Практическое задание (к семинарским занятиям)
1 Обсудить и разобрать основные принципы распределенной базы данных, сформулированные К. Дейтом;
2 Обсудить и разобрать основные принципы построения технологии клиент-сервер.
Вопросы для обсуждения на семинаре, самостоятельного изучения и проверки знаний студентов
1 Дайте понятие распределенной БД.
2 Охарактеризуйте принципы распределенной БД, сформулированные 3 К. Дейтом.
4 В чем состоит сущность технологии клиент-сервер?
5 Назовите преимущества технологии клиент-сервер по сравнению
с технологией файл-сервер.
6 Охарактеризуйте технологию репликации данных.
7 Охарактеризуйте технологию объектного связывания данных.
ДОКУМЕНТАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Первоначальным направлением развития СУБД стала разработка и использование фактографических информационных систем, которые ориентированы на обработку структурированных данных. Были разработаны модели организации фактографических данных, отработаны программно-технические решения по накоплению и физическому хранению таких данных, реализованы языки запросов к БД.
Теоретические исследования вопросов автоматизации обработки неструктурированной информации, начавшись еще в 50-х годах, пока не привели к созданию такой строгой, полной и технически реализуемой модели представления и обработки данных, как реляционная модель. Пока не разработаны стандартные информационно-поисковые языки (подобные SQL), которые можно было бы использовать для формализованного описания содержания документов и построения запросов.
|
|
|
Элементом данных в документальных ИС является документ (в фактографических информационных системах элементом является запись). Обычно под документом понимается текстовый файл.
Основной задачей документальных информационных систем является хранение и предоставление пользователю документов, содержание которых соответствуют его информационным потребностям.
Документальная информационная система (ДИС) — единое хранилище документов с инструментарием поиска и выдачи необходимых пользователю документов.
Поисковый характер документальных информационных систем определил еще одно их название — информационно-поисковые системы (ИПС).
Соответствие найденных документов информационным потребностям пользователя называется пертинентностью. В силу теоретических и практических сложностей формализации смыслового содержания документов пертинентность относится скорее к качественным понятиям.
В зависимости от особенностей реализации хранилища документов и механизмов поиска, ДИС можно разделить на две группы:
|
|
|
системы на основе индексирования;
семантически-навигационные системы.
Семантика (от грсч. semantikos — обозначающий) — значения единиц языка,
В семантически-навигационных (гипертекстовых) системах документы, помещаемые в хранилище документов, оснащаются специальными навигационными конструкциями (гиперссылками), соответствующими смысловым связям между различными документами или отдельными фрагментами одного документа.
В системах на основе индексирования исходные документы помещаются в базу без какого-либо дополнительного преобразования, но при этом смысловое содержание каждого документа отображается в некоторое поисковое пространство. Процесс отображения документа в поисковое пространство называется индексированием и заключается в присвоении каждому документу некоторого индекса — координаты в поисковом пространстве. Формализованное представление индекса документа называется поисковым образом документа(ПОД). Пользователь выражает свои информационные потребности, посредством специального языка, формируя поисковый образ запроса (ПОЗ) к базе документов.
На основе определенных критериев ДИС осуществляет поиск и выдачу документов, поисковые образы которых соответствуют поисковым образам запроса пользователя.
|
|
|
Соответствие найденных документов запросу пользователя называется релевантностью.
Информационно-поисковый язык (ИПЯ) представляет собой некоторую формализованную семантическую систему, предназначенную для выражения содержания документа и поискового запроса.
Основными элементами ИПЯ являются алфавит, лексика и грамматика.
Алфавит ИПЯ — система знаков, используемых для записи слов и выражений ИПЯ.
Лексика, или словарный состав, ИПЯ — совокупность слов, словосочетаний и выражений, используемых для построения текстов ИПЯ.
Грамматика ИПЯ — совокупность средств и способов построения, изменения и сочетания лексических единиц. Грамматика включает морфологию и синтаксис.
Построение выражений ИПЯ требует решения, по крайней мере, двух проблем. Первая из них связана с выбором лексических единиц ИПЯ, необходимых для построения выражений.
Выбор слов определяется их смыслом, обусловленным парадигматическими отношениями между предметами и явлениями, которые они определяют.
Парадигматические отношения — это отношения, обусловленные наличием логических связей между предметами и явлениями, обозначенными данными словами.
|
|
|
Естественный язык обладает высокой многозначностью. В ИПЯ недопустима многозначность. Поэтому здесь необходимо учитывать отношения синонимии и омонимии слов естественного языка, используемых в ИПЯ.
