MoveDict (c) DataFile.WriteSymbol (c);
Методы сжатия информации
Любые данные можно представить, как последовательность сообщений, которые получаются от некоторого источника информации. При этом очевидно, что каждое состояние источника будет характеризоваться своей вероятностью. Количество информации, что содержится в одном состоянии источника, можно оценить:
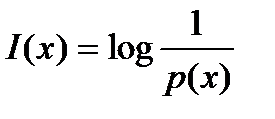
Эта мера была предложена Харли.
Оценить среднее количество информации, которая поступает от одного источника, можно, используя формулу энтропии:
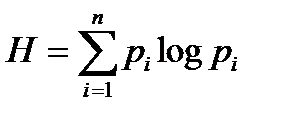
где pi – вероятность i-того состояния источника,
n – общее количество состояний.
Энтропия максимальна, если все состояния источника равновероятны, но таких источников в природе почти не существует, и энтропия должна иметь меньшее значение источника. Можно построить такой код, который разрешает получать среднюю длину кодовой комбинации не больше, чем значение энтропии плюс один бит, и поскольку состояние большинства источников неравновероятное, такой код будет лучше, чем двоичное кодирование источника.
Сжатие информации с помощью оптимальных по короткости кодов
Если проанализировать любой источник информации, можно заметить, что оно генерирует разнообразные сообщения с разной частотой, то есть, можно сказать, что вероятности состояний всех фактических реальных источников информации неодинаковые. Это стало основой главной идеи построения оптимальных по короткости кодов. Идея состоит в том, чтобы представить более вероятные состояния более короткими комбинациями кодов. Любой оптимальный по короткости код соответствует следующим требованиям:
|
|
|
1. Все комбинации кода разные;
2. Более вероятные состояния присваивают комбинации покороче;
3. Свойство префиксности: ни одна комбинация кода не начинается с другой, более короткой. Это свойство разрешает получать мгновенный код – код, который можно передавать без разделителей. При декодировании со входного потока изымается информация про символы, и как только накопленная комбинация совпадет с комбинацией кода, она декодируется.
Есть источник:
Х1 0
Х2 010
Х3 10
Х4 1
Генерируется последовательность:
Х2 Х1 Х3
010 0 10
Из-за невыполнения свойства префиксности возникает неопределенность.
4. Две кодовые комбинации, соответствующие двум состояниям с наименьшей вероятностью, имеют одинаковую длину и различаются только в одном - последнем двоичном разряде.
МЕТОД ХАФФМАНА
Для построения кода необходимо:
1. Записываем все состояния в порядке убывания их вероятности.
2. Объединяем два состояния с наименьшей вероятностью, заменяя их одним, вероятность которого равна сумме его составляющих.
|
|
|
3. Шаг 1 и 2 повторяем, пока не останется одно состояние, с вероятностью 1.
4. На основании этих шагов строится дерево: верхушка дерева – состояние с вероятностью 1, справа от каждой вершины находятся состояния с большими вероятностями, слева с меньшими. Все правые ветви обозначаются 0, левые 1.
5. Выписываются кодовые комбинации путем обхода дерева от корня к терминальным узлам.
Например:
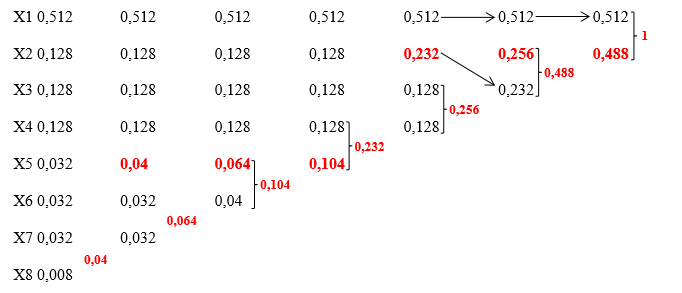
Рис. 1. Алгоритм метода Хаффмана.
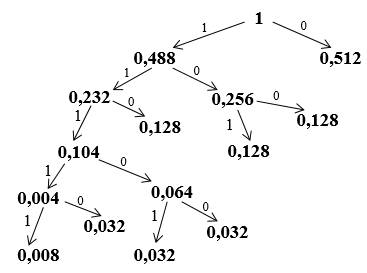
Рис. 2. Построение дерева Хаффмана.
Х1 0
Х2 100
Х3 101
Х4 110
Х5 11100
Х6 11101
Х7 11110
Х8 11111
Эффективность построенного кода можно оценить, вычислив среднюю длину кодовой комбинации, сравнив ее с энтропией и длиной комбинации при двоичном кодировании:
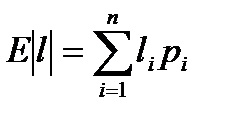
В среднем при сжатии сообщения, состоящего из 1000 состояний источника, мы потратим 2184 битов. При использовании же простого двоичного кода потребовалось бы 3000 бит.
В идеале средняя длина кодовой комбинации должна быть равна среднему количеству информации, получаемой от одного события сгенерированного источника.
МЕТОДЫ СЖАТИЯ ТЕКСТОВОЙ И ГРАФИЧЕСКОЙ ИНФОРМАЦИИ.
МЕТОД ПОДАВЛЕНИЯ НУЛЕЙ.
Один из старейших и самых простых методов сжатия данных известен как подавление нулей (null suppression), или подавление пропусков (blank suppression).
|
|
|
В тексте или потоке символов часто встречаются длинные строки пропусков или нулей. В методе подавления нулей передатчик сканирует данные в поисках строк пропусков и заменяет каждую такую строку двухсимвольным кодом. Код состоит из специального управляющего символа, затем указывается количество пропусков в строке. Например, код, в котором символы пропуска, отмеченные b:
XYZbbbbbQRX
Эта строчка заменяется следующей строчкой, в которой Scпредставляет собой специальный управляющий символ:
XYZSc5QRX
Такая схема позволяет сократить все строки, где есть три и больше пропуска.
В методе подавления нулей получатель ищет в потоке входящих символов специальный символ, используемый для индикации удаленных пропусков. Получив такой символ, получатель понимает, что следующий символ содержит количество удаленных пропусков. По этой информации может быть восстановлен первоначальный поток данных.
При том что метод подавления нулей является крайне примитивной формой сжатия данных, его преимущество заключается в том, что он очень легко реализуется. Кроме того, выигрыш также для использования такого простого метода может быть значительным. Практически, при первых внедрениях этого метода выигрыш составил от 30% до 50%.
|
|
|
ГРУППОВОЕ КОДИРОВАНИЕ
Групповое кодирование (run - length encoding) является простым методом сжатия данных без потерь, достаточно эффективен для сжатия текста. Этот метод также находит применение в факсимильном сжатии.
ScXCc
Sc – специальный символ, указывает на то, что после него идут сжатые данные;
Х – любой повторяющийся символ;
Cc – счетчик символов, то есть, количество повторений сжатого символа.
Пример:
$******55.72 $Sc*655.72
--------- Sc-9
Как и в методе подавления нулей, передатчик ищет последовательности повторяющихся символов. В данном случае он заменяет их на трехсимвольний код. Код состоит из специального индикатора сжатия, за которым следуют сам символ, который повторяется, и количество его повторений. Таким образом, этот метод позволяет сократить место, которое занимает любая последовательность из четырех и более одинаковых символов.
Эффективность метода группового кодирования зависит от того, насколько часто в исходных данных встречаются последовательности повторяющихся символов, и средней длины таких серий. Стандартной мерой эффективности сжатия является коэффициент сжатия, который представляет собой отношение длины несжатых данных к длине сжатых данных (включая символы кодировки).
Любая схема сжатия будет иметь переменную производительность, которая будет зависеть от исходных данных. Однако в большинстве случаев в тексте содержится достаточное количество повторяющихся символов, чтобы применение даже такого простого метода как групповое кодирование, было оправданным.
Групповое кодирование было одним из первых методов сжатия факсимильных сообщений, но теперь оно больше не используется с этой целью. Однако этот метод следует изучить, поскольку он применяется в сложных методах сжатия изображений. При использовании метода группового кодирования для изображений вместо отсканированной и оцифрованной линии передаются длины серий белых и черных элементов изображения.
Каждый пиксель представляется как один бит, что означает белый или черный цвет. Код длин серий состоит из длин черных и белых последовательностей, которые чередуются. Поскольку при таком кодировании изображения черный и белый цвета всегда чередуются; нет необходимости в использовании специального символа, который указывает на цвет серии. Таким образом, закодированный поток данных является рядом цифр, обозначающих длины серий черных и белых точек, которые чередуются. В простом примере закодированные данные занимают больше места, чем первоначальные. Но в случае использования этого метода относительно типичной страницы текста, этот метод будет сжимать данные. Тем не менее, это не самый эффективный способ сжатия изображений.
Методы сжатия данных очень важны для широкого применения цифровых и факсимильных аппаратов. Для примера рассмотрим типичную страницу, с разрешением в 200 пелов (белых или черных точек) на дюйм (это является приемлемой, но не высокой степенью разрешения). В результате такая страница содержит 3740000 бит (8,5 дюймов х 11 дюймов х 40 000 пелов на квадратный дюйм). При базовой скорости службы ISDN в 64 Кбит / с передача такой страницы займет около одной минуты.
Сектор ITU-T стандартизировал два метода сжатия данных без потерь для факсимильной связи: модифицированный код Хаффмана и модифицированный метод READ. В типичном документе черные и белые области имеют тенденцию к объединению. Если рассматривать документ как последовательность линий и обратить внимание на расположение участков белого и черного в строки, можно обнаружить длинные серии белых и черных точек. Благодаря этому свойству можно предположить, что сжатие, основанное на методе группового кодирования, даст хороший результат. Входные данные, которые состоят из двух значений, превратятся в длины серий, которые затем кодируются для передачи. Кроме этого, поскольку в общем случае длинные серии черных и белых точек менее вероятны, чем короткие, можно воспользоваться преимуществом кодирования последовательностей переменной длины.
