационально пользоваться термином совокупность.
Граждане могут быть обижены, если их сосчитают как ''реализации'' или даже ''элементы''. По опыту кадровиков, лучше считать граждан единицами.
Итак, совокупность состоит из единиц вмаркетинговом исследовании.
Понятие статического ансамбля подменяется во многих публикациях контуром выборки – ограничивающим всеединицы совокупности. Полный перечень всех единиц составить невозможно и поэтому есть ошибка контура выборки, т.е. разность между истинными и учтенными событиями или состояниями совокупности.
Маркетологи применяют методы составления выборок, отличающиеся от рассмотренных выше. Эти методы состоят из ''вероятностных'' (случайных) и ''невероятностных'' (неслучайных). Оперировать термином ''невероятность'' имеет смысл только с заказчиком, вежливо уточняя, что он имеет в виду.
К случайным относят методы, оперирующие с единицами, каждая из которых имеет известный шанс быть избранной в выборку. Это вроде думы, где все депутаты прошли процедуру голосования по одному алгоритму.
Случайные выборки составляются по одному из методов:
|
|
|
– простой случайный отбор;
– систематический отбор;
– кластерный отбор;
– стратифицированный отбор.
Простой случайный отбор – это обеспечение равного шанса всем единицам совокупности попасть в выборку, т.е. в соответствии с рекомендациями нормативно-справочной литературы.
Систематический отбор выполняется в два этапа.
Сначала проводят – простой случайный отбор начальных номеров для поиска единиц, например, в справочнике – страница или колонка. Затем применяют ''интервал скачка'' т.е. отбирают каждый 250-ый адрес. 250 – здесь пример любого постоянного числа. Это ''удобство'' комплектования выборки привносит некорректность и, как следствие, методическую погрешность в последующие оценки. Однако часто применяется при работе со списками, спецификациями и т.п.
Кластерный отбор основан на делении совокупности на подгруппы, каждая из которых представляет совокупность в целом. Совокупность делят на единицы, являющиеся равными по исследуемым признакам – кластеры. К примеру, страну делят на области с равным населением или доходом. На следующем этапе в одной области выделяют единицы с равным доходом и т.д.
Исследование распределений становиться многоуровневым оно может быть корректным в достаточной мере. Этот метод применяется для весьма сложных объектов, для которых обоснована относительно высокая трудоёмкость.
|
|
|
При исследовании сложных объектов, недоступных делению на равные части, выделяют подгруппы – страты. Например, области страны различаются по всем признакам, но делить их по частям вне границ на карте бессмысленно. Вводят стратифицированный отбор. Страты выделяются по избранному признаку, к примеру, числу семей. Выборки составляются внутри этих подгрупп, для каждой страты. Размер страты по отношению ко всей совокупности определяет размер выборки с учетом весовых коэффициентов, учитывающих их размер страт. Метод является наиболее сложным, вносит существенные методические погрешности, так что применять его имеет смысл для объектов, недоступных другим подходам.
''Неслучайные'' методы состоят из приемов, трансформирующих составление выборки в отбор комплекта.
Принято применять методы:
– на основе принципа удобства;
– отбор на основе суждений;
– отбор на основе квот или в процессе обследования.
Принцип удобства реализуется исследователем, исходя из минимизации затрат времени и усилий или доступности респондентов. К примеру, одобрение продукции завода (фирмы) можно получить, опрашивая сотрудников в день зарплаты.
|
|
|
Выборка на основе суждений базируется на мнении специалистов относительно состава выборки. Однако специалисты далеко не всегда объективны. Есть ''науки'' телепатия, к примеру, созданные исключительно из некорректно составленных выборок. Есть ''лекари'', неизлечимых болезней демонстрирующие исцелившиеся единицы… Нет метода, внесшего подобное обилие недобросовестных наукообразных спекуляций, как волюнтаристские приемы составления выборок.
