Концепция многомерной модели данных
В службах SQL Server Analysis Services используется унифицированная многомерная модель данных (Unified Dimensional Model, UDM). Эта модель позволяет различным клиентским приложениям получить доступ к данным из реляционных и многомерных БД без применения различных моделей (рисунок 2.7). Роль унифицированной многомерной модели заключается в создании моста между пользователем и источниками данных [2, 3]. Модель UDM конструируется на одном или нескольких источниках данных. Пользователь запрашивает модель UDM при помощи различных клиентских средств, например Microsoft Excel.
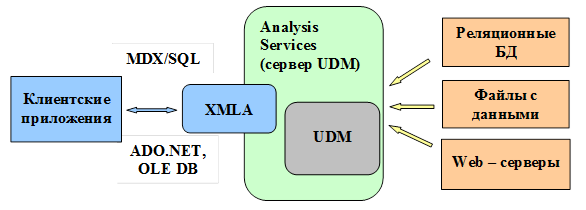
Рисунок 2.7 – Многомерная модель данных
Конечному пользователю это дает определенные преимущества, даже если модель UDM конструируется только как тонкий слой над источником данных: проще и легче можно понять модель данных; обеспечивается изоляция от гетерогенных серверных источников данных; повышается производительность при обработке запросов обобщенного типа. В некоторых сценариях простая модель UDM может конструироваться автоматически. Дополнительные вложения в создание унифицированной многомерной модели могут обеспечить дополнительные преимущества, вытекающие из богатства метаданных, которые может предоставить эта модель. Преимущества унифицированной многомерной модели данных:
§ значительно обогащает пользовательскую модель;
§ обеспечивает высокую производительность запросов, поддерживая интерактивный анализ даже на очень больших объемах данных;
|
|
|
§ использует в модели бизнес-правила для поддержки более содержательного анализа данных;
§ поддерживает «закрытие цикла»: пользователям позволяется действовать с данными, которые они видят на экране монитора.
Многомерная модель данных определяет представление данных на трех уровнях: концептуальной модели; физической модели; прикладной модели.
В терминах концептуальной модели пользователь описывает данные организации (предприятия): структуру и организацию данных; правила доступа; методы расчётов и преобразований. Модель используется в качестве моста между моделью предметной области и многомерной моделью данных. Для описания концептуальной модели используется Язык Описания Данных (Data Definition Language, DDL) и язык сценариев (Multidimensional Expressions, MDX).
Физическая модель основывается на концептуальной модели. Как и в случае реляционных БД, физическая модель определяет условия хранения данных на физических носителях:
• место хранения: тип файлов с данными, носитель информации, размещение носителя;
• способ хранения: в сжатом или несжатом виде, вид индексирования;
• правила доступа к данным, организацию кеширования данных, способ занесения и извлечения данных из памяти.
|
|
|
Для хранения всех видов информации в службах Analysis Services используется структура данных, называемая накопителем данных (Data store). Данные в накопителе сервера разделены и структурированы (рисунок 2.8). Основными элементами накопителя является поля, поддерживающие различные числовые типы данных размером от 1 до 8 байтов, а также строковые типы данных. Поля группируются в записи, содержащие набор данных для всех полей. Поле может быть помечено как пустое, т.е. содержащее значение null. В конце каждой записи для каждого потенциально пустого поля (столбца) добавляется один бит для указания пустого поля.
При передаче данных аналитическим приложениям прикладная модель также определяет их формат. Клиентское приложение непосредственно взаимодействует с прикладной моделью данных. Прикладная модель разрабатывается с применением Языка MDX. Посредством MDX выполняется описание модели формирования данных с включением MDX-сценариев (MDX Scripts) и представлений запросов к многомерной БД,
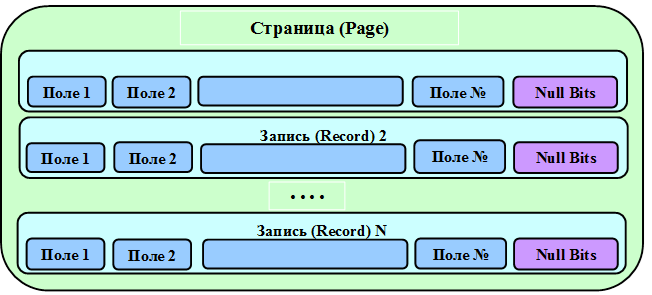
Рисунок 2.8 – структура записей и страниц
В многомерных БД для описания данных используется понятие многомерного пространства. В отличие от геометрического пространства многомерное пространство дискретно и содержит дискретное количество значений на каждом измерении. Пространство данных может иметь любое количество измерений. Для описания многомерного пространства используются следующие термины:
|
|
|
§ измерение (dimension), описывающее элемент данных для анализа;
§ элемент (member): соответствует одной точке на измерении.
