Корреляционный анализ номинативных признаков. Коэффициенты ассоциации и сопряженности: понятие, процедура вычисления и условия применения.
К непараметрическим методам исследования (измеренным в номинальных шкалах) можно отнести коэффициент ассоциации Q и коэффициент сопряженности Ф, которые используются, если, например, необходимо исследовать тесноту зависимости между качественными признаками, каждый из которых представлен в виде альтернативных признаков.
Для определения этих коэффициентов создается расчетная таблица (таблица сопряженности - таблица «четырех полей»), где статистическое сказуемое схематически представлено в следующем виде:
| Признаки | Х1 (да) | Х0 (нет) | Сумма |
| Y1 (да) | a | b | a + b |
| Y0 (нет) | с | d | c + d |
| Сумма | a + c | b + d | n |
Здесь а, b, c, d - частоты взаимного сочетания (комбинации) двух альтернативных признаков X и Y ; n - общая сумма частот.
Коэффициент ассоциации можно рассчитать по формуле:

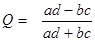
Коэффициент сопряженности рассчитывается по формуле фи-корреляции Пирсона (называется также тетрахорическим показателем связи):

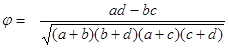
Нужно иметь в виду, что для одних и тех же данных коэффициент сопряженности (изменяется от -1 до +1) всегда меньше коэффициента ассоциации (так как более жесткий) и предназначен для измерения двухсторонней связи (корреляции) между значениями коррелируемых показателей.
Достоверность корреляции определяется по формуле c2 = N * j2
Следующий этап – обращение к таблице критических значений c2 к строке df = 1 (в случае тетрахорической связи степень свободы всегда равна 1).
Пример:
| Сдал зачет с первого раза | Не сдал зачет с первого раза | сумма | |
| Посещал все лекции | 20 | 5 | 25 |
| Посещал не все лекции | 6 | 16 | 22 |
| Сумма | 26 | 21 | 47 |
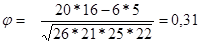
Достоверность корреляции определяется по формуле c2 = N * j2
c2кр (р £ 0,001) =10,8
c2кр (р £ 0,01) = 6,6
c2кр (р £ 0,05) = 3,8
В нашем случае c2эмп = 47 * 0,31 = 4,52. c2эмп > c2кр (р £ 0,05) Þ Н1 ! ст.зн.
Таким образом, на уровне статистической значимости установлена связь между фактами посещения студентом всех занятий и сдачи им зачета с первого раза.
Интерпретация корреляции. Представление корреляционных показателей в форме интеркорреляционной матрицы. Построение корреляционных плеяд и их анализ.
Какова прогностическая значимость вычисления корреляций? Оно помогает установить, можно ли предсказывать возможные значения одного показателя, зная величину другого.
Корреляционный анализ делает нашу жизнь более предсказуемой
Примеры интерпретации корреляции:
1) Исследователь показывает, что время, которое тратится ребенком-дошкольником на ролевые игры, связано с развитием его произвольности, и после этого делается вывод о необходимости больше играть с дошкольниками в ролевые игры, т.к. это будет способствовать росту произвольного поведения.
2) Исследователь обнаруживает корреляцию между употреблением наркотиков подростками и их нежеланием учиться в школе и делает вывод о том, что употребление наркотиков приводит к снижению (падению) учебной мотивации.
Процедура корреляционного анализа предполагает подготовку таблицы данных (называется также матрицей наблюдения), где в первом столбце приводятся коды или фамилии испытуемых, а последующие столбцы содержат значения зарегистрированных признаков.
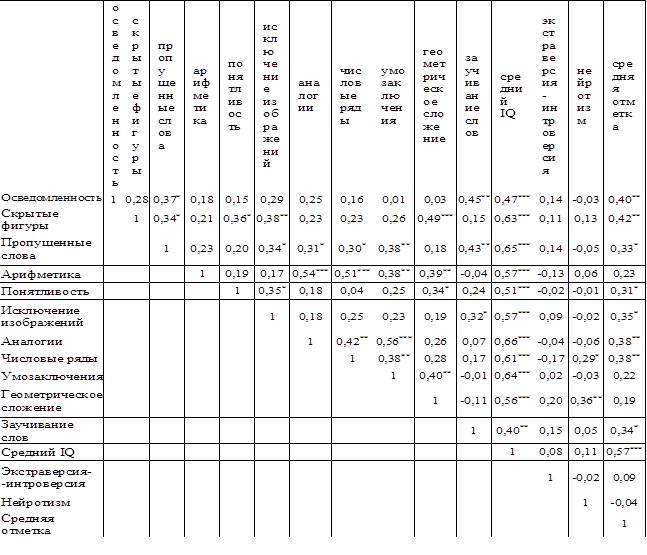
Дальнейший этап – составление матрицы интеркорреляций. Например, для показателей субтестов «осведомленность» и «скрытые фигуры» значение коэффициента rxy = 0,28. Вручную обработка матрицы занимает очень много времени, поэтому рекомендуется для этой цели использовать компьютерные программы: например, Statistica, SPSS или Excel последних версий.
Поскольку таблица симметрична относительно диагонали, нижнюю часть матрицы можно не печатать. Отдельный фрагмент матрицы интеркорреляции, когда по горизонтали представлены одни признаки, а по вертикали – другие, можно называть корреляционной матрицей.
Следующий этап заключается в маркировке соответствующим числом звездочек тех значений коэффициентов, которые статистически значимо отличаются от нуля (р £ 0,05, 0,01, 0,001). Можно также для обозначения разных уровней достоверности использовать фломастеры разного цвета. После данной процедуры таблица будет выглядеть следующим
Затем следует построение корреляционного графа. На чертеже представляются отдельные качества, измеренные субтестами, при этом коррелирующие качества соединяются линиями. Рекомендуются употреблять следующие типы линий:
| r > 0 | r < 0 | |
 0,1 0,1
| 
| |
 0,05 0,05
| 
| |
 0,01 0,01
| 
| |
 0,001 0,001
| 
|
Фрагмент графа называется корреляционной плеядой.
Корреляционные плеяды являются формой графического отображения корреляционных связей между параметрами, включенными в корреляционный анализ.
Это интересно! Впервые термин «корреляционные плеяды» был применен П. В. Терентьевым в 1928 году и обозначал группы признаков или свойств, связанных между собой близкими по величине коэффициентами корреляции, но независимыми от признаков других групп. Этот метод дает полное представление о комплексе коррелирующих признаков.
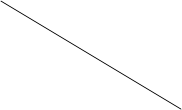
Ниже дан пример корреляционных графов, демонстрирующих структурированность лингвистических способностей у студентов, характеризующихся высоким (слева) и низким (справа) уровнем обучаемости (данные получены по результатам исследования проведенного А.Н. Кутейниковым).