ФАКСИМИЛЬНОЕ СЖАТИЕ. МОДИФИЦИРОВАННЫЙ МЕТОД ХАФФМАНА.
Факсимильное изображение хорошо поддается сжатию, это связано с тем, что изображения являются бинарными и в них присутствуют длинные последовательности, которые повторяются.
Бинарное изображение – изображение с двумя цветами: цвет фона и цвет точки. Минимальное разрешение факса таково, что в одной линии будет не менее 1728 точек, поскольку точки бывают только двух цветов, изображение можно эффективно сжимать с помощью RLE-кодирования.
Для кодирования факсов может применяться код Хаффмана, описанный выше. Этот метод можно применить для каждой строки изображения, кодируя последовательности черных и белых точек. Например, предположим, что при сканировании отдельной строки получается следующая последовательность черных и белых точек: W7, В7, W4, В8, W4, В7, W10 (в данном случае W означает белый, а В – черный). Если рассматривать каждый из этих элементов как символ алфавита источника, то для кодирования этих данных может быть использован метод кодирования Хаффмана. Однако, поскольку стандарт ITU-T требует минимум 1728 точек в линии, количество различных кодов, а, следовательно, и средняя длина кода будет очень большой.
Альтернативой является модифицированный метод кодирования Хаффмана. В этом методе длина серии N рассматривается как сумма двух слагаемых:
N = 64m + n; m = 0, 1, 2…27; n = 0,1, 2, …, 63.
То есть длина каждой серии черных или белых точек считается величиной, кратной 64 с остатком.
Теперь каждая длина серии может быть представлена двумя значениями, одним для m и другим для n, и эти значения могут кодироваться с помощью метода Хаффмана. Например, строка из 200 черных точек подряд может быть выражена как 64 * 3 + 8. Для этого сектора ITU-T были определены восемь образцов документов и рассчитана вероятность нахождения в документах серий различных длин. Поскольку для серий из черных и белых точек эти вероятности различаются, были сочтены два множества вероятностей. На основе полученной информации были составлены две таблицы. Длина серии делится на 64, после чего доля и остаток от деления кодируются двумя кодовыми словами. Если длина серии меньше 64 (доля от разделения равна нулю), то такая длина серии кодируется только кодовым словом остатка. Серии длиной более 64 точек кодируются двумя кодами: код остатка (n) и кодом кратности (m). Есть еще несколько моментов, касающихся этого кода. Каждая строка заканчивается уникальным кодовым словом EOL (End Of Line - конец строки). Это кодовое слово, что никогда не встречается в строках данных, обеспечивает восстановление синхронизации в случае ошибок. Внутри строки должны чередоваться кодовые слова для белых и черных серий. Обратите внимание на то, что для белых и черных серий используются различные кодовые слова. Это обеспечивает дополнительную защиту от ошибок. Наконец, по соглашению каждая строка начинается с белой серии.
■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■
Табл. 1. Составные коды модифицированного кода Хаффмана.
| Длина серии | Белая серия | Черная серия |
| Кодовые слова остатка | ||
| 0 | 00110101 | 0000110111 |
| 1 | 000111 | 010 |
| 2 | 0111 | 11 |
| 3 | 1000 | 10 |
| 4 | 1011 | 011 |
| 5 | 1100 | 0011 |
| 6 | 1110 | 0010 |
| 7 | 1111 | 00011 |
| 8 | 10011 | 000101 |
| 9 | 10100 | 000100 |
| 10 | 00111 | 0000100 |
| 11 | 01000 | 0000101 |
| 12 | 001000 | 0000111 |
| 13 | 000011 | 00000100 |
| 14 | 110100 | 00000111 |
| 15 | 110101 | 000011000 |
| 16 | 101010 | 0000010111 |
| 17 | 101011 | 0000011000 |
| 18 | 0100111 | 0000001000 |
| 19 | 0001100 | 00001100111 |
| 20 | 0001000 | 00001101000 |
| 21 | 0010111 | 00001101100 |
| 22 | 0000011 | 00000110111 |
| 23 | 0000100 | 00000101000 |
| 24 | 0101000 | 00000010111 |
| 25 | 0101011 | 00000011000 |
| 26 | 0010011 | 000011001010 |
| 27 | 0100100 | 000011001011 |
| 28 | 0011000 | 000011001100 |
| 29 | 00000010 | 000011001101 |
| 30 | 00000011 | 000001101000 |
| 31 | 00011010 | 000001101001 |
| 32 | 00011011 | 000001101010 |
| 33 | 00010010 | 000001101011 |
| 34 | 00010011 | 000011010010 |
| 35 | 00010100 | 000011010011 |
| 36 | 00010101 | 000011010100 |
| 37 | 00010110 | 000011010101 |
| 38 | 00010111 | 000011010110 |
| 39 | 00101000 | 000011010111 |
| 40 | 00101001 | 000001101100 |
| 41 | 00101010 | 000001101101 |
| 42 | 00101011 | 000011011010 |
| 43 | 00101100 | 000011011011 |
| 44 | 00101101 | 000001010100 |
| 45 | 00000100 | 000001010101 |
| 46 | 00000101 | 000001010110 |
| 47 | 00001010 | 000001010111 |
| 48 | 00001011 | 000001100100 |
| 49 | 01010010 | 000001100101 |
| 50 | 01010011 | 000001010010 |
| 51 | 01010100 | 000001010011 |
| 52 | 01010101 | 000000100100 |
| 53 | 00100100 | 000000110111 |
| 54 | 00100101 | 000000111000 |
| 55 | 01011000 | 000000100111 |
| 56 | 01011001 | 000000101000 |
| 57 | 01011010 | 000001011000 |
| 58 | 01011011 | 000001011001 |
| 59 | 01001010 | 000000101011 |
| 60 | 01001011 | 000000101100 |
| 61 | 00110010 | 000001011010 |
| 62 | 00110011 | 000001100110 |
| 63 | 00110100 | 000001100111 |
| Кодовые слова кратности 64 | ||
| 64 | 11011 | 0000001111 |
| 128 | 10010 | 000011001000 |
| 192 | 010111 | 000011001001 |
| 256 | 0110111 | 000001011011 |
| 320 | 00110110 | 000000110011 |
| 384 | 00110111 | 000000110100 |
| 448 | 01100100 | 000000110101 |
| 512 | 01100101 | 0000001101100 |
| 576 | 01101000 | 0000001101101 |
| 640 | 01100111 | 0000001001010 |
| 704 | 011001100 | 0000001001011 |
| 768 | 011001101 | 0000001001100 |
| 832 | 011010010 | 0000001001101 |
| 896 | 011010011 | 0000001110010 |
| 960 | 011010100 | 0000001110011 |
| 1024 | 011010101 | 0000001110100 |
| 1088 | 011010110 | 0000001110101 |
| 1152 | 011010111 | 0000001110110 |
| 1216 | 011011000 | 0000001110111 |
| 1280 | 011011001 | 0000001010010 |
| 1344 | 011011010 | 0000001010011 |
| 1408 | 011011011 | 0000001010100 |
| 1472 | 010011000 | 0000001010101 |
| 1536 | 010011001 | 0000001011010 |
| 1600 | 010011010 | 0000001011011 |
| 1664 | 011000 | 0000001100100 |
| 1728 | 010011011 | 0000001100101 |
| EOL | 000000000001 | 000000000001 |
МОДИФИЦИРОВАННЫЙ КОД READ
Использование модифицированного кода Хаффмана значительно сокращает количество битов, передаваемых по сравнению с передачей несжатого изображения. Дополнительного увеличения производительности можно достичь, зная о корреляции между последовательностями черно-белых серий точек в двух соседних строках. На самом деле, в типичных документах, передаваемых по факсу, примерно 50% черно-белых и бело-черных переходов находятся точно под соответствующими переходами предыдущей строки, а еще 25% отличаются только на одну точку. Поэтому примерно 75% всех переходов можно с большой эффективностью определить относительно предыдущей строки. Эти соображения и стали основой для создания модифицированного кода READ (Modified READ, MR), (Relative Element Address Designate - относительное определение адресов элементов).
В схеме MR длины серий кодируются в соответствии с расположением так называемых переключающих элементов. Переключающий элемент (changing element) определяется как точка цвета, отличного от цвета предыдущей точки той же линии. Переключающий элемент а1, кодируется расстоянием от одной из опорных точек: или от предыдущего переключающего элемента а0 в той же строке, или от переключающего элемента b1 в предыдущей строке. Выбор переключающего элемента а0 или b1 зависит от конкретной конфигурации.
а0 – стартовый, переключающий элемент кодированной линии, который в начале кодированной линии устанавливается на воображаемый белый переключающий элемент, расположенный левее первого элемента линии, а в процессе кодирования линии переопределяется после каждого шага кодирования;
а1 – следующий переключающий элемент справа от элемента а0 в кодированной линии;
а2 – следующий переключающий элемент справа от элемента a1 в кодированной линии;
b1 – первый, расположенный на опорной линии правее элемента а0 переключающий элемент, цвет которого противоположен цвету а0;
b2 – следующий переключающий элемент правее b1 на опорной линии.
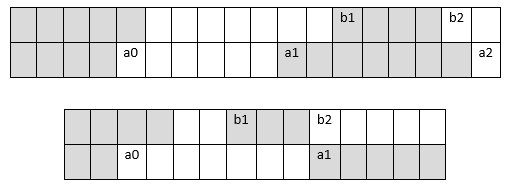
Рис. 3. Расположение переключающих элементов MR.
