Мал. 2.20. Інтерфейс словників Lingvo
З Lingvo 8.0 поставляється вісімнадцять словників (сукупний обсяг – 1200000 словникових статей). Крім словників загальної лексики ще і тематичні словники – економічний, політехнічний, науково-технічний, з обчислювальної техніки й програмування, з нафти і газу, медичний і юридичний.
Словники Lingvo не є точними копіями паперових аналогів. Як джерела для підготовки економічного словника “LingvoEconomics” зазначені сім словників різних авторів. Деякі словники з багатомовного набору Lingvo 8.0 сформовані і доповнені лексикографічним відділом фірми ABBYY, деякі ліцензовані. Усі словники Lingvo 8.0, крім спеціальних „Граматичного словника” і „Словника вимови” мають обидва напрями перекладу.
2.5. Cистема конвертації друкованих документів в електронну форму FineReader
 FineReader – це система розпізнавання текстових та графічних даних, в якій передбачені засоби роботи зі сканером, розпізнавання багатомовної структури, таблиць, вбудована підсистема перевірки орфографії, автоматична передача даних у Word, Excel, а також у деякі інші додатки, розсилка даних електронною поштою. Розглянемо версію програми FineReader 8.0. У цій версії додатково покращено якість розпізнавання, розширено словники для перевірки.
FineReader – це система розпізнавання текстових та графічних даних, в якій передбачені засоби роботи зі сканером, розпізнавання багатомовної структури, таблиць, вбудована підсистема перевірки орфографії, автоматична передача даних у Word, Excel, а також у деякі інші додатки, розсилка даних електронною поштою. Розглянемо версію програми FineReader 8.0. У цій версії додатково покращено якість розпізнавання, розширено словники для перевірки.
На мал. 2.21 зображене головне вікно програми FineReader.
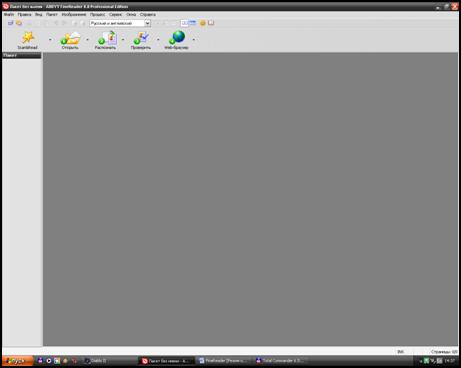
Мал. 2.21. Вікно програми FineReader
Для зручності ознайомлення з функціональними можливостями на малюнку представлені керуючі кнопки: Scan&Read, Открыть,Распознать,Проверить та Web-браузер.
Доступ до основних функцій програми також можна отримати через її головне меню, яке містить дев’ять пунктів: Файл,Правка, Вид, Пакет, Изображение, Процес, Сервис, Окна, Помощь.Перша кнопка ніби узагальнює собою всі наступні: Scan&Read викликає Майстра, виконуючи вказівки якого, можна виконати всю роботу. Схематично весь процес зводиться до таких дій: сканування, сегментування, розпізнаваннятаперевірки.
 Натиснення кнопки сканування або перший крок Майстра ініціює процес сканування. За допомогою миші визначаються межі сканування, обирається формат виводу, розподільна здатність, при потребі застосовують додаткові параметри, користуючись інструкцією до сканера.
Натиснення кнопки сканування або перший крок Майстра ініціює процес сканування. За допомогою миші визначаються межі сканування, обирається формат виводу, розподільна здатність, при потребі застосовують додаткові параметри, користуючись інструкцією до сканера.
 Процес сегментації полягає у виділенні блоків для розпізнавання однотипної структури. Здійснюється це також найпростішим способом – визначаючи мишею межі виділення.
Процес сегментації полягає у виділенні блоків для розпізнавання однотипної структури. Здійснюється це також найпростішим способом – визначаючи мишею межі виділення.
Сканований документ необхідно відкрити обравши в меню пункт ФайлÞОткрыть PDF/изображение. Якщо вам потрібно опрацювати пакет сканованих документів (наприклад, ви сканували багатосторінковий документ або розділ книги) необхідно обрати в меню пункт ФайлÞОткрыть текст. Відкривши пакет, оберіть документ для подальшої обробки (див. мал. 2.22).
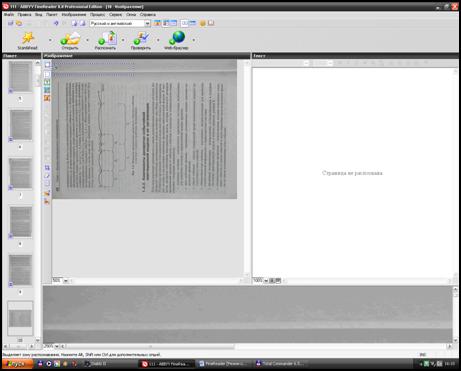
Мал. 2.22.
Вікно програми FineReader 8.0 складається з чотирьох вікон: вікна Пакет (відображаються пронумеровані документи пакету в маленькому масштабі), вікна Изображение (вікні відображається сканований документ), вікна Текст (відображається текст документа після розпізнавання), вікна Крупный план (відображається та частина документа, яку ви редагуєте у вікні Текст). Розміщення цих вікон в головному вікні програми можна змінювати використовуючи пункт меню Вид.
У вікні Текст, зліва, міститься низка піктограм (мал. 2.22). За допомогою цих піктограм можна виконати подальшу обробку документа, підготувавши його до розпізнавання. Зокрема, можна зробити аналіз макета сторінки (тобто ініціювати автоматичну сегментацію сторінки), виділити зону розпізнавання, виділити блок Текст, виділити блок Таблица, виділити блок Рисунок, видалити блок, обрізати зображення, стерти будь-який елемент зображення (наприклад, якийсь недолік сканування або номер сторінки сканованого документа), повернути сканований документ за чи проти годинникової стрілки.
Наприклад, скановане зображення, що представлене на мал. 2.22, перед розпізнаванням необхідно повернути за годинниковою стрілкою. Далі необхідно провести аналіз макета сторінки для того, щоб програма FineReader автоматично поділила сторінку на відповідні блоки. FineReader 8.0 оперує чотирма типами блоків: текст, таблиця, зображення та штрих-код.
Якщо програма помилково присвоїть блоку неправильний тип, це можна виправити натиснувши на будь-яке місце блоку правою кнопкою миші й обравши пункт меню Изменить тип блока. У підменю цього пункту слід обрати потрібний тип блоку (рис 2.23). Змінити тип блоку також можна обравши в меню пункт ИзображениеÞ Изменить тип блока.
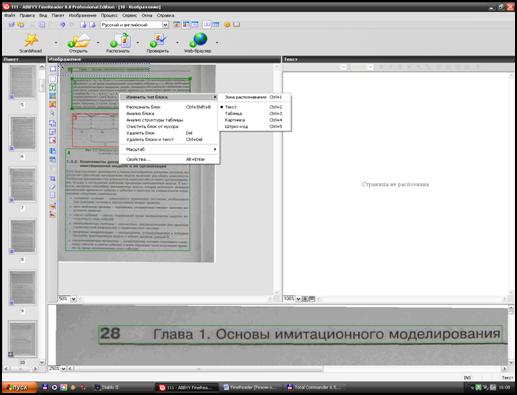
Мал. 2.23.
 Перед початком процесу розпізнавання необхідно обрати мову тексту на панелі інструментів. Якщо в тексті використовуються декілька мов, то необхідно обрати пункт Выбор нескольких языков. Ініціювати процес розпізнавання можна натиснувши кнопку Распознать або обравши в меню пункт ПроцессÞРаспознать. На рис 2.24 зображено вікно програми FineReaderпісля завершення процесу розпізнавання тексту.
Перед початком процесу розпізнавання необхідно обрати мову тексту на панелі інструментів. Якщо в тексті використовуються декілька мов, то необхідно обрати пункт Выбор нескольких языков. Ініціювати процес розпізнавання можна натиснувши кнопку Распознать або обравши в меню пункт ПроцессÞРаспознать. На рис 2.24 зображено вікно програми FineReaderпісля завершення процесу розпізнавання тексту.
Процес зчитування даних ілюструється заповненням рядків блакитним кольором, потім слова, які не вдалось розпізнати (не знайдено аналога у словниках), виділяються синім кольором. Розпізнаний текст виведеться у вікні Текст. Розпізнаний текст редагується у вікні Текст. При цьому у вікні Крупный план відображається та частина документа, яку ви редагуєте у вікні Текст. Це робить процес редагування тексту зручнішим.
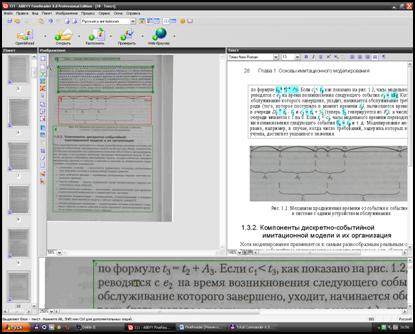
Мал. 2.24.
