Программирование микропроцессора
Принципиальным достоинством МП является программируемость. Это означает, что, подавая на вход МП команды, можно обеспечить нужную последовательность операций, т.е. реализацию определенного алгоритма. Алгоритм решаемой задачи может быть сколь угодно сложным, необходимо лишь, чтобы этот алгоритм был разбит на шаги в соответствии с системой команд МП. Поэтому система команд важна не только с точки зрения, что МП может делать, но и как выполняется алгоритм. Наличие или отсутствие какой-либо команды или группы команд может существенно повлиять на выбор МП для конкретного применения.
Все языки программирования условно можно разделить на три уровня:
- машинный код;
- автокод (язык ассемблера);
- языки высокого уровня (процедурные языки - BASIC, FORTRAN, PASCAL, C, MODULA-2, ADA; и языки искусственного интеллекта - LISP, PROLOG, SMALLTALK, OCCAM).
Машинно-ориентированные языки
Более понятные для ЭВМ - это так называемые машинно-ориентированные языки (машинный код и язык ассемблера). Более понятные для человека именуют языками высокого уровня.
Программное обеспечение на машинно-ориентированном языке экономично в эксплуатации, однако сравнительно высокая трудоемкость и длительность разработки программного обеспечения обуславливают преимущественное применение их для создания и развития программного обеспечения драйверов и операционных систем с целью наилучшего использования аппаратных особенностей каждой конкретной ЭВМ.
|
|
|
Языки высокого уровня
Алгоритмические языки (языки программирования высокого уровня общего назначения) являются машинно-независимыми, позволяют создавать компактные обозримые программы при относительно небольших затратах времени и труда программистов. Разработка программ значительно упрощается при использовании языков высокого уровня в качестве языков программирования. Однако при этом снижается эффективность программ по быстродействию и затратам памяти в сравнении с применением языка ассемблера. Но этот недостаток с лихвой перекрывается четкостью и легкостью написания программы.
Языки высокого уровня в свою очередь подразделяются на языки процедурного (или императивного) и эвристического (декларативного) стиля программирования (языки искусственного интеллекта). Наиболее популярные языки программирования ПЭВМ высокого уровня приведены в таблице 1.
Таблица 1 Наиболее популярные языки программирования ПЭВМ высокого уровня
| Язык | Год разработки | Разработчик | Основное применение |
| FORTRAN | 1954 | Дж. Бэкус (США) | Математические расчеты, научные исследования |
| BASIC | 1965 | Дж. Кенеми (США) | Обучение, тестовые программы |
| PASCAL | 1971 | Н.Вирт (Швейцария) | Обучение, широкое применение |
| C | 1972 | Д.М.Ричи (США) | Системное программирование |
| MODULA-2 | 1981 | Н.Вирт (Швейцария) | Разработка больших программных комплексов |
| LISP | 1960 | Дж. Маккарти (США) | Системы искусственного интеллекта |
| PROLOG | 1971 | А.Колмедауэр (Франция) | Принятие решений, логический вывод |
| SMALLTALK | Середина 1970-х | А.КейАнглия) | Системы диалога со средствами машинной графики |
| OCCAM | Начало 1980-х | Фирма INMOS(Англия) | Системы с параллельными процессами |
|
|
|
Кроме того, в настоящее время появились языки так называемого 4-го поколения - это языки СУБД, электронных таблиц, интегрированных систем и т.д., которые предназначены для решения узкого круга задач прикладного характера (например, обработка баз данных), но зато еще больше, по сравнению с языками общего назначения, снижают затраты времени и труда на создание выходного продукта.
Специализированные языки
Опыт применения ПЭВМ для построения прикладных систем обработки данных показывает, что самым эффективным инструментом создания контроллера являются не универсальные языки высокого уровня, а узкоспециализированные языки - как правило языки высокого манипулирования с особенностями микропроцессора.
|
|
|
Система микропрограммирования является набором компактных программных продуктов для разработки программ для микропроцессоров. СМ реализована для работы на ряде компьютеров, от небольших 16-разрядных персональных машин до 32-разрядных суперминикомпьютеров.
В нем имеется ряд примеров использования как стандартных, так и имеющих особенности средств СМ. Отметим, что независимые средства ассемблера СМ очень просты и эффективны.
СМ ассемблеры - это мощные МАКРО-ассемблеры со средствами перемещения программ, с универсальными характеристиками и применением. Хотя ассемблеры созданы на базе одного и того же основного пакета, они обладают высокой степенью совместимости с ассемблерами разработчиков микропроцессоров. Основные предметы - это способы использования ассемблера, поддержка модульного программирования и связь с языками высокого уровня.