Омонимия — это совпадение слов по написанию или звучанию и несовпадение по смыслу.
Полисемия слова состоит в том, что одно и то же слово выражает пучок родственных понятий. Например, слово «соль» обозначает вещество, а также понятие смысла. Оба значения близки по сути.
Синонимия — это совпадение слов по значению и несовпадение по написанию.
Вторая проблема построения фраз ИПЯ связана с определением последовательности выбранных слов.
Синтагматические отношения — отношения слов при соединении их в словосочетания и фразы. Для уточнения смысла документа или запроса, помимо ключевых слов, часто необходимо указывать, в каких синтагматических отношениях эти слова находятся. Так, фраза «защита окружающей среды от человека» и фраза «защита человека от окружающей среды» имеют совершенно разный смысл, хотя и состоят из одних и тех же ключевых слов.
Многообразие используемых в ИПЯ парадигматических и синтагматических отношений определяет семантическую силу ИПЯ.
Координатное индексирование — индексирование, при котором основное смысловое содержание текста (документа) или информационного запроса представляется в виде сочетания ключевых слов или дескрипторов.
Ключевые слова — это наиболее существенные для отображения содержания документа слова и словосочетания, обладающие назывной функцией.
К классификационным языкам относят:
информационно-поисковый язык иерархического типа;
информационно-поисковый язык фасетного типа;
алфавитно-предметную классификацию.
Основными показателями эффективности функционирования ДИС являются полнота и точность информационного поиска.
Полнота информационного поиска R определяется отношением числа найденных релевантных документов А к общему числу релевантных документов С, имеющихся в системе:

Точность информационного поиска Р определяется отношением числа найденных релевантных документов А к общему числу документов L, выданных па запрос пользователя:
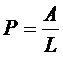
Наличие среди отобранных на запрос пользователя нерелевантных документов называется информационным шумом системы. Коэффициент информационного шума К определяется отношением числа нерелевантных документов (L - А), выданных в ответе пользователю, к общему числу документов L, выданных на запрос пользователя:
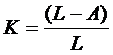
Информационно-поисковые каталоги, основанные на классификации сведений по определенной предметной области, были первыми системами информационного поиска документов.
Классификация — это группировка объектов по признакам.
Первоначальные подходы к классификации тематики документов основывались на формировании списка предметных заголовков, располагаемых в алфавитном порядке. Каждая предметная рубрика получала определенный цифровой или буквенно-цифровой код. Содержание документа индексировалось перечислением кодов тех рубрик, которые отражали темы документа. Это перечислительная классификация.
Особенностью систем перечислительной классификации является возможность индексирования документов любым количеством рубрик, отражающих содержание документа. Для осуществления поиска необходимых документов по классификатору определяются коды интересующих пользователя рубрик и далее отбираются из хранилища те документы, которые проиндексированы соответствующими кодами. Отсутствие систематизированных связей и отношений между предметными рубриками является основным недостатком перечислительной классификации.
При систематизированной классификациисписок предметных рубрик строится как иерархическая структура, в виде перевернутого дерева. Вся предметная область разбивается на ряд взаимоисключающих (непересекающихся) рубрик. Каждая рубрика, в свою очередь, может включать несколько подрубрик. Таким образом, при систематизированной классификации учитываются уже некоторые семантические основы предметной области, выражаемые в родо-видовых отношениях основных категорий, понятий и классов.
Содержание документа индексируется кодами соответствующих рубрик, однако при этом отпадает необходимость в явном указании более общих рубрик, к которым относятся выделенные подрубрики. В результате индексирование и поиск документов на основе иерархической классификации позволяют более адекватно отражать содержание документов и обеспечивают большую точность поиска.
Перечислительный и иерархический подходы к классификации используются в алфавитно-предметных каталогах библиотек, Недостатком как перечислительной, так и иерархической классификации является принципиальная невозможность заранее перечислить все возможные темы документов.
Фасетная классификация не связана подобными ограничениями. Ее идея состоит в том, что вся предметная область разбивается на ряд исходных рубрик - фасет — по семантическому принципу, отражающему специфику предметной области.
Фасеты выступают в роли элементов, из которых можно сконструировать любую, даже самую сложную и узкую предметную рубрику. Внутри фасет предметные рубрики строятся и упорядочиваются по алфавитно-иерархическому принципу.