Процедура кодирования выглядит следующим образом:
1. На первом этапе выбирается один из двух возможных вариантов действий:
a. Если переключающий элемент b2 расположен левее переключающего элемента a1, это кодируется словом 0001. После кодирования позиция a1 смещается так, чтобы переключающий элемент a1 располагался под b2. Это называется режимом пропуска. Затем повторяется шаг 1.
b. Если предварительное условие не выполняется, переходим к шагу 2.
2. На втором шаге также избирается один из двух возможных вариантов действий:
a. Если позиция переключающего элемента a1 находится в пределах трех точек от позиции переключающего элемента b1 (| a1b1 | <3), тогда а1 кодируется вертикально, после чего старая позиция a1 становится новой позицией а0, a2 становится a1 и тому подобное.
b. Если позиция переключающего элемента a1 не находящаяся в пределах трех точек от позиции переключающего элемента b1, тогда a1 кодируется горизонтально. Вслед за кодом горизонтального режима 001 a0a1 и a1a2 кодируются с помощью одномерного модифицированного кодирования Хаффмана. Затем старая позиция а2 становится новой позицией а0.
Табл. 2. Процедура кодирования MR.
| Режим | Элементы, которые кодируются | Нотация | Кодовое слово |
| Пропуск | b1b2 | P | 0001 |
| Горизонтальный | a0a1, a1a2 | H | 001+M(a0a1)+M(a1a2) |
| Вертикальный | a1 под b1 a1b1=0 | Vr(0) | 1 |
| a1 справа от b1 a1b1=1 | Vr(1) | 011 | |
| a1b1=2 | Vr(2) | 000011 | |
| a1b1=3 | Vr(3) | 0000011 | |
| a1 слева от b1 a1b1=1 | Vl(1) | 010 | |
| a1b1=2 | Vl(2) | 000010 | |
| a1b1=3 | Vl(3) | 0000010 |
Шаг 1 используется для перемещения позиций переключающих элементов и b2 после выполнения шага 2. Кроме этого, шаг 1 позволяет избежать больших серий. На шаге 2, если текущий переключающий элемент,который кодируется, оказывается в пределах трех позиций от такого же перехода в предыдущий линии, тогда его позиция кодируется одним из семи возможных значений с помощью модифицированного кодирования Хаффмана. Эта ситуация сохраняется большую часть времени. В отдельных случаях, когда переход в текущей линии не находящаяся в пределах трех позиций от такого же перехода в предыдущий линии, следующие две серии кодируются с помощью модифицированного кодирования Хаффмана.
Схема MR в большей степени чувствительна к ошибкам, чем схема модифицированного кодирования Хаффмана. Результат ошибки может распространяться на непредвиденные расстояния. Чтобы избежать этого, для каждой К-й линии применяется модифицированная схема кодирования Хаффмана. Сектор ITU-T рекомендует значение К = 2 для разрешения 3,85 линии на миллиметр и К = 4 для разрешения 7,7 линий на миллиметр.
СЛОВАРНЫЕ МЕТОДЫ СЖАТИЯ
Входную последовательность символов можно рассматривать как последовательность строк, содержащих любое количество символов. Идея словарных методов заключается в замене строк символов на такие коды, которые можно трактовать как индексы строк некоторого словаря. Строки, образующие словарь, далее будем называть фразами. При декодировании осуществляется обратная замена индекса на соответствующую ему фразу словаря.
Словарь – это набор таких фраз, которые, как мы считаем, будут встречаться в последовательности, которая обрабатывается. Индексы фраз должны быть построены так, чтобы в среднем их представление занимало меньше места, чем требуют строки, которые замещаются. За счет этого и происходит сжатие.
Уменьшение размера возможно в первую очередь за счет того, что обычно в данных, которые сжимаются, встречается лишь небольшая часть всех возможных строк длины n, поэтому для представления индекса фразы нужно, как правило, меньшее количество битов, чем для представления исходной строки.
Далее, если у нас есть гипотезы, которые заслуживают доверия, о частоте использования тех или иных фраз или проводился какой-то частотный анализ данных, которые обрабатываются, мы можем назначить вероятным фразам коды меньшей длины.
Обычно просто предполагается, что короткие фразы используются чаще, чем длинные. Поэтому в большинстве случаев индексы строятся таким образом, чтобы длина индекса короткой фразы была меньше длины индекса длинной фразы. Такой прием обычно способствует улучшению сжатия.
КЛАССИЧЕСКИЕ АЛГОРИТМЫ ЗИВА-ЛЕМПЕЛА
Алгоритмы словарного сжатия Зива-Лемпела появились во второй половине 1970-х годов. Это были так называемые алгоритмы LZ77 и LZ78, которые были разработаны совместно Зивом (Ziv) и Лемпелом (Lempel). В дальнейшем первичные схемы подвергались многочисленным изменениям, в результате чего мы сегодня имеем десятки достаточно самостоятельных алгоритмов и бесчисленное количество модификаций.
LZ77 и LZ78 являются универсальными алгоритмами сжатия, в которых словарь формируется на основании уже обработанной части входного потока, то есть адоптивно. Принципиальным отличием является лишь способ формирования фраз. В модификациях первичных алгоритмов это свойство сохраняется. Поэтому словарные алгоритмы Зива-Лемпела разделяют на два семейства – алгоритмытипа LZ77 и алгоритмы типа LZ78. Иногда также говорят о словарных методах LZ1 и LZ2.
МЕТОД СЖАТИЯ LZ77
Этот словарный алгоритм сжатия является старейшим среди методов LZ. Описание было опубликовано в 1977 году, но сам алгоритм разработан не позднее 1975 года. Алгоритм LZ77 является «основателем» целого семейства словарных схем - так называемых алгоритмов со словарем (окном), который скользит. Действительно, в LZ77 в качестве словаря используется блок уже закодированной последовательности. Как правило, по мере выполнения обработки, положение этого блока относительно начала последовательности постоянно меняется, словарь «скользит» входным потоком данных.
Окно, которое скользит, имеет длину N (то есть в нем содержатся N символов), и состоит из 2 частей:
· Последовательности длины W = N – nуже закодированных символов, которая и является словарем;
· Буфера предыдущего просмотра (lookahead) длины n; обычно nна порядки меньше, чем W.
Пусть до настоящего момента времени мы уже закодировали t символов s1, s2, ..., st. Тогда словарем будут W предыдущих символов st-(W-1), st- (W-1) + 1, ... st. Соответственно, в буфере находятся символы, которые ожидают кодирования, st + 1, st + 2, ..., st + n. Очевидно, если W ≥ t, то словарем будет вся уже обработанная часть входной последовательности.
Идея алгоритма заключается в поиске самого длинного совпадения между строкой буфера, начинается с символа st + 1, и всеми фразами словаря. Эти фразы могут начинаться с любого символа st- (W-1), st- (W-1) + 1, ... st и выходить за пределы словаря, вторгаясь в область буфера, но должны лежать в окне. Итак, фразы не могут начинаться с st + 1, поэтому буфер не может сравниваться сам с собой. Длина совпадения не должна превышать размера буфера. Полученная в результате поиска фраза st- (i-1), st- (i-1) +1 ..., st- (i-1) + (j-1) кодируется с помощью двух чисел:
1. Смещения (offset) от начала буфера, i;
2. Длины соответствия, либо совпадения (matchlength), j.
Смещение и длина соответствия играют роль указателя (ссылки), который однозначно определяет фразу. Дополнительно в выходной поток записывается символ s, непосредственно следует за строкой буфера, которая совпала.
Таким образом, на каждом шагу кодер выдает описание трех объектов: смещение и длины соответствия, образующих код фразы, равной обработанной строке буфера, и одного символа s (литерала). Затем окно смещается на j + 1 символов вправо и осуществляется переход к новому циклу кодирования. Размер смещения объясняется тем, что мы реально закодировали именно j + 1 символов: j с помощью указателя на фразу в словаре, и 1 с помощью тривиального копирования. Передача одного символа в явном виде позволяет решить проблему обработки еще ни разу не виденных символов, но существенно увеличивает размер сжатого блока.
Пример:
Попробуем сжать строку «кот_ломом_колол_слона» длиной в 21 символ. Пусть длина буфера равна 7 символам, а размер словаря больше длины строки, которая сжимается.
Условимся также, что:
· Нулевое смещение зарезервировали для обозначения конца кодирования;
· Символ s, соответствует единичному смещению относительно символа st+i, с которого начинается буфер;
· Если есть несколько фраз с одинаковой длиной совпадения, тогда выбираем самую ближнюю к буферу;
· В неопределенных ситуациях – когда длина совпадения нулевая – смещению назначаем единичное значение.