Все ассемблеры двухпроходные, выполняются как одна программа. Во время выполнения не создается временных файлов.
Все ассемблеры, так же как и ХLINK, используют для внутренних вычислений 32-разрядные структуры, что позволяет виртуально генерировать код любого размера (т.е. не существует предела в 64 кБайт, что могло бы затруднить использование процессоров типа 68000).
|
|
|
Для обеспечения совместимости внутри пакета было применено несколько компромиссных решений, с учетом совместимости с ассемблерами разработчиков микропроцессоров. Особенно это касается макро-конструкций, которые сильно различаются у различных разработчиков. Во многих отношениях, однако, СМ превосходит оригинальные ассемблеры.
Они должны быть совместимы по:
- машинным командам (именам и синтаксису)
- директивам определения констант (именам и синтаксису)
- директивам распределения памяти (именам и синтаксису)
- разделителям
- меткам
- основным операторам (+,-,*,/)
- ORG и EQU
Могут быть не совместимы по:
- директивам перемещения
- расширениям операторов
- средствам условной трансляции
- опциям и командам управления ассемблером
- макросредствам.
Средства, перечисленные в разделе "не совместимы", часто отличаются от оригинальных ассемблеров разработчиков только синтаксисом.
Наиболее популярными на сегодняшний день у программистов являются С-51 и Assembler 8051, так как оба они позволяют получать исходный код.
Внутренняя кэш-память.
В системах, состоящих из клиентов и серверов, потенциально имеется четыре различных места для хранения файлов и их частей:
· диск сервера,
· память сервера,
· диск клиента (если имеется)
· память клиента.
Наиболее подходящим местом для хранения всех файлов является диск сервера. Он обычно имеет большую емкость, и файлы становятся доступными всем клиентам. Кроме того, поскольку в этом случае существует только одна копия каждого файла, то не возникает проблемы согласования состояний копий.
Проблемой при использовании диска сервера является производительность. Перед тем, как клиент сможет прочитать файл, файл должен быть переписан с диска сервера в его оперативную память, а затем передан по сети в память клиента. Обе передачи занимают время.
Значительное увеличение производительности может быть достигнуто за счет кэширования файлов в памяти сервера. Требуются алгоритмы для определения, какие файлы или их части следует хранить в кэш-памяти.
Кэш-память Внешняя память
Основная память компьютера – это устройство с очень низкой скоростью обмена данных. И если процессору необходимы какие-то данные для работы, то он посылает запрос через шину памяти, и производится поиск этих нужных данных.
Только потом они отправляются непосредственно в процессор. Все это занимает очень много времени по компьютерным меркам. А вот, что если бы данные хранились где-то рядом с процессором?
Как раз кэш-память работает на основе этой идеи. И для того чтобы понять концепцию, для наглядности возьмем возьмем пример работы обычной библиотеки.
Смысловое содержание кэш-памяти или кэш (по англ. cache memory, cache):
· в широком смысле, подразумевается любая память с быстрым доступом, где хранится часть данных с другого носителя с более медленным доступом;
· в узком смысле — это сверхоперативный вид памяти, который используется для повышения скорости
При выборе алгоритма должны решаться две задачи:
1) Во-первых, какими единицами оперирует кэш.
Этими единицами могут быть или дисковые блоки, или целые файлы. Если это целые файлы, то они могут храниться на диске непрерывными областями (по крайней мере в виде больших участков), при этом уменьшается число обменов между памятью и диском а, следовательно, обеспечивается высокая производительность. Кэширование блоков диска позволяет более эффективно использовать память кэша и дисковое пространство.
2) Во-вторых, необходимо определить правило замены данных при заполнении кэш-памяти.
Здесь можно использовать любой стандартный алгоритм кэширования, например, алгоритм LRU (least recently used),соответствии с которым вытесняется блок, к которому дольше всего не было обращения.
Кэш-память на сервере легко реализуется и совершенно прозрачна для клиента. Так как сервер может синхронизировать работу памяти и диска, с точки зрения клиентов существует только одна копия каждого файла, так что проблема согласования не возникает.
Хотя кэширование на сервере исключает обмен с диском при каждом доступе, все еще остается обмен по сети.
Существует только один путь избавиться от обмена по сети - это кэширование на стороне клиента, которое, однако, порождает много сложностей.