Основное достоинство фасетной классификации заключается в возможности небольшим перечнем фасетных рубрик отразить большое количество специализированных рубрик и тем самым наиболее точно и полно проиндексировать содержание документов.
В основе построения дескрипторных ИПЯ лежит принцип координатного индексирования, который предполагает, что основное смысловое содержание документа может быть выражено списком ключевых слов. К ключевым словам относятся так называемые полнозначные слова - существительные, прилагательные, глаголы, наречия, числительные, местоимения. Ключевыми словами не могут быть предлоги, союзы, связки, частицы.
Основными элементами ДИПЯ являются:
словарь лексических единиц;
правила применения ИПЯ (грамматика), определяющие процедуру перевода текстов документов и запросов с естественного
языка на ИПЯ;
правила построения ИПЯ.
Словари лексических единиц делятся па две группы:
основные лексические словари, составляющие лексику ИПЯ;
морфологические словари, обеспечивающие морфологический
анализ и нормализацию слов.
В качестве лексических единиц основных словарей используются ключевые слова, словосочетания и дескрипторы.
Дескриптор — понятие, обозначающее группу эквивалентных или близких по смыслу ключевых слов. Дескриптор — это имя класса синонимов. В качестве дескрипторов могут быть использованы код, слово или словосочетание.
Разработка дескрипторного языка фактически сводится к разработке информационно-поискового тезауруса (ИПТ).
Тезаурус(от греч. «хранилище», «сокровищница») в узком смысле представляет собой специальный словарь-справочник, в котором перечислены ключевые слова — дескрипторы определенной предметной области, указаны их синонимы, установлены способы устранения синонимии, омонимии, полисемии, определены родо-видовые и ассоциативные связи дескрипторов.
Обобщенная структура ИПТ включает как минимум три составляющих: словарную часть, семантическую карту, руководство по использованию.
Приведем ряд определений.
Словарная часть — алфавитный список дескрипторов с их словарными статьями.
Семантическая карта — система тематических классов дескрипторов, представленная в виде графической схемы или таблицы.
Руководство по использованию ИПТ содержит правила перевода ключевых слов и словосочетаний на ИПЯ, правила лексикографического контроля и редактирования ПОД и ПОЗ, а также правила ведения ИПТ.
Отличием информационно-поисковых тезаурусов от информационно-поисковых каталогов на основе предметной иерархической рубрикации является то, что в тезаурусах, помимо классификационной схемы, присутствуют сами ключевые слова и дескрипторы, объединяемые под названием классов, рубрик и т. д. В каталогах же присутствуют только лишь обозначения (названия) классов.
Главная идея информационно-поисковых тезаурусов заключается в повышении эффективности индексирования документов в рамках дескрипторного подхода. Иначе говоря, в системах на основе ИПТ ПОД представлен набором дескрипторов. Однако в процессе индексирования документов учитываются семантические отношения между дескрипторами, что, в конечном счете, обеспечивает более адекватный содержанию документа ПОД и повышает эффективность поиска документов.
Система индексирования (СИ) — совокупность методов и средств перевода текстов с естественного языка на ИПЯ в соответствии с заданным набором словарей лексических единиц и с правилами применения ИПЯ.
Рассмотрим классификацию систем индексирования.
1 По степени автоматизации процесса индексирования выделяют
системы:
ручного индексирования;
автоматического индексирования;
автоматизированного индексирования.
2 По степени контролируемости различают системы:
без словаря;
с жестким словарем;
со свободным словарем.
3 По характеру алгоритма отбора слов текста выделяют системы:
с последовательным просмотром текста (отбираются все полнозначные слова);
с эвристическими процедурами выбора слов текста (слова отбираются интуитивно или по заданной процедуре);
со статистическими процедурами выбора слов (отбираются
только информативные слова в соответствии с распределением частот их употребления).
4 По характеру лексикографического контроля различают системы:
без лексикографического контроля;
с полным контролем;
с промежуточным контролем.
5 Лексикографический контроль предусматривает:
устранение синонимии, полисемии и омонимии на основе нормативных словарей лексических единиц с парадигматическими отношениями между ними;
нормализацию слов на основе морфологических нормативных
словарей.
6 По характеру морфологического анализа слов различают системы:
с использованием морфологических словарей;
с использованием основных лексических словарей;
с использованием морфологического анализа с усечением слов.