Таблица 3. Пример кодирования методом LZ77.
| Шаг | Окно, которое скользит | Фраза, которая совпадает | Закодированные данные | |||
| Словарь | Буфер | i | J | S | ||
| 1 | - | кот_лом | - | 1 | 0 | «к» |
| 2 | к | от_ломо | - | 1 | 0 | «о» |
| 3 | ко | т_ломом | - | 1 | 0 | «т» |
| 4 | кот | _ломом | - | 1 | 0 | « » |
| 5 | кот_ | ломом_к | - | 1 | 0 | «л» |
| 6 | кот_л | омом_ко | о | 4 | 1 | «м» |
| 7 | кот_лом | ом_коло | ом | 2 | 2 | « » |
| 8 | кот_ломом | колол_с | ко | 10 | 2 | «л» |
| 9 | кот_ломом_кол | ол_слон | ол | 2 | 2 | « » |
| 10 | …ломом_колол_ | слона | - | 1 | 0 | «с» |
| 11 | …ломом_колол_с | лона | ло | 5 | 2 | «н» |
| 12 | …ом_колол_слон | а | - | 1 | 0 | «а» |
Для кодирования i нам достаточно 5 битов, для j нужно 3 бита, и пусть символы требуют 1 байт для своего представления. Тогда всего мы потратим 12 * (5 + 3 + 8) = 192 бита. В начале строка занимала 21*8 = 168 бит, то есть LZ77 кодирует нашу строку еще более расточительным образом. Не следует также забывать, что мы опустили шаг кодирования конца последовательности, который требовал бы еще не менее 5 битов (размер поля i = 5 битов). Процесс кодирования можно описать следующим образом:
while ( ! DataFile.EOF() ){
/* Найдем максимальное совпадение; в match_pos получим смещение i, в match_len - длину j, в unmatched_sym - первый символ St + i + j, который не совпал; считаем также, что в функции find_match учитывается ограничение на длину совпадения
*/
find_match (&match_pos, &match_len, &unmatched_sym);
/* Запишем в файл сжатых данных описание найденной фразы, при этом длина битового представления i задается константой OFFS_LN, длина представления j - константой LEN_LN, размер символа s принимаем равным 8 битам
*/
CompressedFile.WriteBits (match_pos, OFFS_LN);
CompressedFile.WriteBits (match_len, LEN_LN);
CompressedFile.WriteBits (unmatched_sym, 8); for (i = 0; i <= match_len; i++) {
// прочитаем очередной символ
с = DataFile.ReadSymbol ();
// удалим из словаря одну самую старшую фразу
DeletePhrase ();
/* добавляем в словарь однуфразу, которая начинается с первого символа буфера */
AddPhrase ();
/* сместим окно на 1 позицию, добавляем в конец буфера символ с */
MoveWindow(c);
}
}
CompressedFile.WriteBits (0, OFFS_LN);
Пример подтвердил, что способ формирования кодов в LZ77 является неэффективным и позволяет сжимать только сравнительно длинные последовательности. До некоторой степени сжатие небольших файлов можно улучшить, используя коды переменной длины для смещения i. Действительно, даже если мы используем словарь в 32 Кбайт, но закодировали еще только 3 Кбайт, то смещение реально требует не 15, а 12 битов. Кроме того, происходит существенный проигрыш из-за использования кодов одинаковой длины при указании длин совпадения j. Статистический анализ больших фрагментов текста (порядка нескольких мегабайт) указывает, что различные длины совпадений фраз встречаются с разной вероятностью.
Что касается декодирования сжатых данных, то оно осуществляется путем простой замены кода на блок символов, который состоит из фразы словаря и символа, который передается явно. Естественно, что декодер должен выполнять те же действия с изменением окна, что и кодер. Фраза словаря элементарно определяется смещением и длиной, поэтому важным свойством LZ77 и других алгоритмов с окном, которое скользит, является очень быстрая работа декодера.
Алгоритм декодирования может иметь следующий вид.
for (;;) {
// читаемсмещение
match_pos = CompressedFile.ReadBits (OFFS_LN);
if (!match_pos)
// найден признак конца файла, выходим из цикла
break;
// читаемдлинусовпадения
match_len = CompressedFile.ReadBits (LEN_LN);
for (i = 0; i < match_len; i++) {
// находим в словаре очередной символ фразу, которая совпала
с = Dict (match_pos + i);
// смещаем словарь на 1 позицию, добавляем к его началу с
MoveDict (c);
// записываем очередной раскодированный символ в исходный файл
DataFile.WriteSymbol (c);
}
/* читаем символ, который не совпал, добавляем его в словарь и записываем в исходный файл */
с = CompressedFile.ReadBits (8);
MoveDict (c) DataFile.WriteSymbol (c);
}
Алгоритмы со скользящим окном характеризуются сильной несимметричностью во времени – кодирование значительно медленней декодирования, поскольку при сжатии много времени тратится на поиск фраз.
МЕТОД СЖАТИЯ LZSS
Алгоритм LZSS позволяет достаточно гибко сочетать в исходной последовательности символы и указатели (коды фраз), что в некоторой степени устраняет свойственно LZ77 расточительство, что проявляется в регулярной передаче одного символа в прямом виде. Эта модификация LZ77 была предложена в 1982 году Сторером (Storer) и Жимански (Szymanski).
Идея алгоритма заключается в добавлении к каждому указателя символа однобитового префикса f, что позволяет различать эти объекты. Иначе говоря, однобитовый флажок f указывает на тип и, соответственно, длину тех данных, которые непосредственно следуют за ним. Такая техника позволяет:
· Записывать символы в явном виде, когда соответствующий код имеет большую длину. Значит, словарное кодирование только вредит;
· Обрабатывать символы, которые до этого ни разу не встречались.
Пример:
Закодируем строку "кот_ломом_колол_слона" из предыдущего примера и сравним коэффициент сжатия для LZ77 и LZSS.
Пусть мы переписываем символ в явном виде, если текущая длина максимального совпадения буфера и какой-нибудь фразы словаря меньшей или равной 1. Если мы записываем символ, то перед ним выдаем флаг со значением 0, если указатель - со значением 1. Если есть несколько фраз одинаковой длины, которая совпадает, выбираем ближайшую к буферу.
Таблица 4. Кодирование методом LZSS.
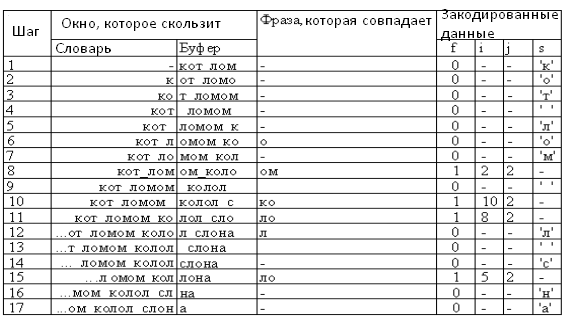
Таким образом, для кодирования строки с помощью алгоритма LZSS нам понадобилось 17 шагов: 13 раз символы были переданы в явном виде, и 4 раза мы использовали указатели. Отметим, что при работе алгоритма LZ77 нам понадобилось только 12 шагов. С другой стороны, если задаться теми же длинами для iи j, размер закодированных с помощью LZSS данных равна 13 * (1 + 8) + 4 * (1 + 5 + 3) = 153 битам. Это означает, что строка действительно была сжатой, потому что ее начальный размер – 168 битов.
Декодирование информации, сжатой алгоритмом семейства LZ на примере алгоритма LZSS:
0 'к' 0 'о' 0 'т' 0 '_' 0 'л' 0 'о' 0 'м' 1 2 2 0 '_' 1 10 2 1 8 2 0 'л' 0 '_' 0 'с' 1 5 2 0 'н' 0 'а'
Таблица 5.Декодирование информации, сжатой алгоритмом семействаLZ на примере алгоритма LZSS.
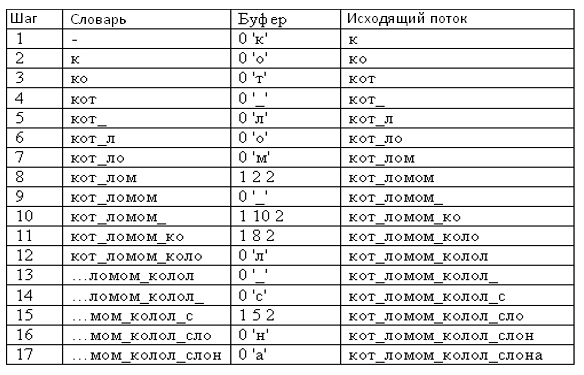
Из алгоритма декодирования видно, что данный процесс исполняется быстрей, чем процесс кодирования, потому что на каждом шаге не нужно многократно использовать поиск в словаре.
СЛОВАРНЫЕ МЕТОДЫ СЕМЕЙСТВА LZ С ТАБЛИЧНЫМ СЛОВАРЕМ. МЕТОД СЖАТИЯ LZ78.
В данных методах словарь представляет собой ассоциативный массив, ключом является индекс фразы, значением - самая фраза. Первым методом этого семейства стал алгоритм LZ78.
Алгоритм работы:
На каждом шагу выполняется поиск длинной фразы из буфера в словаре, если фраза найдена, в выходной поток заносятся ее индекс и символ, следующий за ней; в словарь добавляется новая фраза, которая является конкатенацией из найденной фразы и символа. Если фраза не найдена, в выходной поток заносится зарезервированный индекс и символ из входного потока.
Пример:
Пусть фраза с индексом "1" означает ситуацию, когда ни одна фраза из буфера не найдена в словаре.
Таблица 6. Кодирование методом LZ78
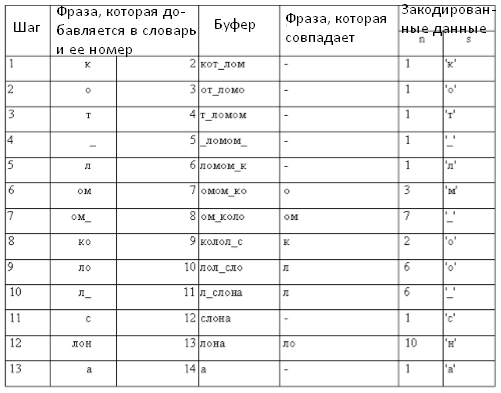
Для индекса достаточно 5 битов информации; символ S - 8 бит; каждый шаг кодирования - 8 + 5 = 13 бит; 13 шагов * 13 бит = 169 бит, а начальная фраза составляла 168.
АЛГОРИТМ СЖАТИЯ LZW.