|

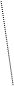
|









|
|
|
|
|
|
|


Рис. 3. Корреляционная плеяда
Условные обозначения:
1 – Общая обучаемость иностранному языку
2 – Вербальная оперативная память
3 – Способность к установлению языковой закономерности
4 – Способность к вероятностному прогнозированию
5 – Слуховая дифференциальная чувствительность
Другой вариант корреляционной плеяды.
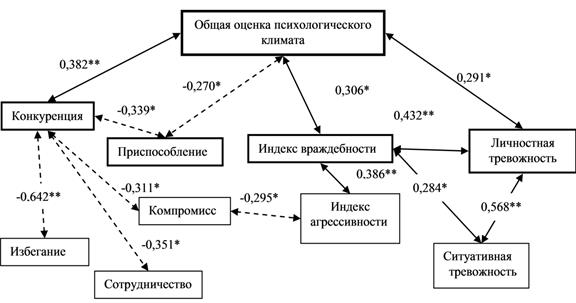
Рис.4.
Примечание:

Мы можем сделать вывод, что конкуренция – ядро корреляционной плеяды. Менее значимым ядром является общая оценка психологического климата.
Для изображения корреляционных плеяд используется геометрическое представление о сопряженности признаков в виде корреляционного кольца. На рисунке 5 и 6 показана степень корреляции (взаимосвязи и взаимозависимости) анализированных с помощью коэффициента Кендэлла параметров экспертной оценки умений студентов.
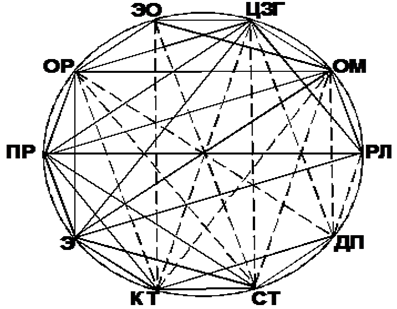
Рис. 5. Корреляционное кольцо корреляции параметров экспертной оценки умений студентов
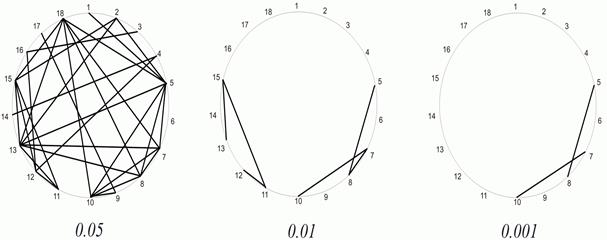
Рис. 6. Корреляционные кольца корреляции параметров испытуемых на разных уровнях значимости
В развитии этого метода Терентьевым П. В. была предложена геометрическая модель, так называемый корреляционный цилиндр. Цилиндр мысленно рассекается на разных уровнях поперечными плоскостями, и каждое сечение представляет собой корреляционное кольцо.
Пример: корреляционный цилиндр с обобщенными данными по степени сходства исследованных параметров у студентов разных профилей химико- биологического факультета можно представить в виде модели, изображенной на рисунке 7.
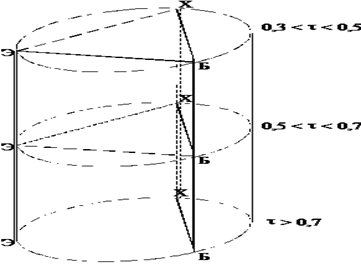
Рис.7. Корреляционный цилиндр сходства параметров экспертной оценки умений студентов разных профилей химико-биологического факультета
Корреляционный цилиндр был рассечен на трех уровнях, имеющих следующие обозначения:
• точками нанесены корреляции уровня 0,3<r<0,5 (слабая связь);
• пунктиром нанесены корреляции уровня 0,5<r<0,7 (средняя связь);
• сплошной линией нанесены корреляции уровня r>0,7 (тесная связь).
ОБРАБОТКА НА КОМПЬЮТЕРЕ (с помощью SPSS)
1. Графики двумерного рассеивания. Выбираем Graphs ... > Scatter ... > Simple . Нажимаем Define . В появляющемся окне назначаем осям переменные: выделяем слева одну переменную, нажимаем > напротив «X Axis» (Ось X), выделяем другую переменную, нажимаем > напротив «Y Axis». Нажимаем ОК. Получаем график рассеивания назначенных переменных.
2. Вычисление парных корреляций. Выбираем Analyze > Correlate > Bivariate ... В открывшемся окне диалога переносим интересующие переменные из левой части в правую при помощи кнопки > (переменных должно быть как минимум две). По умолчанию стоит флажок «Pearson» (корреляция г-Пирсона). Если интересует корреляция r-Спирмена или т-Кендалла, необходимо поставить соответствующие флажки внизу. Нажимаем ОК. В появившейся таблице строки и столбцы соответствуют выделенным ранее переменным. В ячейке на пересечении строки и столбца, соответствующих интересующим нас переменным, видим три числа: верхнее соответствует коэффициенту корреляции, нижнее - численности выборки N , среднее - уровню значимости.
3. Вычисление частной корреляции. Выбираем Analyze > Correlate > Partial .. В открывшемся окне диалога переносим интересующие переменные из левой части в правое верхнее окно ( Variables :) при помощи верхней кнопки > (переменных должно быть как минимум две). Затем при помощи нижней кнопки > из левой части в правое нижнее окно ( Controlling for :) переносим переменную, значения которой хотим фиксировать. Нажимаем ОК. Получаем таблицу, аналогичную таблице парных корреляций, но верхнее число в каждой ячейке - значение частной корреляции соответствующих двух переменных при фиксированном значении указанной третьей переменной. Нижнее число - уровень значимости, а посередине - число степеней свободы.
Вопросы для обсуждения:
1. Дайте определение термину «корреляция».
2. В каких пределах может изменяться коэффициент корреляции?
3. Может ли зависимость одного явления от другого говорить о корреляции?
4. Как связаны объем выборки и уровень значимости корреляции?
5. Для какого типа шкал использует коэффициент корреляции Пирсона?
6. Какие методы используются для вычисления величины линейной корреляции?
7. Если подтвердилась нулевая гипотеза, то это говорит о случайности или неслучайности корреляции?
8. Какие методы используются для вычисления величины ранговой корреляции?
9. На каком принципе основан подсчет величины ранговой корреляции по Спирмену?
10. Как вычислить коэффициенты номинативной корреляции?
11. Какого эффекта (применительно к вычислению корреляции) можно добиться, изменив объем выборки?
Дата добавления: 2019-07-15; просмотров: 1829; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!