Процесс восстановления данных при помощи декодера RLE вполне очевиден.
Методы контекстного моделирования
Для осуществления эффективного сжатия сообщений, поступающих с выхода источника информации, требуется знание его характеристик. При рассмотрении источников с памятью в качестве таких характеристик принято брать условные вероятности появления символов в сообщении вслед за различными символьными последовательностями. В случае, когда нет никакой дополнительной информации об источнике, определить эти вероятности можно только путем статистического анализа его информационной выборки. Данный принцип лежит в основе методов контекстного моделирования.
Последовательность символов, непосредственно предшествующую некоторому символу в информационном сообщении, принято называть контекстом этого символа, а длину этой последовательности – порядком контекста. На основе статистики, собираемой во время обработки информации, метод контекстного моделирования позволяет оценить вероятность появления в текущем контексте произвольного символа или последовательности символов. Оценка вероятности определяет длину кода, который генерируется с использованием алгоритма Хаффмена, арифметического кодирования или другого метода, основанного на вероятностной модели (такие методы называются методами энтропийного кодирования). Методы контекстного моделирования в большинстве своем являются адаптивными методами. Вычисление вероятностных оценок осуществляется одним и тем же способом на этапах кодирования и декодирования, что позволяет не хранить описание информационной модели.
|
|
|
Методы контекстного моделирования отличаются способом получения оценок условных вероятностей появления символов в различных контекстах. Можно выделить четыре основных способа получения таких оценок, которые легли в основу соответственно четырех статистических методов: метода PPM, метода DMC, метода CTW и нейросетевого метода.
Наибольшее распространение среди перечисленных методов получил метод PPM. Метод DMC, хотя и появился практически одновременно с методом PPM, все же не получил такого широкого распространения. Он обладает меньшей эффективностью в сравнении с методом PPM и представляет интерес в основном только с идейной точки зрения. Метод CTW стал результатом целенаправленных теоретических исследований по поиску так называемого «универсального» метода сжатия данных. Нейросетевой метод первоначально разрабатывался как общий метод моделирования и предсказания в рамках теории искусственных нейронных сетей, а затем был использован в области сжатия информации.
Оценку вероятности появления символов на выходе источника информации можно получать на основе контекстов только некоторого строго определенного порядка. В этом случае говорят, что используется контекстная модель соответствующего порядка. Такой метод малоэффективен по причине того, что реальные информационные источники, как правило, не обладают постоянной памятью. Более разумно при определении вероятностей появления символов учитывать модели разных порядков, т.е. производить так называемое смешивание моделей.
|
|
|
Очевидно, что конечный вклад различных моделей в вероятностную оценку должен как-то различаться. Одним из возможных решений этой проблемы является введение весов, определяющих влияние той или иной модели на результирующую оценку. В методе PPM используется несколько более упрощенный подход. Вероятность появления символа всегда оценивается в текущем контексте какого-то одного порядка, то есть в некоторой конкретной контекстной модели.
Вариации метода PPM работают по следующей схеме. Первоначально для оценки вероятности появления символа берется контекст некоторого заранее определенного достаточно большого порядка (выбирается некая конкретная контекстная модель). Если кодируемый символ ранее в таком контексте не встречался, то вероятность его появления не может быть оценена с использованием выбранной модели. В этом случае кодер генерирует код служебного символа перехода (ESCAPE-символ), сигнализирующего о невозможности использования рассматриваемой модели и необходимости перехода к другой модели. После этого осуществляется попытка оценить вероятность появления кодируемого символа с помощью модели следующего по убыванию порядка (возможен переход и на модель более низкого порядка). Если использование новой модели также не позволяет получить вероятностную оценку, кодер снова генерирует код служебного символа перехода и снова рассматривается модель меньшего порядка и т. д. Для гарантии завершения описанного процесса вводится дополнительная модель 1-го порядка, с одинаковой вероятностью оценивающая появление всех символов информационного алфавита (т.е. символ будет оценен, даже если он ранее вообще не встречался). В дальнейшем рассмотренная схема будет называться схемой контекстного спуска.
|
|
|
При оценке вероятности появления символа в методе PPM учитываются самые различные контекстные модели, причем, на первый взгляд, этого удается достичь без использования весов. В действительности это не совсем так. Вес незримо присутствует в вероятностной оценке и определяется вкладом, вносимым служебными символами перехода. Символы перехода фактически оказываются полноправными символами информационного алфавита. Как и обычным символам, символам перехода необходимо ставить в соответствие определенные кодовые комбинации. Это приводит к необходимости учета символов перехода при накоплении статистической информации, что следует рассматривать как неявное взвешивание.