При опросах часто выбирается ''фокус'' группа. К примеру, могут быть выбраны 12 домохозяек, которые сообщают о себе заданную информацию. Однако поведение единицы становится неестественным, дополняется ''эффектом сцены'' и как следствие, чрезмерной погрешности.
Формирование выборок на основе квот базируется на заданном соотношении объемов с совокупностью. Выборка пополняется, пока не будет накоплена установленная квота.
Часто совмещают несколько методов в одном исследовании. Если, например, требуется выборка для оценки Всероссийского мнения о марках магнитофонов, то требуется алгоритм:
1. Россия состоит из 89 субъектов.
2. По методу простого отбора выбираются 9 субъектов (кроме Москвы и Санкт-Петербурга).
3. Все населенные пункты делятся на 6 групп, по числу жителей.
4. Устанавливается квота: по 3 города и 2 поселка. Берут каждый 5-й населенный пункт из справочника и выясняют, в какую категорию он попал.
5. Выбирают случайно по 20 респондентов в каждом городе или селе. Всего 900 респондентов.
Несоблюдение статистических норм проявится в том, что окажутся вместе поселки с нефтяниками и безработными, данные будут искажены и, несмотря на солидный объем выборки, не будет основания считать её представительной.
Выше говорилось о представительности выборки, как об уровне близости её статистических мер к мерам статистического ансамбля.
В маркетинговых исследованиях упоминают репрезентативность. Смысл этого термина может быть связан с математической моделью, т.е. дифференцируемыми функциями и N ® ¥ .
Выбор алгоритма комплектования выборки для сложных объектов исследования, является задачей со многими неизвестными. Факторы, определяющие представительность планируемой выборки, неизвестны априорно, так что необходимы исходные данные, обычно специальный эксперимент, чтобы их ранжировать. Люди являются наиболее сложными объектами исследования. Выбор единиц совокупности должен быть особенно корректным, так что всяческие упрощения будут совсем некстати.
Единственным критерием оценки правил составления выборки является сходимость выборок, определяемая апостериорно по итогам статистического анализа нескольких эмпирических распределений. Термин “сходимость” маркетологами практически не используется. Речь идет о свойстве выборок сохранять свои статистические меры по мере уменьшения объема. Очевидно, алгоритм формирования выборки тем корректнее, чем меньше меняются статистические меры при сокращении объема.
При необходимости корректировки состава выборки применяют один из 3 способов:
– выборка с большим объемом;
– замена респондента на следующего по списку;
– повторная выборка.
К примеру, контуром выборки является телефонный справочник. Не ответил абонент, надо звонить следующему по списку. Рассылка почтой планируется, исходя из “нормы” – 5% присылающих ответы, поэтому надо посылать в 20 раз больше анкет, чем требуется для обработки данных. Повторную выборку комплектуют, когда слишком много отказов отвечать.
Методика исследований корректируется по мере проявления факторов, определяющих достоверность оценок. Однако эта коррекция осуществляется без обратной связи. Рассмотренная задача напоминает выбор колера для окрашивания стен. У хороших красок (статистических ансамблей) цвет не зависит от объема, так что можно смешать в баночке пигменты и связующее (выборку) будучи в уверенности, что полученный при пробном окрашивании цвет точно повторится на стенах (представительность). В реальности нередки “сюрпризы”, неучтенные факторы могут быть доминирующими и цвета “уплывают”.
Обоснование объема выборки
Объем выборки вносит основной вклад в затраты времени и средств на маркетинговые исследования и поэтому является темой сложных дискуссий между заказчиками и исполнителями.
Стремление минимизировать объемы выборок сопровождается требованиями всемерно повышать их представительность. Особое внимание уделяется условиям сбора и обработки данных.
Однако встречаются ситуации, в которых объемы выборок явно избыточны. Причинами тому являются традиции или реклама.
Избыточность объема не всегда повышает представительность, многие погрешности проявляются при любом объеме.
Маркетологи применяют несколько методик выбора объема выборки:
1. Правило ''большого пальца''. Принимается, к примеру, объем, составляющий 5% от совокупности, просто потому, что “5” ассоциируется с “отлично”.