В большинстве систем используется кэширование в памяти клиента, а не на его диске
| Назначение кеш памяти Кэшиликеш(англ.cache, от фр.cacher— «прятать»; произносится [kæʃ] — «кэш») — промежуточный буфер с быстрым доступом, содержащий информацию, которая может быть запрошена с наибольшей вероятностью. Доступ к данным в кэше осуществляется быстрее, чем выборка исходных данных из более медленной памяти или удаленного источника, однако её объём существенно ограничен по сравнению с хранилищем исходных данных | 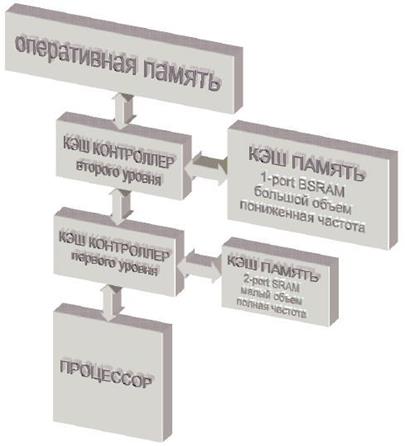
|
Самый простой состоит в кэшировании файлов непосредственно внутри адресного пространства каждого пользовательского процесса. Обычно кэш управляется с помощью библиотеки системных вызов. По мере того, как файлы открываются, закрываются, читаются и пишутся, библиотека просто сохраняет наиболее часто используемые файлы. Когда процесс завершается, все модифицированные файлы записываются назад на сервер. Хотя эта схема реализуется с чрезвычайно низкими издержками, она эффективна только тогда, когда отдельные процессы часто повторно открывают и закрывают файлы. Таким является процесс менеджера базы данных, но обычные программы чаще всего читают каждый файл однократно, так что кэширование с помощью библиотеки в этом случае не дает выигрыша
Другим местом кэширования является ядро. Недостатком этого варианта является то, что во всех случаях требуется выполнять системные вызовы, даже в случае успешного обращения к кэш-памяти (файл оказался в кэше). Но преимуществом является то, что файлы остаются в кэше и после завершения процессов. Например, предположим, что двухпроходный компилятор выполняется, как два процесса. Первый проход записывает промежуточный файл, который читается вторым проходом. На рисунке 1в показано, что после завершения процесса первого прохода промежуточный файл, вероятно, будет находиться в кэше, так что вызов сервера не потребуется.
Примечание
Компиля́тор— Компьютерная программа, выполняющая компиляцию
Компиля́ция—трансляция программы, составленной на исходном языке высокого уровняв эквивалентную программу на низкоуровневом языке, близком машинному коду(абсолютный код, объектный модуль, иногда на язык ассемблера). Входной информацией для компилятора (исходный код) является описание алгоритма или программа на объектно-ориентированном языке, а на выходе компилятора — эквивалентное описание алгоритма на машинно-ориентированном языке (объектный код).
Компили́ровать— проводить трансляцию машинной программы с любого языка программирования на машинно-ориентированный язык
Третьим вариантом организации кэша является создание отдельного процесса пользовательского уровня - кэш-менеджера.
Преимущество этого подхода заключается в том, что ядро освобождается от кода файловой системы и тем самым реализуются все достоинства микроядер.
Примечание
□ S-код (англ. S-code) – заменитель s-символа или s-сообщения, построенный из символов другой символьной системы (напр., числовой) и удовлетворяющий требованиям решения базовых задач s-(представления, преобразования, распознавания, конструирования, интерпретации, обмена, сохранения, накопления, поиска и защиты) в s-среде.□
См. TSM– комплекс средств формализации гипермедийных описаний s-моделей.
Исследователям и инженерам, имеющим дело с различными моделями, свойственно стремление представлять их в числовой форме. Это позволяет применять методы решения задач, которые можно представить в виде программ, рассчитанных на выполнение s-машинами.
Числовое кодирование
S-символам любого вида ставят во взаимно однозначное соответствие числа, которые можно представить в памяти s-машины.
☼ ASCII (American Standard Code for Information Interchange) — набор, состоящий из 128 текстовых символов(букв, цифр, знаков пунктуации и др.). Расширенный набор ASCII включает 256 текстовых символов. Каждому символу назначен уникальный номер, называемый кодом ASCII. В этих наборах строчные буквы и заглавные — это разные символы (буквы а строчная и А заглавная и т.д.), которые имеют разные коды. ☼
Представление в памяти s-машин
Изобретая s-машины, выбирают систему счисления и число разрядов для представления чисел в памяти s-машин. При этом выбор направляется стремлением обеспечить наиболее эффективное манипулирование числовыми кодами, которое выполняют s-машины.