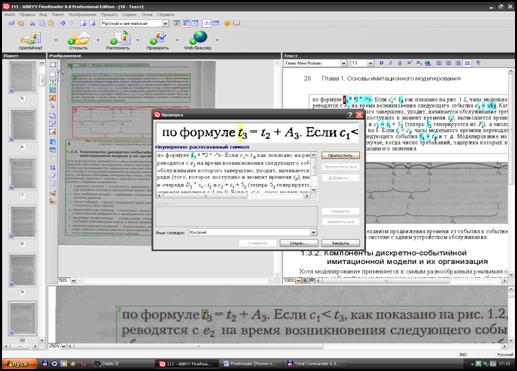
Щоб почати процес перевірки просканованого матеріалу потрібно натиснути кнопку Проверка, яка виконує команду Проверить правописание.Цього ж ефекту можна досягти, обравши в меню пункт Сервис Þ Проверка. Завантажується діалогове вікно Проверка,зображене на рис. 2.25. У ньому відображається слово, якого не знайдено у словнику, варіанти заміни, кнопки управління процесом: Пропустить, Пропустить все, Добавить, Заменить, Заменить все.
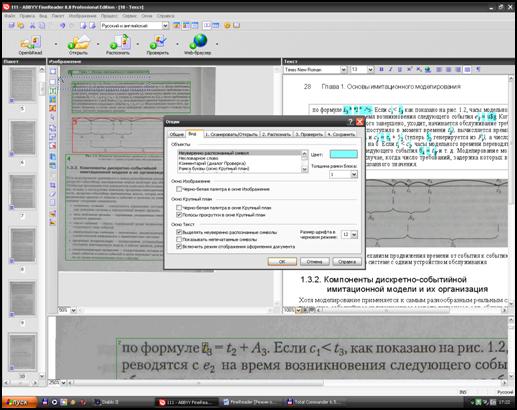
Команда меню Сервис Þ Опцииактивує однойменне діалогове вікно, представлене на рис 2.26. Це вікно містить такі вкладки: Общие, Вид, Сканировать/Открыть, Распознать, Проверить, Сохранить. На вкладці Общие можна задати загальні опції, зокрема, обрати мову інтерфейсу. Також можна задати додаткові опції (наприклад, шукати штрих-коди, задавати тип друку). На закладці Вид можна задати колір об’єктів, якими оперує програма FineReader. Такими об’єктами є блоки Текст, Рисунок, Штрих-код, Таблица, слово, літера тощо. На цій закладці також можна задати параметри відображення вікон програми. На закладці Сканировать/Открыть можна обрати драйвер для сканера, задати опції сканера, задати параметри обробки зображень тощо.
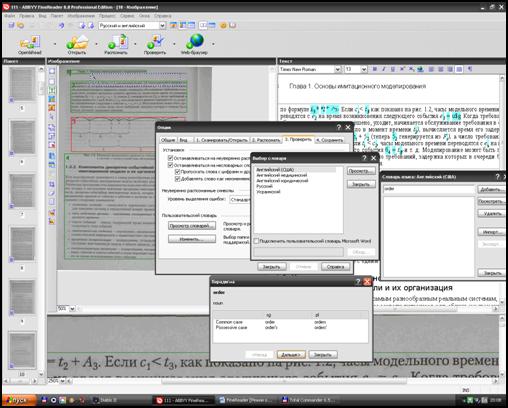
На вкладці Распознать можна задати мову та режим розпізнавання. На ній також можна задати опції для розпізнавання з навчанням. На вкладці Проверить можна переглянути та відредагувати обраний словник користувача. Для цього необхідно обрати словник, ввести слово та натиснути кнопку Просмотреть. Після цього на екрані з’явиться вікно, в якому представлені різні форми слова (рис. 2.27). На закладці Сохранить можна задати параметри збереження тексту.
Мал. 2.25.
Мал. 2.26.
Мал. 2.27.
Переглядати та редагувати словники також можна, виконавши команду Сервис/Просмотреть словники.
Після завершення роботи з FineReaderви можете зберегти пакет документів, який ви обробляли, за допомогою команди Файл Þ Сохранить как…Зберегти результати роботи можна за допомогою команди ФайлÞСохранить результаты.
На цьому процес роботи з FineReader можна вважати завершеним. Зазначимо, що пакет передбачає відкриття розпізнаних сторінок доти, аж поки їх не буде вилучено клавішею <Delete>.
2.6. Системи машинного перекладу
Ідея використання комп’ютера для автоматичного перекладу текстів виникла ще на початку появи обчислювальної техніки. Для автоматичного перекладу документів з однієї мови на іншу розроблено багато різних програм. Однак через складнощі опису семантики природних мов до цього часу остаточно проблему перекладу ще не вирішено. Проте сучасні засоби автоматизації перекладу досягли такого рівня, який дає змогу ефективно використовувати їх на практиці. Це пов’язано з тим, що в наукових, технічних, економічних та інших текстах, на відміну від художніх, використовується обмежена кількість мовних конструкцій, які більше орієнтовані на однозначну інтерпретацію.
Оцінюючи актуальність автоматизації перекладу, уже цитований нами Дж. Слокум вважав, що фахівця, який бажає бути в курсi подiй у своїй науковiй, технiчнiй галузі, цiлком задовольняє недорога система МП, яка здiйснює швидкий, хоча й недосконалий переклад текстової iнформацiї. В найгiршому випадку, тобто при одержаннi вiд машини перекладу недостатньо високої якостi, фахiвець мiг би, вирiшити, чи потрiбний йому бiльш точний iнтелектуальний переклад. Що ж стосується перекладу iнформацiї на iноземнi мови, то на думку Дж. Слокум вигiднiше користуватися системами машинного перекладу, якi допускають постредагування, нiж робити повнiстю „ручний” переклад.
 Інженерно-лiнгвiстичний пiдхід до проблематики машинного перекладу базується на лiнгвiстичній класифікації систем МП. Перш нiж запропонувати типологію систем, визначимо, що можливі рiзноманiтнi підвалини такої класифiкацiї. Це пояснюється багатоаспектнiстю самої проблематики.
Інженерно-лiнгвiстичний пiдхід до проблематики машинного перекладу базується на лiнгвiстичній класифікації систем МП. Перш нiж запропонувати типологію систем, визначимо, що можливі рiзноманiтнi підвалини такої класифiкацiї. Це пояснюється багатоаспектнiстю самої проблематики.
Iз лiтератури нам вiдомi такi принципи класифiкацiї.
1). Щодо участi ЕОМ у процесi перекладу, обсягу роботи, яку вона „бере на себе”, системи МП подiляються на автоматизованi та автоматичнi. Першим в англiйськiй мовi вiдповiдає термiн MAT (machine-aided translation), тобто переклад, який виконується за допомогою машини, а другим – MT (machine translation), тобто машинний переклад як такий.
В автоматизованих системах МП людина є обов’язковим учасником процесу перекладу. На частку машини в них приходиться виконання тiльки рутинних операцiй – пошук слiв i словосполучень в автоматичному словнику та вивiд їхнього перекладу на екран з можливою наступною вставкою у вихiдний текст. Навпаки, в автоматичних системах машина здійснює аналiз вхiдного тексту та синтез вихiдного, так що переклад, хоча й має неминучi лексичнi, граматичнi, стилiстичнi помилки, в цiлому є зрозумiлим користувачевi й може бути використаний у виглядi iнформацiйного документа, котрий в деякiй мiрi може замiнити оригiнал. У той же час, такi системи, як правило, мають засоби редагування машинного продукту, що особливо важливо при перекладi текстiв, котрi мають статут документiв у прямому значеннi цього слова, наприклад, технiчної документацiї, котра поставляється за кордон разом з устаткуванням, що експортується.
2). Ще однiєю характеристикою системи МП є кiлькiсть мов, що їх „розумiє” система. Вiдповiдно до даного критерiю будемо розрiзняти двомовнi та багатомовнi системи. Першi здiйснюють переклад для однiєї мовної пари. Якщо ж система охоплює бiльше однiєї мовної пари, вона є багатомовною.
У розвиток цього пункту представляється доцiльним ввести також такий пiдроздiл систем МП, як оборотнiсть (англiйський термiн – “two-way systems”) i необоротнiсть (“1-way systems”). Системи першого типу перекладають текст тiльки „в один бiк”, а системи другого типу – „в обидва боки”.
3). Важливою характеристикою систем МП є також тип документiв, на переклад яких орiєнтована система. Зокрема, iснують системи, якi працюють тiльки з заголовками документiв (наприклад, патентiв); iншi – здебiльшого з технiчними специфiкацiями тощо. Iснують також унiверсальнi системи, якi можуть на однаковому рiвнi ефективностi перекладати тексти рiзноманiтних типiв (try-anything systems – термiн Веронiки Лоусон).
Промисловi системи МП розрiзняються залежно вiд тематичних галузей, що покриваються ними. Визначимо при цьому, що в сучасних системах МП програмне забезпечення залежить тiльки вiд структури лiнгвiстичного забезпечення, але не вiд конкретного наповнення автоматичного словника, i треба розрiзняти саме словники систем, а також практичну можливiсть їхнього поширення.
4). Нарештi, широко вiдомий суто лiнгвiстичний принцип класифікації систем МП. Системи МП подiляються на:
· системи, що реалiзують прямий переклад (direct translation);
· системи, якi базуються на трансферi (transfer approach);
· системи з мовою-посередником (interlingua approach).
Оскiльки ця пiдстава класифiкацiї представляє, зрозумiло, особливий iнтерес для комп’ютерної лiнгвiстики, розглянемо її детальнiше.
