Развитие микропроцессоров семейства Intel.
- Первый принцип – разбивка всей области памяти микрокомпьютера на логические участки – сегменты.
Существуют два различных способа адресации памяти:
- Линейная адресация, которая предполагает последовательную адресацию памяти от адреса “0” до адреса 2n-1, где n – разрядность шины адреса.
- Сегментная адресация, где память логически разделена на участки называемые сегментами, внутри которых адресация – линейная. Любая локализация в памяти происходит относительно базы сегмента.
2. Другой принцип – формирование некоторой виртуальной памяти. Виртуальная память определяется как область памяти, которую может сформировать пользователь, расположив последовательно максимальное количество сегментов (каждый сегмент максимального размера) используя некоторый виртуальный адрес. Что интересно, объём виртуальной памяти может намного превосходить объём физической памяти микрокомпьютера. В область виртуальной памяти входят все ресурсы микрокомпьютера (как внутренние, так и внешние – диски, магнитная лента и т.д.).
3. Появляется механизм управления памятью. Он состоит в отображении виртуального адреса (используемого программистом) в физический адрес. Первым представителем семейства Intel, который применяет данный механизм, является Intel 80286. Он поддерживает виртуальное адресное пространство объёмом 1GВ, физически адресуемая память – 16MВ. Следующие микропроцессоры i386, i486, Pentium поддерживают виртуальное адресное пространство объёмом 64 GB. На рисунке 1 представлена функциональная блок-схема микропроцессора i286
|
|
|

| Рис. 1 функциональная блок-схема микропроцессора i286
В сравнении со схемой микропроцессора 8086 здесь появились два новых устройства:
|
Для i286 устройство декодирования команд поддерживает последовательность из трёх декодированных команд, готовых к исполнению (эти команды считываются из очереди команд (6В) которая находится в устройстве сопряжения с шиной). Четыре устройства выполняют свои функции одновременно, параллельно, что увеличивает производительность процессора.
4. Следующий принцип – многозадачность(“multitasking”), которая определяется, как способность компьютера исполнять несколько задач (“task”) одновременно, это осуществляется последовательным переключением с одной последовательности команд некоторой задачи (“task”) к другой последовательности, другой задачи и т.д. В итоге переключается к первой последовательности.
5. Важным следствием механизма управления памятью является механизм защиты.
Защита обладает тремя аспектами:
|
|
|
· контроль информации (коды или другие типы данных);
· разделение пользователей один от другого (защита “inter-task”);
· разделение системного software от прикладного (защита “intra-task”);
6. С точки зрения механизма защиты сегмент переопределяется как минимальная область (логическая) памяти с атрибутами защиты.
Для экономии объёма памяти необходимой для выполнения текущей задачи применяется следующий принцип – замена места задач (“swapping task”), который состоит во временном отправлении задачи (или часть задачи) во внешнюю память, если данная задача (или часть) не находится в исполнении в данный момент. Замена места некоторых сегментов взаимосвязана с методом компактирования программ путём точного определения базы сегментов кодов и данных

| Рис. 2. Замена места некоторых сегментов взаимосвязана с методом компактирования программ путём точного определения базы сегментов кодов и данных |
7. Механизм, который применяют практически все современный компьютеры это страничный механизм – разделение виртуальной памяти на фиксированные блоки называемые страницами. Многозадачность, а также метод замены места задач могут реализовываться страницами вместо сегментов. Оба метода, страничный механизм и сегментация памяти, применяются в следующих поколениях микропроцессоров Intel. Первым из них является i386.
|
|
|
Функциональная схема микропроцессора i386 (первый 32-х разрядный микропроцессоров) представлена на рис. 3.
В сравнении с i286 появляются новые устройства. Устройство декодирования команд разделяется на два устройства:
· Устройство предварительной выборки команд (“prefetch”) - поддерживает очередь команд, т.е. его функция состоит в извлечении из памяти последовательности команд и размещение их в регистрах очереди (16 байт). Команды переходов (или вызов подпрограмм) информируют устройство “prefetch” о необходимости извлечения команд с нового адреса.

| Рис. 3 Функциональная схема микропроцессора i386 (первый 32-х разрядный микропроцессоров) |
· Устройство предварительного декодирования (формат команд в случае i386 – от одного до 16 байт).