§ значение элемента (member value): уникальная характеристика элемента;
§ атрибут (attribute): полная коллекция элементов одного типа;
§ размер (size) или кардинальность (cardinality) измерения: количество элементов, которое содержит измерение.
На рисунке 2.9 приведено пространство данных с тремя измерениями

Рисунок 2.9 – Трехмерное пространство данных
Количество точек в пространстве данных образует теоретическое пространство данных. Размерность теоретического пространства математически определяется перемножением размеров всех измерений. Поскольку каждое измерение дискретно, то пространство является ограниченным (конечным). При описании многомерного пространства дополнительно используются следующие понятия:
§ кортеж (tuple), определяющий координату в многомерном модельном пространстве;
§ срез (slice), определяющий секцию многомерного модельного пространства, которая определяется кортежем.
|
|
|
Таким образом, каждая точка пространства данных определяется набором координат, который называется кортежем. Например, любая точка пространства на рисунке 1.11 определяется кортежем (  ),
),  ,
,  ,
,  . Если зафиксировать элемент одного измерения, то получится срез в пространстве данных. Примером среза может служить
. Если зафиксировать элемент одного измерения, то получится срез в пространстве данных. Примером среза может служить  , ,
, ,  ,
, 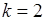 .
.
Краткие итоги
§ Архитектура описания данных включает три уровня абстракции: внешний, внутренний и концептуальный.
§ Концептуальный уровень описания данных обеспечивает представление данных в абстрактной форме и включает логическое описание элементов данных, отношений между ними и логическую структуру БД. Любые доступные пользователю даны должны содержаться на данном уровне.
§ Хранилище данных представляет собой предметно-ориентированное, интегрированное, связанное со временем и неизменное во времени собрание данных. Основными составляющими структуры являются таблицы измерений и фактов.
§ Концептуальная многомерная модель данных реализуется на основе представления данных в виде многомерного пространства, размерность которого определяется количеством измерений.
§ Компанией Microsoft предложена концепция универсальной многомерной модели данных UDM. Эта концепция позволяет различным приложениям получить доступ к данным реляционных и многомерных БД.
Контрольные вопросы
1. Размерность многомерного пространства данных для анализа математически определяется:
а) сложением размеров всех измерений в модели данных;
б) количеством атрибутов в реляционной таблице фактов;
в) количеством таблиц содержащих измерения;
г) перемножением размеров всех измерений в модели данных.
2. Размер или кардинальность измерения определяется:
а) количеством атрибутов и свойств в измерении;
б) количеством значений ключа в таблице измерения;
в) количеством элементов в измерении;
г) количеством записей в таблице измерений;
3. Роль унифицированной многомерной модели заключается:
а) в создании концептуальной модели хранилища данных;
б) в определении функциональной зависимости между данными;
в) в определении реляционных отношений между сущностями;
г) в создании моста между пользователем и источниками данных.
4. Схема реляционного хранилища данных носит название «снежинка», если:
а) хранилище данных содержит несколько таблиц с фактами;
б) одно из измерений хранилища данных содержится в нескольких связанных таблицах;
в) каждое измерение хранилища данных содержится в одной таблице;
г) каждое измерение хранилища данных содержится в нескольких связанных таблицах.
5. Многомерная модель данных определяет представление данных на уровне:
а) концептуальной модели и прикладной модели;
б) концептуальной модели и физической модели;
в) физической модели и прикладной модели;
г) концептуальной, физической и прикладной моделей.
Литература
1. Малыхина М.П. Базы данных: основы, проектирование, использование. – Спб.: БХВ-Петербург, 2004. – 512 с.
2. Бергер А.Б. Microsoft SQL Server 2005 Analysis Services. OLAP и многомерный анализ данных / Бергер А.Б, Горбач И.В., Меломед Э.Л, Щербинин В.А., Степаненко В.П. / Под общ. Ред. А.Б. Бергера, И.В. Горбач. – СПб.: БХВ-Петербург, 2007. – 928 с.
3. Барсегян А.А. Методы и модели анализа данных: OLAP и Data Mining / Барсегян А.А., Куприянов М.С., Степаненко В.В., Холод И.И. – СПб.: БХВ-Петербург, 2004. – 336 с.
Дата добавления: 2018-10-26; просмотров: 697; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!