Алгоритм работы LZW основан на априорном знании входного алфавита. На первом шаге алгоритма весь алфавит заносится в словарь. Кодирование происходит следующим образом: если фраза найдена в словаре, то никакие действия не выполняются, из входного потока извлекается следующий символ и выполняется поиск в словаре уже длинной фразы. Так продолжается до тех пор, пока не будет построена фраза, которой нет в словаре. Когда это произойдет, в выходной поток выводится индекс последней найденной фразы, а текущей фразой становится последний извлеченный из входного потока символ плюс идущий за ним.
Часто используется модификация алгоритма, в которой после выполнения начального словаря, заносится код очистки. Этот код выводится в выходной поток для сброса параметров алгоритма, который позволяет сжимать больший объем информации.
Таблица 7. Кодирование методом LZW.
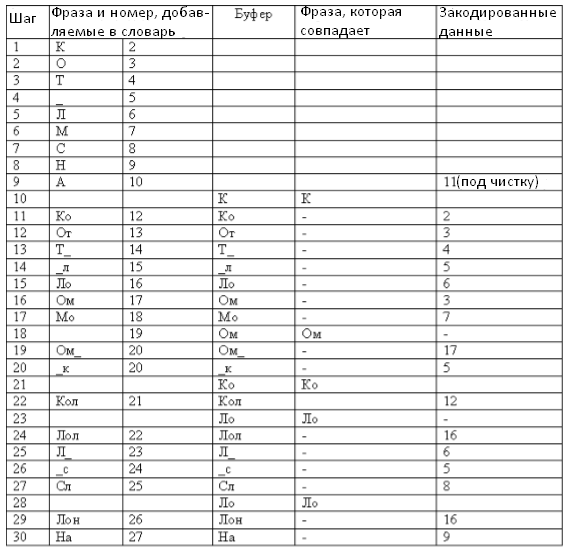
Необходимо 6 битов для сохранения словаря. Закодированная фраза занимает 6 * 18 = 108 бит, а начальная фраза составляла 169 бит.
Общая характеристика словарных методов: коэффициент сжатия для методов, использующих окно, которое скользит, в 2-4 раза; для методов с табличным словарем - в 2,5-5 раз. Отличие в производительности кодера и декодера в 8-10 раз. Как правило, рассмотренные методы редко применяются в чистом виде. Для достижения большего сжатия, к выходному потоку применяют этап вторичного сжатия с применением метода Хаффмана.
МЕТОДЫ ВЫЧИСЛЕНИЯ ЦИФРОВЫХ ДАЙДЖЕСТОВ.
Цифровым дайджестом называется набор значений, вычисленных на основании какого-либо набора данных. Алгоритм вычисления цифрового дайджеста всегда формирует последовательность одной и той же длины независимо от объема обрабатываемых данных. Как правило, алгоритмы получения дайджестов характеризуются крайне малым количеством коллизий (часто коллизию не удается получить в течение многих лет распределенных вычислений).
Сферы применения дайджестов:
1. Проверка целочисленности информации.
2. Создание цифровой подписки.
3. Криптография (шифрование паролей).
Применение цифровых дайджестов в криптографии возможно потому, что алгоритмы фактически необратимые и восстановление начального сообщения возможно только путем полного перебора комбинаций.
АЛГОРИТМ MD5.
Логику вычисления MD5 можно изобразить схемой:
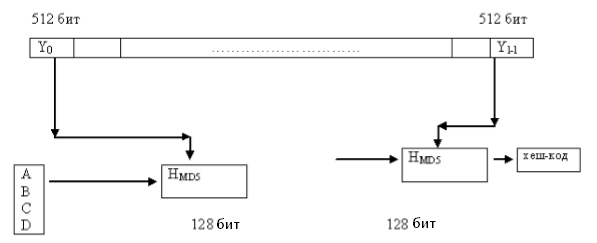
Рисунок 4. Логика вычисления MD5.
Согласно алгоритму MD5 каждый блок исходного сообщения (512 бит) обрабатывается независимо; в результате этой обработки с начального значения хэш-кода выходит новый промежуточный результат. После обработки последнего блока будет получен окончательный результат. Предварительная обработка данных осуществляется следующим образом: из исходного сообщения получают расширенное, для этого сообщения дополняют единицей и набором нулевых битов так, чтобы его длина, плюс еще 64 бита, была кратной 512. Если сообщение уже имеет такую длину, то к нему все равно добавляется пустой блок. После этого к результату присоединяют 64битовую длину сообщения.
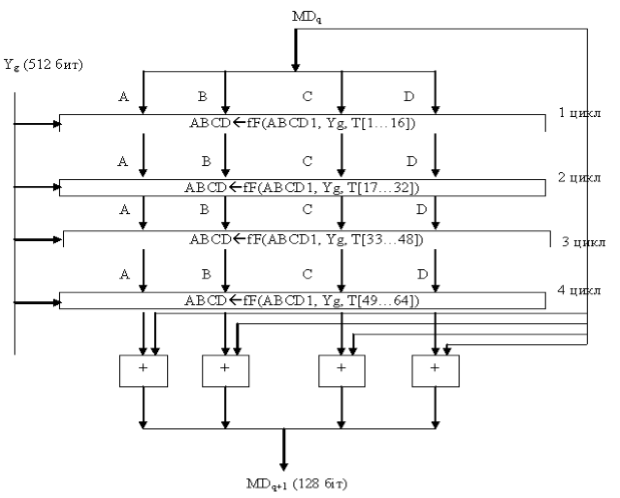
Рисунок 5. Обработка каждого 512-битного блока.
Для каждого цикла используется своя логическая функция, согласно которой выполняется преобразование 32-битных слов дайджестом.
Используются функции:
fF=(B∧C) ∨ (not B∧D)
fG=(B∧D) ∨ (C∧ not D)
fH=B xor C xor D
fL=C xor (B ∧ not D)
Схема цикла:
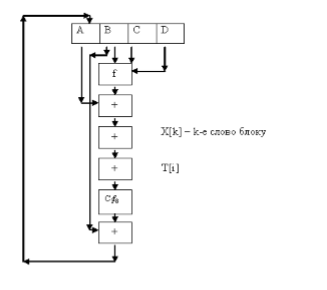
Рисунок 6. Схема цикла.
Обработка 512-битного слова:
CLS - циклический сдвиг влево;
T [i] - элемент массива, используется для переименования битов.
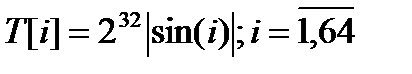
Общая схема преобразования:
A = B + CLSs (A + f (B1C1D1) + X [k] + T [i]);
CLSs - циклический сдвиг влево на s позиций.
Инициализация:
A = 0x1234567
B = 0x89ABCDEF
C = 0xFEDCBA98
D = 0x76543210
Благодаря такой инициализации даже для пустого сообщение будет вычислено нетривиальное значение хеш-функции.
Все сложения при вычислении MD5 выполняются по модулю 2. MD5 имеет достаточную устойчивость для использования при шифровании паролей; для полного перебора понадобится 2128 вычислений хеш-функций, а для поиска коллизии 2128/2 операций, то есть 264.
АЛГОРИТМ ИСЧИСЛЕНИЯ ДАЙДЖЕСТА SHA1.

Рисунок 7. Логика исчисления SHA1.
Логика построения расширенного сообщения совпадает с той, что используется в MD5.
Отличается начальная инициализация хэш-кода:
A = 0x67452301
B = 0xEFCDAB89
C = 0x98BADCFE
D = 0x10325476
E = 0xC3D2E1F0
Обработка каждого 512-битного блока:
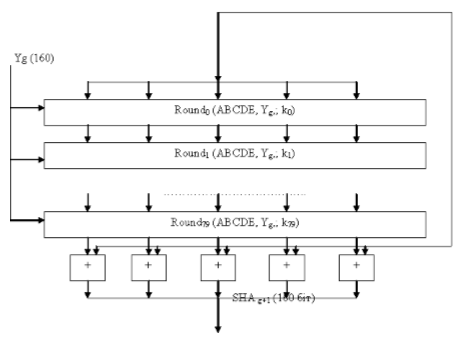
Рисунок 8. Обработка каждого 512-битного блока.
0≤t≤1gk1=0xA827999
Целая часть 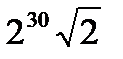
20≤t≤39kt=0x6ED9EBA1
Целая часть 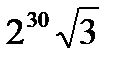
40≤t≤59kt=0x8F1BBCDC
Целая часть 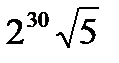
60≤е≤79kt=0xCA62C1D6
Целая часть 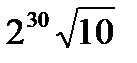
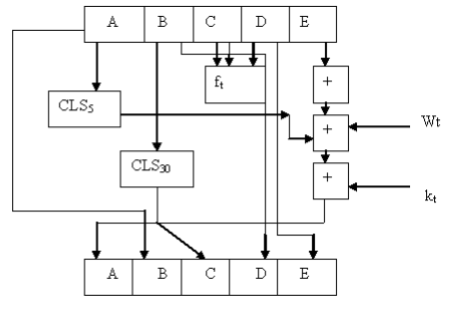
Рисунок 9. Схема цикла.
ЛОГИКА ВЫПОЛНЕНИЯ ROUNDХ
Таблица 7. Логика выполнения ROUNDX
| Номер цикла | Ft (B, C, D) |
| 0≤t≤19 | (B^C) ∨ (~B^D) |
| 20≤t≤ 39 | B xor C xor D |
| 40≤t≤ 59 | (B^C) ∨ (B^D) ∨ (C^D) |
| 60≤t≤ 79 | B xor C xor D |
Слова Wt вычисляются на основании исходных данных, по которым ведется обработка.