|
|
|
Говорить о неких отдельно взятых кодовых комбинациях, когда речь идет об арифметическом кодировании не совсем корректно. Под кодами обрабатываемого и служебного символов в этом случае подразумевается вклад соответствующих условных вероятностей в результирующую вероятностную оценку, используемую для вычисления длины кода для всей обрабатываемой информации. Вклад каждого кодируемого символа определяется вероятностями появления задействованных при его кодировании служебных символов перехода (данные вероятности определяются отдельно в рамках каждой модели) и вероятностью появления самого символа в оценивающей модели (модели, задействованной для оценки).
При оценке вероятности появления символа в контексте можно использовать два различных подхода. Первый сопряжен с вычислением вероятностной оценки в модели данного порядка без учета моделей более высоких порядков. Такой подход недостаточно эффективен, так как, если символ может быть оценен моделью некоторого порядка, то, согласно описанной схеме, он никогда не будет оценен моделью более низкого порядка, что, однако, никак не учитывается при получении оценки с применением моделей низших порядков. Для примера рассмотрим ситуацию, когда требуется оценить вероятность появления символа c в контексте bcabdab, при условии, что оценка производится, начиная с модели второго порядка. Так как символ c в контексте ab ранее не встречается, то в кодовую последовательность добавляется код служебного символа перехода, сигнализирующий о необходимости оценки символа «с» с использованием модели первого порядка. Теперь оценка производится с учетом текущего контекста первого порядка – b. В данном контексте встречаются два символа: c и d. Однако символ d встречается также и в контексте второго порядка ab. Значит, в случае его появления в текущем контексте вместо символа c он был бы закодирован с применением модели второго, а не первого порядка. Следовательно, символ d не имеет смысла учитывать при оценке вероятности появления символа c в контексте b. Итак, второй подход заключается в учете при вычислении вероятностной оценки контекстных моделей более высокого порядка по сравнению с порядком модели, используемой для оценки.
Про вариации метода PPM, основанные на последнем подходе, говорят, что они используют механизм исключений, так как из вероятностной оценки исключается вклад моделей более высоких порядков. Применение механизма исключений приводит к повышению эффективности кодирования, однако из-за увеличения сложности оценки значительно снижается его производительность.
Для повышения скорости кодирования в практических реализациях метода PPM применяются так называемые исключения при обновлении. Обновление – процесс, заключающийся в адаптивном изменении параметров различных контекстных моделей во время обработки информации. Изменения, вносимые после кодирования (декодирования) очередного символа, обычно сводятся к увеличению содержимого счетчиков появления данного символа в текущих контекстах разного порядка. Содержимое счетчиков в дальнейшем используется при вычислении вероятностных оценок. В случае применения механизма исключений при обновлении содержимое счетчика для символа в контексте не увеличивается, если данный символ оценивается контекстом более высокого порядка (т.е. производится обновление всех моделей, порядок которых больше или равен порядку модели, использованной для оценки символа). Такой подход дает значительный выигрыш в скорости работы, так как ограничивается количество операций, необходимых для обновления моделей на каждом шаге, а кроме того, использование данного подхода позволяет немного увеличить эффективность кодирования (последнее достигается за счет повышения роли контекстных моделей, непосредственно задействованных при получении оценок). Заметим, что механизм исключений при обновлении не является заменой для механизма простых исключений, хотя исключения при обновлении частично выполняют функцию простых исключений. Поэтому для достижения наибольшей эффективности обычно задействуются сразу оба механизма. Способ оценки вероятностей переходов и появлений символов в методе PPM является предметом особого рассмотрения. Как правило, вариации метода различаются именно по способу оценки. В методе PPMA вероятность перехода к другой модели и вероятность появления символа в текущем контексте определяются в соответствии с формулами
 ,
,
где c – число появлений текущего контекста, cs – число появлений символа s в текущем контексте. Для определения c и cs для каждого символа в модели заводится отдельный счетчик.
Метод PPMB использует другие оценки:
 ,
,
где d – число различных символов, встреченных в текущем контексте. При оценке вероятности в этих методах применяется механизм исключений.
Более эффективным является метод PPMC. Для вычисления вероятностных оценок в данном методе используются формулы
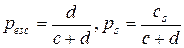 .
