Стандартная ошибка среднего арифметического
Оценки  и
и  , полученные по выборке, естественно не совпадают с истинными значениями параметров
, полученные по выборке, естественно не совпадают с истинными значениями параметров  и
и  генеральной совокупности. Экспериментально проверить это утверждение невозможно, поскольку не известны истинные значения этих параметров. Но если брать повторные выборки из одной и той же генеральной совокупности с параметрами и и каждый раз вычислять их оценки и , то окажется, что эти оценки для разных выборок не совпадают, хотя все это из одних и тех же генеральных параметров.
генеральной совокупности. Экспериментально проверить это утверждение невозможно, поскольку не известны истинные значения этих параметров. Но если брать повторные выборки из одной и той же генеральной совокупности с параметрами и и каждый раз вычислять их оценки и , то окажется, что эти оценки для разных выборок не совпадают, хотя все это из одних и тех же генеральных параметров.
Отклонения оценок генеральных параметров от истинных значений этих параметров называются статистическими ошибками, или ошибками репрезентативности. Их происхождение не имеет ничего общего с ошибками измерения, а возникают они только потому, что не все объекты генеральной совокупности представлены в выборке.
Величины статистических ошибок оценивают по среднему квадратическому (стандартному) отклонению выборочных характеристик. Здесь рассматривается только стандартное отклонение выборочного среднего арифметического.
Если взять очень много независимых выборок объема n из одной и той же генеральной совокупности и определить для каждой из них среднее арифметическое, то окажется, что полученные средние арифметические варьируют вокруг своего среднего значения (равного ) в  раз меньше, чем отдельные варианты выборки. Т.е. стандартное отклонение выборочного среднего арифметического будет равно
раз меньше, чем отдельные варианты выборки. Т.е. стандартное отклонение выборочного среднего арифметического будет равно
|
|
|

где  — стандартное отклонение генеральной совокупности.
— стандартное отклонение генеральной совокупности.
В качестве оценки стандартного отклонения выборочного среднего используется величина
(5.1)
называемая стандартной ошибкой среднего арифметического. В формуле (5.1) S — выборочное стандартное отклонение  .
.
Величина  показывает, какая ошибка в среднем допускается, если использовать вместо генерального среднего его выборочную оценку
показывает, какая ошибка в среднем допускается, если использовать вместо генерального среднего его выборочную оценку  . Поэтому вычисленное среднее арифметическое часто указывают в виде
. Поэтому вычисленное среднее арифметическое часто указывают в виде

чтобы оценить точность оценки х.
Из формулы (5.1) видно, как зависит стандартная ошибка от объема выборки n: с увеличением объема выборки n стандартная ошибка уменьшается пропорционально корню квадратному из n.
Интервальные оценки
По известной величине выборочной характеристики ( или и др.) можно определить интервал, в котором с той или иной вероятностью определяется значение параметра генеральной совокупности, оцениваемого по этой выборочной характеристике.
Вероятности, признанные достаточными для того, чтобы уверенно судить о генеральных параметрах на основании выборочных характеристик, называются доверительными.
Обычно в качестве доверительных вероятностей выбирают значения 0,95, 0,99 или 0,999 (их принято выражать в процентах). Перечисленным значениям соответствуют 95, 99 и 99,9 %. Выбор той или иной доверительной вероятности производится исследователем исходя из практических соображений о той ответственности, с какой делаются выводы о генеральных параметрах.
|
|
|
Чтобы найти границы доверительного интервала для среднего значения генеральной совокупности, действуем в следующем порядке:
1) по полученной выборке объема n вычисляем среднее арифметическое и стандартное отклонение S. Методы вычислений рассмотрены в гл. 3;
2) задаемся доверительной вероятностью 1–  (например, 0,95) исходя из целей исследования;
(например, 0,95) исходя из целей исследования;
3) по таблице Т-распределения Стьюдента находим граничные значения  . В силу симметричности Т-распределения достаточно знать только положительное значение . Например, если объем выборкиn=12, то число степеней свободы Т-распределения v=12–1=11, и по таблице Т-распределения определяем для = 0,05 значение t0,05 = 2,20;
. В силу симметричности Т-распределения достаточно знать только положительное значение . Например, если объем выборкиn=12, то число степеней свободы Т-распределения v=12–1=11, и по таблице Т-распределения определяем для = 0,05 значение t0,05 = 2,20;
4) находим границы доверительного интервала по формуле (5.3). Для =0,05 и n=12:

чтобы найти доверительный интервал для среднего значения генеральной совокупности при больших объемах выборки (n  30), поступаем следующим образом:
30), поступаем следующим образом:
|
|
|
1. По выборочным данным находим среднее арифметическое и стандартное отклонение S, как показано в гл. 3.
