Методы кодирования длин серий
Сжатие информации
Основные понятия
При проектировании информационных систем часто необходимо минимизировать затраты на передачу и хранение информации. Добиться этого можно с помощью кодирования, устраняющего избыточность информации. При решении практических задач такое кодирование называют сжатием информации. При сжатии информации, изначально представленной в дискретном виде, говорят о сжатии данных. При этом часто говорят, что сжимается файл или поток данных. Для описания методов сжатия данных используются следующие основные понятия и характеристики.
Компрессор или кодер – программа (устройство), которая сжимает исходные данные, т.е. преобразует входной несжатый файл в выходной сжатый файл. Программа (устройство), выполняющая обратное преобразование (восстановление исходных данных из сжатого файла), называется декомпрессором или декодером. Компрессор и декомпрессор вместе образуют кодек.
Методы сжатия данных делятся на неадаптивные, адаптивные, полуадаптивные и локально адаптивные методы. Неадаптивный метод сжатия данных (метод неадаптивного сжатия данных) – метод сжатия данных, в котором не предусмотрена возможность изменения операций, параметров и настроек в зависимости от характера сжимаемой информации. Метод, в котором предусмотрена возможность изменения операций, параметров и настроек в зависимости от характера сжимаемых данных, называется адаптивным методом. Если для изменения операций, параметров и настроек предварительно собирается некоторая статистика сжимаемой информации, то метод сжатия называется полуадаптивным (говорят, что реализуется двухпроходное сжатие: на первом проходе выполняется анализ информации, а на втором – собственно сжатие). Метод сжатия называется локально адаптивным, если в нем предусмотрена возможность изменения параметров в зависимости от локальных особенностей входного файла.
|
|
|
Методы сжатия данных делятся также на методы сжатия без потерь и с потерями информации. Метод сжатия без потерь (метод неискажающего сжатия) позволяет восстановить сжатую информацию без искажений. Метод сжатия с потерями (метод искажающего сжатия) предусматривает искажение сжимаемой информации для получения требуемых характеристик сжатия (скорости, качества, простоты и т.д.).
Симметричный метод сжатия – это метод, при использовании которого кодер и декодер выполняют одни и те же действия, но в противоположных направлениях. Если либо кодер, либо декодер выполняет значительно большую работу, то соответствующий метод сжатия называется асимметричным.
Для определения производительности метода сжатия данных часто используют коэффициент сжатия, фактор сжатия, качество сжатия, время сжатия и время восстановления. Коэффициент сжатия – величина, получающаяся в результате деления размера выходного (сжатого) файла на размер входного (несжатого) файла. Фактор сжатия – величина, обратная коэффициенту сжатия. Качество сжатия определяется по формуле
|
|
|
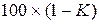
выражается в процентах и показывает на сколько процентов уменьшается размер исходного файла после сжатия. Время сжатия – это время, затрачиваемое на сжатие данных. Время восстановления – это время, необходимое для восстановления данных из сжатого файла.
Сжатие по Хаффмену
Методы сжатия по Хаффмену основаны на методе оптимального кодирования Хаффмена. Непосредственная реализация метода Хаффмена приводит к неадаптивному сжатию, так как вероятности символов должны быть известны заранее (неадаптивный метод далее рассматриваться не будет). Полуадаптивный метод сжатия по Хаффмену заключается в том, что сначала весь исходный файл просматривается, определяются частоты символов в файле, а затем производится кодирование на основании полученных частот, которые используются как оценки вероятностей символов. При этом в выходной файл со сжатыми данными заносятся значения частот символов и/или коды символов, например в виде кодовой таблицы. Адаптивный метод сжатия по Хаффмену основан на использовании некоторой вероятностной модели источника исходных данных, корректируемой после кодирования каждого символа. В этом случае хранить информацию о частотах символов не нужно, поскольку декодер будет использовать точно такую же модель и точно также ее корректировать после восстановления каждого символа.
|
|
|
Рассмотрим два адаптивных метода сжатия по Хаффмену. Первый из них заключается в использовании модели, которая изначально является равномерной, содержащей все возможные символы (в том числе и символ конца файла EOF) с частотами, равными 1. После кодирования очередного символа его частота увеличивается на единицу. При этом подсчитывается суммарная частота и если она достигает заранее заданного, максимального, значения, то производится нормализация – уменьшение частот всех символов. Как правило, при нормализации все частоты делят на 2. При этом частотам, получившимся равными 0, присваивают значение 1. Процесс продолжается до тех пор, пока не будет достигнут конец файла (считан символ EOF).