.
Символ перехода рассматривается здесь как обычный символ. Для него заводится особый счетчик, содержимое которого увеличивается на 1 при каждом появлении в текущем контексте ранее не встречавшегося символа. Появление такого символа означает увеличение суммарного веса модели на 2, так как на 1 увеличивается содержимое счетчиков самого символа и символа перехода. С целью повышения производительности в методе PPMC используются исключения при обновлении.
Дальнейшим развитием метода PPMC стал метод PPMD. Он отличается от метода PPMC тем, что при появлении символа, который ранее не встречался в текущем контексте, содержимое счетчиков обычного символа и символа перехода увеличиваются не на 1, а на 1/2. Таким образом, суммарный вес модели всегда увеличивается на 1, что, как оказывается, положительно влияет на эффективность кодирования. Формулы для определения вероятностных оценок в данном случае приобретают вид
 .
.
Среди методов, использующих другие оценки, особого упоминания заслуживают методы PPMP, PPMX и PPMXC. Эффективность метода PPM во многом предопределяется правильностью выбора порядка первой оценивающей модели. Этот порядок должен находиться в полном соответствии с порядком памяти кодируемого информационного источника. Опытным путем было установлено, что при обработке англоязычной текстовой информации в качестве первой оценивающей модели следует выбирать модель, порядок которой лежит в пределах от 4 до 6. Данное решение вполне оправданно по отношению не только к указанной информации, но и ко многим другим распространенным типам информации, в частности, к русскоязычной текстовой информации. При этом, однако, оно абсолютно неприменимо в случае, когда порядок памяти порождающего источника достаточно мал (частая генерация символов перехода при недостаточно адекватной оценке вероятности их появления может стать причиной снижения эффективности кодирования). Несмотря на то, что выбор первой оценивающей модели далеко не однозначен, во всех вышеупомянутых вариациях метода PPM порядок этой модели фиксируется. В данном случае можно говорить о четкой ориентации на источники, порядок памяти которых ограничен и меняется в очень незначительных пределах, но большинство реальных информационных источников далеки от такого приближения.
Поэтому наиболее эффективным кодирование станет только тогда, когда порядок первой оценивающей модели будет меняться в зависимости от особенностей обрабатываемой информации. Алгоритм выбора первой оценивающей модели в процессе кодирования больше известен под аббревиатурой LOE (Local Order Estimation). Один из вариантов LOE состоит в том, чтобы в качестве первой оценивающей модели выбирать модель, лучше всего предсказывавшую в прошлом появление символов. Другое (более удачное) решение нашло свое отражение в методе PPM*, где для оценки появления очередного символа допускается использование контекстной модели неограниченного порядка. При оценке задействованы так называемые детерминированные контексты, т.е. такие контексты, которые предсказывают появление ровно одного символа. Выбор первой оценивающей модели производится в соответствии со следующим правилом. Среди всех детерминированных контекстов выбирается контекст с минимальным порядком, а в случае отсутствия таковых берется уже ранее встречавшийся в сообщении контекст максимального порядка. Выбранный контекст используется первым при получении вероятностной оценки.
Вероятности появления символов в методе PPM* вычисляются по формулам, используемым в методе PPMC. Вместо исключений при обновлении здесь предлагается применять частичные исключения при обновлении. Они отличаются тем, что при использовании частичных исключений обновлению подлежит содержимое счетчиков появления обработанного символа не во всех контекстах, а только в детерминированных контекстах и в одном недетерминированном контексте – в том, который имеет наибольший порядок (имеются в виду контексты, использованные для оценки символа).
Альтернативное решение проблемы LOE было использовано в алгоритме PPMZ. В качестве первой оценивающей модели здесь предлагается выбирать ту модель, в рамках которой вероятность появления наиболее вероятного символа имеет наибольшее значение. При этом механизм LOE применяется совместно с новым механизмом. Помимо оригинального подхода к выбору первой оценивающей модели в алгоритме PPMZ используется особый способ получения вероятностных оценок. Формулы, в соответствии с которыми определяются вероятности появления обычных символов и символов перехода, включают в себя свободные коэффициенты, меняющиеся в процессе кодирования в зависимости от особенностей обрабатываемой информации.
