Понятие о хешировании и индексировании
Для повышения скорости обмена информацией процессора с базой данных используется специальный прием, получивший название хеширование, при котором операционная система обеспечивает в процессе работы с БД сохранение части прочитанных данных в специальной области ОЗУ, называемой дисковым хэшем . Данная функция включается в ядро системы и работает автоматически без участия пользователя. При необходимости повторного обращения к этим же данным процессор их считывает уже не с диска, а из ОЗУ, что значительно ускоряет обработку данных.
Общеизвестным недостатком табличных и иерархических структур является трудоемкость записи адреса нового элемента данных и сложность последующего их упорядочения. Более того, информация в базу данных вводится в произвольном порядке и в этом же порядке сохраняется на диске. Для быстрого поиска требуемой записи можно применить предварительное индексирование, которое заключается в том, что каждому атрибуту данных пользователь может присвоить свой уникальный индекс.
Таблица, содержащая данные, может иметь несколько индексов. В зависимости от количества полей, используемых в индексе, различают простые индексы (по одному полю) и составные индексы (по нескольким полям).
Индексы создаются, обычно, по вторичным ключам, которые могут устанавливаться в отличие от первичных ключей на такие поля, которые могут содержать повторяющиеся значения (данные).
Для каждого значения индекса в индексном файле содержится уникальная ссылка, указывающая на местоположение в таблице записи, соответствующей данному индексу. Поэтому при поиске записи осуществляется не последовательный просмотр всей таблицы, а прямой доступ к записи на основании упорядоченных значений индекса.
Можно создавать индексы трех типов:
1) уникальный индекс, в котором две строки не могут иметь одинаковые значения индекса;
2) индекс первичного ключа — автоматически создается при задании первичного ключа и является особым типом уникального индекса;
3) кластерный индекс, в котором физический порядок строк в таблице совпадает с логическим (индексированным) порядком ключевых значений. Таблица может содержать только один кластерный индекс.
Кластерный индекс обычно обеспечивает более быстрый доступ к данным по сравнению с не кластерными индексами.
В основном требуется индексировать поля, в которых часто осуществляется поиск, сортировка или поля, объединенные путем запросов с полями из других таблиц.
Следует иметь в виду, что индексы могут замедлить выполнение некоторых запросов на изменение или добавление данных, при выполнении которых потребуется обновление индексов многих полей.
Поля с типом данных «OLE» индексировать нельзя. Для остальных полей индексирование используется, если выполняются следующие условия:
· поле имеет тип данных «Текстовый», «Числовой», «Денежный» или «Дата/время»;
· предполагается выполнение поиска значений в поле;
· предполагается выполнение сортировки значений в поле.
Если предполагается частое выполнение одновременной сортировки или поиска в нескольких полях, можно создать для этих полей составной индекс, например, для полей «Имя» и «Фамилия».
Составные индексы позволяют различать записи, в которых в одном столбце имеются одинаковые значения.
В составной индекс можно включить до 10 полей.
Индексы занимают дополнительное место на диске и могут замедлить операции добавления, удаления и обновления данных, содержащихся в нескольких таблицах. Поэтому при частом обновлении данных в приложении или при ограничениях на дисковое пространство следует ограничивать их количество.
Перед созданием индекса необходимо принять решение, какие поля (атрибуты) использовать и какой тип индекса следует выбрать.
Пусть, например, имеются таблица 1 и таблица 2. В табл. 1 уже есть индекс первичного ключа — поле Код клиента, с помощью которого она связана со всеми другими таблицами по финансовым операциям клиентов банка, в том числе и с табл. 2.
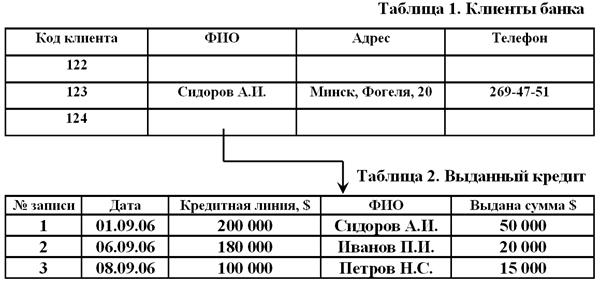
На рис. 3.1. показано, как можно построить логическую структуру табл. 2 с помощью индексации полей: Дата, Кредитная линия, ФИО (клиента), Выдана сумма.
| Индекс даты | Индекс линии | Индекс клиента | Индекс суммы | ||||
| Дата | № записи | Кредитная линия, $ | № записи | ФИО | № записи | Выдана сумма, $ | № записи |
| 01.09.06 | 1 | 100 000 | 3 | Иванов П.И. | 2 | 15 000 | 3 |
| 06.09.06 | 2 | 180 000 | 2 | Петров Н.С | 3 | 20 000 | 2 |
| 08.09.06 | 3 | 200 000 | 1 | Сидоров А.И | 1 | 50 000 | 1 |
Рис. 3.1. Принцип присвоения индексов полям (атрибутам) таблицы
Проведя такую индексацию, можно обеспечить быстрое получение (выборки) информации по выдаче кредитов:
1. В заданный день.
2. По заданной кредитной линии.
3. Конкретным клиентам.
4. Конкретной суммы кредита.
Вопросы для самопроверки
1. Поясните сущность физической и логической организации данных.
2. Назовите основные технологии, обеспечивающие физический доступ к БД.
3. Выполнение каких основных операций по организации, размещению данных и доступу к ним обеспечивают программы: диспетчер файлов и диспетчер дисков?
4. Какая основная особенность физического размещения данных и работы с ними используются в СУБД по сравнению с другими программами, например, Word и Excel?
5. В чем заключается сущность хеширования?
6. Для каких целей применяется индексирование данных в СУБД.
7. Назовите и объясните сущность основных типов индексов.
8. По каким причинам пользователь должен с осторожностью принимать решение о выборе количества и типа индексов?
Дата добавления: 2019-02-12; просмотров: 381; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!