Системи прямого перекладу будуються, виходячи з такого мiркування: нехай маємо двi конкретнi мови, на котрi настроюється певна система; в основному iнформацiя знаходиться в лексицi, тому достатньо правильно перекласти лексику вхiдного тексту, для чого, зрозумiло, необхiдно зняти багатозначнiсть, яка заважає цьому (в першу чергу граматичну), i привести в мiнiмально необхiдну вiдповiднiсть вхiднiй синтаксичнiй структурi вихiдну структуру, щоб лексика вихiдного тексту справдi передавала iнформацiю, закладену в текстi, що перекладається. Цi системи придiляють основну увагу лексицi, iгноруючи „глобальний” синтаксис речення i спираючись на мiнiмальний контекст. Важливо пiдкреслити, що при прямому перекладi речення i аналiзується, i синтезується не у виглядi синтаксичного утворення, а як сукупнiсть лiнiйних фрагментiв. Безумовно, в цiй лiнiйностi синтаксичнi зв’язки i залежностi враховуються, але непрямо i далеко не в повному обсязi.
Суть прямого перекладу – в гiпотезi, згiдно з якою надлишковiсть мови є такою, що правильний переклад лексики компенсує помилки в граматицi. Можна також припустити, що, чим ближче синтаксичне оформлення текстiв двох мов, тим вищою буде якiсть перекладу. А навпаки? Наскiльки достатньою є надлишковiсть? Наскiльки знань користувача з предметної галузi достатньо для того,щоб зрозумiти граматично помилковi фрагменти? На цi питання краще всього вiдповiдає оцiнка машинних перекладiв, виконаних такими системами. Зараз визначимо лише, що, як показує практика, системи прямого перекладу можуть претендувати, в першу чергу, на одержання сигнальних перекладiв, тому що якiсть вихiдного продукту в них є далекою вiд iдеалу, якщо йдеться про новий текст, котрий, ранiше не опрацьовувся системою.
Системи прямого перекладу можна удосконалювати. Їхнiй нижчий рiвень – пословний переклад; можна було б вказати i вищий, проте головне, що цей вищий рiвень iснує, розвивати безмежно такi системи неможливо, основний принцип системи в процесi вдосконалення не змiнюється: прямий переклад - це так чи iнакше автоматично вiдредагований пiдстрочник.
Не можна не бачити, що всi перетворення пiдстрочника базуються на особливостях вхiдної структури. Таким чином, якщо пiдстрочник дав помилковий переклад iз-за невiдповiдностi вхiдної та вихiдної структур, то ця помилка збережеться на всiх наступних етапах обробки.
Нехай, наприклад, необхiдно перекласти на українську мову англiйське речення I saw her walking. Прямий переклад: Я побачив її ідучи.
У розвинених системах прямого перекладу застосовуються процедури усунення багатозначностi, котрi базуються на аналiзi обмежених лiнiйних контекстiв, сегментiв. При такому аналiзi, що враховує не залежностi слiв, а тiльки їхнє лiнiйне роташування, iснує можливiсть багатозначного та по-милкового видiлення фрагментiв, що призводить до помилок у побудовi вихiдного тексту.
Як бачимо, помилковий – iз-за неврахування синтаксичної структури речень – пiдстрочник призводить до того, що, одержавши його, уже пiзно будь-що змiнювати, помилка залишається. У зв’язку з цим, грубому прямому перекладу протиставляється трансфер-пiдхiд. Його iдея: якщо при прямому перекладi лексика часто „не працює” iз-за неврахування синтаксичної ролi слiв, то необхiдно виявити синтаксичну структуру вхiдного речення, трансформувати її у структуру мови перекладу i тiльки потiм – перекладати на лексичному рiвнi, тобто пiдставляти слова в синтаксичну структуру вихiдного тексту.
Розглянемо той же приклад, використовуючи такi умовнi означення: N – iменник чи займенник; V – дiєслово; D – поширене доповнення; pres – теперiшнiй час. I saw her walking. Аналiз: I = N; saw = V; her walking = D. Трансфер: N - V - D= N - V, как N1 V1pres. Синтез: Я побачив, як вона іде.
Таким чином, переклад, виконаний системою з використанням трансферу, буде кращий, нiж переклад, виконаний системою прямого перекладу, якщо задовольняються три умови:
· вдалим був аналiз вхiдного тексту, тобто система вiрно розпiзнала синтаксичну структуру тексту;
· словник правил трансферу досить повний;
· структури вхiдного та вихiдного текстiв розрiзняються, так що перетворення є необхiдним.
Отже, тотальнiй вiдмовi вiд синтаксичного аналiзу протиставляється теж тотальний синтаксичний аналiз. При цьому ясно, що синтаксичний аналiз без урахування семантики слiв не буде повноцiнним. Приклад: The cell changed a minute later („змінилася”). The reporter changed the article later („змінив”).
Визначимо, що наведенi цi „простi” приклади не є штучними: в реальних наукових та iнформацiйних текстах ситуацiї є значно складнiшими для обробки, тому що в них використовуються термiни, семантику яких складно описати, причому вони вступають у реальних текстах у складнi синтаксичнi вiдносини одне з одним.
Як бачимо, труднощi в обох методик – спiльного порядку: необхiднiсть заздалегiдь, у словнику, тобто на рiвнi мови, завбачити поводження слiв у текстi, тобто на рiвнi мовлення. При цьому: при прямому перекладi завбачається менше, i це потребує менше iнформацiї при утвореннi словника, що спрощує цей процес, але вiдсутнiсть частини важливої iнформацiї про слова та граматику призводить до помилок; трансфер-переклад потребує бiльше iнформацiї, словник поповнювати складнiше, при аналiзi, синтезi й трансферi враховується бiльше зв’язкiв, а значить з’являються помилки, викликанi тим, що ми бiльше хочемо узнати про речення, а також тим, що можливi помилки при введення слiв у словник.
Справдi, при прямому перекладi нас не цiкавлять синтаксичнi зв’язки, точнiше, вся їх маса, а значить, помилок, що проявляються у виявi неiснуючих зв’язкiв, просто немає. Зате, з iншого боку, трансфер-пiдхiд у рядi випадкiв позбавляє вiд помилок прямого перекладу, тому що не робить прямих, “пiдрядкових” пiдстановок слiв, а значить, не робить i вiдповiдних помилок. Практика показує, що трансфер-системи, що мають, здавалося б, вищу розпiзнавальну спроможнiсть, нiж системи прямого перекладу, мають не бiльш високi показники якостi перекладу. Наприклад, система нiмецького-англiйського перекладу METAL має процент правильно перекладених речень 45% – 85%, залежно вiд того, чи новi це тексти для системи . Причина тут в тому, що притягнення синтаксичної iнформацiї саме по собi не може не дати помилок. Трансфер-переклад, таким чином, будучи гiпотетично ефективнiшим за прямий переклад, на практицi в цiлому працює не краще щодо загальної якостi вихiдного тексту, якщо тiльки не демонструвати його переваги на заздалегiдь пiдготовлених прикладах. У той же час, не слiд забувати принаймнi двi його переваги перед прямим засобом:
· деякi конструкцiї, наприклад, наведена вище – I saw her walking – принципово не пiдлягають прямому перекладу i мають опрацьовуватися з використанням правил трансферу;
· за допомогою трансферу значно легше будувати багатомовнi системи, i ця перевага є тим значнiшою, чим у системi бiльше мов i необхiдно реалiзувати переклад з кожної мови на кожну: аналiзiв i синтезiв треба стiльки, скiльки опрацьовується мов, i для кожної пари необхiдно задати правила трансферу, тодi як при прямому перекладi потрiбно будувати стiльки систем, скiльки маємо мовних пар.
Щодо систем з мовою-посередником, то однiєю з головних передумов їх побудови є бажання суттєво спростити розробку багатомовних систем, а також iстотно пiдвищити якiсть перекладу. Суть засобу полягає в тому, що, незалежно вiд мови, текст на етапi аналiзу перетворюється не в прив’язаний до цiєї мови структурний вираз, а в незалежний вiд конкретних мов опис, що передає змiст вхiдного тексту. Пiсля цього смислове подання перетворюється в текст на вихiднiй мовi. Безумовно, досвiдченi перекладачi працюють саме так: не бездумно „транслюють” вхiдний текст на вихiдну мову, а спочатку розумiють змiст тексту, що перекладається, i лише потiм працють з цим змiстом.
Звiдси витiкає ще одна гiпотеза: можливо, „проста” i „складна” системи перекладуть один i той ж текст з приблизно однаковими показниками якостi, але зроблять при цьому рiзнi помилки. Вчені вважають, що ця гiпотеза потребує перевiрки для пошуку нових, ефективніших засобiв перекладу. Одним iз таких шляхiв може виявитися розробка гiбридних систем, якi поєднують можливостi прямого перекладу та трансферу.
 Аналiзуючи системи машинного перекладу, так же як iнформацiйнi системи двох iнших „класичних” типiв – пошуку i реферування iнформацiї, необхiдно користатися певними критерiями їхньої оцiнки,тому що iнакше буде неясно, що саме ми розумiємо пiд „гарною” та „поганою” системами. Зрозумiло, оцiнювати якiсть перекладу ми можемо тiльки щодо систем автоматичного МП, тодi як якiсть автоматизованих систем логiчно оцiнювати в основному з точки зору їх зручностi.
