Задание на лабораторную работу
Nbsp;
Министерство образования и науки Украины
Севастопольский национальный технический университет
МЕТОДИЧЕСКИЕ УКАЗАНИЯ
к выполнению лабораторных работ
по дисциплине “Системное программное обеспечение ЭВМ”
Для студентов специальности 7.091501
“Компьютерные системы и сети”
Всех форм обучения
Севастополь
2014
Методические указания содержат краткое изложение основных теоретических положений, задания на лабораторные работы, порядок их выполнения, список рекомендованной литературы.
Методические указания утверждены на заседании кафедры кибернетики и вычислительной техники __28 октября__ 2007г, протокол N_3_
Методические указания разработали к.т.н., доцент Максимова Т.М., к.т.н., доцент Фисун С.Н.., ст.преп Шалимова Е.М.
Рецензент: д.т.н., профессор Цуканов А.В.
СОДЕРЖАНИЕ
Стр.
1 Лабораторная работа № 1. Программирование сканера 4
2 Лабораторная работа № 2. Синтаксический анализ методом рекурсивного спуска 10
3 Лабораторная работа № 3. Программирование нисходящего синтаксического LL(1) анализатора 16
4 Лабораторная работа № 4. Восходящий синтаксический анализ методом предшествования 25
|
|
|
5 Лабораторная работа № 5. Восходящий синтаксический анализ методом LR(1) 30
6 Лабораторная работа № 6. Оптимизация объектного кода 35
7 Лабораторная работа № 7. Трансляция выражений 41
Приложения
ЛАБОРАТОРНАЯ РАБОТА № 1. ПРОГРАММИРОВАНИЕ СКАНЕРА
Цель работы: Изучение организации данных лексического анализатора, приобретение навыков в построении регулярных грамматик и их автоматных моделей и программировании алгоритмов разбора с помощью таких грамматик.
Теоретические сведения
Лексический анализ представляет собой первую фазу процесса компиляции, при которой отдельные литеры входной цепочки группируются в слова (лексемы). Каждому распознанному слову входного языка ставится в соответствие некоторое внутреннее представление. Часто термин "лексема" относят и к этому внутреннему представлению. Во избежание двусмысленности будем называть внутреннее представление лексемы кодом лексемы.
Например, если предложения входного языка представляют собой списки идентификаторов, разделенных запятыми, то результатом лексического анализа предложения abc,d1,ef2 при условии, что коды лексем зафиксированы в таблице лексем (таблица 1), будет следующий список кодов: 2 1 3 1 4 .
|
|
|
Таблица 1.1
| Лексема | Код лексемы |
| , abc d1 ef2 | 1 2 3 4 |
Множество различных лексем языка программирования обычно бесконечно. Поэтому формирование таблицы лексем выполняется в процессе анализа конкретной входной цепочки. При этом каждый экземпляр определенной лексемы, присутствующий во входной цепочке, должен получить в выходном списке один и тот же код, что обеспечивается наличием вышеуказанной таблицы.
Код лексемы обычно представляет собой пару вида (тип лексемы, некоторые данные) /1/. Первая компонента пары является синтаксической категорией, указывая принадлежность лексемы какой-либо непосредственной составляющей грамматики. В грамматиках языков программирования, как правило, к таким непосредственным составляющим относятся: идентификатор, константа, разделитель и др. Вторая компонента кода может быть указателем на месторасположение информации об этой конкретной лексеме, в частности, - просто номером соответствующей записи в таблице лексем.
Обозначим в вышерассмотренном примере тип лексемы символом "r", если она является запятой, и символом "i", если она принадлежит категории <идентификатор>. Тогда код лексемы "," приобретет вид: r1, а коды лексем "abc", "d1" и "ef2", соответственно: i2, i3 и i4. При этом вторая компонента кода является указателем на соответствующую запись таблицы лексем.