|
|
|
Второй метод адаптивного сжатия по Хаффмену основан на использовании дополнительного символа ESC, частота которого всегда равна 1. Исходная модель в этом случае содержит только два символа – ESC и EOF с единичными частотами. При появлении очередного символа проверяется его наличие в текущей модели. Если символ имеется в модели (его частота не равна 0), то ему присваивается код по методу Хаффмена. Если же символ в модели отсутствует (его частота равна 0), то ему присваивается код, состоящий из кода Хаффмена символа ESC, к которому приписывается справа исходный код символа (код, считанный из файла). Если символ при кодировании уже присутствовал в модели, то после кодирования его частота увеличивается на 1, иначе – он добавляется в модель с частотой 1. Так же как и в предыдущем случае подсчитывается суммарная частота и производится нормализация, когда суммарная частота достигает заданного, максимального, значения. При этом можно модифицировать нормализацию: после уменьшения значений частот все символы (кроме ESC и EOF), у которых частоты стали меньше 1, удаляются из модели. Отметим, что кодирование выполняется таким образом, что бы коды символов ESC и EOF имели не меньшую длину, чем другие символы.
Восстановление данных, сжатых с помощью первого адаптивного метода, выполняется следующим образом: побитно считывается код из сжатого файла, производится попытка его декодировать и если это удается, то соответствующий символ записывается в выходной файл, его частота увеличивается на 1, определяется суммарная частота и при необходимости выполняется нормализация. Процесс продолжается до тех пор, пока не будет декодирован символ EOF. Восстановление по второму методу отличается только тем, что если декодирован символ ESC, то далее считывается известное количество бит несжатого символа, который затем добавляется в модель с частотой 1. При использовании обоих методов исходная модель должна быть точно такой же, что и при сжатии данных.
Проиллюстрируем описание методов сжатия по Хаффмену на примерах. Пусть файл данных, который нужно сжать, имеет вид
s1s2s2s2 s1s3s3EOF.
При сжатии файла полуадаптивным методом, частоты символов и их коды будут найдены после первого прохода (таблица 6.1), а затем использованы на втором проходе. В результате будет получена двоичная последовательность:
01111000000001.
При этом в результирующий файл необходимо поместить также частоты символов и/или их коды.
Таблица 6.1
Полуадаптивные коды Хаффмена
| Символ | s1 | s2 | s3 | EOF |
| Частота | 2 | 3 | 2 | 1 |
| Код | 01 | 1 | 000 | 001 |
Теперь выполним сжатие того же файла, но с помощью адаптивных методов. При этом будем полагать, что максимальное значение суммарной частоты, при которой необходимо проводить нормализацию, равно 8. Коды, получаемые при сжатии первым адаптивным методом, приведены в таблице 6.2. На выходе в результате будет получена последовательность
1001001010101001.
Таблица 6.2
Кодирование первым адаптивным методом Хаффмена
| № | Символ | Модель | № | Символ | Модель | ||||
| 1 | s1 | Символ | Частота | Код | 5 | s1 | Символ | Частота | Код |
| s1 | 1 | 10 | s1 | 1 | 01 | ||||
| s2 | 1 | 11 | s2 | 2 | 1 | ||||
| s3 | 1 | 00 | s3 | 1 | 000 | ||||
| EOF | 1 | 01 | EOF | 1 | 001 | ||||
| 2 | s2 | Символ | Частота | Код | 6 | s3 | Символ | Частота | Код |
| s1 | 2 | 1 | s1 | 2 | 1 | ||||
| s2 | 1 | 01 | s2 | 2 | 00 | ||||
| s3 | 1 | 000 | s3 | 1 | 010 | ||||
| EOF | 1 | 001 | EOF | 1 | 011 | ||||
| 3 | s2 | Символ | Частота | Код | 7 | s3 | Символ | Частота | Код |
| s1 | 2 | 1 | s1 | 2 | 00 | ||||
| s2 | 2 | 00 | s2 | 2 | 01 | ||||
| s3 | 1 | 010 | s3 | 2 | 10 | ||||
| EOF | 1 | 011 | EOF | 1 | 11 | ||||
| 4 | s2 | Символ | Частота | Код | 8 | EOF | Символ | Частота | Код |
| s1 | 2 | 00 | s1 | 1 | 10 | ||||
| s2 | 3 | 1 | s2 | 1 | 11 | ||||
| s3 | 1 | 010 | s3 | 1 | 00 | ||||
| EOF | 1 | 011 | EOF | 1 | 01 | ||||
Отметим, что после выполнения четвертого и седьмого (перед выполнением пятого и восьмого) шагов была проведена нормализация, заключавшаяся в делении значений всех частот на два и замене нулей на единицы.