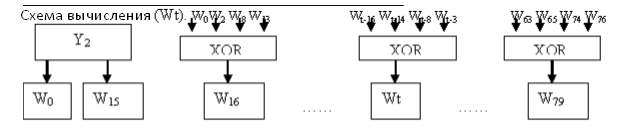
Рисунок 10. Вычисление слов.
Wt=Wt-16 xor Wt-14 xor Wt-8 xor Wt-3
Таблица 8. Сравнение MD5 и SHA1
| Дайджест | MD5 | SHA1 |
| Длина дайджеста | 128 бит | 160 бит |
| Размер блока обработки | 512 бит | 512 бит |
| Количество итераций | 64 (4 по 16) | 80 |
| Количество эл. лог. ф-ий | 4 | 3 |
| Количество доп. констант | 64 | 4 |
Реализация MD4, MD5, SHA1:
C++; OpenSSL; Java; java.security; System.Security.Cryptography
МЕТОДЫ ХРАНЕНИЯ И СЖАТИЯграфической информации. Форматы графических файлов
Изображение на экране монитора формируется из маленьких квадратиков (иногда их называют точками) - пикселей. В зависимости от типа монитора и видеокарты количество таких точек на экране может быть разной. Современные видеокарты обеспечивают разрешение 1024 на 768 пикселей и более. Каждому пикселю соответствуют один или несколько байтов видеопамяти, задающие атрибуты пикселя: цвет, яркость. Итак, изображение на экране - это массив в видеопамяти, каждый элемент которого содержит значение атрибутов для одного пикселя.
Все графические файлы можно разделить на два больших класса: растровые файлы и векторные.
Растровое изображение - это изображение, составленное с помощью отдельных точек.
Векторное изображение - изображение, составленное из группы более сложных объектов и представленное с помощью их описания.
Изображение, построенное с помощью отдельных точек - пикселей, называется растровым. Реально изображение делится на квадратики (пиксели) и данные о каждом из них кодируются. Такая схема уже много веков назад была придумана для вышивания узоров крестиком. Заметим, что растровые рисунки в компьютерах имеют прямоугольную форму: к любому изображению прилагается фон, превращает рисунок в прямоугольник. Не зная размера пикселя, нельзя построить изображение на основе закодированных данных. На практике используют не размер пикселя, а задают ширину и высоту (в пикселях, в сантиметрах или в других единицах) рисунка и его разрешения.
Разрешение экрана - это плотность размещения пикселей. Она зависит от качества кинескопа монитора. Принятой единицей измерения разрешения является количество точек на дюйм - dpi (Dot Per Inch). При отображении рисунков на мониторе, используют разрешение от 72 dpi до 120 dpi. При печати распространенным разрешением для вывода текста является 300 dpi, но для высококачественной печати можно использовать и более разрешение (1440 dpi).
Устройства, которые формируют изображение из отдельных точек, называются растровыми. Видеомонитор, матричный и лазерный принтеры являются растровыми устройствами.
Недостатки растровых изображений:
· Плохое масштабирование. При уменьшении изображения несколько соседних точек превращаются в одну, потому теряются мелкие подробности. При увеличении масштаба происходит увеличение размера каждой точки, из-за чего происходит ступенчатый эффект.
· Большой размер файла, поскольку включены данные про каждый пиксель изображения.
ФОРМАТ BMP
Формат bmp (от слов BitMaP - битовая карта, или, битовый массив) представляет собой несжатое изображение. Оно достаточно легко читается и выводится в ОС Windows, поскольку в нее включены специальные функции API, которые в этом помогают.
По решению разработчиков формат Bmp файла не привязан к конкретной аппаратной платформе. Этот файл состоит из четырех частей: заголовка, информационного заголовка, таблицы цветов (палитры) и данных изображения. Если в файле хранится изображение с глубиной цвета 24 бита (16 млн. цветов), то таблица цветов может отсутствовать.
Заголовок файла начинается с сигнатуры "BM", а затем идет длина файла, выраженная в байтах. Следующие 4 байта зарезервированы для дальнейших расширений формата, а заканчивается этот заголовок смещением от начала файла до записанных в нем данных изображения. При 256 цветах это смещение составляет 1078.
Информационный заголовок начинается с собственной длины (она может меняться, но для 256-цветного файла составляет 40 байт) и содержит размеры изображения, разрешение, характеристики представления цвета и другие параметры.
Ширина и высота изображения задаются в точках растра и объяснений, пожалуй, не требуют.
Количество плоскостей могло применяться в файлах, имеющих небольшую глубину цвета. При количестве цветов 256 и больше оно всегда равняется 1, поэтому сейчас это поле уже можно считать устаревшим, но для совместимости оно сохраняется.
Глубина цвета считается важнейшей характеристикой способа представления цвета в файле и измеряется в битах на точку. В данном случае она равна 8.
Компрессия. В Bmp-файлах обычно не используется, но поле в заголовке для нее предусмотрено. Обычно она равна 0, и это означает, что изображение несжатое. В дальнейшем будем использовать только такие файлы.
Размер изображения - количество байт памяти, требуемых для хранения этого изображения, кроме данных палитры.
Горизонтальное и вертикальное расширение измеряются в точках растра на метр. Они особенно важны для сохранения масштаба отсканированных картинок. Изображения, созданные с помощью графических редакторов, как правило, имеют в этих полях нули.
Количество цветов позволяет сократить размер таблицы палитры, если в изображении реально присутствует меньше цветов, чем это допускает выбранная глубина цвета. Однако на практике такие файлы почти не встречаются. Если количество цветов приобретает значение, максимально допустимого глубиной цвета, например, 256 цветов при 8 битах, поле становится нулевым.
Количество основных цветов - идет с начала палитры, и его желательно выводить без искажений. Это поле бывает важным тогда, когда максимальное количество цветов дисплея было меньше, чем в палитре Bmp-файла. При разработке формата, очевидно, принималось, что цвета, которые чаще всего встречаются, будут располагаться в начале таблицы. Сейчас это требование практически не соблюдается, то есть цвета не упорядочиваются по частоте, с которой они встречаются в файле. Это очень важно, поскольку палитры двух разных файлов, даже состоящих из одних и тех же цветов, удерживали бы их (цвета) в разном порядке, что могло существенно осложнить одновременный вывод таких изображений на экран.
Вслед за информационным заголовком следует таблица цветов, является массивом из 256 (по числу цветов) 4-байтовых полей. Каждое поле соответствует своему цвету в палитре, а три байта из четырех - компонентам синей, зеленой и красной составляющих для этого цвета. Последний, самый старший байт каждого поля зарезервирован и равен 0.
После таблицы цветов находятся данные изображения, которое по строкам растра записано снизу вверх, а внутри строки - слева направо. Поскольку на некоторых платформах невозможно считать единицу данных, которая меньше 4 байт, длина каждой строки выровнена на границу в 4 байта, то есть при длине строки, некратной четырем, она дополняется нулями. Это обстоятельство обязательно нужно учитывать при считывании файла, хотя, возможно, лучше заранее позаботиться, чтобы горизонтальные размеры всех изображений были кратны 4.
СТРУКТУРА BMP-ФАЙЛА
Таблица 9. Структура BMP-файла.
| Имя | Длина | Смещение | Описание |
| Заголовок файла (BitMapFileHeader) | |||
| Type | 2 | 0 | Сигнатура «BM» |
| Size | 4 | 2 | Размер файла |
| Reserved 1 | 2 | 6 | Зарезервировано |
| Reserved 2 | 2 | 8 | Зарезервировано |
| OffsetBits | 4 | 10 | Смещение изображения от начала файла |
| Информационный заголовок (BitMapInfoHeader) | |||
| Size | 4 | 14 | Длина заголовка |
| Width | 4 | 18 | Ширина изображения, точки |
| Height | 4 | 22 | Высота изображения, точки |
| Planes | 2 | 26 | Количество плоскостей |
| BitCount | 2 | 28 | Глубина цвета, бит на точку |
| Compression | 4 | 30 | Тип компрессии (0 – несжатое изображение) |
| SizeImage | 4 | 34 | Размер изображения, байт |
| XpelsPerMeter | 4 | 38 | Горизонтальное расширение, точек на метр |
| YpelsPerMeter | 4 | 42 | Вертикальное расширение, точек на метр |
| ColorsUsed | 4 | 46 | Количество цветов, которые используются (0 – максимально возможное для данной глубины цвета) |
| ColorsImportant | 4 | 50 | Количество основных цветов |
| Таблица цветов (палитра) (ColorTable) | |||
| ColorTable | 1024 | 54 | 256 элементов по 4 байта |
| Данные изображения (BitMap Array) | |||
| Image | Size | 1078 | Изображение, которое записано по строкам слева направо и снизу-вверх. |
ФОРМАТ GIF
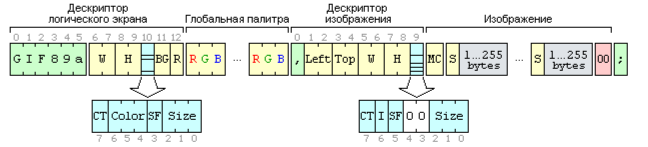
Рисунок 11. Минимально необходимый набор блоков – самый простой не анимированный gif.
Таблица 10. Таблица для разных глубин цвета изображения.