Аналiзуючи системи машинного перекладу, так же як iнформацiйнi системи двох iнших „класичних” типiв – пошуку i реферування iнформацiї, необхiдно користатися певними критерiями їхньої оцiнки,тому що iнакше буде неясно, що саме ми розумiємо пiд „гарною” та „поганою” системами. Зрозумiло, оцiнювати якiсть перекладу ми можемо тiльки щодо систем автоматичного МП, тодi як якiсть автоматизованих систем логiчно оцiнювати в основному з точки зору їх зручностi.
Щодо лiнгвiстичних можливостей систем МП, найрозповсюдженими i широко цитованим у лiтературi є такий пiдхiд до оцiнки текстiв, котрi генеруються комп’ютером, при якому пiдраховується кiлькiсть правильно перекладених речень. Ми вважаємо, що система МП може бути визнана ефективною, якщо переклади, що генеруються нею, є зрозумiлими користувачевi й читаються їм без особливої напруги. Щодо систем, орiєнтованих на розповсюдження iнформацiї, то до якостi їх роботи пред’являються, взагалi кажучи, жорсткiші вимоги: переклад, виконаний такою системою, має бути не тiльки зрозумiлим науково-технiчному редактору або квалiфiкованому перекладачу, але й вимагати прнаймнi не бiльших витрат на редагування, нiж „ручний” переклад того ж тексту.
Вчені запропонували таку шкалу оцiнки якостi машинного перекладу:
1). Якiсть перекладу є неприйнятною. Переклад цiлком некорисний для будь-яких цiлей. Краще читати оригiнал, нiж такий „переклад”.
2). Переклад поганий, вдається вловити лише деякi фрагменти змiсту. Ледве зрозумiло, про що йдеться в текстi.
3). Якiсть перекладу низька. Можна зрозумiти лише загальний змiст тексту, але читати великi порцiї такого перекладу важко. Переклад такої якостi можна використати при формуваннi довiдково-iнформацiйного фонду, але не у виглядi iнформацiйного чи навiть сигнального документа.
4). Якiсть перекладу середня. Такий переклад може бути використаний при первинному ознайомленнi зi змiстом невеликого чи середнього за обсягом документа для визначення необхiдностi його повного перекладу, або при читаннi великого тексту – для визначення фрагментiв, якi потребують квалiфiкованого перекладу.
5). Якiсть перекладу прийнятна. Зрозумiлi тематика та змiст документа. Iз перекладу можна витягти також деякi фактичнi вiдомостi. В цiлому ж переклад читається з напругою.
6). Переклад задовiльний. Є помилковi та незрозумiлi фрагменти, але їх порiвняно небагато, загалом переклад може бути використаний як джерело iнформацiї.
7). Переклад хороший, хоч i граматично кострубатий.
8). Ще одним критерiєм оцiнки системи МП має бути комфортнiсть з точки зору кiнцевого користувача. У поняття комфортностi входить багато технiчних i лiнгвiстичних аспектiв, на якi ми будемо звертати увагу при розглядi конкретних систем.
 Системи МП доцільно використовувати:
Системи МП доцільно використовувати:
· при абсолютному незнанні іноземних мов;
· у разі необхідності одержати переклад швидко, наприклад, при перекладі веб-сторінок;
· для створення підрядкового перекладу – чернетки, що використовується для повноцінного перекладу;
· у разі пересилання документів іноземним партнерам.
 Цю систему (її більш ранні версії відомо під назвою Stylus) розроблено російською фірмою PROMT. Компанія PROMT є однією із найстаріших російських ІТ-компаній, з 1991 року успішно розвиваючи технології машинного перекладу. Система PROMT є додатком до операційних систем, Windows і може бути інтегрована в комплект програм MS Office, зокрема, у програми MS Word та MS Excel.
Цю систему (її більш ранні версії відомо під назвою Stylus) розроблено російською фірмою PROMT. Компанія PROMT є однією із найстаріших російських ІТ-компаній, з 1991 року успішно розвиваючи технології машинного перекладу. Система PROMT є додатком до операційних систем, Windows і може бути інтегрована в комплект програм MS Office, зокрема, у програми MS Word та MS Excel.
 Можливості системи МП PROMT:
Можливості системи МП PROMT:
· забезпечення перекладу документів з англійської, німецької та французької мов на російську і українську та навпаки;
· до неї можна підключати кілька десятків спеціалізованих словників, що забезпечує правильний переклад термінів, які стосуються певної галузі знань;
· динамічне відслідковування напрямку перекладу, тобто визначення мови оригіналу і перекладу;
· переклад вмісту буфера обміну, поточного параграфа, виділеного фрагмента тексту або всього тексту;
· забезпечення перекладу документів для 26 напрямів перекладу, підключення й відключення словників, доповнення та виправлення їх, складання списку зарезервованих слів, які не перекладаються;
· робота безпосередньо з програмами розпізнавання текстів, наприклад, FineReader;
· не виходячи з програми можна використати відомі способи редагування й форматування оригіналу та перекладу;
· забезпечення перевірки орфографії оригіналу і перекладу після встановлення прикладних програм для перевірки правопису (LingvoCorrector, Пропис, Орфо, Hugo).
Програма PROMT забезпечує низку додаткових можливостей, які розглянемо окремо:
1). Сумісна робота з програмою розпізнавання текстів. Якщо до комп'ютера підключено сканер і встановлено програму оптичного розпізнавання текстів, наприклад, FineReader, то її можна запустити безпосередньо з програми перекладу PROMT. Використовуючи сканер, програма FineReader забезпечить перетворення надрукованого на папері тексту в електронну форму і передасть його до програми для перекладу й редагування.
2). Сумісна робота з пакетом MS Office. Програму перекладу PROMT можна інтегрувати з MS Word і MS Excel. Це дає змогу перекладати відкриті в цих додатках документи, не виходячи з програм.
3). Переклад Веб-сторінок. До складу програми PROMT входить додаткова програма WebView, яка забезпечує підключення користувача до Web-вузлів, пошук інформації у мережі Інтернет та автоматичний переклад Веб-сторінок з англійської, німецької, французької мов на російську і навпаки. Запустити цю програму можна з панелі Інтегратора PROMT .
 Головне вікно програми PROMT складається з трьох частин: дві призначені для відображення оригіналу тексту і його перекладу, третя утворює інформаційну панель, де відображаються дані про перекладений документ і спеціальні настройки. Вікно має стандартні елементи управління вікна Windows – заголовок, рядок меню, панелі інструментів і т.д.
Головне вікно програми PROMT складається з трьох частин: дві призначені для відображення оригіналу тексту і його перекладу, третя утворює інформаційну панель, де відображаються дані про перекладений документ і спеціальні настройки. Вікно має стандартні елементи управління вікна Windows – заголовок, рядок меню, панелі інструментів і т.д.
Для швидкого запуску всіх програм, що входять до складу PROMT, призначений Інтегратор PROMT у вигляді окремої панелі робочого стола Windows. Кнопки панелі Інтегратора, а також пункти контекстного меню, яке викликається клацанням правою клавішею миші на значку Інтегратора, що є на панелі задач, дають змогу вибрати такі функції програми PROMT :
1) перекласти Clipboard (вміст буфера обміну);
2) відкрити файл;
3) відкрити WWW-вузол;
4) пошук у WWW;
5) запустити програму PROMT;
6) запустити File Translator – програму перекладу файлів у пакетному режимі;
7) запустити WebView – броузер-перекладач, що забезпечує синхронний переклад Веб-сторінок при навігації в мережі Інтернет;
8) запустити Quick Translator – програму швидкого перекладу тексту, набраного з клавіатури.
Переклад окремих слів і виділених фрагментів можна здійснити прямо в тексті, навівши на них вказівник миші. Окремі фрагменти тексту можна перекласти без попереднього запуску програми PROMT. Для цього досить, знаходячись в будь-якому текстовому редакторі, наприклад, Notepad або Microsoft Word, скопіювати виділений фрагмент у буфер обміну і викликати функцію Переклад Clipboard Інтегратора PROMT.
Переклад документа за допомогою програми PROMT передбачає кілька етапів:
1). Введення документа, який необхідно перекласти. Документ може бути завантажений з файла. Для цього слід виконати стандартну операцію відкриття файла. Текст для перекладу може також бути набраний на клавіатурі в редакторі програми. Для цього треба спочатку створити новий документ за допомогою відповідної команди. Для перекладу введеного з клавіатури тексту без виклику основного вікна програми PROMT можна також скористатися функцією Quick Translator Інтегратора PROMT. У вікні програми Quick Translator, крім перекладу, можна виконати також інші дії з оригіналом і перекладеним текстом: скопіювати переклад у буфер обміну, змінити напрямок перекладу, підключити додаткові словники тощо.
2). Уточнення параметрів перекладу. Після того, як підготовлено оригінал тексту, що підлягає перекладу, слід визначити напрямок перекладу, тобто з якої мови на яку мову буде здійснюватися переклад, а також уточнити формат тексту оригіналу (формат файла, наприклад MS Word файл, текст RTF тощо).