|
|
|
Синтаксис лексем, как правило, описывается в рамках автоматной грамматики, или грамматики типа 3 в соответствии с классификацией Хомского /2/. Это означает, что лексический анализатор (сканер) может быть организован в виде модели конечного автомата. Так, если порождающие правила грамматики имеют вид: <U>::=<W>N и <U>::=N, где <U>,<W> - нетерминальные, а N - терминальный символы грамматики, то соответствующий автомат определяется пятеркой /2/:
1) конечное множество V внутренних состояний, каждое из которых, за исключением одного (обозначим его - F), соответствует нетерминальному символу грамматики;
2) конечный входной алфавит T, каждый символ которого соответствует терминальному символу грамматики;
3) множество P переходов; при этом правилу грамматики <U>::=<W>N в автоматной модели соответствует переход P(W,N)=U, а правилу <U>::=N - переход P(F,N)=U;
|
|
|
4) начальное состояние F;
5) множество S последних состояний, соответствующее множеству нетерминалов грамматики, являющихся альтернативными определениями ее аксиомы (начального символа). Попадание автомата в одно из состояний множества S означает, что процесс распознавания входного слова закончен. Можно сказать, что каждому из последних состояний соответствует свой выходной символ (свойство модели автомата Мура /3/), при появлении которого на выходе автомата запускается соответствующая семантическая подпрограмма сканера, формирующая код распознанной лексемы.
Например, грамматике G[<S>] с порождающими правилами:
<S>::=<X>$
<X>::=<U>0|<V>1
<U>::=<X>1|1
<V>::=<X>0|0
соответствует автоматная модель, представленная на рис.1 в виде графа переходов и выходов и на рис.2 в виде матрицы переходов и выходов, где y1 - символ, сигнализирующий об успешном окончании распознавания слова, поступившего на вход автомата.
Граф переходов и выходов конечного автомата Мура
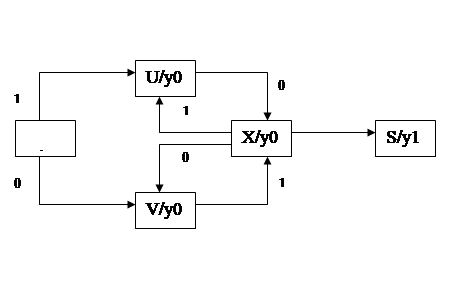

Рис.1.1
Матрица переходов и выходов конечного автомата Мура
| F | U | V | X | S | |
| 0 | V | X | - | V | - |
| 1 | U | - | X | U | - |
| $ | - | - | - | S | - |
| y0 | y0 | y0 | y0 | y1 |
Рис.1.2
Символами "-" в матрице переходов отмечены запрещенные переходы в автомате, попадание в соответствующую клетку матрицы переходов означает наличие ошибки во входной цепочке терминальных символов. Можно ввести дополнительное внутреннее состояние автомата - E("ошибка") - и заменить в матрице переходов символы "-" символами состояния E, снабдив его выходом yE, по которому запускается семантическая подпрограмма обработки ошибочной ситуации.
Построенный автомат является автоматом однократного действия, т.е. предназначен для распознавания одного слова входной цепочки. Для преобразования его в автомат многократного действия можно, полагая состояние S неустойчивым, описать переход из него при неизменном входном символе в начальное состояние F. Другой вариант преобразования - построить автомат Мили /3/, в котором состояния F и S исходного автомата будут объединены, и переход в это объединенное состояние будет сопровождаться появлением выходного символа y1. Граф переходов для такой автоматной модели изображен на рис.3.
Граф переходов и выходов конечного автомата Мили
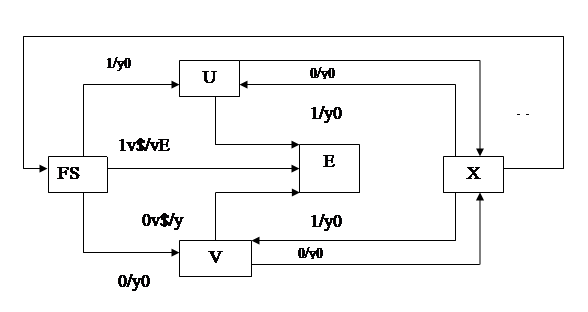
Рис. 1.3
В ЭВМ автоматная модель может быть представлена /2/ двумерным массивом, соответствующим матрице переходов, или списочной структурой. Во втором случае каждое состояние с k дугами, исходящими из него, занимает 2*k+2 слов. Первое слово - имя состояния, второе - значение k. Каждая последующая пара слов содержит терминальный символ из входного алфавита и указатель на начало представления состояния, в которое надо перейти по этому символу. Для вышерассмотренного графа переходов список имеет вид:
F 2 1 7 0 11 U 1 0 15 V 1 1 15 X 3 0 11 1 7
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
$ 23 S 0
21 22 23 24
Порядок выполнения работы
1.2.1.Построить регулярную грамматику для заданного языка(в соответствии с вариантом).При распознавании лексемы выбирается самое короткое слово входной цепочки.