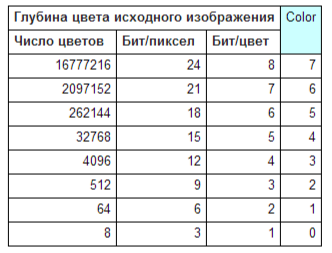
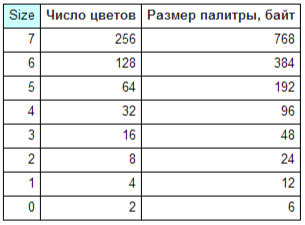
Таблица 11. Таблица для разных размеров палитр и количества цветов картинки
СЖАТИЕ РАСТРОВЫХ ИЗОБРАЖЕНИЙ
Пиксель является неразделимой точкой в графическом изображении растровой графики на экране монитора. Он характеризуется прямоугольной формой и размерами, определяющих пространственное разрешение изображения. Беда растровых файлов в том, что они большие, даже очень большие. Если пренебречь заголовками файла и другими неграфические данными, его размер пропорционален количеству пикселей в изображении и количеству битов, необходимых для представления каждого пикселя. Полноцветная картинка размером 1024х768 пикселей занимает более двух мегабайт памяти. Используя метод, называемый сжатием изображений, можно резко уменьшить в размере графические файлы. Существует два способа сжатия:
1. Без потерь информации
2. С потерями.
Если мы сохраняем чертежи, то, естественно, что сжатие с потерями нас не устроит, сохраняя же какую-то картинку, обобщения оттенков ее цветов вполне допустимо, а иногда приводит и к удачным спецэффектам.
Краткое описание формата GIF:
GIF один из самых распространенных и популярных в Интернете форматов изображений. Такое широкое распространение GIF во многом определяется особенностями его формата
Общие данные:
• Размер картинки-от 1х1 до 65535х65535 пикселей.
• Количество цветов палитры - от 2 до 256.
• Каждый цвет палитры имеет глубину 24 бита / пиксель (выбор из 16000000 цветов).
• Карта прозрачности - 1-битная (полупрозрачных цветов нет).
• Количество повторов анимации - от 1 до 65535, а также бесконечное.
• Время показа одного кадра анимации - от 1/100 секунды до 655 секунд.
• Количество кадров анимации – неограниченное
• Количество невидимых текстовых комментариев и размер каждого комментария – неограниченно.
Структура GIF-файла:
1. Файлы формата GIF имеют блочную структуру. Это означает, что онисостоят из отдельных блоков, которые в большинстве случаев никак не связаны друг с другом. Программы, не распознают некоторые типы блоков, могут просто пропускать их - для этого у каждого нестандартного блока в заголовке указан его размер. Блоки графики (картинки), идущие один за другим, составляют анимацию. Они меняются на экране и создают иллюзию движения. До или после них (или даже между ними) в файле могут находиться другие блоки:
1. Комментарии. Скрытый текст, его можно увидеть только с помощьюспециальных программ - например, GIF-аниматоров, таких, как UleadGIFAnimator.
2. Простой текст. Строки символов с ограниченными возможностями форматирования. Сейчас не используется.
3. Блоки управления графикой, задающие параметры вывода отдельных картинок.
4. Глобальная и локальные палитры цветов, определяющих, какие именно цвета будут у картинок.
5. Особые блоки, которые могут использоваться только теми программами, которыезнают об их существовании и назначения - например, блок Netscape, задает количество циклов анимации. Без него анимация после загрузки страницы срабатывает только один раз.
Минимальный необходимый набор блоков для простогонеанимированного GIF (смотреть рис. 11):
1. Дескриптор логического экрана.
2. Глобальная палитра.
3. Дескриптор изображения.
4. Изображение.
В начале каждого файла GIF находится заголовок. поскольку сразу за ним идет дескриптор логического экрана, заголовок считается его частью. Он состоит из текста "GIF87a" или "GIF89a", в зависимости от версии
Дескриптор - это просто "описатель" или "описание". Логический экран - область реального экрана компьютера, куда выводятся все картинки данного файла GIF. Они могут иметь разный размер и занимать различное положение налогическом экране. W, H - ширина и высота логического экрана в пикселях, то есть размер области вывода картинок. Изображения, которые не умещаются налогическом экране, должны обрезаться по его размеру.
BG - номер цвета фона. Если в файле присутствует глобальная палитра, то этим цветом заливаются области фона, где нет картинок. Но если при этом в первом, еще до всех картинок, расширении управления графикой включена прозрачность, то этот цвет считается прозрачным.
R - соотношение сторон исходного изображения. В версии GIF87a это поле зарезервировано, и здесь стоят нули. Насколько известно, этот параметр никогда и никем не используется. Предполагалось, что пиксель экрана может быть и не квадратным, как было в старых компьютерах и как сейчас бывает при некоторых режимах DOS, и для вывода таких изображений необходимо менять разрешение экрана или растягивать изображение так, чтобы оно выглядело реалистичным.
CT - наличие глобальной палитры. Если этот флажок установлен,
то сразу после дескриптора глобального экрана должна начинаться
глобальная палитра. Размер палитры определяется полем Size.
Color - цветовое разрешение начальной картинки. Число битов,
приходится на каждый из трех основных цветов. Если файл GIF создан
непосредственно с полноцветного изображения, то Color равно 7, а
если с уже индексированного, то его значение будет зависеть от глубины цвета
этой индексированной картинки, причем очень приблизительно. Например, если файл
создан на основе 16-цветной картинки, то Color должно быть равным 1, и начальная палитра должна равняться 1, начальная палитра предполагается 64 цветной.
 - флажок сортировки палитры. В версии GIF87a этот бит зарезервирован, и здесь стоит ноль. Указывает, отсортированная палитра по значимости цветов, когда первыми идут наиболее значимые цвета. Значимость цвета определяется тем, какую площадь изображения он занимает по отношению к другим цветам.
- флажок сортировки палитры. В версии GIF87a этот бит зарезервирован, и здесь стоит ноль. Указывает, отсортированная палитра по значимости цветов, когда первыми идут наиболее значимые цвета. Значимость цвета определяется тем, какую площадь изображения он занимает по отношению к другим цветам.
 - размер палитры и количество цветов картинки. если флажок глобальной палитры
- размер палитры и количество цветов картинки. если флажок глобальной палитры
 сброшен, то должны стоять нули.
сброшен, то должны стоять нули.
Глобальная палитра
Изображения, хранящиеся в файле GIF, индексированные. картинки состоят не из полноцветных пикселей, а из номеров цветов, а сами цвета находятся в палитре. Палитра составлена из триад, в свою очередь состоят из байтов красного  , зеленого
, зеленого  и синего
и синего  основных цветов. Из всего разнообразия цветов (современные компьютеры и мониторы могут показывать на экране до 16 миллионов цветов) используется только от 2 до 256. Возведение числа цветов к минимуму без значительного ухудшения качества изображения и без потери информации - сродни искусству, и автоматизации поддается плохо. Многие графические редакторы - такие как Adobe Photoshop, например - позволяют интерактивно выбрать лучший вариант индексации картинки «на глаз»
основных цветов. Из всего разнообразия цветов (современные компьютеры и мониторы могут показывать на экране до 16 миллионов цветов) используется только от 2 до 256. Возведение числа цветов к минимуму без значительного ухудшения качества изображения и без потери информации - сродни искусству, и автоматизации поддается плохо. Многие графические редакторы - такие как Adobe Photoshop, например - позволяют интерактивно выбрать лучший вариант индексации картинки «на глаз»
Если она есть, глобальная палитра идет сразу за дескриптором логическогоэкрана. Наличие палитры определяется флагом  дескриптора, а размер – полем
дескриптора, а размер – полем  Глобальная палитра действует на все картинки, в которых нет своей локальной палитры. В том аварийном случае, если в файле нет не глобальной, не локальных палитр, программа просмотра может действовать по своему усмотрению - например, использовать системную палитру. Однако рекомендуется, чтобы первые два цвета в ней черными и белыми, чтобы в любом случае на экран вывелось хоть что-то.
Глобальная палитра действует на все картинки, в которых нет своей локальной палитры. В том аварийном случае, если в файле нет не глобальной, не локальных палитр, программа просмотра может действовать по своему усмотрению - например, использовать системную палитру. Однако рекомендуется, чтобы первые два цвета в ней черными и белыми, чтобы в любом случае на экран вывелось хоть что-то.
Дескриптор изображения
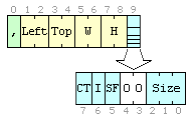
Действует на графический блок (картинку), что идет за ним. Без него картинка выводится не будет, так что его можно считать неотъемлемой частью графического блока. Между дескриптором и блоком графики может находиться только локальная палитра.
 - ширина и высота картинки в пикселях.
- ширина и высота картинки в пикселях.
 - положение картинки на логическом экране.
- положение картинки на логическом экране.
 - наличие локальной палитры. Если этот флажок установлен,то сразу после дескриптора изображения должно начинаться локальная палитра. Размер палитры определяется полем
- наличие локальной палитры. Если этот флажок установлен,то сразу после дескриптора изображения должно начинаться локальная палитра. Размер палитры определяется полем 
 - чересстрочная или обычная развертка картинки при выводе на экран. При скачивании картинки из Интернета чересстрочная развертка позволяет быстрее получить первое впечатление о картинке, хотя оно будет еще недостаточно четким. Однако файлы с чересстрочная разверткой немного больше по размеру, а при просмотре в отключенном режиме такие картинки могут выводиться медленнее.
- чересстрочная или обычная развертка картинки при выводе на экран. При скачивании картинки из Интернета чересстрочная развертка позволяет быстрее получить первое впечатление о картинке, хотя оно будет еще недостаточно четким. Однако файлы с чересстрочная разверткой немного больше по размеру, а при просмотре в отключенном режиме такие картинки могут выводиться медленнее.
 - флажок сортировки палитры. В версии GIF87a этот бит зарезервирован, и здесь стоит ноль. Указывает, отсортированная палитра по значимости цветов, когда первыми идут наиболее значимые цвета. значимость цвета определяется тем, какую площадь изображения он занимает по отношению к другим цветам.