Устройство предварительной выборки загружает внутреннюю очередь команд, из которой они считываются устройством предварительного декодирования. Последнее, по коду команды, формирует 100-разрядную микрокоманду, которую заносит в очередь микрокоманд. Устройство управления и устройство обработки извлекают первую микрокоманду из очереди и обеспечивают её выполнение.
|
|
|
Физические адреса формируются блоком трансляции адресов, состоящим из двух устройств, поддерживающих страничную и сегментную организацию памяти. Допустимость обращения к памяти и портам ввода/вывода проверяется устройством защиты (которое находится в блоке трансляции адресов).
Между сегментным и страничным устройствами появляется новый тип адресов – линейный адрес, который рассмотрим далее.
8. Т.к. обращение к памяти становится сложным механизмом (виртуальный адрес→линейный адрес→физический адрес), то возникает необходимость в методах уменьшающих время доступа в память. Для этого применяется метод элементов скрытых структур (“cache”). Так Intel применяет регистры cache, которые дополняют (дублируют), невидимо для пользователя, информацию в сегментных регистрах (для полного определения сегментов в памяти вместе с атрибутами защиты), i386 содержит ассоциативную кэш-память (“translation lookaside buffer”- TLB), которая содержит адреса наиболее часто используемых 32 страниц, что существенно уменьшает время трансляции адресов, этапа: линейный адрес→физический адрес.
9. Следующий представитель: i486 имеет встроенную кэш-память размером 8kB. На рисунке 9.4 дана функциональная схема, на которой можно выделить его функциональные узлы отличные от i386 .
- модуль арифметического сопроцессора (Floating Point Unit - FPU);
- внутренняя кэш-память.

| Рис. 4 Функциональная схема |
Внутренняя кэш-память выполнена как ассоциативная и работает в режиме “write through”(т.е. данные заносятся и в кэш-память и в ОЗУ).
а) Суперскалярная архитектура. Для того чтобы пояснить этот термин, разберемся вначале со значением другого термина — конвейеризация вычислений. Важным элементом архитектуры, появившимся в i486, стал конвейер — специальное устройство, реализующее такой метод обработки команд внутри микропроцессора, при котором исполнение команды разбивается на несколько этапов, i486 имеет пятиступенчатый конвейер. Соответствующие пять этапов включают:
· выборку команды из кэш-памяти или оперативной памяти;
· декодирование команды;
· генерацию адреса, при которой определяются адреса операндов в памяти;
· выполнение операции с помощью АЛУ;
· запись результата (куда будет записан результат, зависит от алгоритма работы конкретной машинной команды).
Таким образом, на стадии выполнения каждая машинная команда как бы разбивается на элементарные операции. В чем преимущество такого подхода? Очередная команда после ее выборки попадает в блок декодирования. Таким образом, блок выборки свободен и может выбрать следующую команду. В результате на конвейере могут находиться в различной стадии выполнения пять команд. Скорость вычисления в результате существенно возрастает. Микропроцессоры, имеющие один конвейер, называются скалярными, а два и более — суперскалярными. Микропроцессор Pentium имеет два конвейера, то есть использует суперскалярную архитектуру, и поэтому может выполнять две команды за машинный такт. Внутренняя структура конвейера такая же, как и у i486. Микропроцессоры семейства Р6 (Pentium Рго/II/III) имеют другую структуру конвейера.
Блок-схема процессора Pentium представлена на рис. 5. Прежде всего, новая микроархитектура этого процессора базируется на идее суперскалярной обработки (правда с некоторыми ограничениями). Основные команды распределяются по двум независимым исполнительным устройствам (конвейерам U и V). Конвейер U может выполнять любые команды семейства x86, включая целочисленные команды и команды с плавающей точкой. Конвейер V предназначен для выполнения простых целочисленных команд и некоторых команд с плавающей точкой. Команды могут направляться в каждое из этих устройств одновременно, причем при выдаче устройством управления в одном такте пары команд более сложная команда поступает в конвейер U, а менее сложная - в конвейер V.

| Рис. 5. Упрощенная блок схема процессора Pentium |
Раздельное кэширование кода и данных. Кэширование — это способ увеличения быстродействия системы за счет хранения часто используемых данных и кодов в так называемой «кэш-памяти первого уровня» (быстрой памяти), находящейся внутри микропроцессора, i486, к примеру, содержит один блок встроенной Кэш-памяти размером 8 Кбайт, который используется для кэширования и кодов, и данных. Pentium содержит два блока кэш-памяти: один для кода и один для данных, каждый по 8 Кбайт. При этом становится возможным одновременный доступ к коду и данным, что увеличивает скорость работы компьютера.