Выбор ограничен рядом условий, среди которых физико-техническая реализуемость элементов, используемых для построения s-машин. Обычно основание выбранной системы счисления выбирают равным количеству устойчивых состояний, в которых могут находиться элементарные составляющие, из которых построена s-машина.
Транзисторы современных электронных s-машин имеют два устойчивых состояния. Поэтому в нынешних s-машинах используется двоичное представление числовых кодов программ и данных.
С другой стороны, когда ядро управляет кэшем, оно может динамически решить, сколько памяти выделить для программ, а сколько для кэша. Когда же кэш-менеджер пользовательского уровня работает на машине с виртуальной памятью, то понятно, что ядро может решить выгрузить некоторые, или даже все страницы кэша на диск, так что для так называемого "попадания в кэш" требуется подкачка одной или более страниц. Нечего и говорить, что это полностью дискредитирует идею кэширования. Однако, если в системе имеется возможность фиксировать некоторые страницы в памяти, то такая парадоксальная ситуация может быть исключена.
Как и везде, нельзя получить что-либо, не заплатив чем-то за это. Кэширование на стороне клиента вносит в систему проблему несогласованности данных.
Одним из путей решения проблемы согласования является использование алгоритма сквозной записи.
Когда кэшируемый элемент (файл или блок) модифицируется, новое значение записывается в кэш и одновременно посылается на сервер. Теперь другой процесс, читающий этот файл, получает самую последнюю версию.
Один из недостатков алгоритма сквозной записи состоит в том, что он уменьшает интенсивность сетевого обмена только при чтении, при записи интенсивность сетевого обмена та же самая, что и без кэширования. Многие разработчики систем находят это неприемлемым и предлагают следующий алгоритм, использующий отложенную запись: вместо того, чтобы выполнять запись на сервер, клиент просто помечает, что файл изменен. Примерно каждые 30 секунд все изменения в файлах собираются вместе и отсылаются на сервер за один прием. Одна большая запись обычно более эффективна, чем много маленьких.
Следующим шагом в этом направлении является принятие сессионной семантики, в соответствии с которой запись файла на сервер производится только после его закрытия. Этот алгоритм называется "запись-по-закрытию". Как мы видели раньше, этот путь приводит к тому, что если две копии одного файла кэшируются на разных машинах и последовательно записываются на сервер, то второй записывается поверх первого. Однако это не так уж плохо, как кажется на первый взгляд. В однопроцессорной системе два процесса могут открыть и читать файл, модифицировать его в своих адресных пространствах, а затем записать его назад. Следовательно, алгоритм "запись-по-закрытию", основанный на сессионной семантике, не намного хуже варианта, уже используемого в однопроцессорной системе.
Совершенно отличный подход к проблеме согласования - это использование алгоритма централизованного управления (этот подход соответствует семантике UNIX).
Когда файл открыт, машина, открывшая его, посылает сообщение файловому серверу, чтобы оповестить его об этом факте. Файл-сервер сохраняет информацию о том, кто открыл какой файл, и о том, открыт ли он для чтения, для записи, или для того и другого. Если файл открыт для чтения, то нет никаких препятствий для разрешения другим процессам открыть его для чтения, но открытие его для записи должно быть запрещено. Аналогично, если некоторый процесс открыл файл для записи, то все другие виды доступа должны быть предотвращены. При закрытии файла также необходимо оповестить файл-сервер для того, чтобы он обновил свои таблицы, содержащие данные об открытых файлах. Модифицированный файл также может быть выгружен на сервер в такой момент.
Четыре алгоритма управления кэшированием обобщаются следующим образом:
1. Сквозная запись. Этот метод эффективен частично, так как уменьшает интенсивность только операций чтения, а интенсивность операций записи остается неизменной.
2. Отложенная запись. Производительность лучше, но результат чтения кэшированного файла не всегда однозначен.
3."Запись-по-закрытию". Удовлетворяет сессионной семантике.
4. Централизованное управление. Ненадежен вследствие своей централизованной природы.
Подводя итоги обсуждения проблемы кэширования, нужно отметить, что кэширование на сервере несложно реализуется и почти всегда дает эффект, независимо от того, реализовано кэширование у клиента или нет.
Кэширование на сервере не влияет на семантику файловой системы, видимую клиентом.
Кэширование у клиента напротив дает увеличение производительности, но увеличивает и сложность семантики
Дата добавления: 2019-11-25; просмотров: 384; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!