Для сжатия вторым адаптивным методом необходимо определить исходные коды символов в несжатом виде. Пусть они будут следующими:
s1 – 00, s2 – 01, s3 – 10, EOF – 11.
Тогда в результате на выходе получим
0000001110001101001011.
Процесс получения соответствующих кодов показан в таблице 6.3. Здесь также после шестого (перед седьмым) шагом выполнялась нормализация модели.
Таблица 6.3
Кодирование вторым адаптивным методом Хаффмена
| № | Символ | Модель | № | Символ | Модель | ||||
| 1 | s1 | Символ | Частота | Код | 5 | s1 | Символ | Частота | Код |
| s1 | 0 | - | s1 | 1 | 01 | ||||
| s2 | 0 | - | s2 | 3 | 00 | ||||
| s3 | 0 | - | s3 | 0 | - | ||||
| ESC | 1 | 0 | ESC | 1 | 10 | ||||
| EOF | 1 | 1 | EOF | 1 | 11 | ||||
| 2 | s2 | Символ | Частота | Код | 6 | s3 | Символ | Частота | Код |
| s1 | 1 | 1 | s1 | 2 | 01 | ||||
| s2 | 0 | - | s2 | 3 | 00 | ||||
| s3 | 0 | - | s3 | 0 | - | ||||
| ESC | 1 | 00 | ESC | 1 | 10 | ||||
| EOF | 1 | 01 | EOF | 1 | 11 | ||||
| 3 | s2 | Символ | Частота | Код | 7 | s3 | Символ | Частота | Код |
| s1 | 1 | 10 | s1 | 1 | 11 | ||||
| s2 | 1 | 11 | s2 | 1 | 10 | ||||
| s3 | 0 | - | s3 | 1 | 01 | ||||
| ESC | 1 | 00 | ESC | 1 | 000 | ||||
| EOF | 1 | 01 | EOF | 1 | 001 | ||||
| 4 | s2 | Символ | Частота | Код | 8 | EOF | Символ | Частота | Код |
| s1 | 1 | 01 | s1 | 1 | 11 | ||||
| s2 | 2 | 00 | s2 | 1 | 10 | ||||
| s3 | 0 | - | s3 | 2 | 00 | ||||
| ESC | 1 | 10 | ESC | 1 | 010 | ||||
| EOF | 1 | 11 | EOF | 1 | 011 | ||||
Арифметическое кодирование
Альтернативой методу сжатия по Хаффмену является арифметическое кодирование. При его применении код присваивается всему передаваемому файлу, вместо кодирования отдельных символов. Кодер читает входной файл символ за символом и добавляет биты к сжатому файлу. Получающийся код представляет собой дробную часть числа из полуинтервала [0, 1). В общем виде алгоритм арифметического кодирования имеет следующие шаги.
1. Задать текущий интервал [0, 1).
2. Повторить следующие действия для каждого символа s входного файла.
2.1. Разделить текущий интервал на части пропорционально частотам каждого символа.
2.2. Выбрать подынтервал, соответствующий символу s, и назначить его новым текущим интервалом.
3. Когда весь входной файл будет обработан, выходом алгоритма объявляется любая внутренняя точка текущего интервала.
Для восстановления сжатых данных последовательно определяются интервалы, в которые попадает анализируемое значение (входной код из сжатого файла), и соответствующие им символы, которые и будут выдаваться на выход декодера.
В качестве примера выполним сжатие той же последовательности, что рассматривалась при изучении методов сжатия по Хаффмену. Процесс образования интервалов показан в таблице 6.4. При этом используются частоты из таблицы 7.1. На последнем (восьмом) шаге выбирается подынтервал
[0.097481728, 0.097507477),
соответствующий символу EOF. В качестве результата можно взять любую точку из этого подынтервала. Выберем такое значение, которое имеет наименьшее число цифр в двоичной форме:
0.09748172810 = 0.000110001111010010012.