3). Підготовка тексту до перекладу. Вибраний документ відображається в області тексту оригіналу. Перед початком перекладу доцільно перевірити орфографію, оскільки неправильно написані слова будуть сприйматися програмою як невідомі і залишаться без перекладу. У разі необхідності текст можна зберегти для подальшої роботи як документ PROMT. У документі можуть бути слова і словосполучення, які не повинні перекладатися, наприклад, прізвища, назви програмних продуктів (Windows 98, MS Word 2000 тощо). Іноді застосовують транслітерацію – запис із використанням іншого алфавіту, що відповідає написанню або вимові мовою оригіналу (наприклад, прізвище Brown бажано перекласти не як Коричневий, а Браун).
Інколи доводиться відмовлятися від перекладу цілих абзаців, наприклад, текстів програм на алгоритмічних мовах. Щоб відмовитися від перекладу окремих слів, їх треба зарезервувати, тобто встановити на цьому слові курсор, а потім клацнути мишею на відповідній кнопці панелі інструментів або вибрати пункт Зарезервировать... у контекстному меню чи меню Перевод.
Можна зарезервувати фрагмент тексту, заздалегідь виділивши його або цілий абзац. У тексті всі зарезервовані слова й абзаци, що мають залишитися без перекладу, виділяють зеленим кольором. Якість перекладу визначається повнотою словників, які використовуються, з урахуванням граматичних правил. Для кожного документа можна задати набір словників, які переглядаються у певному порядку до першого виявлення слова для перекладу. Програмою PROMT для перекладу передбачено три типи словників:
· генеральний словник (містить загальновживану лексику і побутове значення слів). Він використовується завжди, причому останнім з усіх словників. Зміна цього словника неможлива;
· спеціалізовані словники (містять терміни з різних областей). Редагувати ці словники не можна, але їх можна підключати й відключати під час перекладу. Базове постачання програми не містить додаткових словників і їх необхідно встановлювати окремо;
· словник користувача (створюється користувачем) До нього додаються слова, яких немає в інших словниках, а також уточнені переклади тих або інших слів. Словник користувача можна редагувати.
Список словників, що використовуються під час перекладу, відображається у вікні інформаційної панелі. Підключення словників здійснюється за допомогою відповідної команди програми PROMT.
5). Переклад документа. Переклад документа починається після вибору користувачем відповідної команди з меню Перевод. Перекладений документ заноситься в область перекладу. Невідомі слова виділяються червоним кольором, а зарезервовані – зеленим. Список невідомих і зарезервованих слів відображається на інформаційній панелі у відповідних вкладках. У разі необхідності невідомі слова можна занести в словник користувача. Початковий текст і переклад можна редагувати, форматувати та перекладати повторно.
6). Збереження результатів. Після завершення робіт із текстами, оригінал і переклад можна зберегти в одному з форматів, що підтримуються програмою, використовуючи стандартні команди збереження файла.
PROMT – програма перекладу текстів для роботи на домашньому комп’ютері або в невеликому офісі. Швидко перекладає тексти, електронну пошту, PDF-документи і тексти з графічних файлів. Має простій і зручний інтерфейс. Не вимоглива до ресурсів комп'ютера. Програма зручна у користуванні та має високу якість перекладу. Підходить для роботи та навчання. PROMT орієнтований на приватного користувача та дозволяє перекладати не лише з англійського а й з італійського, французького, німецького.
Успішно розвивається сервіс on-line перекладу. Наприклад, PROMT Internet Premium 7.0 дозволяє швидко і точно переводити on-line веб-сторінки зарубіжного сайту із збереженням форматування, а також перекладати запити з російської мови на вибраний іноземний для передачі пошуковим серверам в Інтернеті. Зручність і легкість установки і використання за рахунок інтеграції меню програми в панель команд MS Internet Explorer. У комплект постачання PROMT Internet Premium 7.0 входять додаткові 19 словників, серед тематик яких спорт, кулінарія, кіно, автомобільний і подорожі. Точність машинного перекладу можливо підвищити за допомогою підключення інших спеціалізованих словників (мал. 2.28).
Мал. 2.28.
Основні можливості програми PROMT Internet Premium 7.0:
- переклад документів основних форматів: DOC, RTF, HTML, TXT;
- збереження форматування при перекладі. Збереження результату перекладу у файлах формату: RTF і TXT;
- переклад PDF-документів безпосередньо в Adobe Acrobat 4.х/5.х і Adobe Acrobat Reader 4.х/5.х;
- вбудовування функцій перекладу у всі основні додатки Microsoft Office 2000/XP (Word, Excel, PowerPoint, FrontPage) і Microsoft Office System 2003;
- переклад електронної пошти. Автоматичний переклад електронної пошти в Microsoft Outlook.
Визначною подією 2009 року стало вихід нової версії системи МП PROMT 8.5, яка підтримує китайську мову.
 Pragma – це багатомовна програма машинного перекладу для перекладу текстових документів з однієї мови на іншу. Програма підтримує сім мов: англійська, російська, українська, німецька, латиська, польська і французька.
Pragma – це багатомовна програма машинного перекладу для перекладу текстових документів з однієї мови на іншу. Програма підтримує сім мов: англійська, російська, українська, німецька, латиська, польська і французька.
Pragma виконує переклад безпосередньо у вікні активного застосування або в окремому вікні швидкого перекладу. За допомогою програми можна перекладати текст, який представлено у вигляді документів MS Word, Інтернет сторінок, поштових повідомлень, довідок, а також зміст різних текстових вікон. За рахунок автоматизації багатьох функцій Pragma дуже проста у використанні. На відміну від інших програм машинного перекладу, в проекті Pragma використовується багатомовна технологія перекладу, в якій для вибраної кількості мов підтримуються всі можливі напрями перекладу. Наприклад, для трьох мов – англійської, російської і української існує 6 напрямів перекладу: англо-російський, російсько-англійський, англо-український, україно-англійський, російсько-український, україно-російський. У назві Pragma 5.x останнє число указує на кількість включених мов.
Так, Pragma 5.2 – працює з будь-якими двома мовами, Pragma 5.3 – з трьома і так далі. Pragma 5.7 включає повний набір всіх доступних на даний момент мов.
Окрім основних перекладних словників, є також словники спеціальних термінів з 50-ти різних тематик. У ці словники включені досить рідкісні і специфічні терміни. Якщо передбачається переклад спеціалізованих документів, то підключення цих словників може підвищити якість перекладу.
Наявність словників спецтермінів відображається в назві програми у вигляді плюса. Pragma 5.x+ або Pragma 5.x Plus.
На відміну від попередніх версій, Pragma 5.x не вбудовується в застосування, а працює як системна утиліта і дозволяє перекладати „з лету" в активному застосуванні. Запуск на переклад у всіх застосуваннях виконується через значок у системній панелі.
Pragma 5.x підтримує нові мови – польську та французьку. Кількість можливих напрямів перекладу складає 42. Трохи змінено інтерфейс програми. Зовнішній вигляд став більш „привабливим”.
Програма підтримує найостанніші розробки Корпорації Microsoft – Windows Vista, Internet Explorer 7, Office 2007. Змінилася процедура активації програми. Як і раніше, є on-line реєстрація через мережу Інтернет, а також – off-line локально. Відповідний режим вибирається автоматично.
Кожна мова локалізована в окремому модулі. Всього є 7 мовних модулів: англійський, німецький, французький, латиський, польський, російський і український.
Оскільки Pragma побудована за модульним принципом, то також є можливість вибору необхідних мовних модулів і комбінування з них необхідних напрямів перекладу.
Необхідно враховувати ще одну особливість організації системи. Російська мова є основною мовою, що пов’язує, майже для всіх напрямів перекладу. Це означає, що при перекладі, скажімо, з латиської мови на українську обов’язково необхідна наявність російської мови.
Виняток становить польська мова. Через граматичну близькість польської і української мов, основною мовою, що пов’язує, для польської є українська мова. Тому при виборі польського модуля наявність українського обов’язкова.
При оновленні програма автоматично враховує ці особливості.
Разом з системними словниками, що поставляються, користувач має можливість поповнювати і редагувати свої особисті словники. Словники користувача мають найвищий пріоритет при перекладі, це дозволяє корегувати перекладні значення слів і виразів.
 Відразу після установки програми Pragma 5.x на системній панелі, поряд з годинником з’являється її значок. Цей значок є точкою входу в програму Pragma 5.x. Натиснення лівої клавіші мишки по значку активізує процес перекладу в активному вікні.
Відразу після установки програми Pragma 5.x на системній панелі, поряд з годинником з’являється її значок. Цей значок є точкою входу в програму Pragma 5.x. Натиснення лівої клавіші мишки по значку активізує процес перекладу в активному вікні.
Pragma 5.x взаємодіє з різними застосуваннями Windows через один і той же значок на системній панелі.
При натисканні правої кнопки мишки на значок Pragma з’являється меню. В цьому меню відображаються всі основні функції програми. Воно містить такі пункти:
· Швидкий переклад – відкриття вікна для швидкого перекладу. У цьому вікні відображується переклад тексту, який міститься у буфері обміну (Clipboard).
· Коректор словника – запуск утиліти роботи зі словником користувача. Дозволяє корегувати, додавати і видаляти словарні статті.
· Активація – перехід до активації програми. Даний пункт меню присутній тільки в тому випадку, якщо програма ще не активована.
· Настройки – перегляд і настройки параметрів роботи програми.
· Перевірка – запуск модуля тестування програмного комплексу на працездатність всіх функцій.
· Оновлення – завантаження оновлень програмних модулів, необхідних словників та їх установка.
· Довідка – довідкові матеріали по роботі з програмою.