2. Задаемся доверительной вероятностью 1– (например, 0,95).
3. По табл. 5.2 находим значение uа, соответствующее заданной доверительной вероятности (u0,05 = 1,96).
4. Определяем границы доверительного интервала по формуле (5.4). Для = 0,05 получаем:

Как видно из сравнения найденного доверительного интервала с доверительным интервалом, полученный выше по Т-распределению, при малых объемах выборки границы первого интервала шире (t0,05 = 2,20, а u0,05 = 1,96). Это понятно из простых физических соображений: при малом объеме выборки получается меньше информации о свойствах генеральной совокупности.
Обнаружение промахов
При проведении ряда одинаковых измерений, подверженных случайным погрешностям, могут встретиться измерения и с очень большими случайными погрешностями. Однако, как известно, большие погрешности имеют малую вероятность, и, если среди результатов измерений встретится одно, имеющее резко отличное от других значение, то может появится соблазн квалифицировать его как промах и не учитывать его как заведомо неверный. В такой операции всегда присутствует известная доля субъективизма. Для объективизации отбрасывания непонравившегося измерения необходимо ввести определенный количественный критерий, основанный на законах теории вероятности.
|
|
|
Если известно точное значение генеральной дисперсии σ, то вероятность появления значения, отклоняющегося от среднего арифметического х более чем на 3 σ, равна 0,003 и все измерения, отличающиеся от х на эту или большую величину, могут быть квалифицированы как промахи и отброшены как очень мало вероятные.
Нужно помнить: существует очень малая вероятность того, что отброшенное число является не промахом, а естественным статистическим отклонением. Однако, если такой маловероятный случай и произойдет, т.е. будет неправильно отброшен один из результатов измерений, то это практически не приведет к существенному ухудшению оценки результатов измерений.
Для совокупности измерений вероятность проявления измерения, отличающегося более чем на 3 σ от среднего значения, всегда > 0,003, а вероятность β того, что ни один из результатов n измерений не будет отличаться от среднего более чем на 3 σ , и 0,997, а равна β = (1 - 0,003) n. Если n не слишком большое, то β = (1 - 0,003) n = 1 - 0,003 n.
При 100 измерениях вероятность того, что хотя бы одно будет случайно отличаться от среднего более чем на 3 σ, составит около 30% .
Обычно число производимых измерений не очень велико – сравнительно редко оно превышает 10-20. При этом точное значение неизвестно, поэтому отбрасывать измерения, отличающиеся от среднего более чем на 3 σ , нельзя.
Для оценки вероятностей β случайного появления выскакивающих значений в ряду n измерений (для n < 25) на основании результатов, даваемых теорией вероятности, составлена таблица (9.4). Методика пользования таблицей 9.4 описана на страницах 265-266 учебника «Биотехнология» (авторы С.Д. Варфоломеев, С.В. Калюжный).
15. Косвенными называются измерения, при которых искомое значение величины определяется на основании известной зависимости
y = f (x1, x2,….,xm), (1)
где x1, x2,….,xm – значения, полученные при прямых измерениях.
Для обработки результатов измерений при нелинейных зависимостях между аргументами и некоррелированных погрешностях используется метод линеаризации. Он состоит в том, что нелинейная функция, связывающая искомую величину с аргументами, разлагается в ряд Тейлора, в котором значимыми являются только члены первой степени:
 (2)
(2)
где  – частные производные первого порядка, или коэффициенты влияния, показывающие влияние погрешности измерений j-го параметра
– частные производные первого порядка, или коэффициенты влияния, показывающие влияние погрешности измерений j-го параметра  на полную погрешность измерения
на полную погрешность измерения  ; – отклонение отдельного результата измерения j-го аргумента от его среднего арифметического; R- остаточный член.
; – отклонение отдельного результата измерения j-го аргумента от его среднего арифметического; R- остаточный член.
Коэффициенты влияния вычисляются в точках 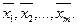
Величина  называется частной погрешностью.
называется частной погрешностью.