Предсказание правильного адреса перехода. Под переходом понимается запланированное алгоритмом изменение последовательного характера выполнения программы. Как показывает статистика, типичная программа на каждые 6-8 команд содержит 1 команду перехода. Последствия этого предсказать несложно: при наличии конвейера через каждые 6-8 команд его нужно очищать заполнять заново в соответствии с адресом перехода. Все преимущества конвейеризации теряются. Поэтому в архитектуру Pentium был введен блок предсказания переходов. Суть этого метода заключается в следующем. Pentium имеет буфер адресов перехода, который хранит информацию о последних 256 переходах. Если некоторая команда управляет ветвлением, то в буфере запоминаются эта команда, адрес перехода и предположение о том, какая ветвь программы будет выполнена следующей. Почти в любой программе имеются циклы, в ходе выполнения которых периодически необходимо принимать решение либо о выходе из цикла, либо о переходе на его начало. Специальный блок предсказания адреса перехода прогнозирует, какое решение будет принято программой. При этом он основывается на предположении, что ветвь, которая была пройдена, будет использоваться снова, и загружает соответствующую команду перехода на конвейер. В случае если это предсказание верно, переход осуществляется без задержки. Для того чтобы судить об эффективности этого нововведения, достаточно отметить, что вероятность правильного предсказания составляет около 80 %.
Рассмотрим, как эти и некоторые другие устройства, реализованные в обобщенной схеме предпоследнего поколения микропроцессоров фирмы Intel P6 (Pentium Pro/II/III). Для иллюстрации используем рис. 6.
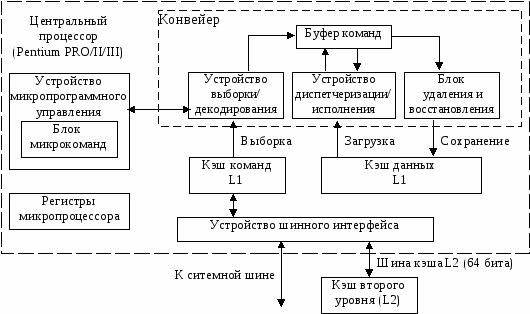
| Рис. 6 Обобщенная схема микропроцессора семейства Р6 (Pentium PRO/II/III) |
На рисунке видно разделение кэш-памяти на две части — для кода и для данных. Это обеспечивает бесперебойную поставку машинных инструкций и элементов данных на конвейер микропроцессора. Исходные данные для кэш-памяти первого уровня обеспечивает кэш-память второго уровня. Заметьте, что информация из нее поступает на устройство шинного интерфейса и далее в соответствующую кэш-память первого уровня по 64-битной шине. При этом благодаря более быстрому обновлению содержимого кэш-памяти первого уровня обеспечивается высокий темп работы микропроцессора.
Наиболее ценным свойством микропроцессорной архитектуры семейства P6 является реализация механизма интеллектуальной обработки потока команд, называемого «динамическим выполнением». Этот механизм основывается на следующих свойствах, некоторые из них уже существовали в прежних моделях микропроцессоров. Перечислим их:
· Предсказание переходов, в том числе вложенных. В микропроцессорах ряда Р6 такая технология реализуется устройством выборки/декодирования (см. рис. 6). Основная задача механизма предсказания — исключить перезагрузку конвейера.
· Динамический анализ потока данных. Анализ проводится с целью определения зависимостей команд программы от данных и регистров процессора с последующей оптимизацией выполнения потока команд. Главный критерий здесь — максимально полная загрузка конвейера. Требование соблюдения данного критерия позволяет даже нарушать исходный порядок следования команд при поступлении на конвейер. Сбоя при этом не будет, так как внешне логика работы программы будет сохранена. Подобная внутренняя неупорядоченность исполнения команд позволяет держать конвейер загруженным даже в то время, когда данные в кэш-памяти второго уровня отсутствуют и необходимо тратить время на обращение за ними в оперативную память.
· Интеллектуальное исполнение. Это свойство характеризует способность микропроцессора реализовать неупорядоченное исполнение команд, восстановив впоследствии исходный порядок команд и организовав передачу результатов работы команд в порядке, предусмотренном исходным алгоритмом. Данная возможность обеспечивается разделением устройства выборки и исполнения команд и устройства формирования результата (см. рис. 6). Все промежуточные результаты работы команд во время их исполнения (нахождения их на конвейере) размещаются во временных регистрах. Блок удаления и восстановления постоянно просматривает буфер команд и ищет те из них, которые уже исполнены и не имеют связи по данным с другими командами или не находятся в ветвях незавершенных переходов. Когда такие команды найдены, устройство удаления и восстановления результатов помещает сформированные ими данные в память или регистры процессора в порядке, заданном исходным алгоритмом. После этого команды удаляются из конвейера.
