Иерархические алгоритмы кластеризации
Иерархические алгоритмы кластерного анализа в свою очередь разделяют на агломеративные и дивизимные.
В иерархических агломеративных алгоритмах кластеризации исходное множество объектов  представляется как множество кластеров
представляется как множество кластеров  . Таким образом, на первом шаге алгоритма имеем:
. Таким образом, на первом шаге алгоритма имеем:
 и
и  .
.
На втором шаге алгоритма, используя выбранную меру близости  , находят кластеры с наименьшим удалением друг от друга и осуществляют слияние кластеров
, находят кластеры с наименьшим удалением друг от друга и осуществляют слияние кластеров 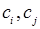 в общий кластер
в общий кластер  . Процесс поиска кластеров с наименьшим удалением и их слияние повторяют. В результате формируются множества кластеров мощностью
. Процесс поиска кластеров с наименьшим удалением и их слияние повторяют. В результате формируются множества кластеров мощностью  ,
,  ,
, 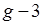 , …. Пересчет расстояния между кластером
, …. Пересчет расстояния между кластером 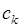 и кластером
и кластером  выполняют по формуле:
выполняют по формуле:
 ,
,
где  – расстояние между кластерами
– расстояние между кластерами  ,
,  – расстояние между кластерами
– расстояние между кластерами  ,
,  – расстояние между кластерами
– расстояние между кластерами 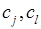 ,
,  – весовые коэффициенты. В методе медиан используются следующие значения коэффициентов:
– весовые коэффициенты. В методе медиан используются следующие значения коэффициентов:  [1].
[1].
В дивизимных алгоритмах исходное множество представляется как единственный кластер. Таким образом, на первом шаге имеем:
 .
.
На втором шаге алгоритма выбирается объект  , который наиболее удален от других объектов в этом кластере. Удаление объекта определяется как наибольшее среднее расстояния до других объектов кластера и рассчитывается по формуле:
, который наиболее удален от других объектов в этом кластере. Удаление объекта определяется как наибольшее среднее расстояния до других объектов кластера и рассчитывается по формуле:
 .
.
Формируется новый кластер 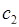 . Выбранный объект удаляется из кластера
. Выбранный объект удаляется из кластера  и помещается в кластер (
и помещается в кластер ( 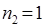 ). На последующих шагах алгоритма объекты из кластера
). На последующих шагах алгоритма объекты из кластера  , у которых разность значений между средним расстоянием до объектов в
, у которых разность значений между средним расстоянием до объектов в  и средним расстоянием до объектов в наибольшая, переносятся в . Перенос объектов из
и средним расстоянием до объектов в наибольшая, переносятся в . Перенос объектов из 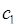 в продолжается до тех пор, пока разности средних расстояний не станут отрицательными. В результате выполнения последовательности шагов формируются два кластера.
в продолжается до тех пор, пока разности средних расстояний не станут отрицательными. В результате выполнения последовательности шагов формируются два кластера.
К одному из сформированных кластеров применяют рассмотренную выше процедуру разделения. Выбор кластера для разделения может осуществляться на основе оценки диаметров кластеров. Оценка диаметра кластеров выполняется с применением формулы:
 ,
, 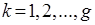 .
.
Разделение кластеров производится до тех пор, пока все члены одного кластера не будут отвечать требованию близости или все кластеры будут содержать по одному объекту.
Неиерархические алгоритмы кластеризации
Неиерархические алгоритмы обеспечивают разделение объектов при заданной целевой функции. Таким образом, при разделении объектов стремятся достичь максимума или минимума целевой функции.
В алгоритме k- means на первом шаге задаётся  произвольных центров и точность кластеризации
произвольных центров и точность кластеризации  . В качестве центров могут быть выбраны объекты множества
. В качестве центров могут быть выбраны объекты множества  . На втором шаге все объекты разделяют по критерию близости к одному из центров на кластеров. Третий шаг алгоритма связан с вычислением новых центров кластеров. Координаты центров в пространстве
. На втором шаге все объекты разделяют по критерию близости к одному из центров на кластеров. Третий шаг алгоритма связан с вычислением новых центров кластеров. Координаты центров в пространстве  вычисляются как средние значения атрибутов объектов, входящих в состав сформированных кластеров. При этом новые центры могут отличаться от центров, использованных для разделения объектов на предшествующем шаге. Далее производится разбиение на кластеры с использование новых центров.
вычисляются как средние значения атрибутов объектов, входящих в состав сформированных кластеров. При этом новые центры могут отличаться от центров, использованных для разделения объектов на предшествующем шаге. Далее производится разбиение на кластеры с использование новых центров.
Процедуры разделения на кластеры повторяются. Разделение завершается, если координаты центров и границы кластеров перестают меняться.
Алгоритм Fuzzy C- Means является обобщением алгоритма k- means. Основное отличие алгоритма – кластеры представляются нечёткими множествами. Каждый объект принадлежит кластеру с различной степенью принадлежности.
Дата добавления: 2018-10-26; просмотров: 405; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!