Основные предпосылки управления проектами 10 страница
Таблица 5.2 – Классы выборки
| Интервал | Количество значений в интервале | Частота | Накопленная частота | |
| Нижняя граница | Верхняя граница | |||
| 0.829 | 0.9969 | 22 | 0.252874 | 0.252874 |
| 0.9969 | 1.1648 | 34 | 0.390805 | 0.643678 |
| 1.1648 | 1.3327 | 16 | 0.183908 | 0.827586 |
| 1.3327 | 1.5006 | 4 | 0.045977 | 0.873563 |
| 1.5006 | 1.6685 | 8 | 0.091954 | 0.965517 |
| 1.6685 | 1.8364 | 0 | 0 | 0.965517 |
| 1.8364 | 2.0043 | 1 | 0.011494 | 0.977011 |
| 2.0043 | 2.1722 | 0 | 0 | 0.977011 |
| 2.1722 | 2.3401 | 0 | 0 | 0.977011 |
| 2.3401 | 2.508 | 2 | 0.022989 | 1 |
| Сумма | 87 | 1 | ||
Строим график частости в виде столбцовой диаграммы (см. рисунок 5.3) и графически определяем модальное значение.

Рисунок 5.3 – График частоты по классам и модальные значения выборки
На основании графика можно сделать вывод о наличии нескольких модальных значений, что, в свою очередь, позволяет сделать вывод об отсутствии нормального закона распределения случайной величины и наличие левой асимметрии.
Для определения графическим способом медианного значения строим график накопленной частости рисунок 5.4
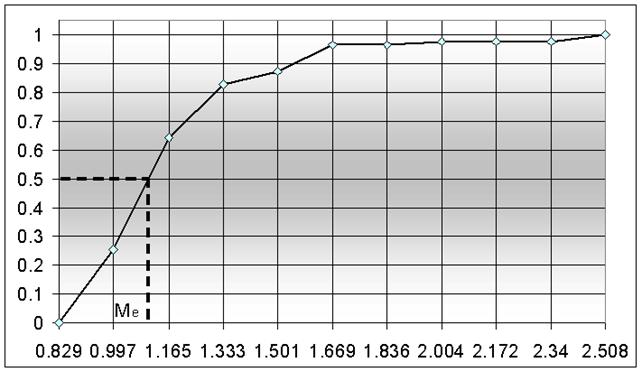
Рисунок 5.4 – Диаграмма накопленной частоты с графическим определением медианного значения.
В результате можно рассчитать значение моды и медианы. Для данной выборки будет четыре значения моды: 0.896, 1.556, 1.920, 2.424. Медианное значение всегда одно и равняется: 1.103. При расчете медианны необходимо помнить, что если частости представляют собой удельные весовые коэффициенты для каждого интервала, то n в формуле 9 будет равно единице. В случае, когда используются количество значений попавших в интервал без деления на количество в выборке, то n приравнивается к числу значений в выборке.
|
|
|
Так же определим с помощью рисунка 5.1 тип распределения случайной величины. Как видно не к одному из распределений значение не близко, но попадает в зону влияния логарифмического нормального закона. Следовательно, опираться при выводах следует больше на моду и медиану, чем на значение среднего.
Опираясь на рассчитанные данные можно сделать следующий вывод. В среднем (1.172) регионы имеют средневзвешенный индекс риска за 2005–2006 гг. выше, чем у России в целом. Медианное значение имеет также высокий показатель риска, что свидетельствует большей плотности данных выше единицы (Россия=1). Но если обратить внимание на первое модальное значение, то это означает, наибольшую вероятность имеют регионы с низким уровнем средневзвешенным индексом риска. Этот вывод подтверждается близостью данных к логарифмически нормальному закону распределения, где асимметрия сдвигает моду в левую сторону от среднего значения.
Эта методика позволяет делать выводы о локальном значении относительно всей выборки, так для Иркутской области средневзвешенный индекс риска за 2005–2006 равен 1.182, т.е. область попадает в интервал третьего класса и имеет значение ниже среднего. Но учитывая ошибку среднего (0.031) отклонение от среднего незначительное.
|
|
|
Более интересными могут получиться выводы, когда используются весовые коэффициенты, так для данного анализа весовыми значениями могут быть плотность населения регионов, территория региона, наличие подготовленных к освоению и эксплуатируемых месторождений полезных ископаемых и т.д.