2. Ссылки на публикации. Учитывается опыт аналогичных исследований, проведенных раньше. Регулярные исследования оптимизируют объем, например на уровне 3000 человек.
3. Расчет, исходя из выделенных на исследования ресурсов.
Расчетное обоснование объема базируется на достоверности оценок и рисков принятых решений в качестве исходных данных.
Предполагается взаимопонимание между заказчиками и исполнителями.
Вариация – понятие, применяемое маркетологами для оценок ''схожести'' и ''несхожести'' ответов в анкетах. В качестве меры для разноголосицы респондентов принято среднее квадратическое отклонение (СКО). Часто используются архаичные термины, типа ''кривых распределения'', подразумевающие функции распределения плотностей вероятности, которые аксиоматически непрерывны. Сужение понятия в конкретной задаче нуждается в предварительном согласовании.
Доверительный интервал – воспринимается всеми, как область, содержащая известную долю реализаций (единиц) внутри заданных границ. Маркетологи применяют всего два типа границ – на уровнях доверительных вероятностей 0,95 и 0,99. Им соответствует расчетное число Z – 1,96 и 2,56. Это число обозначает уровень названной вероятности на вертикальной шкале с нормальным масштабом – 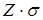 ;
; 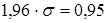 и
и 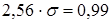 .
.
Для понимания полученных результатов предлагается вообразить 100 выборок, данные которых разместились в заданных интервалах и только 5 или 1 из них стали '' нарушителями''. В исследованиях есть всего одна выборка. “Экономия” на выборках вносит ошибку. Рассчитывается среднее квадратическое отклонение этой ошибки, зависящее в основном, от объема выборки.
Ошибка может быть симметрична относительно искомого значения, и тогда говорят о точности оценки ± e.
По заданной точности рассчитывает объем выборки n. В частности, для ответов в альтернативной форме:
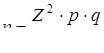 ,
,
где: n – объем выборки;
Z – нормированное отклонение: 1,95 или 2,56;
p – доля положительных ответов;
q – доля отрицательных ответов.
Размерности e, p , q одинаковые, например в %.
Вариация наибольшая, когда согласие и несогласие респондентов пополам и наименьшая при единогласном голосовании (берут 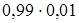 ).
).
Если, например, точность ±10%, а ''да'' и ''нет'' поровну и 0,95 = g:
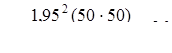
если g = 0,99 (Z = 2,56) точность ±3%, то n = 1067
Для ответов в количественной форме определяются статистические меры. Если, например, требуется среднее квадратическое отклонение sс точностью до ±10% на уровне g=0,95(Z=1,96), то 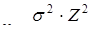 ; если, например, s = 100, то n = 384.
; если, например, s = 100, то n = 384.
Аналогичные формулы есть для всех точечных оценок – 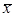 и x т.п. Формулы справедливы в той мере, в которой соблюдается условия центральной предельной теоремы. А именно, совокупность должна быть суммой нескольких случайных величин, каждая из которых может не соответствовать нормальному распределению, но не должна быть доминирующей. Это условие соблюдается далеко не всегда на практике, и точность оценок может быть гораздо хуже рассчитанной.
и x т.п. Формулы справедливы в той мере, в которой соблюдается условия центральной предельной теоремы. А именно, совокупность должна быть суммой нескольких случайных величин, каждая из которых может не соответствовать нормальному распределению, но не должна быть доминирующей. Это условие соблюдается далеко не всегда на практике, и точность оценок может быть гораздо хуже рассчитанной.
''Сюрпризы'' изучаемых совокупностей могут быть учтены исключительно по функциональным оценкам, по доверительным интервалам для эмпирических распределений. Однако для “пилотных” оценок, при планировании исследований, приемлемы ориентировочные формулы – для представительных выборок из совокупностей с нормальным распределением.
Дата добавления: 2019-01-14; просмотров: 233; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!