О применимости метода рекурсивного спуска
Метод рекурсивного спуска применим в том случае, если каждое правило грамматики имеет вид:
a) 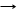 либо A a, где a Î (VT È VN)* и это единственное правило вывода для этого нетерминала;
либо A a, где a Î (VT È VN)* и это единственное правило вывода для этого нетерминала;
b) 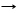 либо A a1a1 | a2a2 | ... | anan, где ai Î VT для всех i = 1,2,...,n; ai ¹ aj для i ¹ j; ai Î (VT È VN)*, т. е. если для нетерминала А правил вывода несколько, то они должны начинаться с терминалов, причем все эти терминалы должны быть различными.
либо A a1a1 | a2a2 | ... | anan, где ai Î VT для всех i = 1,2,...,n; ai ¹ aj для i ¹ j; ai Î (VT È VN)*, т. е. если для нетерминала А правил вывода несколько, то они должны начинаться с терминалов, причем все эти терминалы должны быть различными.
Ясно, что если правила вывода имеют такой вид, то рекурсивный спуск может быть реализован по выше изложенной схеме.
Естественно, возникает вопрос: если грамматика не удовлетворяет этим условиям, то существует ли эквивалентная КС-грамматика, для которой метод рекурсивного спуска применим? К сожалению, нет алгоритма, отвечающего на поставленный вопрос, т.е. это алгоритмически неразрешимая проблема.
Изложенные выше ограничения являются достаточными, но не необходимыми. Попытаемся ослабить требования на вид правил грамматики:
(1) при описании синтаксиса языков программирования часто встречаются правила, описывающие последовательность однотипных конструкций, отделенных друг от друга каким-либо знаком-разделителем (например, список идентификаторов при описании переменных, список параметров при вызове процедур и функций и т.п.).
Общий вид этих правил:

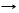 L a | a,L ( либо в сокращенной форме L a {,a} )
L a | a,L ( либо в сокращенной форме L a {,a} )
Формально здесь не выполняются условия применимости метода рекурсивного спуска, т.к. две альтернативы начинаются одинаковыми терминальными символами.
Действительно, в цепочке a,a,a,a,a из нетерминала L может выводиться и подцепочка a, и подцепочка a,a , и вся цепочка a,a,a,a,a. Неясно, какую из них выбрать в качестве подцепочки, выводимой из L. Если принять решение, что в таких случаях будем выбирать самую длинную подцепочку (что и требуется при разборе реальных языков), то разбор становится детерминированным.
Тогда для метода рекурсивного спуска процедура L будет такой:
void L()
{ if (c != 'a') ERROR();
while ((c = fgetc(fp)) == ',')
if ((c = fgetc(fp)) != 'a') ERROR();
}
Важно, чтобы подцепочки, следующие за цепочкой символов, выводимых из L, не начинались с разделителя (в нашем примере - с запятой), иначе процедура L попытается считать часть исходной цепочки, которая не выводится из L. Например, она может порождаться нетерминалом B - ”соседом” L в сентенциальной форме, как в грамматике
S ® LB^
L ® a {, a}
B ® ,b
Если для этой грамматики написать анализатор, действующий РС-методом, то цепочка а,а,а,b будет признана им ошибочной, хотя в действительности это не так.
Нужно отметить, что в языках программирования ограничителем подобных серий всегда является символ, отличный от разделителя, поэтому подобных проблем не возникает.
(2) если грамматика не удовлетворяет требованиям применимости метода рекурсивного спуска, то можно попытаться преобразовать ее, т.е. получить эквивалентную грамматику, пригодную для анализа этим методом.
a) если в грамматике есть нетерминалы, правила вывода которых леворекурсивны, т.е. имеют вид
A Aa1 | ... | Aan | b1 | ... | bm,
где ai Î (VT È VN)+, bj Î (VT È VN)*, i = 1, 2, ..., n; j =1, 2 ,..., m, то непосредственно применять РС- метод нельзя.
Левую рекурсию всегда можно заменить правой:
A b1A’ | ... | bmA’
A’ a1A’ | ... | anA’ | e
Будет получена грамматика, эквивалентная данной, т.к. из нетерминала A по-прежнему выводятся цепочки вида bj {ai}, где i = 1,2,...,n; j = 1,2,...,m.
b) если в грамматике есть нетерминал, у которого несколько правил вывода начинаются одинаковыми терминальными символами, т.е. имеют вид
 A aa1 | aa2 | ... | aan | b1 | ... |bm,
A aa1 | aa2 | ... | aan | b1 | ... |bm,
где a Î VT; ai, bj Î (VT È VN)*, то непосредственно применять РС-метод нельзя. Можно преобразовать правила вывода данного нетерминала, объединив правила с общими началами в одно правило:
A aA’ | b1 | ... | bm
A’ a1 | a2 | ... | an
Будет получена грамматика, эквивалентная данной.
c) если в грамматике есть нетерминал, у которого несколько правил вывода, и среди них есть правила, начинающиеся нетерминальными символами, т.е. имеют вид
A B1a1 | ... | Bnan | a1b1 | ... | ambm
B1 g11 | ... | g1k
. . .
