Раздел 3. Интеллектуальный анализ данных
Лекция 8. Кластерный анализ данных
В лекции рассматривается постановка и решение задач кластерного анализа: исследования схем группирования объектов; представление гипотез на основе собранных данных; проверка гипотез о наличии кластеров в данных, выделенных пользователем.
Цель лекции – изучение формальной постановки задачи кластеризации, мер близости объектов, иерархических и неиерархических алгоритмов.
Кластерный анализ данных не требует выделения зависимой переменной и предполагает разделение множества объектов не кластеры (cluster) или классы, таксоны, сгущения, группы. Для задач кластеризации характерно отсутствие различий объектов по атрибутам (переменным). Термин кластерный анализ, впервые введён Трионом (Tryon) в 1939 году. При проведении кластерного анализа не строят априорных предположений о заданном наборе данных, не вводят ограничений на представление объектов анализа и типы данных. Кластерный анализ также можно использовать для сокращения размерности и визуализации данных. В настоящее время кластерный анализ развивается в направлениях, связанных с коммерческой деятельностью, техническими науками, биологией и психологией [1, 2].
Формальная постановка задачи кластеризации
Формальная постановка задачи кластеризации осуществляется следующим образом. Определяется множество объектов данных  . Каждый объект
. Каждый объект  характеризуется набором атрибутов:
характеризуется набором атрибутов:
 .
.
Примером такого множества объектов может быть коллектив преподавателей высшего учебного заведения, каждый из которых характеризуется набором показателей (атрибутов) о квалификации, учебно-методической и научной деятельности, внеаудиторной работе.
Каждая переменная из набора  принимает значения из множества действительных чисел
принимает значения из множества действительных чисел  . Решением задачи кластеризации является множество сформированных кластеров
. Решением задачи кластеризации является множество сформированных кластеров
 ,
,
где  - кластер, содержащий похожие объекты из множества
- кластер, содержащий похожие объекты из множества  ,
,  - мера близости между объектами,
- мера близости между объектами,  - величина, определяющая меру близости между объектами.
- величина, определяющая меру близости между объектами.
Мера близости должна отвечать следующим условиям [1, 2]:
а) 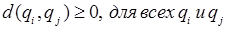 ;
;
б) 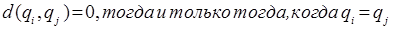 ;
;
в)  ;
;
г) 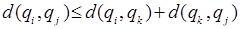 .
.
При выполнении неравенства 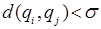 объекты из множества
объекты из множества  рассматриваются как близкие и помещаются в один кластер. Иначе объекты помещаются в разные кластеры.
рассматриваются как близкие и помещаются в один кластер. Иначе объекты помещаются в разные кластеры.
Меры близости в кластерном анализе
В задачах кластеризации выбор меры близости предполагает представление объектов в виде точек  - мерного пространства
- мерного пространства 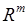 . При этом меры близости определяют расстояние между двумя точками пространства . Наибольшее применение находят следующие меры: евклидово расстояние, расстояние по Хеммингу, расстояние Чебышева, расстояние Махаланобиса.
. При этом меры близости определяют расстояние между двумя точками пространства . Наибольшее применение находят следующие меры: евклидово расстояние, расстояние по Хеммингу, расстояние Чебышева, расстояние Махаланобиса.
Евклидово расстояние между объектами вычисляется по формуле:
 .
.
Данная мера придаёт большие веса более отдалённым друг от друга объектам из заданного множества  .
. 
Расстояние по Хеммингу вычисляется следующим образом:
 .
.
Эта мера в отличие от расстояния Евклида снижает влияние больших разностей по отдельным атрибутам на результаты кластеризации.
Для оценки расстояния по Чебышеву используется формула:
 .
.
Как правило, формула Чебышева используется при необходимости разнести объекты по кластерам, имеющим существенное различие только по одному атрибуту (измерению).
Расстояние Махаланобиса вычисляется по формуле:
 ,
,
где – ковариационная матрица размерности  ,
,  - символ транспонирования [1].
- символ транспонирования [1].
К настоящему времени известно более 100 алгоритмов кластерного анализа. Все алгоритмы разделяют на иерархические и неиерархические алгоритмы.
Дата добавления: 2018-10-26; просмотров: 335; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!