1.2.2.Построить конечный автомат для полученной грамматики.
1.2.3.Разработать и отладить лексический анализатор - препроцессор на основе построенной автоматной модели. Лексический анализатор должен быть оформлен в виде отдельной процедуры (подпрограммы).
Задание на лабораторную работу
Варианты заданий приведены в таблице 2.
Таблица 1.2
| номер варианта | код задания | номер варианта | код задания |
| 1 2 3 4 5 6 7 8 9 10 | П 1 П 2 П 3 П 4 П 5 П 6 П 7 П 8 П 9 П 10 | 11 12 13 14 15 16 17 18 19 20 | С 1 С 2 С 3 С 4 С 5 С 6 С 7 С 8 С 9 С 20 |
Код задания состоит из двух компонент. Первая - П или С - определяет язык программирования, ПАСКАЛЬ или СИ соответственно; вторая - номер варианта описания языка.
Варианты описаний языков.
1) Цепочка символов "а" произвольной длины, после которой следует символ "b";
цепочка символов "а" произвольной длины, после которой следует символ "с";
цепочка символов "b" произвольной длины, после которой следуют "а"или "с".
2) Цепочка пар символов "а""b"произвольной длины, после которой следует "b";
цепочка пар символов "b""а"произвольной длины, после которой следует "с";
символ "с".
3) Произвольная цепочка символов из "а","b","с", заканчивающаяся "а","b","с";
произвольная цепочка символов из "а","b","с", заканчивающаяся "с","b","а".
4) Три подряд пришедших символа "а" в произвольной цепочке из "а" и "b", после которых следует "b";
три подряд пришедших символа "b", после которых следует "а";
три подряд пришедших символа "b", после которых следует "с".
5) Произвольное число символов "а" между двумя символами "b"; произвольное число символов "b" между двумя символами "с"; три подряд пришедших символа "с".
6) Произвольная цепочка из 0 и 1 между /* и */; последовательность двух пар 01; символ *.
7) Произвольная цепочка из 0 и 1,после которой следует "."; цепочка четной длины из 0 и 1 между двумя символами "."; два символа ".".
8) Цепочка четной длины из 0 между двумя 1; цепочка нечетной длины из 1 между двумя 0; две 1 подряд.
9) 1 между двумя цепочками из 0, четной длины каждая, после которых следует символ «.»;
0 между двумя цепочками из 1, четной длины каждая, после которых следует символ «.».
10) Две 1 ,за которыми следует два 0;
цепочка чередующихся 0 и 1 нечетной длины, за которой следует ".".
Содержание отчета
1) Постановка задачи.
2) Регулярная грамматика.
3) Граф автоматной модели грамматики и соответствующая таблица переходов и выходов.
4) Текст программы.
5) Описание тестовых примеров.
6) Распечатка результатов.
Библиографический список
1.А.Ахо, Дж. Ульман. Теория синтаксического анализа, перевода и компиляции. Т.1. Синтаксический анализ. - М.: Мир,1978. - 612c.
2.Д.Грис. Конструирование компиляторов для цифровых вычислительных машин. - М.: Мир, 1975. - 544c.
3.Р.Миллер. Теория переключательных схем. Т.1. - М.: Наука.
Главная редакция физико-математической литературы, 1970. -
416c.
Дата добавления: 2019-02-12; просмотров: 358; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!