Погрешность косвенного измерения  определяется как погрешностью каждого из прямых измерений, входящих в косвенное, так и зависимостью, связывающей искомую и измеренные величины. Формула является приближенной, так как учитывает только линейную часть приращения функции, однако в большинстве практических случаев она обеспечивает удовлетворительную точность оценки погрешностей косвенных измерений. Результат косвенного измерения вычисляется по формуле
определяется как погрешностью каждого из прямых измерений, входящих в косвенное, так и зависимостью, связывающей искомую и измеренные величины. Формула является приближенной, так как учитывает только линейную часть приращения функции, однако в большинстве практических случаев она обеспечивает удовлетворительную точность оценки погрешностей косвенных измерений. Результат косвенного измерения вычисляется по формуле
 (4)
(4)
Если распределение погрешностей результатов измерений аргументов не противоречит нормальному распределению, то доверительные границы случайной погрешности косвенного измерения при числе наблюдений аргументов 25…30 вычисляют по формуле
 ..
..
Границы неисключенной систематической погрешности результата косвенного измерения вычисляются следующим образом:
а) при равномерном распределении составляющих  . Если неисключенные систематические погрешности результатов измерений аргументов заданы границами , то доверительные границы НСП результата косвенного измерения
. Если неисключенные систематические погрешности результатов измерений аргументов заданы границами , то доверительные границы НСП результата косвенного измерения  при вероятности P находят по формуле
при вероятности P находят по формуле
 (6)
(6)
где k – коэффициент, определяемый принятой доверительной вероятностью и числом составляющих .
При 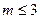 следует также оценить алгебраическую сумму
следует также оценить алгебраическую сумму
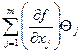 ,
,
и если эта сумма окажется меньше, чем , вычисленное по формуле (6) то за границы неисключенной НСП нужно принять

Если границы НСП результатов измерений аргументов заданы доверительными границами  , соответствующими вероятностям
, соответствующими вероятностям  , и при этом границы НСП результатов измерений аргументов вычислены по формуле, аналогичной (6), то границы НСП результата косвенного измерения для вероятности P находят по формуле
, и при этом границы НСП результатов измерений аргументов вычислены по формуле, аналогичной (6), то границы НСП результата косвенного измерения для вероятности P находят по формуле
 (7)
(7)
б) при нормальном распределении составляющих .Если все составляющие общей погрешности  можно считать имеющими нормальное распределение (а это оправдано тогда, когда все они образованы большим числом составляющих) и все границы вычислены для одной и той же доверительной вероятности P, то границы НСП результата косвенного измерения рассчитываются по формулу (6).
можно считать имеющими нормальное распределение (а это оправдано тогда, когда все они образованы большим числом составляющих) и все границы вычислены для одной и той же доверительной вероятности P, то границы НСП результата косвенного измерения рассчитываются по формулу (6).
в) в промежуточном случае, когда k составляющих имеет нормальное распределение, а  – равномерное, в этом случае оценка дисперсии суммы:
– равномерное, в этом случае оценка дисперсии суммы:
– k слагаемых
 ;
;
– слагаемых

Доверительные границы полной погрешности результата косвенного измерения определяют по формулам:
а) если  , то
, то  ;
;
б) если  , то
, то  ;
;
в) если  , то
, то  ,
,
где 

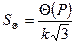 – при равномерном законе распределения составляющих НСП;
– при равномерном законе распределения составляющих НСП;  – при нормальном законе распределения составляющих;
– при нормальном законе распределения составляющих;  – в промежуточном случае.
– в промежуточном случае.
Косвенным измерениям присуща методическая погрешность. Она может возникать из-за того, что в общем случае при нелинейной функции y = f (x1, x2,….,xm) коэффициенты влияния  , в свою очередь являются функциями значений величин
, в свою очередь являются функциями значений величин  .
.
Коэффициенты влияния оцениваются путем подстановки в выражения частных производных оценок . Следовательно, вместо самих коэффициентов влияния получают лишь их оценки. Кроме того, коэффициенты влияния определяют экспериментально. И в том и другом случае они устанавливаются с некоторой погрешностью, что является еще одним источником методической погрешности при обработке результатов косвенных измерений.
16. В микробиологии существуют две основные задачи: во-первых, выделить из определенной экосистемы микробную популяцию и определить ее видовую принадлежность; во-вторых, осуществить культивирование микробной популяции данного вида в управляемых условиях с целью накопления биомассы или ценных продуктов метаболизма.
Для решения этих задач необходимо наличие диалоговых информационно-вычислительных систем на базе современных быстродействующих ЭВМ, оснащенных соответствующим математическим обеспечением (мини- и микро-ЭВМ, микропроцессоров).
