Методы сравнения с образцом (case based reasoning)
В методах данной группы объекты рассматриваются как прецеденты и используется только одна операция — определение сходства (различия) этих прецедентов с неизвестным объектом. Сходство (различие) выражается геометрически через расстояние в p‑мерном пространстве признаков . В зависимости от условий конкретной задачи роль отдельного прецедента может меняться в широких пределах от главной до весьма косвенного участия. Этим объясняется дальнейшее разделение данной группы методов на подклассы.
Метод сравнения с прототипом
Это самый простой метод. Он применяется тогда, когда классы объектов wi отображаются в пространстве признаков компактными геометрическими группировками. В таком случае обычно в качестве точки — прототипа выбирается центр геометрической группировки класса (или ближайший к центру объект), определяемый как

где Ni — количество объектов в классе wi.
Для классификации неизвестного объекта x находится ближайший к нему прототип, и объект относится к тому же классу, что и этот прототип.

Рис. 6. 20. Иллюстрация метода сравнения с прототипом
В качестве меры близости могут применяться различные меры расстояний. Например, для определения расстояния между объектом x и прототипом i‑го класса zi используют квадрат евклидова расстояния
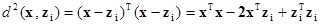 .
.
Так как xTx не зависит от класса, то этот член можно из приведенного выражения устранить. Тем самым, умножив оставшуюся часть на –1/2, получим правило классификации, эквивалентное линейной решающей функции (Рис. 6. 20)
|
|
|
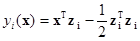 .
.
Указанный факт следует особо отметить. Он наглядно демонстрирует связь прототипной и признаковой репрезентации знаний о структуре данных. Пользуясь приведенным представлением можно любую линейную решающую функцию (линейную модель) рассматривать как гипотетический прототип. В свою очередь, если анализ пространственной структуры классов позволяет сделать вывод об их геометрической компактности, то каждый из этих классов достаточно заменить одним прототипом, который эквивалентен линейной модели классификации объектов.
На практике, конечно, ситуация часто бывает отличной от описанного идеализированного примера. Перед аналитиком, намеревающимся применить метод классификации объектов БД, основанный на сравнении с прототипами классов, встают непростые проблемы. Это, в первую очередь, выбор меры близости (метрики), от которого может существенно измениться пространственная конфигурация распределения объектов. И, во‑вторых, самостоятельной проблемой является анализ многомерных структур данных. Обе проблемы особенно остро заявляют о себе в условиях высокой размерности и неоднородности пространства признаков.
|
|
|
Метод k‑ближайших соседей
Как уже отмечалось на четвертом уроке, метод k‑ближайших соседей для решения задач дискриминантного анализа был впервые предложен /Fix E. et al., 1952/. Он заключается в следующем.
При классификации неизвестного объекта x находится заданное количество k геометрически ближайших к нему объектов (ближайших соседей) с известной классификацией. Решение об отнесении объекта x к тому или иному классу принимается путем анализа информации об этой известной принадлежности его ближайших соседей, например, с помощью простого подсчета голосов.
Первоначально метод k‑ближайших соседей (k‑БС) рассматривался как непараметрический метод оценивания отношения правдоподобия в окрестности x. Для этого метода получены теоретические оценки его эффективности в сравнении оптимальным байесовским классификатором. Так, для случая k = 1 в /Cover T. et al., 1967/ была доказана следующая теорема.
Пусть PN — вероятность сделать по правилу первого ближайшего соседа (1‑БС) в выборке X объема N. Тогда при распознавании двух классов в предположении, что из X делаются независимые случайные выборки с возвращением
|
|
|
 ,
,
где 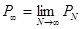 ;
;
P* — риск ошибочной классификации любого случайным образом выбранного объекта при использовании неизвестного байесовского метода оптимальной классификации.
В работе /Дуда Р. и др., 1976/ приведен аналогичный результат для K классов
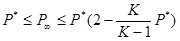 .
.
Приведенные выражения показывают, что асимптотические вероятности ошибки для правила 1‑БС превышают ошибки правила Байеса не более чем в два раза.
Для многих реальных задач искусственного интеллекта, когда объекты описываются большим количеством разнородных признаков (в том числе качественных и номинальных), удобно интерпретировать каждый объект обучающей выборки как отдельный линейный классификатор. Тогда тот или иной класс представляется не одним прототипом, а набором линейных классификаторов. Их совокупное взаимодействие дает в итоге кусочно‑линейную поверхность, разделяющую классы в пространстве признаков. Вид такой поверхности, состоящей из кусков гиперплоскостей, может быть разнообразным и зависит от конфигурации классифицируемых совокупностей объектов (Рис. 6. 21).