В совокупности указанные решения позволяют добиться очень высокой эффективности кодирования. При практических реализациях метода PPM основной проблемой является обеспечение хранения большого массива статистической информации. Например, если рассматривать только модели первого порядка, для хранения статистической информации в формате, в котором под каждый счетчик появлений символа в контексте отводится ровно один байт, может потребоваться до 64 килобайт памяти (здесь подразумевается, что используется алфавит из 256 символов). Поэтому для того, чтобы избежать переполнения памяти, количество счетчиков ограничивается, что означает ограничение количества контекстов, используемых для получения вероятностных оценок.
Для хранения накапливаемой статистической информации в практических реализациях метода PPM в большинстве случаев используются деревья цифрового поиска и всевозможные хэш-структуры, позволяющие компактно представлять данные и производить быстрый поиск контекстов.
Методы сжатия с потерями
Все методы сжатия, описанные до этого, являются методами без потерь. Методы сжатия с потерями применяются, как правило, для хранения графических, звуковых и видеоданных. Рассмотрим принципы работы данных методов на примере сжатия графики с использованием дискретного косинусного преобразования (ДКП).
Пусть имеется непрерывный периодический сигнал a(t) с периодом T. Его можно представить в виде:
 .
.
Можно подобрать систему функций 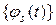 , s = 0, 1, …, N – 1, так, чтобы:
, s = 0, 1, …, N – 1, так, чтобы:
- ни одна из них не могла быть получена линейной комбинацией других:
 ;
;
- за скалярное произведение принимается
 ;
;
- они попарно ортогональны и нормированы:
 .
.
Такой выбор системы функций  , s = 0, 1, …, N – 1, позволяет представить сигнал a(t) в виде точки N-мерного функционального пространства с координатами a s. Систему функций
, s = 0, 1, …, N – 1, позволяет представить сигнал a(t) в виде точки N-мерного функционального пространства с координатами a s. Систему функций  , s = 0, 1, …, N – 1, называют базисом пространства сигналов, каждую из функций – базисной, представление сигнала в форме композиции базисных функций – разложением по заданному базису. Координаты точки, соответствующие сигналу a(t), можно найти по формуле
, s = 0, 1, …, N – 1, называют базисом пространства сигналов, каждую из функций – базисной, представление сигнала в форме композиции базисных функций – разложением по заданному базису. Координаты точки, соответствующие сигналу a(t), можно найти по формуле
 .
.
Существует множество систем функций, обладающих свойствами базиса. В частности базис образует система функций вида:
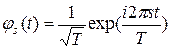 .
.
Разложение сигнала по этому базису называют разложением Фурье, а нахождение коэффициентов разложения – преобразованием Фурье. Преобразование Фурье выполняется по формуле:
 .
.
В дальнейшем будем рассматривать периодический сигнал, который принимает значения в дискретные моменты времени
 ,
,
где  , N – количество разбиений интервала T. Тогда, непрерывный сигнал a(t) заменяется на последовательность отсчетов
, N – количество разбиений интервала T. Тогда, непрерывный сигнал a(t) заменяется на последовательность отсчетов
a((k + 0.5)Dt) = ak, k = 0, 1, …, N – 1,
взятых посредине отрезков разбиения Dt, а формулы преобразования Фурье приобретают вид
 . (6.1)
. (6.1)
Формула (7.1) задает прямое ДКП, которое выполняется по базису
 ,
,
где cs – нормировочный множитель, определяемый как
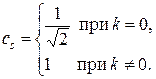
Данное преобразование обратимо, т.е. существует обратное ДКП. Оно задается формулой
 . (6.2)
. (6.2)
В выражении (7.2) элементы  есть дискретные отсчеты базисных функций, где s – номер базисной функции, k – номер отсчета дискретизации базисной функции. Их значения образуют матрицу N ´ N, которую обозначим
есть дискретные отсчеты базисных функций, где s – номер базисной функции, k – номер отсчета дискретизации базисной функции. Их значения образуют матрицу N ´ N, которую обозначим  . Тогда прямое и обратное ДКП можно записать в матричной форме:
. Тогда прямое и обратное ДКП можно записать в матричной форме:
 (6.3)
(6.3)
где a = (a0, a1, …, a N – 1)T, a = (a0, a1, …, aN – 1)T.
Описанные прямое и обратное ДКП являются одномерными преобразованиями. Однако их можно обобщить для двумерного сигнала, представленного в виде матрицы размера N ´ N. В результате ДКП над двумерным сигналом получается также матрица размера N ´ N коэффициентов разложения по базисным функциям:
 , s = 0, 1, …, N – 1, r = 0, 1, …, N – 1.