В данной главе электронные вычислительные машины рассматриваются как центральные элементы автоматизированных систем для биотехнологических исследований. Одна из отличительных особенностей управляющих ЭВМ заключается в том, что они взаимодействуют не с человеком – оператором, а непосредственно и физическим объектом и отображает информацию о ходе процесса. Кроме того, она не может самостоятельно выбирать темп работы и должна в реальном масштабе времени реагировать на разнообразные изменения в управляемом процессе. При культивировании микроорганизмов необходимо оптимальное регулирование основных параметров процесса. Для этого следует в эксперименте определять реальную траекторию процесса (набор физико-химических, биохимических параметров) и сравнивать ее в каждый момент времени с выбранной (расчетной), чтобы вовремя ввести необходимую коррекцию. Проведение таких расчетов в ручную потребует столько времени, что результаты окажутся уже практически ненужными, а ЭВМ позволяет вычислить необходимые параметры в реальном масштабе времени.
Рассмотрим, например, систему, обеспечивающую управление процессом культивирования микроорганизмов в ферментёре. Она состоит из исполнительных механизмов, датчиков, управляющей ЭВМ и программы, которая работает согласно трехкомпонентной модели реальной обстановки. Стратегия, согласно которой работает машинная программа, заключается в оптимальном ведении процесса. В такой системе ЭВМ, управляемая программными средствами, воспринимает информацию от датчиков об уровнях и скоростях течения различных жидкостей, температуре, давлении, кислотности в ферментёре, а также о параметрах, характеризующих состояние исследуемой культуры. Она выдает команды, по которым осуществляется регулирование этих параметров с помощью исполнительных механизмов, и тем самым определяет объемы и качественные показатели конечных продуктов. Подобная система управления также может быть запрограммирована и на минимизацию энергетических затрат либо расходуемых субстратов.
В любых приложениях управляющих систем связующими звеньями между ЭВМ и процессом служат датчики и исполнительные механизмы. Как правило, датчик воспринимает аналоговую информацию, которую, прежде чем ввести в ЭВМ, следует преобразовать в цифровую форму. Это осуществляют аналого-цифровые преобразователи (АЦП). При работе с некоторыми датчиками системные программы обеспечивают периодический запрос информации от них; датчики других типов в произвольные моменты времени сами прерывают выполнение программ для выдачи информации. Система управления тем или иным процессом содержит также устройство задания временного режима – таймер (тактовый генератор), которое можно рассматривать как датчик. Исполнительный орган воздействует на процесс с помощью либо электрических, либо электромеханических средств. При регулировании температуры такой механизм может включать или выключать нагреватель и холодильник.
Взаимодействие между ЭВМ и оператором осуществляется через устройство ввода-вывода. Типичное устройство ввода – это пульт с клавиатурой. Современные вычислительные системы зачастую оснащаются дополнительными средствами ввода, например световым пером или графическим манипулятором типа «мышь», которые позволяют оператору выбрать решение путем выделения определенных элементов на экране дисплея. Экран дисплея – это устройство вывода, отображающее графическую и текстовую информацию о состоянии управляемого процесса. Еще один пример устройства вывода – звуковая или световая сигнализация, уведомляющая о том, что на определенную часть процесса следует обратить особое внимание.
Центральным звеном любой управляющей вычислительной системы является модель реально протекающего процесса. Такая модель включает три компонента: модельное состояние, функция модификации состояний и функция предсказания. Модельное состояние содержит данные, представляющие полное описание реального процесса в каждый момент времени. Функция модификации состояний на основе информации, получаемой от датчиков, заключается в переходе от одного модельного состояния к другому. Функция предсказания (при точно заданном модельном состоянии) формирует набор машинных команд, позволяющих установить некоторые условия, требуемые для данного управляемого процесса. Перечисленные формализованные компоненты описывают замкнутую систему управления: ЭВМ получает информацию от датчиков, реализует функции модификации состояний и предсказания и выдает команды на исполнительные органы. Результаты выполнения этих команд сказываются в дальнейшем на информации, поступающей от датчиков.
Самостоятельную, не связанную с моделью, но крайне важную роль для функционирования системы играет обобщенный план. Он определяет последовательность состояний, которые должен проходить управляемый процесс. Указанный план может либо подготавливаться специалистами, либо автоматически «генерироваться» программными средствами на основе комплекса более абстрактных целей, поставленных разработчиками системы.
