Частотный анализ текстовой базы данных
Используемые математические понятия и обозначения
Таблица данных и обозначения
Любое практическое исследование на начальном этапе включает в себя стадию сбора данных. Да́нные (калька от лат. data) – это представление фактов и идей в формализованном виде, пригодном для передачи и обработки в некотором информационном процессе.
При систематизации данных, как правило, исследователь выделяет в системе объекты, сходные по природе и фиксирует у объектов свойства, с помощью которых он может определять их сходство и отличие в том или ином контексте. В результате возникает средство для представления и хранения собранных данных – таблица данных. В дальнейшем мы будем считать понятия данных и таблицы синонимами, считая, что все собранные материалы исследователь хранит в виде таблиц.
Разумеется, таблица данных может содержать данные не об исследуемых отдельных объектах или явлениях, а данные о состоянии одного и того же объекта, но в разных ситуациях или в разные моменты времени. Тогда следует говорить о различии в состоянии одного и того же объекта.
Будем представлять, согласно традициям и соображениям удобства, что каждой строке таблицы соответствует определенный объект или явление изучаемой системы, а в столбцах таблицы размещаются значения или метки признаков. В результате получается таблица экспериментальных данных (ТЭД).
В приведенной ниже таблице приняты следующие обозначения:
|
|
|
N – общее количество объектов (многомерных наблюдений, примеров, фактов, образцов);
p – общее количество признаков;
xj – "j"‑й признак (наряду с термином "признак" употребляются также термины "показатель", "переменная" и "атрибут");
xij – значение "j"‑го признака, измеренное у "i"‑го объекта.
В соответствии с данной символикой приняты также обозначения:
x = (x1, …, xp)T – вектор признаков (знак "т" означает транспонирование);
xi = (xi1, …, xip)T – "i"‑й объект;
X = { xi } – множество объектов.
Таблица 3.2. Таблица экспериментальных данных
| Объекты | Исходные признаки | |||||
| (наблюдения, факты, образцы и т. п.) | x1 | x2 | … | xj | … | xp |
| x1 | x11 | x12 | … | x1j | … | x1p |
| x2 | x21 | x22 | … | x2j | … | x2p |
| . | . | . | … | . | … | . |
| . | . | . | … | . | … | . |
| xi | xi1 | xi2 | … | xij | … | xip |
| . | . | . | … | . | … | . |
| . | . | . | … | . | … | . |
| xN | xN1 | xN2 | … | xNj | … | xNp |
Характерные примеры
Экономическая таблица
В журнале «Эксперт» ежегодно публикуются таблицы экономических показателей для двухсот самых крупных предприятий России. В числе таких показателей указываются валовый годовой доход, выраженный в рублях и долларах по среднегодовому курсу, темп роста предприятия, его балансовая прибыль до и после налогообложения, а также число работающих и некоторые производные характеристики, общепринятые в экономике, типа производительности предприятия. Кроме этого, указана территориальная и отраслевая принадлежность предприятия.
|
|
|
Таблица 3.3. Начальный фрагмент таблицы экономических показателей крупнейших предприятий России
| 1999 г. | 1998 г. | Компания | Регион | Отрасль | Объем реализации в 1998 г. (млн руб.)** | Темп роста (%) | Объем реализации в 1998 г. (млн долл.)*** | Балансовая прибыль за 1998 г. (млн руб.) | Прибыль после налогообложения за 1998 г. (млн руб.) | Количество работающих за 1998 г. (тыс. чел.) | Производительность труда (тыс. руб./чел.) |
| 1 | 1 | РАО «ЕЭС России»* | Электроэнергетика | 218802.1 | 2.0 | 22349.5 | 21534.3 | 16045.6 | 697.8 | 313.6 | |
| 2 | 2 | ОАО «Газпром»* | нефтяная и нефтегазовая промышленность | 171295.0 | 23.4 | 17496.9 | -22147.0 | -30119.0 | 278.4 | 615.3 | |
| 3 | 3 | Нефтяная компания «ЛУКойл»* | нефтяная и нефтегазовая промышленность | 81660.0 | 52.2 | 8341.2 | 2032.0 | 573.0 | 102.0 | 800.6 | |
| 4 | Башкирская топливная компания* | Башкирия | нефтяная и нефтегазовая промышленность | 33081.8 | –9.1 | 3379.1 | 1228.3 | 517.2 | 104.8 | 315.7 | |
| 5 | 4 | Сибирско-Дальневосточная нефтяная компания («Сиданко»)****** | нефтяная и нефтегазовая промышленность | 31361.8 | 0.9 | 3203.5 | 80.0 | 392.0 |
|
|
|
В дальнейшем мы познакомимся с этой таблицей поближе, а сейчас следует отметить некоторые характерные особенности данных, представленных в этой таблице:
- большая часть признаков таблицы измеряется числом – значением соответствующего показателя; все количественные признаки могут принимать любые вещественные значения в определенном диапазоне; мы можем сравнить два предприятия по значению того или иного признака (например, отметить, что темп роста ГазПрома больше, чем ЕЭС);
- данные неполны – значения некоторых признаков неизвестны или недостоверны по тем или иным причинам;
- один из признаков (валовый объем производства) для разных предприятий принимает значения, отличающиеся на порядки.