Возможны системы индексирования без морфологического анализа.
Процесс свободного индексирования состоит в следующем. Индексатор выписывает слова или словосочетания, которые, по его мнению, отражают содержание текста. Он может брать слова, отсутствующие в тексте, но важные, с его точки зрения, для выражения смысла текста. Отобранный список слов является поисковым образом документа. Это СИ с ручным индексированием.
При жестком индексировании слова берутся только из текста.
Поначалу индексирование осуществлялось специально подготовленными специалистами-экспертами в предметной области, которые могли осуществлять глубокий анализ смыслового содержания документа и относить его (индексировать) к тем или иным классам, рубрикам, ключевым терминам. В этом случае были высоки накладные расходы, поскольку требовалось наличие в штате высококвалифицированных специалистов-индексаторов. Кроме того, процесс индексирования в некоторой мере был субъективным. Поэтому возникла задача автоматизации индексирования документов.
Существуют два подхода к автоматическому индексированию. Первый основан на использовании словаря ключевых слов и применяется в системах на основе ИПТ. Индексирование в таких системах осуществляется путем последовательного автоматического поиска в тексте документа ключевых терминов. Строится индекс, представляющий поисковое пространство документов. Возможны два типа такого индекса — прямой и инвертированный (рис. 9.4).
Прямой тип индекса строится по схеме «документ—термины». Поисковое пространство в этом случае представлено в виде матрицы размерностью n x m. Строки этой матрицы представляют поисковые образы документов.
Инвертированный тип индекса строится по обратной схеме — «термин—документы». Поисковое пространство соответственно представлено аналогичной матрицей, только в транспонированной форме. Поисковыми образами документов в этом случае являются столбцы матрицы.
Второй подход к автоматическому индексированию применяется в полнотекстовых системах.В процессе индексирования в индекс заносится информация обо всех словах текста документа (отсюда и название «полнотекстовые»).
Процессы компьютеризации деятельности предприятий привели к накоплению большого объема неструктурированной текстовой информации. Возникла потребность в программном обеспечении, реализующем эффективный поиск информации.
Информационно-поисковые каталоги, фасетные и тезаурусные системы не могли быть в полной мере использованы в массовой персональной автоматизации. Потребовались средства, которые бы в максимальной степени освобождали пользователя от необходимости сложной предварительной структуризации предметной области и затратных процедур индексирования при накоплении текстовых данных, но в то же время создавали бы эффективный и интуитивно понятный поисковый инструментарий. В результате на рынке программных продуктов появились полнотекстовые ИС.
Полнотекстовые ИС строятся на основе информационно-поисковых языков дескрипторного типа. Информационно-технологическая структура полнотекстовых ИС включает:
хранилище документов;
глобальный словарь системы;
инвертированный индекс документов;
интерфейс ввода документов в систему;
механизм индексирования;
интерфейс запросов пользователя;
механизм поиска документов;
механизм извлечения найденных документов.
Хранилище документов может быть организовано как единая локально сосредоточенная информационная структура в виде специального файла с текстами документов.
Существенное влияние на эффективность полнотекстовых ИС оказывает морфологический разбор при индексировании документов и запросов. Морфологический разбор позволяет выделять общую для однокоренных слов словоформу, а также выделять лексемы, т. е. слова, отличающиеся окончаниями, приставками и суффиксами.
В результате индексирования поисковый образ каждого нового документа представляется набором словоформ из глобального словаря, присутствующих в тексте документа, и поступает в виде соответствующего двоичного вектора для дополнения индекса системы. Индекс строится но инвертированной схеме и в двоичном виде отражает весь (полный) текст учтенных или накопленных документов.
При удалении документа из системы соответственно удаляется и поисковый образ документа.
Через интерфейс запросов пользователь в терминах ИПЯ делает запрос, который обрабатывается поисковой машиной. Механизм поиска основывается на тех или иных алгоритмах и критериях сравнения поискового образа запроса с поисковыми образами документов, образующими индекс системы. Результатом поиска является определение номеров документов, поисковые образы которых соответствуют поисковому образу запроса. Далее специальная подсистема на основе установленных в хранилище указательных конструкций извлекает и доставляет соответствующие документы пользователю.
Примером полнотекстовых информационно-поисковых систем являются автоматизированные информационные системы по законодательству.
Автоматизированная информационная система по законодательству(АИСЗ) — это программный комплекс, включающий в себя массив правовой информации и инструменты для работы с ним. Эти инструменты позволяют производить поиск документов, формировать подборки документов, печатать документы.