5.3. Регрессионный анализ
Регрессионный анализи корреляционный анализ необходимы для выявления корреляций и их лагов — задержек, их периодичности. А также выявления тенденции. Связь в одном процессе — это автокорреляция, а связь между двумя процессами — это кросс-корреляция. Высокий уровень корреляции может служить индикатором причинно-следственных связей, взаимодействий внутри одного процесса, между двумя процессами, а величина лага указывает временную задержку в передаче взаимодействия.
Обычно в процессе расчета значений корреляционной функции на k-м шаге вычисляется ковариация между переменным по длине отрезком i = 1, ..., (n — k) первого ряда X и отрезком i = k, ... n второго ряда Y, где используются средние значения полноразмерных рядов, а не собственно этих отрезков.
|
|
|
Осреднение, деление производится не на один элемент отрезка n — j, а на один элемент полноразмерного ряда, включающего n элементов. Затем эта ковариация нормируется на стандартные отклонения полноразмерных рядов, а не собственно упомянутых отрезков.
В результате получается некоторая трудная для практической интерпретации величина, напоминающая коэффициент корреляции Пирсона, но не идентичная ему. Поэтому возможности корреляционного анализа, методика которого используется во многих статистических пакетах, ограничены узким кругом стационарных и эргодических временных рядов, которые не характерны для большинства экономических процессов.
На это обратил внимание А.П.Кулаичев, он постарался устранить указанный недостаток. Экономистов в корреляционном анализе интересует исследование лагов в передаче воздействия от одного процесса другому или влияния начального возмущения на последующее развитие того же самого процесса. Для решения таких задач А.П.Кулаичев предложил модификацию известного метода, названную интервальной корреляцией.
Интервальная корреляционная функция представляет собой последовательность коэффициентов корреляции Пирсона, вычисленных между фиксированным отрезком первого ряда заданного размера и положения и равными им по размеру отрезками второго Ряда, выбранных с последовательными сдвигами от начала ряда.
|
|
|
В определение добавляются два новых параметра: длина сдвигаемого фрагмента ряда и его начальное положение, а также используется принятое в математической статистике определение коэффициента корреляции Пирсона. Благодаря этому вычисляемые значения становятся сравнимы между собой и просто интерпретируемы.
Для выполнения анализа необходимо выбрать одну или соответственно две переменные для автокорреляционного, или кросскорреляционного анализа, а также задать следующие параметры:
· размерность временного шага анализируемого ряда для согласования результатов с реальной временной шкалой;
· длину сдвигаемого фрагмента первого ряда в виде числа включаемых в него измерений;
· сдвиг этого фрагмента относительно начала ряда.
Разумеется, необходимо выбрать вариант интервальной корреляции или иной корреляционной функции.
Если для анализа выбрана одна переменная, то вычисляются значения автокорреляционной функции для последовательно увеличивающихся лагов. Автокорреляционная функция позволяет определить, в какой степени динамика изменения заданного фрагмента воспроизводится в сдвинутых во времени его же отрезках.
Если для анализа выбраны две переменные, то вычисляются значения кросскорреляционной функции для последовательно увеличивающихся лагов — сдвигов второй из выбранных переменных относительно первой. Кросскорреляционная функция позволяет определить, в какой степени динамика изменения заданного фрагмента первого ряда воспроизводится в сдвинутых во времени фрагментах второго ряда.
Результаты анализа должны включать оценки критического значения коэффициента корреляции r0 для гипотезы r0 = 0 на определенном уровне значимости. Это позволяет не принимать во внимание статистически незначимые коэффициенты корреляции. Необходимо получить значения корреляционной функции с указанием лагов. Весьма полезны и наглядны графики авто- или кросскорреляционных функций.
Базовые понятия регрессионного анализа опираются на классическое представление о связи данных. Ниже приведены основные формулы необходимые для его проведения.
В практике прогнозирования и планирования часто встречаются случаи, когда необходимо проанализировать связь между двумя событиями, или показателями. Для этого используют свойство смешанного центрального момента. Показатель меры связи между двумя радами данных называется ковариацией. Рассчитывается следующим образом:
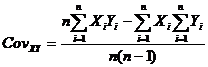 (14)
(14)
Ковариация имеет размерность такую же, как размерность данных в исходном ряде, как и в случае со стандартным отклонением это затрудняет принятие решений, поэтому используют не абсолютный, а относительный показатель связи между двумя выборками – коэффициент корреляции. Он рассчитывается по формуле 15.