· Про програму – загальні відомості про версію програми і встановлені словники.
· Вихід – завершення роботи Pragma.
Натиснення мишки по значку Pragma активізує переклад тексту активного застосування. Це може бути документ, Веб-сторінка, повідомлення електронної пошти або будь-які інші текстові дані.
Переклад в активному застосуванні працює в MS Word, Internet Explorer, Outlook, Outlook Express, WordPad, Блокнот (Notepad) і деяких інших.
Якщо переклад неможливий у вибраному застосуванні, буде видано відповідне повідомлення. В цьому випадку можна буде спробувати перекласти в режимі швидкого перекладу.
Переклад здійснюється для виділеного фрагмента тексту. Якщо виділення немає, то перекладається весь документ від початку до кінця.
Часто система МП не може зробити коректний лінгвістичний аналіз тексту, вдатись до перекладацьких трансформацій і адекватно зробити переклад. Натомість система робить значні успіхи в дослівному перекладі, коли немає необхідності образно переосмислювати текст.
Отже, можна помітити деякі розбіжності в зразках перекладів з використанням систем МП і перекладом професійного перекладача, і таким чином оцінити недоліки систем МП.
 Існує велика кількість корисних проектів з теми „On-line переклад”, які дозволяють безкоштовно грамотно перекладати слова, словосполучення, речення і навіть невеликі тексти. Звичайно, найсучасніша програма-перекладач не може перевести текст краще, ніж професійний лінгвіст, але, коли потрібно одержати швидкий і миттєвий результат, то on-line перекладач може стати в нагоді.
Існує велика кількість корисних проектів з теми „On-line переклад”, які дозволяють безкоштовно грамотно перекладати слова, словосполучення, речення і навіть невеликі тексти. Звичайно, найсучасніша програма-перекладач не може перевести текст краще, ніж професійний лінгвіст, але, коли потрібно одержати швидкий і миттєвий результат, то on-line перекладач може стати в нагоді.
До переваг on-line перекладача можна віднести: достатню якість перекладу окремих слів та речень, доступність та простоту інтерфейса, який зрозумілий будь-якому користувачу і до того ж безкоштовний. On-line перекладач містить великий словник, який складається не лише з окремих слів, але і часто вживаних словосполучень у кожній мові, що дозволяє приблизити текст, що перекладається, до літературного перекладу без додаткового редагування, а можливість вибору тематики тексту дозволяє грамотно і точно перекласти наукові або технічні терміни.
Компанії-розробники систем МП постійно розширяють функціональні можливості сервісу, збільшують бази синонімів, працюють над більш коректною обробкою словоформ і виразів. Це робиться для того, щоб користувач мав можливість належно оцінити їх перекладач.
На фоні великої кількості on-line перекладачів, особливо виділяється компанія Google і її сервіс on-line перекладач – „Google Переводчик”.
Нагадаємо, що Google створили у 1989 році Ларрі Пейдж та Сергsй Брінм – аспіранти університету Стен форд. На сьогодні Google є однією із великих Інтернет-компаній, що відома своєю пошуковою системою.
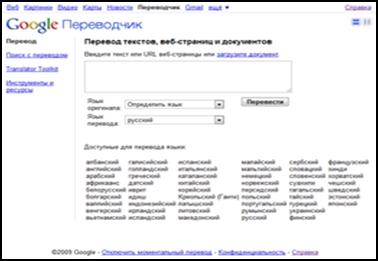
„Google Переводчик”  – це безкоштовна інтерактивна служба on-line перекладів, яка миттєво перекладає текст і веб-сторінки. Перекладач підтримує на більш ніж 52 мови. Сервіс містить також переклад всієї веб-сторінки і навіть одночасний пошук текстових даних з перекладом на іншу мову (див. мал. 2.29).
– це безкоштовна інтерактивна служба on-line перекладів, яка миттєво перекладає текст і веб-сторінки. Перекладач підтримує на більш ніж 52 мови. Сервіс містить також переклад всієї веб-сторінки і навіть одночасний пошук текстових даних з перекладом на іншу мову (див. мал. 2.29).

Мал. 2.29.
„Google Переводчик”, як і інші сервіси автоматизованого перекладу, має свої обмеження. Він може допомогти користувачу зрозуміти загальний зміст перекладу на іноземній мові, але не дає точного перекладу. Постійно ведеться робота над якістю перекладу, розробляються переклади на інші мови.
 Компанія Google оголосила про введення нового сервісу. У більшості системи МП мають певні обмеження в кількості слів, що вводяться для перекладу, до 1 тис. На практиці сервіс Google дозволяє без проблем перевести декілька сторінок тексту (10 тис. знаків). Крім того, нова система допускає введення пошукових запитів на рідній мові і здійснення пошуків інформації з іноземних сайтів. Так, якщо користувач шукає інформацію про комп’ютерне піратство на англомовних ресурсах, в рядку пошуку запит можна ввести на російській мові. Результати будуть виведені у двох колонках: англомовні сайти по запиту "computer piracy" та їх російськомовний переклад (http://news.liga.net/news/N0723270.html).
Компанія Google оголосила про введення нового сервісу. У більшості системи МП мають певні обмеження в кількості слів, що вводяться для перекладу, до 1 тис. На практиці сервіс Google дозволяє без проблем перевести декілька сторінок тексту (10 тис. знаків). Крім того, нова система допускає введення пошукових запитів на рідній мові і здійснення пошуків інформації з іноземних сайтів. Так, якщо користувач шукає інформацію про комп’ютерне піратство на англомовних ресурсах, в рядку пошуку запит можна ввести на російській мові. Результати будуть виведені у двох колонках: англомовні сайти по запиту "computer piracy" та їх російськомовний переклад (http://news.liga.net/news/N0723270.html).
На відміну від інших сервісів перекладу, таких як Babel Fish та AOL, які використовують технологію SYSTRAN, Google використовує власне програмне забезпечення. Використовується так званий алгоритм статистичного машинного перекладу, що самонавчається.
Компанія Google почала розробку універсального перекладача нового типу. Ідея нового проекту у створенні програмного забезпечення, яке дозволить користувачам, що спілкуються на різних мовах, розмовляти один з одним в режимі реального часу. Отже, програмне забезпечення повинно розпізнавати мову, перекладати одержаний текст і видавати його вже на іншій мові.
Френк Оуч (Frank Och), керівник відділу сервісу з перекладу (Google Translate) вважає, що компанія вже знаходиться на порозі створення універсального голосового перекладача. Оскільки технологія розпізнавання голосу в Google вже є. Демонстрація її можливостей була проведена за допомогою комунікатора Nexus One, на який було встановлено відповідне програмне забезпечення (http://expert.com.ua/44766.html).
За словами Франца Оуча, за останні декілька років в галузі машинного перекладу і розпізнавання мови спостерігаються великі зрушення. Найскладнішим завданням залишається саме аналіз мови, оскільки в кожної людини різні голоси та вимови (http://www.gnews.ua/cat/material/id/36514.html).
Очікується, що нова технологія буде широко застосовуватися в мобільних телефонах. Франц Оуч вважає, що телефон з функцією синхронного перекладу буде створений протягом декількох років. Представники Google вважають, що можливо натренувати програму перекладу на свій голос. Для цього вона буде порівнювати слова, що вимовляються, із записами попередніх голосових пошукових запитів. Тобто, програма зможе розпізнавати акцент, діалект і особливості голосу користувача, що забезпечить її чітке функціонування (http://korrespondent.net/tech/technews/1045282).
При роботі з системами МП слід пам’ятати, що оскільки ці програми поки ще далекі від ідеалу, автоматичний програмний переклад дає змогу зрозуміти, про що йдеться в оригіналі, але перекладений текст потребує редагування.

Питання для самоперевірки
1). Що таке програмне забезпечення комп’ютера?
2). Що таке системне програмне забезпечення комп’ютера?
3). Які існують види системного програмного забезпечення комп’ютера?
4). Що таке прикладне програмне забезпечення комп’ютера?
5). Які програми можна віднести до прикладного програмного забезпечення?
6). Які типи вікон ви знаєте?
7). Які стани може приймати вікно?
8). Як представляються дані в комп’ютері?
9). Які основні характеристики операційної системи Windows ХР?
10). Які елементи операційної системи Windows ХР присутні на робочому столі?
11). Які дії над об’єктами визначені в системній оболонці Windows ХР?
12). Як знайти об’єкт та перемістити його по файловій структурі?
13). Як відкрити документ?
14). Як створити папку і файл та присвоїти їм ім’я?
15). Як здійснити копіювання, переміщення, вилучення і перейменування об’єктів?
16). Яка особливість вилучення файлів?
17). Що таке ярлик і як його створити?
18). Як переглянути властивості об’єктів?
19). Що таке атрибути файла?
20). Як встановити атрибути файлів?
21). Що таке шлях до файла?
22). Яке призначення програми Мой компьютер?
23). Які команди працюють з буфером обміну даних Clipboard?
24). Скільки об’єктів можна записати в буфер обміну даних?
25). Які програми є стандартними додатками оболонки Windows XP?
26). Які прикладні програми входять у пакет MS Office 2003?
27). Що таке електронний словник?
28). Які ви знаєте електронні словники?
29). Які основні характеристики електронних словників?
30). До яких електронних словників є доступ в мережі Інтернет?