, s = 0, 1, …, N – 1, r = 0, 1, …, N – 1.
Формулы в матричной форме для выполнения прямого и обратного двумерного ДКП имеют вид
 (6.4)
(6.4)
Матрица FN зависит только от N и может быть просчитана заранее. Например, при N = 8 она будет иметь вид.

При сжатии графических данных файл представляет собой последовательность пикселей – значений цвета точек изображения. Можно считать, что значение пикселя представляет собой вектор-функцию вида
f(x, y) = (r, g, b),
где x, y – координаты пикселя, r, g, b – яркости красной, зеленой и синей компонент цвета (считается, что любой цвет можно разложить на три указанные компоненты). При использовании методов сжатия, основанных на ДКП, последовательность пикселей разбивают на блоки размером 8 ´ 8 и обрабатывают эти блоки по отдельности. При этом из каждого блока выделяют матрицы яркостей красной, зеленой и синей компонент.
Предположим, что матрица яркостей одной из компонент какого-либо блока имеет вид
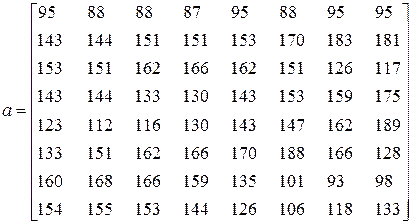
Теперь последовательно выполним следующие шаги.
1. Все данные смещаются на 128. Новое значение матрицы данных
a СМ = a – 128:
 .
.
2. Выполняются ДКП над смещенными данными:  ; результаты округляются до целых значений:
; результаты округляются до целых значений:
 .
.
3. Выполняется загрубение коэффициентов разложения. Этот шаг требует подробного объяснения, так как именно он является основным для сжатия изображения. Дело в том, что каждый коэффициент разложения характеризует вклад соответствующей базисной функции (гармоники) в формирование сигнала. Чем больше сумма значений индексов у коэффициента, тем выше частота соответствующей ему гармоники (гармоника представляет собой косинусоиду). Гармонические составляющие с большими частотами переносят более мелкие подробности изображения, неразличимые зрением. Поэтому некоторые коэффициенты могут быть отброшены и за счет этого уменьшен объем данных, если их хранить или передавать не как отсчеты сигнала, а как результаты ДКП. Для этого коэффициентам с большими индексами необходимо установить больший порог значимости, например следующим образом:

где Q – параметр, задающий степень сжатия. Для рассматриваемого примера при Q = 4 получим
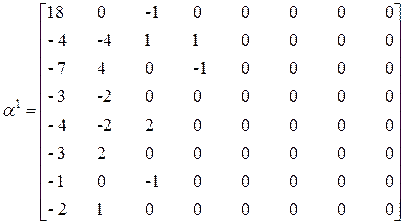 .
.
4. Кодирование данных. На этом шаге сначала полученные коэффициенты матрицы a1 представляют в виде линейной последовательности
 ,
,
т.е. в зигзагообразном порядке. Для нашего примера будет получена следующая последовательность:
18, 0, –4, –7, –4, –1, 0, 1, 4, –3, –4, –2, 0, 1, 0, 0, 0, –1, 0, –2, –3, –1, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, –2, 1, –1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.
Затем серии нулей кодируют методом RLE, что дает существенное сжатие (например, в приведенной последовательности имеется одна серия из 3 нулей, одна серия из 11 нулей и одна серия из 26 нулей). Кроме того, для улучшения сжатия дополнительно можно применить метод Хаффмена или арифметического кодирования.
Для восстановления данных выполняются обратные действия:
1. восстанавливается матрица a1;
2. восстанавливается матрица a:
 ;
;
3. восстанавливается матрица a СМ:
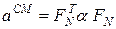 ;
;
4. восстанавливается матрица a:
a = a СМ + 128.
Восстановленная матрица будет отличаться от исходной матрицы. Однако при правильном подборе параметра, задающего степень сжатия, отличия не будет восприниматься человеком, рассматривающим изображение.
Подчеркнем, что шаги компрессии и декомпрессии выполняются для всех компонент всех блоков графического файла.
Изложенный метод служит основой сжатия данных по известному стандарту JPEG. Он также является основой метода сжатия, применяемого при представлении видеоданных в стандарте MPEG. Аналогичные методы применяются также и для сжатия звуковых данных.
Дата добавления: 2018-10-26; просмотров: 236; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!