Коэффициенты взаимозависимости для номинального
уровня измерения.
Связь в табл. 2 X 2. Простейшая задача о взаимозависимости возникает тогда, когда имеются два признака, каждый из которых принимает два значения (табл. 13).

Представим данные о группировке по этим двум признакам так;

Для характеристики степени связи двух признаков применяется коэффициент Ф, определяемый формулой

Коэффициент Ф равен 0, если нет соответствия между двумя дихотомическими переменными, и равен 1 или —1, когда имеется полное соответствие между ними. В силу трудностей. с интерпретацией знака коэффициента для катетеризованных (поминальных) переменных часто используют в анализе лишь абсолютную величину—|Ф|. Ф легко интерпретируется, поскольку показано, что он представляет собой просто коэффициент корреляции r, если значения каждой дихотомической переменной обозначить 0 и 1.
Как уже отмечалось, Ф вычисляется для катетеризованных данных, представляющих естественные дихотомии: пол, раса, и т. п. Приведение количественных переменных к дихотомическому виду связано .с выбором граничной точки разделения (например, мужчины до 30 лет и мужчины старше 30 лет). Искусственная дихотомизация, столь часто необходимая в конкретном исследовании при изучении взаимосвязи признаков, может привести к тому, что одна часть дихотомической переменной по своему воздействию будет более значима для одной связи, другая —для другой, а это даст ошибочный результат.
|
|
|
Измерение связи в табл. с X k. Рассмотрим теперь более общую ситуацию, когда две переменные классифицированы па две или более категории. Запишем это таким образом:

где nij частоты; ni— маргинальные суммы частот по строкам; nj— маргинальные суммы частот по столбцам. На с. 169—172 для выяснения отклонения от независимости распределения значений в подобном случае использовался критерий c2. Однако сама величина c2не очень подходит в качестве меры связи, поскольку сильно зависит от числа категорий.
Нормированным коэффициентом корреляции для таблицы c X k является коэффициент сопряженности Пирсона (P)

Коэффициент Р = 0 при полной независимости признаков. Недостатком, его является зависимость максимальной величины Р от размера таблицы (максимум Р достигается при c = k, но сама граница изменяется с изменением числа категорий). В связи с этим возникают трудности сравнения таблиц разного размера.
Чтобы исправить указанный недостаток, Чупров ввел другую величину:

При с = kТ достигает +1 в случае полной связи, однако не обладает этим свойством при k не равно с.
Коэффициент Крамера (К) может всегда достигать +1 независимо от вида таблицы:

Для квадратной таблицы коэффициенты Крамера и Чупрова совпадают, а в остальных случаях К > Т.
|
|
|
Величина c2 быстро вычисляется с помощью формулы

Вычисление коэффициентов Р, Т и К связано с теми же ограничениями на х2, которые сформулированы на с. 172.
Следующая группа коэффициентов связи для категоризованных данных основана на предположении, что если две переменные связаны, то информация об одной переменной может быть использована для предсказания другой. Так, если предположить, что связь между полом индивида и его отношением к правилам уличного движения абсолютно детерминирована, то согласно табл. 13 либо все мужчины были бы нарушителями, а женщины нет, либо наоборот. Поскольку это не так, то возникает несоответствие, или, как говорят, ошибка предположения абсолютной связи (обозначим величину этой ошибки 0 А).
С другой стороны, можно предположить, что два признака абсолютно не связаны, и нельзя на основе одной переменной предсказать другую. Поскольку это тоже не так, то возникает ошибка предположения об отсутствии связи (00).

может служить мерой относительного уменьшения ошибки при- использовании информации об одной переменной для предсказания другой.
Признак, на основе которого предсказывается другой признак, будем называть независимой переменной, а предсказываемый — зависимой.
|
|
|
Тогда для случая, когда зависимая переменная расположена по строкам таблицы (т. е. Категории расположены по строкам), вычисляется коэффициент связи l г:

где max n — наибольшая частота в столбце r; max n j — наибольшая маргинальная частота для строк j.
Пример. Вычислим К2для данных табл. 13 в предположении, что K1 независимая переменная, а отношение к правилам уличного движения — зависимая
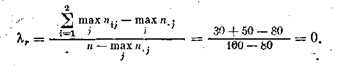
Таким образом, использование информации о поле обследованных для предсказания отношения к правилам движения не уменьшает относительной ошибки.
Если зависимая переменная — это категории столбцов таблицы, то совершенно аналогично предыдущему вычисляется

где mах nij — наибольшая частота в строке; max ni— наибольшая
маргинальная частота для столбцов i.
Для нашего примера, когда пол зависимая переменная, l = 0,4, т. е. получаем 40%-пое уменьшение в ошибке, если используем отношение к правилам в качестве предсказывающей пол нарушителя.
Коэффициенты А и К имеют пределы изменения от 0 до 1. Чем ближе К г или К с к 1, тем больше относительное уменьшение в ошибке и большее соответствие (связь) между переменными. Эти коэффициенты могут быть использованы для таблиц любого размера.
|
|
|
В ряде случаев удобно использовать симметричную l:

Разнообразие корреляционных коэффициентов продиктовано стремлением отразить реально существующее разнообразие типов связей в природе и обществе. Поэтому данное обстоятельство следует рассматривать скорее как свидетельство достоинств статистического аппарата, заключающихся в гибкости и большой приспособленности его к анализу сложнейших взаимосвязей в социальной области. Каждый корреляционный коэффициент приспособлен дли измерения вполне определенного вида связи. Техника расчета и конструкция формулы одного и того же коэффициента могут измениться в зависимости от того, какие (например, сгруппированные или не сгруппированные) данные приходится анализировать. Сравните, например, различные варианты формул для парного коэффициента корреляции r. Таким образом, применение того или иного показателя определяется природой данных и формой их представления. Требуемая степень точности также может существенно повлиять на выбор способа расчета связи в каждом конкретном случае. Обычно оценка пригодности той или иной формулы производится с учетом следующих факторов:
1) природы данных (качественные или количественные признаки);
2) формы и типа зависимости (линейная или нелинейная, положительная или отрицательная связь);
3) требуемой точности расчетов (например, коэффициенты корреляции рангов rи t иногда могут использоваться вместо более точных мер rи t2);
4) удобства при вычислении и сравнительной простоты интерпретации;
5) трудностей технического порядка (имеется ли счетная техника или нужно вести расчеты вручную);
6) распространенности использования того или иного коэффициента корреляции;
7) возможности сравнения различных коэффициентов.
Обычно предпочитают использовать наиболее распространенные в практике социологических исследований коэффициенты, так как тем самым достигается возможность сравнения полученных результатов с материалами других исследований.
Дата добавления: 2018-10-26; просмотров: 230; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!