31). Які основні операції програми ABBYY FineReader?
32). В чому полягає процес сегментації зображень?
33). В чому полягає процес розпізнавання документа?
34). В які програми можна передати текст після розпізнавання в ABBYY FineReader?
35). Як виконується перевірка правопису в програмі ABBYY FineReader?
36). Які існують кнопки управління процесом редагування?
37). В яких випадках доцільно використовувати програми автоматизованого перекладу?
38). Які типи програм автоматизованого перекладу існують? В чому полягає різниця між ними?
39). Які можливості забезпечує системи МП PROMT?
40). З яких етапів складається процес перекладу документа в програмі PROMT?
41). Які можливості забезпечує системи МП Pragma?
42). Які можливості забезпечує система МП „Google Переводчик”?

Практичні завдання
Завдання 1.
Письмово перерахувати та проаналізувати помилки системи МП PROMT з підключенням спеціального словника і без підключення останнього.
Оригінал:
Nokia 9000i Communicator now supports short messages with up to 2 280 characters, the current standard being 160 characters. With the Text Web service based on Smart Messaging, the end-user is able to obtain information in a simple text format without graphics or logos from the Internet by using the short message service. Text Web information can include flight schedules, weather or traffic reports, or the stock news.
Переклад без підключення спеціалізованого словника:
Nokia 9000i комунікатор тепер підтримує короткі повідомлення з до 2280 характерів (знаків), поточного стандарту, що є 160 характерами (знаками). З обслуговуванням (службою) Тканини (мережі) Тексту, заснованим на Шикарному (сильному) Messaging, кінцевий користувач здатний отримати інформацію в простому форматі тексту без графіки або емблем від Internet, використовуючи коротке обслуговування(службу) повідомлення. Інформація Тканини (мережі) Тексту може включати списки (графіки) рейса (польоту), погоду або повідомлення руху, або новини запасу (акції).
Переклад з підключеним словником “Телекомунікації і зв'язок”:
Nokia 9000i Комунікатор тепер підтримує короткі повідомлення з до 2280 символів, поточного стандарту, що є 160 символами. З Текстовим обслуговуванням Мережі, заснованим на Smart Messaging, кінцевий користувач здатен отримати інформацію в простому текстовому форматі без графіки або емблем від Internet, використовуючи систему передачі коротких повідомлень. Текстова інформація Мережі може включати список рейса (польоту), погоду або повідомлення трафіку, або новини фондового ринку.
Завдання 2.
1. Відсканувати та розпізнати текст, який запропонує викладач, за допомогою програми ABBYY FineReader.
2. Перекласти цей тексту допомогою систем МП Pragma та „Google Переводчик”.
3. Відредагуйте перекладені тексти та письмово проаналізуйте та опишіть помилки систем Pragma та „Google Переводчик”.
Завдання 3.
1. Проаналізуйте недоліки машинного перекладу наведеного уривку з використанням системи МП PROMT. Перерахуйте помилки електронного перекладача.
Переклад з використанням системи МП PROMT:
Electronic commerce over the Internet is growing at an almost exponential rate. An April 1998 report of the United States Department of Commerce, entitled The Emerging Digital Economy describes the almost mind-boggling growth of electronic commerce, and of the Internet itself. Some of the more fantastic facts included in the report are:
By the end of 1997 more than 100 million people were using the Internet and some experts expect that 1 billion people will be connected to the Internet by 2005. Traffic on the Internet is doubling every 100 days.
By 2002, Internet commerce between businesses will likely surpass $ 300 billion. The number of names registered in the domain name system grew from 26,000 in July of 1993 to 1.3 million in July of 1997.
Переклад на російську мову:
Электронная торговля по Интернету возрастает в почти показательную функцию (норма) (разряд). Апрель 1998 сообщение Отдела Соединенных Штатов Торговли, имея право Появляющейся Цифровой Экономике (экономия), описывает почти ошеломляющий рост электронной торговли и Интернета непосредственно. Некоторые из более фантастических фактов, включенных в сообщение:
К концу 1997 больше чем 100 миллионов людей использовали Интернет и некоторые эксперты ожидают, что 1 миллиард людей будет связан с Интернетом 2005. Движение в Интернете удваивается каждые 100 дней. 2002, торговля Интернета между бизнесами вероятно превзойдет 300 миллиардов. Номер (число) названий (имена), зарегистрированных в системе названия (имя) области рос от 26000 в июле от 1993 до 1.3 миллиона в июле 1997.
2. Звіт щодо виконаної практичної роботи №2здайте викладачу.

Література для самонавчання
1. Википедия – свободная энциклопедия [Електронний ресурс]. – Режим доступу: http://en.wikipedia.org
2. Дибкова Л.М. Інформатика та комп’ютерна техніка. – К., «Академвидав», 2003. – 320 с.
3. Комиссаров В.Н. Вопросы истории перевода. – М.: МО, 1989. – 296 c.
4. Макарова М.В., Карнаухова Г.В., Запара С.В. Інформатика та комп’ютерна техніка: Навч. посіб. / За заг. ред. к.е.н., доц. М.В. Макарової. – Cуми: ВТД „Університетська книга”, 2003. – 642 с.
5. Мирам. Г.Э. Переводные картинки. – К.:, Эльга, 2001. – 235 c.
6. Мірам Г.Е. та ін. Основи перекладу. Курс лекцій з теорії та практики перекладу для факультетів та інститутів міжнародних відносин.– К.: Эльга, 2002. – 432 c.
7. Ревзин И И., Розенцвейг В.Ю. Основы общего и машинного перевода.– М.: ВШ, 1964. – 324 c.
8. Pragma 5.x – Многоязычная система машинного перевода [Електронний ресурс]. – Режим доступу: www.pragma5.com
9. Translator and on-line translation from Trident Software [Електронний ресурс]. – Режим доступу: http://www.trident.com.uа
10. Google разрабатывает переводчик для разговоров онлайн [Електронний ресурс]. – Режим доступу: http://expert.com.ua/44766.html
Тема 3.
БЕЗПЕКА ДАНИХ У КОМП’ЮТЕРНОМУ СЕРЕДОВИЩІ
 3.1. Система захисту даних.
3.1. Система захисту даних.
3.2. Захист даних у персональних комп’ютерах, архіватори.
3.3. Комп’ютерні віруси, ознаки зараження персональних комп’ютерів, способи уникнення зараження.
3.4. Антивірусні програми та їх характеристика (Aidstest, Doctor Web, Scan, Norton Anti Virus, Anti Vral Toolkit Pro).
3.1. Система захисту даних
 Інформаційна безпека (англ. Information Security) – стан інформації, в якому забезпечується збереження визначених політикою безпеки властивостей інформації.
Інформаційна безпека (англ. Information Security) – стан інформації, в якому забезпечується збереження визначених політикою безпеки властивостей інформації.
Інформаційна безпека – стан захищеності життєво важливих інтересів людини, суспільства і держави, при якому запобігається нанесення шкоди через: неповноту, невчасність та невірогідність інформації, що використовується; негативний інформаційний вплив; негативні наслідки застосування інформаційних технологій; несанкціоноване розповсюдження, використання і порушення цілісності, конфіденційності та доступності інформації.
 Захист даних (англ. Data protection ) – сукупність методів і засобів, що забезпечують цілісність, конфіденційність і доступність даних за умов впливу на них загроз природного або штучного характеру, реалізація яких може призвести до завдання шкоди їх власникам і користувачам [19].
Захист даних (англ. Data protection ) – сукупність методів і засобів, що забезпечують цілісність, конфіденційність і доступність даних за умов впливу на них загроз природного або штучного характеру, реалізація яких може призвести до завдання шкоди їх власникам і користувачам [19].
Захистити дані – це значить:
· забезпечити фізичну цілісність даних, тобто не допустити спотворень або знищення їх елементів;
· не допустити підміни (модифікації) даних при збереженні їх цілісності;
· не допустити несанкціонованого отримання даних особами або процесами, що не мають на це відповідних повноважень;
· бути упевненим у тому, що інформації ресурси використовуватимуться тільки відповідно до умов, що встановлені законодавством або сторонами, що заключають відповідну угоду.
До основних характеристик захисту даних можна віднести:
- конфіденційність – захист від несанкціонованого ознайомлення з даними;
- цілісність – захист даних від несанкціонованої модифікації;
- доступність – захист (забезпечення) доступу до (можливості використання) відповідних даних. Доступність забезпечується як підтриманням систем у робочому стані, так і завдяки способам, які дозволяють швидко відновити втрачені чи пошкоджені дані.
 На сьогодні існує достатньо багато способів несанкціонованого доступу до даних:
На сьогодні існує достатньо багато способів несанкціонованого доступу до даних:
· перегляд;
· копіювання та підміна даних;
· введення помилкових програм і повідомлень у результаті підключення до каналів зв’язку;
· читання залишків даних на магнітних носіях інформації;
· прийом сигналів електромагнітного випромінювання і хвильового характеру;
· використовування спеціальних програмних і апаратних „заглушок” тощо.