Проиллюстрируем систему управления процессами на том же примере установки, обеспечивающей управление процессами ферментации. Модельное состояние в данном случае включает в себя значения параметров, считываемых с датчиков. Наиболее важная задача функции модификации состояний – наиболее точная оценка состояния процесса в конкретный момент времени. Функция предсказания на основе модельного состояния и стратегии ведения процесса указывает, когда следует запустить или отключить тот или иной исполнительный механизм. Обобщенный план предусматривает ведение процесса оптимальным образом, исходя из информации конечной задачи, стоимости субстратов и энергозатрат. Определение функции предсказания и выработка стратегии поведения (принятие решений) являются сложными процедурами, как в программном, так и в математическом плане.
Расчет и планирование – это те задачи, которые часто приходится решать во многих случаях применения вычислительных машин; в программах управления процессами используются те же универсальные алгоритмы, которые применяются в программном обеспечении для решения других задач. Требования к системам управления процессами отличаются необходимостью повышенного быстродействия, система обязана принимать решения быстро, функционировать в «реальном времени». Важное значение для управляющих ЭВМ приобретают синхронизация, распределение времени и надежность, поскольку отказ системы приводит к безвозвратной потере информации о процессе.
Представим себе какой-либо один из способов повышения надежности системы (100%-ное резервирование важнейших компонентов). Одна вычислительная машина считается основной, вторая – дублирующей. Каждая ЭВМ принимает все входные данные, но только основная имеет выход на исполнительные органы. Дополнительная ЭВМ выполняет все вычисления, как и при управлении процессом. Если основная машина отказывает, управление основными органами передается дополнительной ЭВМ. В системе также предусмотрено резервирование датчиков, исполнительных механизмов, индикаторов и устройств ввода, поскольку они должны работать также надежно, как и ЭВМ.
Создание процессов управляемого культивирования требует наличия анализаторов состояния микробных популяций, характеризующих физико-химические, биохимические, морфологические, генетические и физиологические показатели популяций. В связи с большим объемом перерабатываемой информации анализаторы также создаются с применением ЭВМ.
Ниже мы рассмотрим примеры применения ЭВМ в составе автоматизированных рабочих мест для автоматизированных рабочих мест для биотехнологических исследований. Автоматизированные рабочие места для классификации и идентификации микроорганизмов и для управляемого культивирования являются определяющим звеном, а автоматизированные рабочие места для машинного анализа, исследования люминесцентных свойств популяции должны рассматриваются как вспомогательные автоматизированные анализаторы.
17. Исследование кинетики роста микробных популяций с использованием ЭВМ
Основными элементами любой микробиологической модели являются субстраты и микроорганизмы, участвующие в процессе, а также стадии превращения этих субстратов в продукты.
Основные типы биологических процессов:
а) производство биомассы (например, белок одноклеточных);
б) производство клеточных компонентов (ферменты, нуклеиновые кислоты и др.);
в) производство метаболитов (химические продукты метаболической активности), включая первичные метаболиты (этанол, молочная кислота и др.) и вторичные метаболиты (например, антибиотики);
г) односубстратные конверсии (превращение глюкозы во фруктозу) и многосубстратные конверсии (обработка сточных вод).
Основные свойствабиопроцессов:
1. способность к росту, высокая скорость роста и образование целевого продукта;
2. стабильность продуцента в отношении производственных свойств, минимальное образование побочных продуктов;
3. безвредность для людей и животных;
4. устойчивость к инфекциям и фагоустойчивость.
Математические модели микробиологической кинетики представляют собой математические описания, дающие возможность получить зависимость скорости микробиологических превращений субстратов, а также скорости роста биомассы от концентраций субстратов и клеток.
Любая постановка задачи по динамике роста и развития микробных популяций начинается с формулировки гипотез исследователя и построения кинетической схемы изучаемого процесса.
При этом исследователь конкретизирует конечные продукты, начальные субстраты, а также ферменты и другие внутриклеточные регуляторы, влияющие на кинетику микробного синтеза.
Затем записываются уравнения, представляющие собой математическую модель процесса. Центральным моментом построения уравнений динамики является выделение ключевых реакций, скорость которых ограничивает интенсивность накопления целевого продукта.
При построении модели необходимо учитывать различные ограничивающие факторы и требования. Например, при реакциях в закрытой системе к кинетическим характеристикам добавляются требования:
1. общая масса системы не меняется (закон сохранения массы);
2. отрицательные концентрации не могут существовать;
3. скорость реакции является непрерывной функцией концентраций реагентов.
Математически это означает, что функция изменения концентрации во времени не должна иметь разрывов.
Таким образом, исследователь при решении каждой конкретной задачи по управляемому биосинтезу популяций микроорганизмов проходит следующие этапы:
Гипотеза исследователя
ß
Дата добавления: 2019-09-02; просмотров: 331; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!