Задание на лабораторную работу
Разработать синтаксический анализатор подмножества заданного языка программирования на основе метода рекурсивного спуска. Варианты заданий приведены в таблице 2.1. Код задания на лабораторную работу состоит из трех компонент.
Первая цифра варианта определяет язык программирования (1- PL0, 2- ASPLE). Описание синтаксиса языков программирования PL0 и ASPLE приведены соответственно в приложениях 1 и 2.
Вторая цифра варианта определяет подмножество языка программирования. Описание подмножеств языков программирования PL0 и ASPLE приведены соответственно в приложениях 3 и 4.
Таблица 2.1
| Номер варианта | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| Код задания | 11П | 12С | 13П | 14С | 21П | 22С | 23П | 24С |
| Номер варианта | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| Код задания | 11С | 12П | 13С | 14П | 21С | 22П | 23С | 24П |
Третья цифра-язык программирования: П- Паскаль, С -Си.
Содержание отчета
4.1.Постановка задачи.
4.2.Исходная и преобразованная грамматики.
4.3.Текст программы.
4.4.Описание тестовых примеров.
4.5.Распечатка результатов.
Библиографический список
1. А.Ахо, Дж.Ульман. Теория синтаксического анализа, перевода и компиляции. Т.1. Синтаксический анализ. - М.: Мир, 1978. - 612с.
2. Р.Хантер. Проектирование и конструирование компиляторов. - М.: Финансы и статистика, 1984. - 232с.
3. Д.Грис. Конструирование компиляторов для ЦВМ. - М.: Мир, 1975.- 544 с.
4. Волкова И.А., Руденко Т.В. Формальные грамматики и языки. Элементы теории трансляции. –МГУ,1998.
|
|
|
ЛАБОРАТОРНАЯ РАБОТА № 3. ПРОГРАММИРОВАНИЕ НИСХОДЯЩЕГО СИНТАКСИЧЕСКОГО LL (1) - АНАЛИЗАТОРА
Цель работы: Изучение нисходящего синтаксического анализа методом LL (1), получение навыков в программировании алгоритмов синтаксического разбора
Постановка задачи синтаксического анализа. Организация данных. Общая схема алгоритмов детерминированного разбора
Синтаксический анализ (разбор) - это процесс, в котором исследуется цепочка лексем и устанавливается, удовлетворяет ли она условиям, сформулированным в определении синтаксиса языка /1/. Выходом синтаксического анализатора является синтаксическое дерево разбора, которое представляет синтаксическую структуру исходной программы.
Пример.
Зададим грамматику G(V,T,P,S) следующим набором правил (полагая, что терминальные символы в правых частях правил представлены соответствующими кодами лексем):
1) <S> ::= <E>
2) <E> ::= <T> + <E>
3) <E> ::= <T>
4) <T> ::= <F> * <T>
5) <T> ::= <F>
6) <F> ::= i
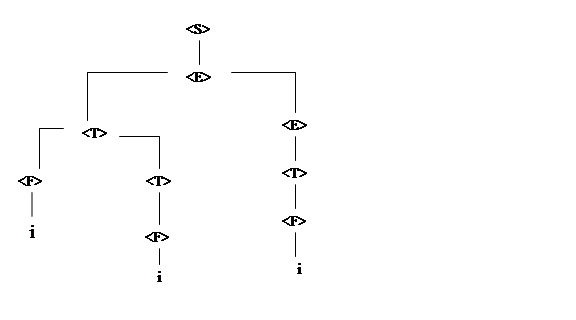
В результате синтаксического анализа цепочки i*i+i может быть построено синтаксическое дерево разбора (рис. 1) .
|
|
|
Рис.3.1. Синтаксическое дерево разбора
Прежде, чем приступить к изложению методов решения задачи синтаксического разбора, зафиксируем формы представления ее входных и выходных данных, их выбор существенно отражается на содержании алгоритма.
Рассмотрим возможную организацию структур перечисленных данных синтаксического анализатора. Входная цепочка лексем, очевидно, должна быть представлена последовательностью кодов фиксированной длины. Для представления грамматики удобно использовать списковую структуру /3/, каждая запись которой представляет символ C из правой части правила и состоит из четырех компонент (рис.3.2).
| ИМЯ | ||
| Опр. | Алт. | Преем. |
Имя - это сам символ C (в некоторой внутренней форме);
Опр - указатель на запись, соответствующую первому символу в правой части для C (0, если C - терминал);
Алт - указатель на первый символ альтернативной правой части, которая следует за правой частью, содержащей данный символ (используется только в записях первых символов правых частей);
Преем - указатель на следующий символ правой части.
Рис.3.2.Структура записи
Кроме того, для каждого нетерминала необходимо иметь указатель на первый символ в первой правой части правила этого нетерминала. Для облегчения поиска правила по его номеру эта дополнительная запись для каждого нетерминала помимо указателя может быть снабжена номером, который присвоен первому правилу данного нетерминала.
|
|
|
Списковая структура для грамматики вышеприведенного примера представлена на рис.3.