Дослідження практики функціонування систем обробки даних і комп’ютерних мереж показали, що існує достатньо багато можливих шляхів несанкціонованого доступу до даних у системах та мережах:
· перехоплення електронних випромінювань;
· примусове електромагнітне опромінювання (підсвічування) ліній зв'язку;
· застосування „підслуховуючих” пристроїв;
· дистанційне фотографування;
· перехоплення акустичних хвильових випромінювань;
· читання даних із масивів інших користувачів;
· копіювання даних з подоланням заходів захисту їх носіїв;
· модифікація програмного забезпечення шляхом виключення або додавання нових функцій;
· використовування недоліків операційних систем і прикладних програмних засобів;
· незаконне підключення до апаратури та ліній зв'язку, зокрема як активний ретранслятор;
· зловмисний вихід з ладу механізмів захисту;
· маскування під зареєстрованого користувача та привласнення собі його повноважень;
· введення нових користувачів;
· упровадження комп’ютерних вірусів.
 Система захисту даних – це сукупність організаційних, адміністративних і технологічних заходів, програмно технічних засобів, правових і морально-етичних норм, направлених на протидію загрозам порушників з метою зведення до мінімуму можливого збитку користувачам власникам системи.
Система захисту даних – це сукупність організаційних, адміністративних і технологічних заходів, програмно технічних засобів, правових і морально-етичних норм, направлених на протидію загрозам порушників з метою зведення до мінімуму можливого збитку користувачам власникам системи.
Враховуючи важливість, масштабність і складність рішення проблеми збереження і безпеки даних, можна розробляти її організацію в декілька етапів:
· аналіз можливих загроз;
· розробка системи захисту;
· реалізація системи захисту;
· супровід системи захисту.
Етап розробки системи захисту даних передбачає використання різних заходів організаційно-адміністративного, технічного, програмно-апаратного, технологічного, правового, морально-етичного характеру тощо.
Організаційно-адміністративні засоби захисту зводяться до регламентації доступу до інформаційних і комп’ютерних ресурсів, функціональних процесів систем обробки даних, до регламентації діяльності персоналу тощо. Їх мета є найбільшою мірою утруднити або виключити можливість реалізації загроз безпеки.
Найтиповіші організаційно-адміністративні засоби захисту:
· створення контрольно-пропускного режиму на території, де розташовуються засоби обробки даних;
· виготовлення і видача спеціальних пропусків;
· заходи щодо підбору персоналу, пов'язаного з обробкою даних;
· допуск до обробки і передачі конфіденційних даних тільки перевірених посадовців;
· зберігання магнітних та інших носіїв інформації, що представляють певну таємницю, а також реєстраційних журналів у сейфах, не доступних для сторонніх осіб;
· організація захисту від установки прослуховуючої апаратури в приміщеннях, пов'язаних з обробкою даних;
· організація обліку використання і знищення документів (носіїв) з конфіденційною інформацією;
· розробка посадових інструкцій і правил по роботі з комп'ютерними засобами й інформаційними масивами;
· розмежування доступу до інформаційних і обчислювальних ресурсів посадовців відповідно до їх функціональних обов'язків.
Технічні засоби захиступокликані створити деяке фізично замкнуте середовище навколо об’єкта і елементів захисту. В цьому випадку можуть використовуватися такі заходи:
· установка засобів фізичної перешкоди захисного контуру приміщень, де ведеться обробка даних (кодові замки; охоронна сигналізація – звукова, світлова, візуальна без запису із записом на відеоплівку);
· обмеження електромагнітного випромінювання шляхом екранування приміщень, де відбувається обробка даних, листами з металу або спеціальної пластмаси;
· здійснення електроживлення устаткування, що відпрацьовує цінну інформацію, від автономного джерела живлення або від загальної електромережі через спеціальні мережні фільтри;
· застосування, щоб уникнути несанкціонованого дистанційного знімання даних, рідкокристалічних або плазмових дисплеїв, струменевих або лазерних принтерів відповідно з низьким електромагнітним і акустичним випромінюванням;
· використання автономних засобів захисту апаратури у вигляді кожухів, кришок, дверей з установкою засобів контролю розкриття апаратури.
Програмні засоби і методи захисту активніше і ширше за інших застосовуються для захисту даних у персональних комп’ютерах і комп’ютерних мережах, реалізовуючи такі функції захисту, як розмежування і контроль доступу до ресурсів; реєстрація і аналіз процесів, що протікають, подій, користувачів; запобігання можливим руйнівним діям на ресурси; криптографічний захист даних; ідентифікація і аутентифікація користувачів і процесів тощо.
На сьогодні найпоширенішими в системах обробки даних є спеціальні пакети програм або окремі програми, що включаються до складу програмного забезпечення, зокрема антивірусні програми з метою реалізації захисту даних від комп’ютерних вірусів.
Технологічні засоби захисту даних – це комплекс заходів, органічно вбудованих в технологічні процеси перетворення даних. Серед них:
· створення архівних копій носіїв інформації;
· ручне або автоматичне збереження оброблюваних файлів у зовнішній пам’яті комп'ютера;
· реєстрація користувачів комп’ютерних засобів у журналах;
· автоматична реєстрація доступу користувачів до тих або інших ресурсів;
· розробка спеціальних інструкцій з виконання всіх технологічних процедур.
До правових і морально-етичних заходів і засобів захисту відносять чинні в країні закони, нормативні акти, що регламентують правила поводження з інформацією і відповідальність за їх порушення; норми поведінки, дотримання яких сприяє захисту даних. Прикладом чинних законодавчих актів є Закон України „Про захист інформації в інформаційно-телекомунікаційних системах” (80/94-ВР ) та Постанова Кабінету Міністрів України від 29 березня 2006 р. №373 „Про затвердження Правил забезпечення захисту інформації в інформаційних, телекомунікаційних та інформаційно-телекомунікаційних системах”.
3.2. Захист даних у персональних комп’ютерах
 Збереження даних на магнітних носіях – важлива функція персональних комп’ютерів. Один із недоліків магнітних носіїв інформації є те, що вони не забезпечують абсолютну надійність збереження даних. Дані можуть бути зруйновані частково або повністю внаслідок фізичного псування носіїв інформації, дії зовнішніх магнітних полів, старіння магнітного покриття та інші. Іноді дані знищується випадково.
Збереження даних на магнітних носіях – важлива функція персональних комп’ютерів. Один із недоліків магнітних носіїв інформації є те, що вони не забезпечують абсолютну надійність збереження даних. Дані можуть бути зруйновані частково або повністю внаслідок фізичного псування носіїв інформації, дії зовнішніх магнітних полів, старіння магнітного покриття та інші. Іноді дані знищується випадково.
Ці обставини вимагають від користувача персонального комп’ютера мати на магнітних носіях інформації (дискетах, флешах, магнітних дисках тощо) архівні копії документів. При цьому їх необхідно перевіряти та поновлювати не менше ніж один раз на півроку.
Якщо весь обсяг даних розміщується на кількох носіях, то архівні копії можна зберігати в початковому вигляді. Для створення копій таких документів використовують стандартні засоби операційних оболонок.
Але за великих обсягів даних зберігання архівів у початковому вигляді дуже не вигідно. Річ у тому, що при зберіганні даних у початковому вигляді не ефективно використовується поверхня носія. Доцільно вихідні дані попередньо стиснути (упакувати), а потім уже створювати її копії. Такий процес створення архівних копій називають архівацією. Під час архівації досягається економія дискового простору від 20% до 90 %, що дозволяє на одному і тому самому носії інформації зберігати значно більший її обсяг.
 Для архівації файлів використовують спеціальні програми, які називають архіваторами.
Для архівації файлів використовують спеціальні програми, які називають архіваторами.
Перші архіватори з’явилися у 1985 р. Вони можуть об’єднувати в один архівний файл цілі групи файлів, включаючи і каталоги.
Можливості сучасних архіваторів широкі та різноманітні. Але можна виділити функції, які є для них загальними. До них відносяться: додавання файлів в архів, поновлення архіву, перегляд файлів в архіві, знищення файлів в архіві, захист файлів від несанкціонованого доступу, вилучення файлів із архіву, перевірка цілісності архіву та інші.
Архівний файл може використовуватися тільки після того, як він буде відновлений у початковому вигляді, тобто розархівований. Розархівацію виконують або ті самі архіватори, або окремі програми, які називають розархіваторами.
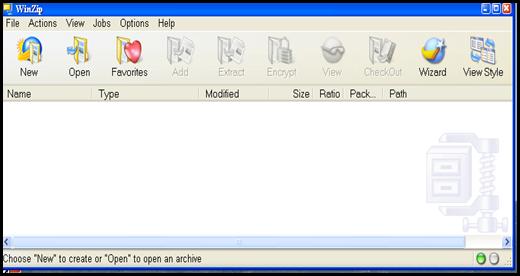
На сучасних персональних комп’ютерах найчастіше використовують для архівації даних такі програми як WinZipта WinRAR.
 Вікно програми WinZip представлено на мал. 3.1. Описана версія цієї програми WinZip11.2. Ця програма легко встановлюється в оболонці Windows ХР і автоматично розміщує свої команди виклику в Start Menu (Головне меню), меню Programs (Програми), контекстні меню файлів, а свій ярлик розміщає на Робочому столі.
Вікно програми WinZip представлено на мал. 3.1. Описана версія цієї програми WinZip11.2. Ця програма легко встановлюється в оболонці Windows ХР і автоматично розміщує свої команди виклику в Start Menu (Головне меню), меню Programs (Програми), контекстні меню файлів, а свій ярлик розміщає на Робочому столі.
Дата добавления: 2018-06-27; просмотров: 573; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!