- флажок сортировки палитры. В версии GIF87a этот бит зарезервирован, и здесь стоит ноль. Указывает, отсортированная палитра по значимости цветов, когда первыми идут наиболее значимые цвета. значимость цвета определяется тем, какую площадь изображения он занимает по отношению к другим цветам.
 - размер глобальной палитры и число цветов картинки (см. выше). Если флажок локальной палитры
- размер глобальной палитры и число цветов картинки (см. выше). Если флажок локальной палитры  сброшен, то должны стоять нули.
сброшен, то должны стоять нули.
Локальная палитра
Если она есть, должна идти сразу за дескриптором изображения. Наличие палитры обозначается флажком  , а размер – полем
, а размер – полем  . Действует она только на тот графический блок (картинку), который идет сразу за ней.
. Действует она только на тот графический блок (картинку), который идет сразу за ней.
Для уменьшения размера файла лучше ограничиться одной глобальной палитрой, не прибегая к локальным - особенно, если речь идет о многоцветных картинках. Максимальный размер палитры при 256 цветах - 768 байт, а если умножить на число картинок в анимации, то сумма набегает солидная.
Графический блок
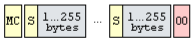
Картинка, сжатая с помощью метода LZW. Она разбита на отдельные субблоки по 255 байт. Число картинок в файле, как и размер каждой картинки, ничем не ограничены. Анимированным GIF становится в том случае, если в нем больше одной картинки. Тогда при просмотре файла в браузере автоматически включается анимация.
MC - начальный размер LZW-кода. Равный глубине цвета картинки, исключая двухцветные, когда MC равен не 1, а 2.
Таблица 12. Начальный размер LZW-кода
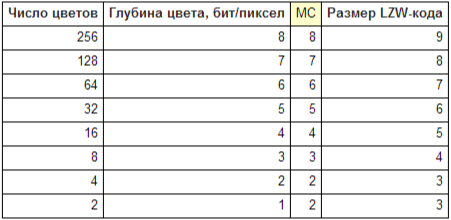
S - размер субблока данных, не включая сам байт S. Во всех субблоках, кроме последнего, размер должен быть равен 255 байт. У последнего субблока (или если он вообще один) размер может быть любым - от 1 до 255 байт.
Расширение управления графикой
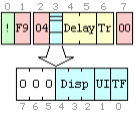
Введено в версии GIF89a. Действует на первый же графический блок (картинку), что идет за ним. Между ним и блоком графики могут быть вставлены другие блоки (например, комментарий) - это его работе не мешает.
Delay - время задержки, в 1/100 сек. Время, в течение которого эта картинка остается на экране. Минимальное значение - 1/100 секунды, максимальное - примерно 655 секунд. Таймер начинает отсчет только после того, как картинка выведена на экран, поэтому в различных программах просмотра время задержки может существенно различаться. Например, если попытаться сделать анимированный GIF - часы, то они могут, в зависимости от браузера, в минуту спешить или отставать более чем на секунду.
Tr - номер прозрачного цвета. Если есть локальная палитра, это номер цвета в ней, если же локальной палитры нет, то это номер цвета в глобальной палитре.
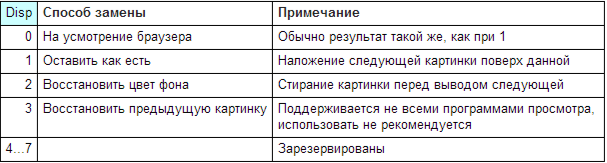
Disp - способ замены картинки после показа:
Таблица 13. Способ замены картинки
UI - ожидается реакция пользователя. Еще один никогда и никем не используемый параметр. Предполагалось, что если этот флажок установлен, то после вывода этой картинки для продолжения анимации и вывода следующих необходимо, например, щелкнуть кнопкой мыши.
TF - флажок прозрачности. Если он установлен, эта картинка выводится с прозрачным фоном, цвет которого определяется параметром Tr.
Расширение простого текста

Введено в версии GIF89a. Предполагалось, что вместе с картинками будут передаваться текстовые сообщения, появляющиеся на экране в паузах между ними или поверх них. Поскольку символы больше 0xF7 не выводимы (заменяются на пробелы), это делает расширение непригодным для вывода символов кириллицы (русских букв). Сейчас все тексты в файлах GIF идут в виде картинок, так что это расширение никогда и никем не используется.
Left, Top-положение области текста на логическом экране.
W, H - размер области текста. Строки, которые выходят за ее рамки, обрезаются. Переводы строки должны быть заранее вставлены в текст.
cW, cH - размер символов. Рекомендуется использовать значение 8х8 или 8х16 пикселей, что сейчас годится только для DOS.
FG - номер цвета текста.
BG - номер цвета фона. Этим цветом заливаются области фона, где нет текста.
S - размер субблока данных, не включая сам байт S. Во всех субблоков, кроме последнего, размер должен быть равен 255 байт. У последнего субблоков (или если он вообще один) размер может быть любым - от 1 до 255 байт.
Расширение комментария
Введено в версии GIF89a. В основном сюда записывают данные об авторских правах создателей файла GIF - и людей, и программ. Длинный текст можно ожидать в том случае, если программа бесплатная или условно бесплатная. Длина текста ничем не ограничивается.
S - размер субблока данных, не включая сам байт S. Во всех субблоков, кроме последнего, размер должен быть равен 255 байт. У последнего субблоков (или если он вообще один) размер может быть любым - от 1 до 255 байт.
Расширение дополнения

Введено в версии GIF89a. Расширение приложения - это специальные блоки данных - не картинки и не текст. С ними могут работать только те программы (приложения), для которых они предназначены. Крупнейшим известным стало расширение приложения Netscape, которое описывается ниже.
ID - идентификатор приложения. Текст из 8 символов, по которому программа просмотра определяет, сможет ли она прочитать данные, и которого они типа.
Code - код идентификатора. Предполагалось, что программа, которая создала GIF, будет синтезировать двоичный код для подтверждения своих прав на это расширение. На деле здесь тоже находится текст с 3 символов.
S - размер субблока данных, не включая сам байт S. Во всех субблоках, кроме последнего, размер должен быть равен 255 байт. У последнего субблока (или если он вообще один) размер может быть любым - от 1 до 255.
Расширение дополнения NetScape

Должен идти сразу после глобальной палитры (если она есть) или дескриптора логического экрана (если ее нет). Единственная цель этого расширения - установить количество циклов анимации. Как можно догадаться, первым применением, которое могло использовать эту информацию, был браузер Netscape 2.0. Сейчас это расширение присутствует почти во всех файлах GIF, где есть анимация.
? - Здесь стоит 0x01, но это значит, неизвестно. Возможно, сначала этот байт предполагалось использовать, но затем он оказался ненужным.
Loop - количество циклов анимации, от 0 до 65535. Здесь есть некоторые особенности. Во-первых, без расширения Netscape цикл анимации срабатывает, но только один раз. Если же вставить расширения Netscape в файл и установить Loop = 1, то цикл будет прокручиваться дважды, как и при Loop = 2. А при Loop = 0 анимация крутится бесконечно, так что ее отключения, для того, чтобы выводилась только одна первая картинка, в любом случае оказывается невозможным.
Вывод
Может показаться, что формат GIF со своими 256 цветами уже окончательно устарел, однако по сравнению с другой техникой вывода изображений он даже может в чем-то и выигрывать. Например, применение для создания анимированных кнопок и баннеров вместо картинок GIF техники Flash предполагает, что на каждом браузере установлен плагин Flash или элемент ActiveX Flash нужной версии. Это может в отдельных случаях привести к тому, что пользователи не только не смогут увидеть рекламу, но и вообще не смогут попасть на этот сайт, тогда как поддержка GIF встроена во все браузеры, начиная с самых первых версий.
Формат PNG, который завоевывает все большую популярность, при всех своих неоспоримых плюсах (полноцветная картинка, прозрачность с альфаканалом), не может обеспечивать такого сильного сжатия малоцветных изображений, не говоря уже об анимации. Его анимированная модификация MNG пока не поддерживается ни одним браузером. Другие новые форматы - такие, как JPEG 2000 - ориентированы в основном на фотографические изображения и не составляют серьезной конкуренции формату GIF, тем более что пройдет еще много времени, пока браузеры во всем мире будут пользоваться поддержкой этих новых форматов. В настоящее же время GIF, вместе с JPEG, остается одним из двух основных форматов изображений, используемых в Интернете, и, скорее всего, будет служить нам еще долго.
АЛГОРИТМ JPEG
В алгоритме JPEG исходное изображение представляется двумерной матрицей размера N * N, элементами которой являются цвет или яркость пикселя. Упаковка значений матрицы выполняется в три этапа.
· Дискретное косинусное преобразование
· Этап Квантования
· Этап Вторичного сжатия
Высокая эффективность сжатия, которую дает этот алгоритм, основана на том факте, что в матрице частотных коэффициентов, которая образуется из исходной матрицы после дискретного косинусного преобразования, низкочастотные компоненты расположены ближе к левому верхнему углу, а высокочастотные - внизу справа. Это важно потому, что большинство графических образов на экране компьютера состоит из низкочастотной информации, так что высокочастотные компоненты матрицы можно безболезненно выбросить. «Выброс» выполняется путем округления частотных коэффициентов. После округления отличные от нуля значения низкочастотных компонент остаются, главным образом, в левом верхнем углу матрицы. Округленная матрица значений кодируется с учетом повторов нулей. В результате графический образ сжимается более чем на 90%, теряя очень немного в качестве изображения только на этапе округления.
Дата добавления: 2018-04-05; просмотров: 655; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!