Методы, применяемые для решения задач классификации
Для классификации используются различные методы:
1. классификация с помощью деревьев решений;
Метод деревьев решений для задачи состоит в том, чтобы осуществлять процесс деления исходных данные на группы, пока не будут получены однородные (или почти однородные) их множества. Процесс продолжается до тех пор, пока не выполнится критерий остановки. Это возможно в следующих ситуациях:
¾ Все (или почти все) данные данного узла принадлежат одному и тому же классу;
¾ Не осталось признаков, по которым можно построить новое разбиение;
¾ Дерево превысило заранее заданный «лимит роста» (если таковой был заранее установлен).
Совокупность правил, которые дают такое разбиение, позволят затем делать прогноз (т.е. определять наиболее вероятный номер класса) для новых данных.
Примеры задач классификации, решаемых методом деревьев:
¾ скоринговые модели кредитования (англ.: credit scoring models);
¾ маркетинговые исследования, направленные на выявление предпочтений клиента или степени его удовлетворённости – обычно эти сведения бывают востребованы маркетинговыми агентствами или рекламными компаниями;
¾ диагностика (медицинская или техническая), где по набору значений факторов (симптомов, результатов анализов) нужно поставить диагноз или сделать вывод о динамике процесса.
¾
2. байесовская (наивная) классификация;
"Наивной" она называется потому, что исходит из предположения о взаимной независимости признаков.
Свойства наивной классификации:
¾ Использование всех переменных и определение всех зависимостей между ними.
¾ Наличие двух предположений относительно переменных:
¾ все переменные являются одинаково важными;
¾ все переменные являются статистически независимыми, т.е. значение одной переменной ничего не говорит о значении другой.
¾
3. классификация методом опорных векторов;
Метод опорных векторов (Support Vector Machine - SVM) относится к группе граничных методов. Она определяет классы при помощи границ областей.
При помощи данного метода решаются задачи бинарной классификации.
В основе метода лежит понятие плоскостей решений.
Плоскость (plane) решения разделяет объекты с разной классовой принадлежностью.
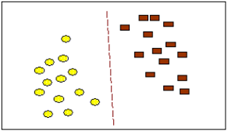
На рисунке приведен пример, в котором участвуют объекты двух типов. Разделяющая линия задает границу, справа от которой - все объекты типа brown (коричневый), а слева - типа yellow (желтый). Новый объект, попадающий направо, классифицируется как объект класса brown или - как объект класса yellow, если он расположился по левую сторону от разделяющей прямой. В этом случае каждый объект характеризуется двумя измерениями.
4. классификация при помощи метода ближайшего соседа;
Следует сразу отметить, что метод "ближайшего соседа" ("nearest neighbour") относится к классу методов, работа которых основывается на хранении данных в памяти для сравнения с новыми элементами. При появлении новой записи для прогнозирования находятся отклонения между этой записью и подобными наборами данных, и наиболее подобная (или ближний сосед) идентифицируется.
Например, при рассмотрении нового клиента банка, его атрибуты сравниваются со всеми существующими клиентами данного банка (доход, возраст и т.д.). Множество "ближайших соседей" потенциального клиента банка выбирается на основании ближайшего значения дохода, возраста и т.д.
5. статистические методы, в частности, линейная регрессия;
Математическое уравнение, которое оценивает линию простой линейной регрессии:
Y = a + bx
х – называется предиктором – независимой или объясняющей переменной.
Для данной величины х, Y — значение переменной у (называемой зависимой, выходной переменной, или переменной отклика), которое расположено на линии оценки. Это есть значение, которое мы ожидаем для у (в среднем), если мы знаем величину х, и называется она «предсказанное значение у» (рис. 5).
а – свободный член (пересечение) линии оценки; это значение Y, когда х = 0.
b – угловой коэффициент или градиент оценённой линии; он представляет собой величину, на которую Y увеличивается в среднем, если мы увеличиваем х на одну единицу (рис. 5). Коэффициент b называют коэффициентом регрессии.
Например: при увеличении температуры тела человека на 1оС, частота пульса увеличивается в среднем на 10 ударов в минуту.
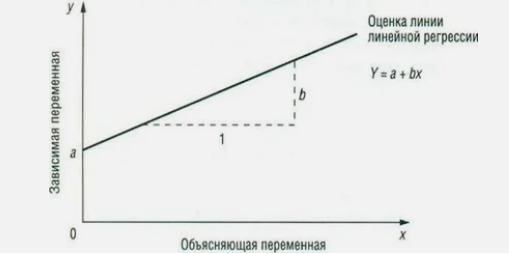
Рисунок 5. Линия линейной регрессии, показывающая коэффициент а и угловой коэффициент b (величину возрастания Y при увеличении х на одну единицу)
Математически решение уравнения линейной регрессии сводится к вычислению параметров а и b таким образом, чтобы точки исходных данных корреляционного поля как можно ближе лежали к прямой регрессии.
6. классификация при помощи искусственных нейронных сетей;
Искусственные нейронные сети как средство обработки информации моделировались по аналогии с известными принципами функционирования биологических нейронных сетей. Их структура базируется на следующих допущениях:
¾ обработка информации осуществляется во множестве простых элементов - нейронов;
¾ сигналы между нейронами передаются по связям от выходов ко входам;
¾ каждая связь характеризуется весом, на который умножается передаваемый по ней сигнал;
¾ каждый нейрон имеет активационную функцию (как правило, нелинейную), аргумент которой рассчитывается как сумма взвешенных входных сигналов, а результат считается выходным сигналом.
Таким образом, нейронные сети представляют собой наборы соединенных узлов, каждый из которых имеет вход, выход и активационную функцию (как правило, нелинейную). Они обладают способностью обучаться на известном наборе примеров обучающего множества. Обученная нейронная сеть представляет собой "черный ящик" (нетрактуемую или очень сложно трактуемую прогностическую модель), которая может быть применена в задачах классификации, кластеризации и прогнозирования.
7. классификация при помощи генетических алгоритмов.
Строго говоря, интеллектуальный анализ данных - далеко не основная область применения генетических алгоритмов, которые, скорее, нужно рассматривать как мощное средство решения разнообразных комбинаторных задач и задач оптимизации. Тем не менее, генетические алгоритмы вошли сейчас в стандартный инструментарий методов data mining. Этот метод назван так потому, что в какой-то степени имитирует процесс естественного отбора в природе.
Первый шаг при построении генетических алгоритмов — это кодировка исходных логических закономерностей в базе данных, которые именуют хромосомами, а весь набор таких закономерностей называют популяцией хромосом. Далее для реализации концепции отбора вводится способ сопоставления различных хромосом. Популяция обрабатывается с помощью процедур репродукции, изменчивости (мутаций), генетической композиции. Эти процедуры имитируют биологические процессы.
Генетические алгоритмы имеют ряд недостатков. Критерий отбора хромосом и используемые процедуры являются эвристическими и далеко не гарантируют нахождения “лучшего” решения. Как и в реальной жизни, эволюцию может “заклинить” на какой-либо непродуктивной ветви.
Дата добавления: 2020-04-25; просмотров: 420; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!