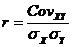 (15)
(15)
Существует упрощенная формула расчета коэффициента корреляции:
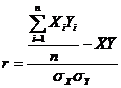
Необходимо помнить, что при малом числе значений (<100) и высоким уровнем связи между данными данная формула имеет ошибку определения коэффициента корреляции.
Данный коэффициент имеет приделы варьирования (-1..1). При значениях равных 1 или -1 связь является функциональной. В некоторых случаях функциональная связь может скрываться за флуктуациями какого-либо параметра и коэффициент корреляции не будет равен 1, но при этом выводы о наличии не функциональной связи будут неправильны. Как, например, при сравнении цен на сырье в рублях и долларах США расчет может дать коэффициент корреляции не равный единицы. Это связано с изменением курса рубля к доллару США, в данном случае изменение параметра курса не зависит от изменения стоимости сырья.
Коэффициент корреляции необходимо оценивать с помощью показателя ошибки и надежности. Стандарт (ошибка) коэффициента корреляции рассчитывается по формуле:

Этот показатель используют для расчета надежности коэффициента корреляции, который рассчитывается по формуле:
 (16)
(16)
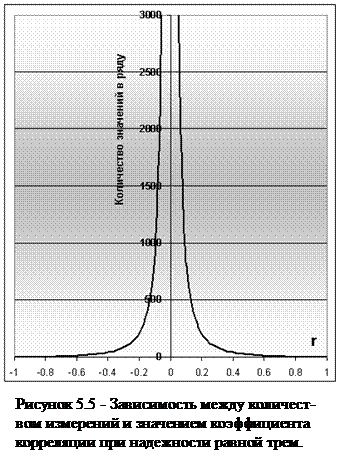
Расчет коэффициента корреляции считается надежным, если показатель, рассчитанный по формуле 16 будет больше трех, в обратном случае необходимо увеличивать число измерений. Зависимость между количеством значений в выборке и коэффициента для надежности равной трем, представлена на рисунке 5.5. Сплошная линия начинается с нуля для значения коэффициента корреляции равного: -1 и по мере приближение к значению 0 уходит в бесконечность. Для положительного коэффициента корреляции ситуация повторяется зеркально. Можно сделать вывод, что в случае, когда имеется выборка менее 100 значений, коэффициент корреляции находится в приделах от -1 до -0,28 и от 0,28 до 1, то ненадежность вычислений будет низкая.
 Далее необходимо сделать вывод о связи между данными. Когда при изменении одного из показателя с положительным приращением второй показатель изменяется тоже положительно, то такая связь будет называться прямой. Обратная связь имеет приращения с разными знаками. Теснота связи между выборками обычно разделяется на три типа: слабая, умеренная и сильная. А также выделяют область с незначительной связью или ее отсутствием. Все эти приделы приведены в таблице 5.3.
Далее необходимо сделать вывод о связи между данными. Когда при изменении одного из показателя с положительным приращением второй показатель изменяется тоже положительно, то такая связь будет называться прямой. Обратная связь имеет приращения с разными знаками. Теснота связи между выборками обычно разделяется на три типа: слабая, умеренная и сильная. А также выделяют область с незначительной связью или ее отсутствием. Все эти приделы приведены в таблице 5.3.
Таблица 5.3 – Значения приделов коэффициентов корреляции в зависимости от тесноты связи.
| Тип связи | Прямая | Обратная |
| Сильная | 0,75 … 1 | -1 … -0.75 |
| Умеренная | 0,5 … 0,75 | -0,75 … -0,5 |
| Слабая | 0,25 … 0,5 | -0,5 … -0,25 |
| Незначительная | 0 …0,25 | -0,25 … 0 |
Существуют частные случаи связи такие, когда коэффициент корреляции равен нулю, возможно, что это функциональная связь, смещенная на четверть периода периодической функции. А также коэффициент корреляции может быть не определен, если один из рядов имеет дисперсию близкую к нулю.
Следующим этапом регрессионного анализа является вычисление уравнения регрессии. Данное уравнение имеет вид линейной функции типа y=ax+b. Где a и b являются коэффициентами, а x и y- переменными. Необходимо помнить о существовании корреляционного парадокса, т.е. зависимость x от y и y от x будут иметь свои самостоятельные уравнения. Поэтому формулы уравнения регрессии будет две:
x от y: 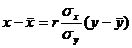 (17)
(17)
y от x: 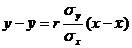 (18)
(18)
Для упрощения можно из формул 17 и 18 вычислить формулы коэффициентов уравнения регрессии:
x от y:  ;
; 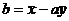 .