Таким образом, реализация динамического исполнения команд позволяет организовать наиболее оптимальное прохождение команд программы через исполнительное устройство микропроцессора. А если учесть то, что в микропроцессорах семейства Р6 команды исполняются в три потока одновременно, то становятся понятными все преимущества такого подхода. Выше мы уже отмечали то, что конвейер микропроцессоров семейства Р6 имеет принципиальное отличие от конвейеров i486 и Pentium. Перечисленные выше три концепции представляют собой основу работы этого конвейера. Расширенная схема микропроцессора ряда Р6 показана на рис. 7. На схеме рис. 7 показан только один из трех конвейеров микропроцессора и некоторые общие для всех трех конвейеров элементы (кэш-память, шины и т. д.). Схема рис. 7 представляет собой развитие рис. 6, на ней некоторые элементы показаны более крупным планом. Из схемы рис. 7 видно, что структурно микропроцессор состоит из следующих подсистем.
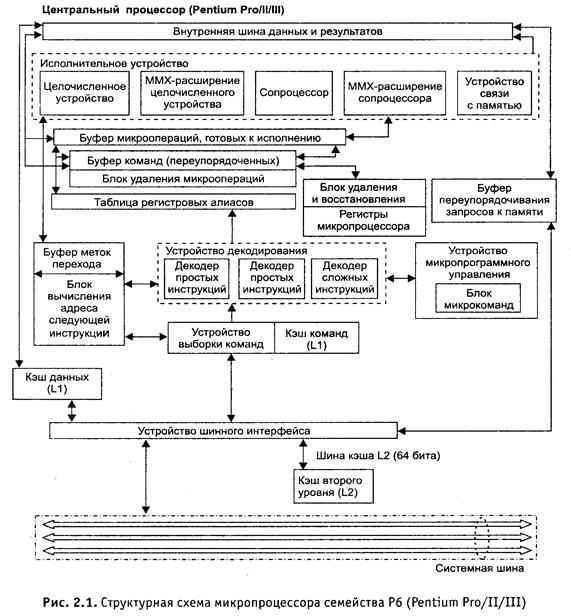
|
· Подсистема памяти. Состоит из системной шины, кэша второго уровня L2, устройства шинного интерфейса, кэша первого уровня L1 (инструкций и данных), устройства связи с памятью и буфера переупорядочивания запросов к памяти.
· Устройство выборки/декодирования. Состоит из устройства выборки инструкций, буфера предсказаний переходов, декодера инструкций, блока микропрограммного управления и таблицы регистровых алиасов.
· Буфер команд. Содержит команды, переупорядоченные для оптимальной загрузки конвейера.
· Устройство диспетчеризации/исполнения. Содержит буфер микроопераций, готовых к исполнению, пять исполнительных устройств: два устройства для исполнения целочисленных операций, два — с плавающей точкой и устройство связи с памятью. На самом деле такого деления нет. Сделано это было для того, чтобы понятней была система команд ассемблера.
Запросы на операнды из памяти от команд в исполнительном устройстве микропроцессора обеспечиваются посредством устройства связи с памятью и буфера переупорядочивания запросов к памяти. Эти два устройства были специально включены в схему для того, чтобы обеспечить бесперебойное снабжение исполняемых команд необходимыми данными. Особо стоит подчеркнуть роль буфера переупорядочивания запросов к памяти. Он отслеживает все запросы к операндам в памяти и выполняет функции планирующего устройства. Если нужные для очередной операции данные в кэш-памяти данных (L1) отсутствуют, то буфер переупорядочивания запросов к памяти автоматически передает информацию о неудачном обращении к данным кэшу второго уровня (L2). Если и в кэше L2 нужных данных не оказалось, то буфер переупорядочивания запросов к памяти заставляет устройство шинного интерфейса сформировать запрос к оперативной памяти компьютера.
Программирование МП
5.2.1. Программирование микропроцессора
5.2.2. Машинно-ориентированные языки
5.2.3. Языки высокого уровня
5.2.4. Специализированные языки
Дата добавления: 2019-11-25; просмотров: 284; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!