Таким образом, арифметическим кодом исходной последовательности будет
00011000111101001001.
Таблицы 6.4
Образование интервалов при арифметическом кодировании
| № | Интервалы | Символ |
| 1 | s1: [0, 0.25) s2: [0.025, 0.625) s3: [0.625, 0.875) EOF: [0.875, 1) | s1 |
| 2 | s1: [0, 0.0625) s2: [0.0625, 0.15625) s3: [0.15625, 0.21875) EOF: [0.21875, 0.25) | s2 |
| 3 | s1: [0.0625, 0.0859375) s2: [0.0859375, 0.12109375) s3: [0.12109375, 0.14453125) EOF: [0.14453125, 0.15625) | s2 |
| 4 | s1: [0.0859375, 0.094726563) s2: [0.094726563, 0.107910156) s3: [0.107910156, 0.116699219) EOF: [0.116699219, 0.12109375) | s2 |
| 5 | s1: [0.094726563, 0.098022461) s2: [0.098022461, 0.102966309) s3: [0.102966309, 0.106262207) EOF: [0.106262207, 0.107910156) | s1 |
| 6 | s1: [0.094726563, 0.095550538) s2: [0.095550538, 0.096786499) s3: [0.096786499, 0.097610474) EOF: [0.097610474, 0.098022461) | s3 |
| 7 | s1: [0.096786499, 0.096992493) s2: [0.096992493, 0.097301483) s3: [0.097301483, 0.097507477) EOF: [0.097507477, 0.097610474) | s3 |
| 8 | s1: [0.097301483, 0.097352982) s2: [0.097352982, 0.097430229) s3: [0.097430229, 0.097481728) EOF: [0.097481728, 0.097507477) | EOF |
Приведенный пример соответствует полуадаптивному методу. Существует также адаптивное арифметическое кодирование, основанное на модели, которая была рассмотрена при описании первого адаптивного метода сжатия по Хаффмену.
Словарные методы
Словарные методы основаны на применении динамических словарей. Эти методы базируются на алгоритмах LZ77 и LZ78, предложенных Лемпелем Зивом. В основе словарных методов лежат следующие идеи:
1. каждая очередная закодированная последовательность символов добавляется к ранее закодированным символам таким образом, что вместе с ними она образует разложение всей переданной и принятой информации на несовпадающие между собой слова;
2. слова хранятся в памяти и используются в дальнейшем в качестве словаря;
3. кодирование осуществляется при помощи указателей на слова из сформированного словаря;
4. кодирование является динамической процедурой, ориентированной на блоки символов.
При реализации методов Лемпеля-Зива как правило используется скользящее окно, состоящее из словаря и упреждающего буфера.
В результате сжатия файла с помощью метода LZ77 формируется последовательность вида
áA, L, Sñ,
где A – относительный адрес в словаре, L – количество совпадающих символов, S – символ из буфера, который отличается от продолжения слова в словаре. При этом код á–1, 0, Sñ (или á0, 0, Sñ) означает, что в словаре ничего не найдено.
Алгоритм LZ77 работает следующим образом. Сначала упреждающий буфер заполняется символами из начала сжимаемого файла. Затем осуществляется поиск в словаре слова, максимально совпадающего со словом в начале упреждающего буфера. После этого формируется и выдается код. После выдачи кода L + 1 символов из начала упреждающего буфера переписываются в словарь, оставшиеся символы смещаются в начало, а на их место записываются символы из файла. Так как размер словаря ограничен, то из его начала часть символов может удаляться со смещением остальных на соответствующее число позиций.
Пусть, например, необходимо закодировать последовательность символов
aaaabaabbbEOF
методом LZ77 с использованием словаря и упреждающего буфера, рассчитанных на 8 и 4 символов соответственно. Процесс кодирования показан в таблице 6.5.