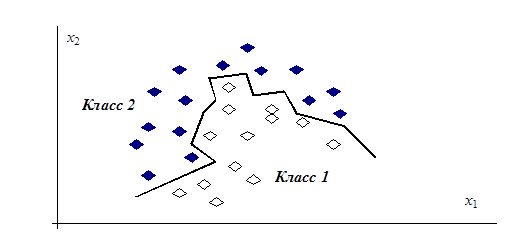
Рис. 6. 21. Пример кусочно‑линейной разделяющей границы для метода k‑ближайших соседей
При использовании метода k‑ближайших соседей для классификации объектов приходится решать сложную задачу выбора метрики. Эта проблема обостряется в условиях высокой размерности данных вследствие достаточной трудоемкости метода. Поэтому здесь, как и в методе сравнения с прототипом, необходимо решать творческую задачу анализа многомерной структуры экспериментальных данных с целью минимизации числа объектов, представляющих свои классы.
|
|
|
Алгоритмы вычисления оценок
Принцип действия алгоритмов вычисления оценок (АВО) состоит в вычислении приоритетов (оценок сходства), характеризующих «близость» классифицируемого и эталонных объектов по системе ансамблей признаков, представляющей собой систему подмножеств заданного множества признаков /Журавлев Ю. И., 1976; 1978; Журавлев Ю. И. и др., 1990/.
В отличие от ранее рассмотренных методов алгоритмы вычисления оценок по‑новому оперируют описаниями объектов. Для АВО объекты существуют одновременно в самых разных подпространствах пространства признаков.
Используемые подпространства (сочетания признаков) называют опорными множествами или множествами частичных описаний объектов. Объекты обучающей выборки в АВО называют эталонными. Сходство между классифицируемым и эталонными объектами определяется через так называемую «обобщенную близость». Эта близость представляется комбинацией близостей, вычисленных на множестве частичным описаний.
Задача определения сходства и различия объектов в АВО формулируется как параметрическая. Выделен этап настройки АВО по обучающей выборке, на котором подбираются оптимальные значения введенных параметров. Критерием качества служит ошибка классификации, а параметризуется буквально все. Сюда относятся правила вычисления близости объектов по отдельным признакам, правила вычисления близости объектов в подпространствах признаков, степень важности того или иного эталонного объекта и значимость вклада каждого опорного множества признаков в итоговую оценку сходства классифицируемого объекта с каким‑либо классом. Параметры АВО задаются в виде значений порогов и/или как веса указанных составляющих.
Теоретические возможности АВО не ниже возможностей любого другого алгоритма классификации, так как с помощью АВО могут быть реализованы все мыслимые операции с исследуемыми объектами. Но, как это обычно бывает, расширение потенциальных возможностей наталкивается на большие трудности их практического воплощения, особенно на этапе настройки АВО. Отдельные трудности отмечались при обсуждении метода k‑ближайших соседей, который можно рассматривать как усеченный вариант АВО. Для алгоритмов вычисления оценок указанные трудности возрастают многократно.
Литература
Андерсон Т. Введение в многомерный статистический анализ. — М.: Физматгиз, 1963.
Демиденко Е. З. Линейная и нелинейная регрессия. — М.: Финансы и статистика, 1981.
Дуда Р., Харт П. Распознавание образов и анализ сцен. — М.: Мир, 1976.
Енюков И. С. Методы, алгоритмы, программы многомерного статистического анализа: Пакет ППСА. — М.: Финансы и статистика, 1986.
Журавлев Ю. И., Гуревич И. Б. Распознавание образов и анализ изображений/Искусственный интеллект. — В 3‑х кн. Кн. 2. Модели и методы: Справочник/под ред. Д. А. Поспелова. — М.: Радио и связь, 1990.
Пфанцагль И. Теория измерений. — М.: Мир, 1976.
Григорьев С. Г., Перфилов А. М., Левандовский В. В., Юнкеров В. И.— STATGRAPHICS на персональном компьютере. — Санкт‑Петербург, 1992.
Cover T., Hart P. Nearest neighbour pattern classification//IEEE Trans. Inform. Theory, v. IT‑13, 1967. — p. 21—27.
Fix E., Hodges J. L. Discriminatory analysis, nonparametric discrimination USA School of Medicine. — Texas: Rendolph Field, 1951—1952.
Дата добавления: 2021-03-18; просмотров: 131; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!