.
Таким же образом выводятся формулы коэффициентов уравнения регрессии для зависимости y от x. Необходимо помнить, что независимо от типа связи эти линии будут пересекаться в середине графика с исходными данными. А также, чем выше коэффициент корреляции, тем ближе линии будут стоять друг к другу, и угол наклона будет стремиться к 45º. Тоже действует для обратной связи. Рекомендуется наряду с регрессионным анализом проводить дисперсионный анализ или вычислять показатель Фишера.
5.4. Особенности анализа временных рядов при прогнозировании экономической динамики
Временной ряд представляет собой совокупность последовательных измерений показателя, произведенных через одинаковые интервалы времени. Анализ временных рядов позволяет решать следующие задачи:
· исследовать структуру временного ряда, включающую, как правило, тренд — закономерные изменения среднего уровня, а также случайные периодические колебания;
· исследовать причинно-следственные взаимосвязи между процессами, проявляющиеся в виде корреляционных связей между временными рядами;
· построить математическую модель процесса, представленного временным рядом;
· прогнозировать будущее развитие процесса;
· преобразовать временной ряд средствами сглаживания и фильтрации.
Значительная часть известных методов предназначена для анализа стационарных процессов, статистические свойства которых (характеризуемые в случае нормального распределения средним значением и дисперсией) не меняются с течением времени.
Ряды часто имеют нестационарный характер. Нестационарность можно устранить следующим образом:
· вычесть тренд, то есть изменения среднего значения, представленного некоторой детерминированной функцией, которую можно подобрать путем регрессионного анализа;
· выполнить фильтрацию специальным нестационарным фильтром.
Для стандартизации временных рядов с целью единообразия методов анализа целесообразно провести их общее или посезонное центрирование путем деления на среднюю величину, а также нормирование путем деления на стандартное отклонение.
Центрирование ряда удаляет ненулевое среднее значение, которое может затруднить интерпретацию результатов, например при спектральном анализе. Цель нормирования — избежать в вычислениях операций с большими числами, что может привести к снижению точности расчетов.
После указанных предварительных преобразований временного ряда может быть построена его математическая модель, по которой осуществлено прогнозирование, то есть, получено некоторое продолжение временного ряда. Чтобы результат прогноза можно было сопоставить с исходными данными, над ним следует произвести преобразования, обратные выполненным.
На практике наиболее часто используют методы моделирования и прогнозирования, а корреляционный и спектральный анализ рассматривают как сугубо вспомогательные методы. Это заблуждение. Методы прогнозирования развития средних тенденций позволяют получить оценки с существенными погрешностями, что затрудняет выработку сценариев и формирование стратегии.
Методы корреляционного и спектрального анализа позволяют выявить различные, в том числе инерционные свойства системы, в которой идет развитие изучаемых процессов. Применение этих методов позволяет по текущей динамике процессов с достаточной уверенностью установить, как и с какой задержкой известная динамика скажется на будущем развитии процессов. Для долгосрочного и сценарного прогнозирования эти виды анализа позволяют получить наиболее ценные результаты.
Анализ тренда предназначен для исследования изменений среднего значения временного ряда с построением математической модели тренда и с прогнозированием на этой основе будущих значений ряда. Анализ тренда выполняют путем построения моделей простой линейной или нелинейной регрессии.
Исходные данные представляют собой две переменные, одна из которых — значения временного параметра, а другая — собственно значения временного ряда. В процессе анализа можно получить следующие результаты:
· опробовать несколько математических моделей тренда и выбрать ту, которая с большей точностью описывает динамику изменения временного ряда;
· построить прогноз будущего поведения временного ряда на основании выбранной модели тренда с определенной доверительной вероятностью;
· удалить тренд из временного ряда с целью обеспечения его стационарности, необходимой для корреляционного и спектрального анализа.
В качестве моделей трендов используют различные элементарные функции и их сочетания, а также степенные ряды, иногда называемые полиномиальными моделями. Наибольшую точность обеспечивают модели в виде рядов Фурье, однако очень немногие статистические пакеты позволяют использовать такие модели.
Дата добавления: 2018-04-15; просмотров: 355; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!