Таблица 6.5
Пример кодирования по методу LZ77
| № | Словарь | Упреждающий буфер | Код | ||||||||||
| 1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 0 | 1 | 2 | 3 | á–1, 0, añ |
| - | - | - | - | - | - | - | - | a | a | a | a | ||
| 2 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 0 | 1 | 2 | 3 | á0, 1, añ |
| a | - | - | - | - | - | - | - | a | a | a | b | ||
| 3 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 0 | 1 | 2 | 3 | á0, 1, bñ |
| a | a | a | - | - | - | - | - | a | b | a | a | ||
| 4 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 0 | 1 | 2 | 3 | á0, 2, bñ |
| a | a | a | a | b | - | - | - | a | a | b | b | ||
| 5 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 0 | 1 | 2 | 3 | á4, 1, bñ |
| a | a | a | a | b | a | a | b | b | b | EOF | - | ||
| 6 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 0 | 1 | 2 | 3 | á–1, 0, EOFñ |
| a | a | b | a | a | b | b | b | EOF | - | - | - | ||
| 7 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 0 | 1 | 2 | 3 | - |
| a | b | a | a | b | b | b | EOF | - | - | - | - | ||
Метод LZ78 отличается от LZ77 тем, что в каждой позиции словаря хранятся слова. Поэтому в выходном коде количество совпадающих символов L отсутствует, т.е. код имеет вид
áA, Sñ,
где A – адрес слова в словаре, совпадающего со словом в начале упреждающего буфера, S – символ из буфера, который отличается от продолжения слова в словаре. При этом код á–1, Sñ означает, что в словаре ничего не найдено. После выдачи кода в словарь добавляется слово, начало которого представляет собой слово из словаря по адресу A (A ≠ –1), а окончание – символ S.
Процесс кодирования по методу LZ78 последовательности символов, рассмотренной в примере применения метода LZ77, показан в таблице 6.6.
Таблица 6.6
Пример кодирования по методу LZ78
| № | Словарь (позиция: слово) | Упреждающий буфер | Код |
| 1 | - | aaaa | á–1, añ |
| 2 | 0: a | aaab | á0, añ |
| 3 | 0: a 1: aa | abaa | á0, bñ |
| 4 | 0: a 1: aa 2: ab | aabb | á1, bñ |
| 5 | 0: a 1: aa 2: ab 3: aab | bbEOF | á–1, bñ |
| 6 | 0: a 1: aa 2: ab 3: aab 4: b | bEOF | á4, EOFñ |
| 7 | 0: a 1: aa 2: ab 3: aab 4: b 5: bEOF | - | - |
Одной из практических модификаций LZ77 является алгоритм LZSS, который отличается от LZ77 тем, как поддерживается скользящее окно и какие коды выдает кодер. LZSS, помимо собственно окна с содержимым сообщения, поддерживает двоичное дерево для ускорения поиска совпадения. Каждая подстрока, покидающая буфер, добавляется в дерево поиска, а подстрока, покидающая словарь, удаляется из дерева. Такая организация модели данных позволяет добиться существенного увеличения скорости поиска совпадения, которая, в отличие от LZ77, становится пропорциональна не произведению размеров окна и подстроки, а его двоичному логарифму. На выходе кодера формируются либо пары áA, Lñ, либо незакодированные символы. Для их различения кодер LZSS использует однобитовый префикс.
Как и в LZ77, в этом алгоритме используется обычный символьный буфер для хранения содержимого окна. Доступ к нему организован как к кольцевому буферу, а размер кратен степени 2. Дерево поиска представляет собой двоичное лексикографически упорядоченное дерево. Каждый узел в дереве соответствует одной подстроке словаря и содержит ссылки на родителя и двух детей: «большего» и «меньшего» в смысле лексикографического сравнения символьных строк.
Для того чтобы кодер LZSS мог начать работать, необходимо загрузить буфер очередными символами сообщения и проинициализировать дерево. Для этого в дерево вставляется содержимое буфера. После этого алгоритм последовательно выполняет следующие действия:
1) кодирует содержимое буфера;
2) считывает очередные символы в буфер, удаляя при необходимости наиболее «старые» строки из словаря;
3) вставляет в дерево новые строки, соответствующие считанным символам.
Для того чтобы декодер смог вовремя остановиться, декодируя сжатое сообщение, кодер помещает в сжатый файл специальный символ конца файла после того, как он обработал все символы сообщения.