АИСЗ являются частью следующих типов информационных систем.
Справочно-информационные системы общего назначения, ориентированные на доступ пользователей к нормативно-правовым
актам. К этим системам относятся «Консультант Плюс», «Гарант», «Кодекс» и др.
Глобальные информационные службы (хост-системы), предоставляющие доступ удаленным пользователям к библиографической, полнотекстовой или другой информации. Крупнейшей в мире коммерческой службой, обеспечивающей доступ к юридической информации, является система LEXIS (США).
Системы информационной поддержки деятельности правотворческих, органов. Спецификой таких систем является необходимость хранения и поиска многих версий и редакций нормативно-правовых документов, с учетом вносимых поправок и изменений.
В 1992 году образовалось НПП «Гарант-Сервис». В этом же году была создана общероссийская сеть «Консультант Плюс», которая охватила множество городов России. В настоящее время наиболее распространена АИСЗ «Консультант Плюс». Система «Гарант» занимает второе место в России по количеству пользователей.
На третьем месте находится достаточно популярный продукт — информационно-поисковая система «Кодекс», которая разработана малым государственным предприятием «Центр компьютерных разработок».
Существуют два источника получения правовой информации разработчиком для включения в систему: официальная рассылка подписавшего ведомства и опубликование в периодической печати.
Официальная рассылка— основной источник информации для систем «Консультант Плюс», «Гарант» и «Кодекс». Следует заметить, что государственные органы выступают не только в качестве источников информации, но и сами являются пользователями систем, т. е. прямо заинтересованы в оперативном и достоверном пополнении информационного банка. Поэтому, как правило, документы передаются из органов государственной власти сразу же после их подписания.
Сеть «Консультант Плюс» имеет прямые договоры об обмене информацией с основными федеральными органами (среди них — Администрация Президента РФ, Министерство финансов РФ, Центральный банк РФ, Федеральная налоговая служба и др.), а также с местными органами власти. Благодаря аналогичным договорам, нормативные акты достаточно оперативно попадают и в систему «Гарант».
Юридическая база «Кодекс» ведется при содействии юридического комитета мэрии Санкт-Петербурга. Документы для данной системы поступают в «Центр компьютерных разработок» на основе договоров не напрямую с органами власти, а с их представительствами в Санкт-Петербурге.
Публикации в печатных изданиях.Выделяют три группы таких источников. К первой относятся все издания, в которых публикация нормативных актов считается официальной: «Бюллетень международных договоров», «Вестник ЦБ РФ», «Российская газета», «Российские вести» и др. Вторую группу составляют издания, не признанные официальными, но в состав учредителей которых входят российские министерства и ведомства: «Бюллетень Верховного суда РФ», «Финансовая газета» и т. д. Наконец, в третью группу входят издания, публикация документов в которых считается достоверной. Такие издания или имеют достаточно большой тираж, или пользуются авторитетом в среде специалистов: «Закон», «Хозяйство и право», «Экономика и жизнь» и др.
Оценка полноты, достоверности и оперативности обновления информации основывается на количественных показателях. Оценка же качества юридической обработки поступающих в информационный банк документов достаточно субъективна.
Без юридической обработки АИСЗ является всего лишь электронным аналогом бумажных изданий, Ее цель — систематизация документов для повышения эффективности их дальнейшего использования.
Классификация документов предназначена для последующего их поиска по некоторым признакам, формальным или неформальным. Классификация производится на основании классификатора данной системы. Как известно, классификатор — это иерархическая структура, содержащая все понятия, используемые для описания документов, входящих в информационную базу.
При работе с удаленной базой пользователю нет необходимости хранить на своем компьютере данные системы, они хранятся на сервере разработчика и доступны через сеть. Большинство АИСЗ имеют версии, доступные через глобальную сеть Интернет. Основное преимущество работы с такими версиями заключается в том, что пользователь всегда имеет доступ к самым последним данным.
Однако для работы с удаленной базой пользователю необходим доступ к Интернету. Зачастую скорость передачи информации через Интернет низкая из-за плохого качества каналов, а стоимость доступа достаточно высокая. Поэтому иногда более выгоден вариант работы с локальной базой, которая доступна в любой момент. Недостатком этого варианта по сравнению с предыдущим является более продолжительный период актуализации информации.
Дата добавления: 2018-04-15; просмотров: 262; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!