- некоторые признаки (например, принадлежность к отрасли) не являются числовыми по смыслу (их значения являются лишь метками);
Медицинская таблица
Весьма популярной для апробации различных методов анализа данных является так называемая таблица осложнений инфаркта миокарда. Некоторые исследователи, пробовавшие свои силы на этой таблице, утверждают, что она содержит большинство характерных трудностей и подводных камней, которые встречаются при анализе таблиц реальных (не модельных) данных. Число признаков в полном варианте таблицы – 128 (табл. 3.4)
|
|
|
Таблица 3.4 Фрагмент таблицы осложнений инфаркта миокарда
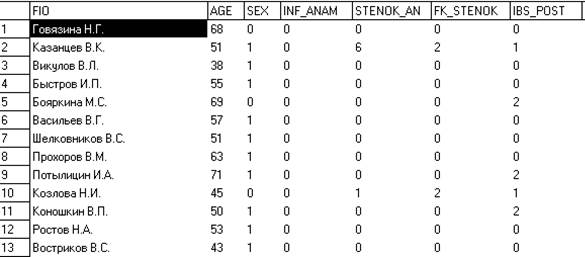 |
Как и в предыдущем случае отметим характерные черты такого набора данных.
Большая часть признаков – это бинарно закодированные ответы на вопросы, то есть единица соответствует ответу «да», ноль – «нет». Кроме этого, встречаются такие признаки, которые хоть и принимают целочисленные значения из определенного диапазона, но не имеет большого смысла сравнивать двух пациентов по величине таких признаков, то есть само числовое значение – это тоже всего лишь метка ответа на вопрос (когда ответов «да» и «нет» - недостаточно).
Данные мониторинга
Исследователь может по сути иметь дело с одним и тем же объектом, наблюдая его различные состояния. Весьма популярным объектом наблюдения является биржа ценных бумаг. Его состояние может быть охарактеризовано несколькими десятками различных параметров – финансовых индикаторов, которые изменяются ежедневно или даже ежеминутно.
В табл. 3.5 показано несколько состояний фондового рынка США, каждое из которых характеризуется значением и последним изменением шести основных финансовых индикаторов. Более подробная таблица включает значения нескольких сотен индексов.
Таблица 3.5. Основные фондовых индексов США
| Date | Time | Dow 30 Industrials | S&P 500 | Nasdaq Composite | AMEX Composite | Nyse Composite | |||||
| Value | Change | Value | Change | Value | Change | Value | Change | Value | Change | ||
| 21.07.2000 | 6.50PM | 10733.56 | -110.31 | 1480.19 | -15.38 | 4094.45 | -90.11 | 927.64 | -12.14 | 655.38 | -4.81 |
| 22.07.2000 | 6.50PM | 10628.51 | -105.05 | 1470.16 | -10.03 | 4014.14 | -80.31 | 917.58 | -10.06 | 650.35 | -5.03 |
| 23.07.2000 | 6.50PM | 10514.29 | -114.22 | 1465.01 | -5.15 | 4004.02 | -10.12 | 918.62 | +1.04 | 648.15 | -2.20 |
Частотный анализ текстовой базы данных
В случае, если предметом исследования является некоторая совокупность текстов (например, все статьи, опубликованные в журнале за десять лет), то содержание (естественно, не смысловое, а формальное) этих текстов можно представить в виде частотной таблицы.
Для составления такой таблицы сначала проводится полный частотный анализ всей текстовой базы и находятся наиболее часто употребляемые слова (как правило, при частотном анализе игнорируют различные варианты написания слов, то есть их окончания и т.д., а также выбрасывают заведомо бессодержательные, но часто употребляемые слова-связки). В результате составляется словарь из некоторого фиксированного набора наиболее часто употребляемых слов во всей совокупности текстов. Этот словарь и играет роль набора признаков, характеризующих каждый отдельный текст из базы. Каждый признак – это отдельное слово из словаря, его значение для конкретного текста – число, описывающее сколько раз данное слово было встречено в тексте.
В табл. 3.6 в качестве объектов выбраны разделы некоторой книги, которые описываются частотами некоторых самых распространенных в тексте книги слов.
В качестве характерной особенности данной таблицы укажем следующее:
- если текстовая база очень неоднородна по содержанию (например, база из всех статей UseNet), то для того, чтобы можно было охватить все темы, частотный словарь должен содержать достаточно много словоформ; необходимое число столбцов в частотной таблице может вырасти до тысячи; при этом сама частотная таблица окажется очень разреженной – будет содержать большое количество нулей.
Таблица 3.6. Результаты Частотного анализа содержания глав книги
на фоне двух других книг
| Текст | данн | точк | карт | модел | сетк | табл | визуал |
| Миркес Е.М. Нейрокомпьютер. Проект стандарта. | 0.006558 | 0.000822 | 0.000249 | 0.000000 | 0.014876 | 0.003212 | 0.000000 |
| Горбань А.Н. Демон Дарвина | 0.001367 | 0.000481 | 0.000751 | 0.009319 | 0.000154 | 0.000058 | 0.000019 |
| Визуализация данных. Глава 1 | 0.025356 | 0.003356 | 0.010938 | 0.007644 | 0.003356 | 0.004164 | 0.001678 |
| Визуализация данных. Глава 2 | 0.017673 | 0.004564 | 0.004467 | 0.004273 | 0.011750 | 0.000777 | 0.001457 |
| Визуализация данных. Глава 3 | 0.020914 | 0.000775 | 0.018203 | 0.000387 | 0.003098 | 0.009295 | 0.003486 |
Приведенный способ составления частотных таблиц достаточно широко применяется для автоматизированного составления каталога текстовых баз. Познакомиться с применениями такого подхода можно, например, в Интернете (http://websom.hut.fi).
Дата добавления: 2021-03-18; просмотров: 676; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!