Вся работа по поиску расположения и установлению длины максимального совпадения содержимого словаря с буфером происходит в процессе добавления в дерево новой строки. При добавлении строки в дерево алгоритм последовательно перемещается от корня дерева к его листу, каждый раз осуществляя лексикографическое сравнение новой строки и узла дерева. В зависимости от результата сравнения выбирается больший или меньший ребёнок этого узла и запоминается длина совпадения строк и положение текущего узла. Если в результате сравнения оказывается, что содержимое буфера и строка, на которую ссылается текущий узел, в точности совпадают, то ссылки в текущем узле обновляются так, чтобы они указывали на буфер, и процедура добавления строки в дерево завершается. Если ребенок текущего узла, выбранный для очередного шага, отмечен как несуществующий, остается заполнить его соответствующей ссылкой и завершить работу.
При удалении узла из дерева возможны два варианта. Если узел имеет не более одного ребенка, то удаление узла осуществляется простым исправлением ссылок «родитель – ребенок». Если узел имеет двоих детей, то необходимы другие действия. Для этого найдем следующий меньший узел в дереве, удалим его из дерева и заменим им текущий удаляемый узел. Следующий меньший узел находится выбором меньшего ребенка и последующим перемещением от него по дереву до листа по большим ветвям.
При восстановлении данных, декодер читает один бит сжатой информации и определяет, что следует далее. Если далее следует символ, то следующие 8 битов выдаются как раскодированный символ и помещаются в скользящее окно. Если же далее следует пара áA, Lñ, то соответствующее количество символов словаря помещается в окно и выдается в раскодированном виде. Декодирование заканчивается при обнаружении символа конца файла.
Примером практической модификации алгоритма LZ78 является алгоритм LZW. Кодер LZW никогда не выдает сами символы сжимаемого сообщения, только коды фраз. Он построен вокруг таблицы фраз (словаря), которая отображает строки символов сжимаемого сообщения в коды фиксированной длины вида áAñ. Таблица обладает так называемым свойством предшествования, то есть для каждой фразы словаря, состоящей из некоторой фразы w и символа S, фраза w тоже содержится в словаре.
Очевидно, что декодер LZW использует тот же словарь, что и кодер, строя его по аналогичным правилам при восстановлении сжитого сообщения. Каждый считываемый код разбивается с помощью словаря на предшествующую фразу w и символ S. Затем рекурсия продолжается для предшествующей фразы w до тех пор, пока она не окажется кодом одного символа, что и завершает декомпрессию этого кода. Обновление словаря происходит для каждого декодируемого кода, кроме первого. После завершения декодирования кода его последний символ, соединенный с предыдущей фразой, добавляется в словарь. Новая фраза получает то же значение кода (позицию в словаре), что присвоил ей кодер. Так шаг за шагом декодер восстанавливает тот словарь, который построил кодер.
Отметим, что словарные методы являются асимметричными методами, поскольку при восстановлении данных не нужно выполнять поиск: ссылка на словарь содержится непосредственно в коде. Например, для LZ77 декодер по адресу A и количеству совпадающих символов L находит слово в словаре, добавляет к нему символ S и выдает на выход.
Методы кодирования длин серий
Методы кодирования длин серий, которые еще называют методами RLE (Run Length Encoding), являются одними из наиболее старых методов сжатия. Однако благодаря своей простоте и эффективности они до сих пор используются либо непосредственно, либо в составе других методов. При использовании простейшего метода RLE последовательность (серия) одинаковых символов заменяется парой áC, Sñ, где C – длина серии, S – символ, из которого состоит серия. Например, для файла
aaaaaaaaabbbbaaaaabbaaaaaabbbbaaaaaabbaaaacccccdddEOF
после применения данного метода будет получена следующая последовательность кодов:
áa, 9ñ áb, 4ñ áa, 5ñ áb, 2ñ áa, 6ñ áb, 4ñ áa, 6ñ áb, 2ñ áa, 4ñ ác, 5ñ ád, 3ñ áEOF, 1ñ.
Недостатком простейшего метода RLE является увеличение размеров информации (вместо сокращения) в том случае, если сжимаемая последовательность содержит большое число одиночных символов. Поэтому для устранения указанного недостатка на практике используют различные модификации RLE-кодирования, например, можно использовать C переменного размера:
при C = 0 – размер равен 1 биту;
при C > 0 – размер равен n бит, старший из которых содержит 1.
Дата добавления: 2018-10-26; просмотров: 360; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!