Представление результатов кластеризации
Кластерная модель представляет описание кластеров и принадлежность к одному из них каждого объекта из исходного множества. В случае небольшого числа объектов, характеризующихся двумя переменными, результаты можно изобразить посредством элементарных фигур (треугольников, четырехугольников), соответствующих объектам, и множества прямых линий [3]. На рисунке 8.1 представлена диаграмма, характеризующая разделение объектов с двумя атрибутами (параметрами).
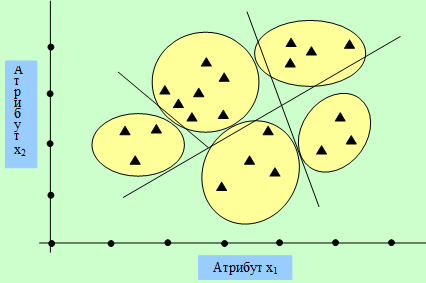
Рисунок 8.1 – Разделение на кластеры
Если кластеры нельзя разделить прямыми линиями, то границы кластеров изображаются с применением ломаных линий. Принадлежность объекта к нескольким кластерам можно изобразить с применением Венских диаграмм.
В случае нечёткой кластеризации принадлежность объекта к кластеру оценивают вероятностью принадлежности или степенью принадлежности. В этом случае результат можно представить в виде таблицы, в которой строки соответствуют объектам, столбцы – кластерам. В ячейках таблицы указывается вероятность или степень.
Некоторые алгоритмы кластеризации строят структуры кластеров. Самый верхний уровень в структуре соответствует всему множеству объектов в виде единственного кластера. На следующем уровне множество делится на несколько кластеров, каждый из которых также делится на несколько кластеров. В принципе, построение иерархии может продолжаться до представления каждого объекта отдельным кластером. Визуализация таких структур выполняется в виде дендограмм (dendrograms). Существует различные способы построения дендограмм [1].
|
|
|
Краткие итоги
§ Задача кластеризации предполагает разделение множества объектов на кластеры (cluster) или классы, таксоны, сгущения, группы. В кластерном анализе различие объектов по атрибутам (переменным) не учитывается.
§ В задачах кластеризации мера близости объектов определяется из представления объектов в виде точек  - мерного пространства. Наибольшее применение находят меры: евклидово расстояние, расстояние по Хеммингу, расстояние Чебышева и расстояние Махаланобиса.
- мерного пространства. Наибольшее применение находят меры: евклидово расстояние, расстояние по Хеммингу, расстояние Чебышева и расстояние Махаланобиса.
§ В иерархических агломеративных алгоритмах кластеризации исходное множество объектов  представляется как множество кластеров
представляется как множество кластеров  . Кластеры с наименьшим удалением сливаются в общий кластер. Процедуру повторяют до выполнения условия остановки алгоритма.
. Кластеры с наименьшим удалением сливаются в общий кластер. Процедуру повторяют до выполнения условия остановки алгоритма.
§ В иерархических дивизимных алгоритмах кластеризации исходное множество объектов представляется как единственный кластер. Разделение кластера выполняют по критерию наибольшей удалённости объектов. Алгоритмы различаются способом выбора кластера для разделения.
|
|
|
§ В неиерархических алгоритмах на первом шаге кластеризации задаются произвольные центры кластеров и точность кластеризации. Последующие шаги связаны с разделением объектов по критерию близости к центрам кластеров и вычислению новых центров кластеров.
Контрольные вопросы
1. В задаче кластеризации отнесение объекта, характеризуемого множеством параметров, осуществляется:
а) к одному заранее определённому аналитиком классу;
б) к одному заранее определённому аналитиком контейнеру;
в) к одному заранее неопределённому классу;
г) к одному заранее определённому экземпляру сущности.
2. Параметры, характеризующие объекты кластерного анализа, могут принимать значения из множества:
а) комплексных чисел;
б) нечётких вещественных чисел;
в) вещественных чисел;
г) лингвистических оценок.
3. Мера близости объектов в кластерном анализе характеризуется:
а) весовыми коэффициентами для пересчёта расстояний;
б) количеством объектов, входящих в кластер;
в) расстоянием между объектами из заданного набора;
г) разностью значений между параметрами объекта.
4. В иерархических дивизимных алгоритмах кластеризации на первом шаге количество кластеров определяется:
|
|
|
а) количеством объектов из анализируемого набора;
б) параметрами, характеризующими алгоритмы кластеризации;
в) требованиями из поставленной задачи кластеризации;
г) требованиями лица принимающего решения.
5. В неиерархических алгоритмах процедура разбиения объектов на кластеры завершается при выполнении условия:
а) количество объектов в кластерах не меньше заданного значения;
б) расстояния между кластерами имеют минимальное значение;
в) количество сформированных кластеров равно заданному значению;
г) центры и границы сформированных кластеров не меняются.
Литература
1. Барсегян А.А. Методы и модели анализа данных: OLAP и Data Mining / Барсегян А.А., Куприянов М.С., Степаненко В.В., Холод И.И. – СПб.: БХВ-Петербург, 2004. – 336 с.
2. Ларсон Б. Разработка бизнес-аналитики в SQL Server 2005. – СПб.: Питер, 2008. – 684 с.
3. Microsoft SQL Server 2008: Data mining – интеллектуальный анализ данных. Пер. с англ. / Дж. Макленнен, Чж. Танг, Б. Криват. – БХВ-Петербург. 2009. – 720 с.
4. Мандель И.Д. Кластерный анализ. – М.: финансы и статистика. 1988. – 176 с.
Дата добавления: 2018-10-26; просмотров: 641; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!