Bn gn1 | ... | gnp,
где Bi Î VN; aj Î VT; ai, bj, gij Î (VT È VN)*, то можно заменить вхождения нетерминалов Bi их правилами вывода в надежде, что правило нетерминала A станет удовлетворять требованиям метода рекурсивного спуска:
A g11a1 | ... | g1ka1 | ... | gn1an | ... | gnpan | a1b1 | ... | ambm
d) если допустить в правилах вывода грамматики пустую альтернативу, т.е. правила вида
A a1a1 | ... | anan | e ,
то метод рекурсивного спуска может оказаться неприменимым (несмотря на то, что в остальном достаточные условия применимости выполняются).
Например, для грамматики G = ({a,b}, {S,A}, P, S), где
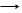 P: S bAa
P: S bAa
A aA | e
РС-анализатор, реализованный по обычной схеме, будет таким:
void S(void)
{if (c == ‘b’) {c = fgetc(fp); A();
if (c != ‘a’) ERROR();}
else ERROR();
}
void A(void)
{if (c == ‘a’) {c = fgetc(fp); A();}
}
Тогда при анализе цепочки baaa функция A() будет вызвана три раза; она прочитает подцепочку ааа, хотя третий символ а - это часть подцепочки, выводимой из S. В результате окажется, что baaa не принадлежит языку, порождаемому грамматикой, хотя в действительности это не так.
Проблема заключается в том, что подцепочка, следующая за цепочкой, выводимой из A, начинается таким же символом, как и цепочка, выводимая из А.
Однако в грамматике G = ({a,b,с}, {S,A}, P, S), где
P: S bAс
A aA | e
нет проблем с применением метода рекурсивного спуска.
Выпишем условие, при котором e-правило вывода делает неприменимым РС-метод.
Определение: множество FIRST(A) - это множество терминальных символов, которыми начинаются цепочки, выводимые из А в грамматике
G = (VT, VN, P, S), т.е. FIRST(A) = { a Î VT | A Þ aa, A Î VN, a Î (VT È VN)*}.
Определение: множество FOLLOW(A) -это множество терминальных символов, которые следуют за цепочками, выводимыми из А в грамматике
G = (VT, VN, P, S), т.е. FOLLOW(A) = { a Î VT | S Þ aAb, b Þ ag, A Î VN, a, b, g Î (VT È VN)*}.
| |
Тогда, если FIRST(A) Ç FOLLOW(A) ¹ Æ , то метод рекурсивного спуска неприменим к данной грамматике.
Если
A a1A | ... | anA | b1 | ... | bm| e
 B aAb
B aAb
и FIRST(A) Ç FOLLOW(A) ¹ Æ (из-за вхождения А в правила вывода для В), то можно попытаться преобразовать такую грамматику:
aA’
A’ a1A’ | ... | anA’ | b1b | ... |bmb| b
A a1A | ... | anA | b1 | ... |bm| e
Полученная грамматика будет эквивалентна исходной, т.к. из B по-прежнему выводятся цепочки вида a {ai} bj b либо a {ai} b.
Однако правило вывода для нетерминального символа A’ будет иметь альтернативы, начинающиеся одинаковыми терминальными символами, следовательно, потребуются дальнейшие преобразования, и успех не гарантирован.
Метод рекурсивного спуска применим к достаточно узкому подклассу КС-грамматик. Известны более широкие подклассы КС-грамматик, для которых существуют эффективные анализаторы, обладающие тем же свойством, что и анализатор, написанный методом рекурсивного спуска, - входная цепочка считывается один раз слева направо и процесс разбора полностью детерминирован, в результате на обработку цепочки длины n расходуется время cn. К таким грамматикам относятся LL(k)-грамматики, LR(k)-грамматики, грамматики предшествования и некоторые другие (см., например, [2], [3]).
Порядок выполнения работы
2.2.1 Произвести проверку применимости метода рекурсивного спуска, при необходимости выполнить существующие преобразования грамматики.
2.2.2 Разработать и отладить синтаксический анализатор, который должен быть оформлен в виде отдельной процедуры (подпрограммы).
Дата добавления: 2019-02-12; просмотров: 357; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!