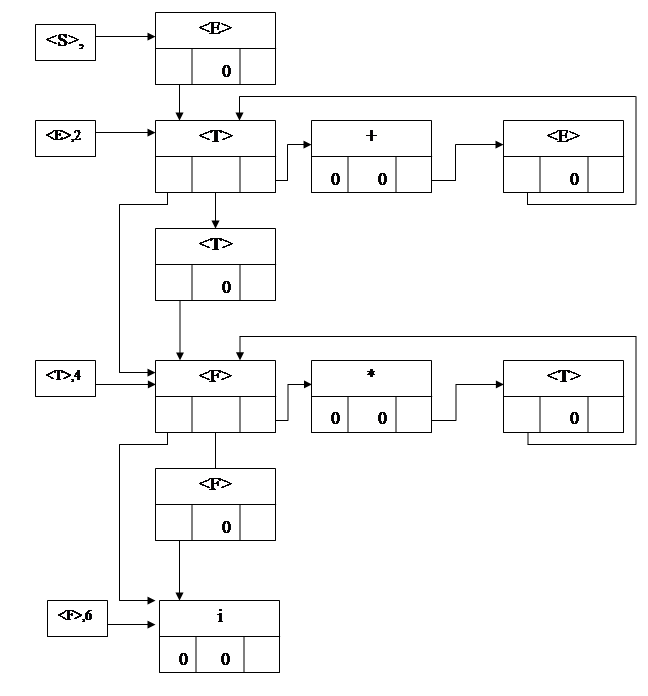 Рис.3.3. Списковая структура для заданной грамматики Синтаксическое дерево разбора может быть представлено с помощью стека, каждая запись которого содержит символ вершины дерева и указатель на запись, являющуюся ее предком. Дерево, полученное в вышерассмотренном примере, будет представлено стеком (таблица 3.1).
Рис.3.3. Списковая структура для заданной грамматики Синтаксическое дерево разбора может быть представлено с помощью стека, каждая запись которого содержит символ вершины дерева и указатель на запись, являющуюся ее предком. Дерево, полученное в вышерассмотренном примере, будет представлено стеком (таблица 3.1).
Таблица 3.1
| 14 | i , 13 |
| 13 | <F>, 12 |
| 12 | <T>, 5 |
| 11 | i , 10 |
| 10 | <F>, 8 |
| 9 | i , 6 |
| 8 | <T>, 3 |
| 7 | *, 3 |
| 6 | <F>, 3 |
| 5 | <E>, 2 |
| 4 | *, 2 |
| 3 | <T>, 2 |
| 2 | <E>, 1 |
| 1 | <S>, 0 |
При выполнении нисходящего разбора начальный символ грамматики будет размещаться на дне стека, а при выполнении восходящего разбора - в вершине стека.
Алгоритмы, предлагаемые для изучения в данной лабораторной работе, положены в основу функционирования однопроходных (детерминированных) синтаксических анализаторов. Возможность построения детерминированного анализатора обеспечивается ограничениями на класс контекстно-свободных (КС) грамматик, для которого проектируется этот анализатор. К наиболее распространенным таким классам грамматик, которые практически отражают все синтаксические черты языков программирования, определяемых с помощью КС-грамматик, относятся /1/:
|
|
|
1) LL(k)-грамматики, для которых левый анализатор работает детерминировано, если позволить ему принимать во внимание k входных символов, расположенных справа от текущей входной позиции;
2) LR(k)-грамматики, для которых правый анализатор работает детерминировано, если позволить ему принимать во внимание k входных символов, расположенных справа от текущей входной позиции;
3) грамматики предшествования, для которых правый анализатор может находить основу правовыводимой цепочки, учитывая только некоторые отношения между парами ее смежных символов.
Рассмотрим алгоритмы функционирования синтаксического анализатора в применении к LL(1)-, LR(1)-грамматикам и грамматикам простого предшествования. Помимо вышеперечисленных структур данных
(входные: цепочка лексем, описание грамматики языка; выходные: стек, содержащий синтаксическое дерево разбора), этими анализаторами используются еще две структуры: управляющая таблица и рабочий стек, предназначенный для хранения текущей сентенциальной формы в процессе выполнения разбора. Все три алгоритма работают по одной общей схеме, которая коротко может быть описана следующим образом. Входная цепочка просматривается слева направо, символ за символом. В зависимости от содержимого вершины рабочего стека (определяющего строку таблицы) и текущего входного символа (определяющего столбец таблицы) с помощью управляющей таблицы решается вопрос о выполнении одной из процедур: занесение входного символа в рабочий стек или преобразование содержимого вершины рабочего стека в соответствии с каким-либо правилом грамматики и с переносом прежнего содержимого вершины этого стека в выходной стек. Успешное завершение разбора входной цепочки происходит по окончании ее просмотра при условии, что рабочий стек оказывается пустым. Другой вариант окончания разбора - получение сообщения о том, что входная цепочка не принадлежит языку, описанному заданной грамматикой. Появление такого сообщения предусматривается управляющей таблицей, которая содержит его в своих элементах, соответствующих несочетаемым парам "содержимое вершины стека - входной символ".
Построение управляющей таблицы (автоматическое или вручную) выполняется во время проектирования синтаксического анализатора, и для алгоритма разбора она является постоянной таблицей. Ее построение выполняется в результате анализа порождающих правил грамматики языка, определения свойства этой грамматики (LL(k),LR(k) или предшествования) и, возможно, преобразования ее правил, если они не удовлетворяют желаемому свойству. Строки управляющей таблицы ставятся в соответствие возможным символам в вершине рабочего стека, столбцы - символам входного алфавита языка. Элемент таблицы, находящийся на пересечении заданной строки и заданного столбца, содержит инструкцию о следующем действии алгоритма.
Остановимся теперь на особенностях каждого из трех вышеперечисленных алгоритмов синтаксического разбора.
Дата добавления: 2019-02-12; просмотров: 302; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!