Элементы и правила построения диаграмм потоков данных
СТРУКТУРНЫЙ СИСТЕМНЫЙ АНАЛИЗ
Место системного структурного анализа в жизненном цикле программного обеспечения
Структурный системный анализ проводится на начальном этапе разработки программного обеспечения – при создании спецификаций требований. Анализ предусматривает сбор и систематизацию сведений о предметной области, в которой должна функционировать разрабатываемая система. В результате проведения анализа создается система формальных спецификаций, ядром которой являются диаграммы потоков данных (ДПД).
Работы, выполняемые на этапе структурного системного анализа, осуществляются как правило, специальным лицом – системным аналитиком. Схема его взаимодействия с другими участниками разработки иллюстрирует рис. 2.1.
Системный аналитик проводит опрос будущих пользователей системы с целью выявления их потребностей и требований к системе автоматизации. Итогом исследования предметной области системным аналитиком являются диаграммы потоков данных, предоставляемые для проверки и согласования заказчику, а также будущим пользователям системы. Диаграммы потоков данных используются разработчиками системы (проектировщиками и программистами) при создании программного продукта. Системный аналитик консультирует разработчиков системы, а при необходимости проводит повторный опрос пользователей и уточняет ДПД.
При выполнении анализа, как правило, возникают проблемы, основными из которых являются следующие.
|
|
|
1. Аналитику сложно получить всю необходимую информацию о предметной области, так как зачастую сами пользователи затрудняются в формулировке алгоритмов, логики обработки информации и принятия решений, руководствуясь в своей практической деятельности интуитивными соображениями.
2. Пользователи будущей системы не обладают достаточными знаниями в области обработки информации, для того чтобы судить, что является выполнимым, а что нет, в каких рамках возможна и наиболее эффективна автоматизация.
3. При создании реальных систем количество понятий, выделяемых в результате проведения анализа, может достигать десятков тысяч; следовательно, аналитику необходимы средства для систематизации данных, а также возможность «рассматривать» систему как в целом, так и по частям.
4. Собранные аналитиком сведения должны быть проверены и согласованы с заказчиками и будущими пользователями системы, поэтому они должны быть представлены, с одной стороны, на языке, доступном людям, не обладающим специальными знаниями, а с другой стороны – на языке, не допускающем многозначной интерпретации фактов. Наилучшим способом разъяснения пользователям функций системы является создание ее прототипа, но эта работа может потребовать значительного времени и средств.
|
|
|
5. Собранные аналитиком сведения используются разработчиками системы, а следовательно, должны быть достаточно полными, формализованными и понятными специалистам в области обработки информации и создания программного обеспечения.
Методология структурного системного анализа нацелена на то, что бы помочь аналитику решить перечисленные выше проблемы. Предлагаемая методика не позволяет автоматически получать хорошие проекты, вместе с тем, она вводит некоторую «технологическую дисциплину», которая может обеспечить сокращение сроков и трудозатрат при создании качественного, а следовательно, более надежного, программного обеспечения.
Этапы структурного системного анализа
Структурный системный анализ может быть разбит на несколько этапов:
· построение диаграмм потоков данных;
· составление словаря данных;
· определение логики процессов;
· описание накопителей данных.
На первом этапе строятся диаграммы потоков данных, содержащие элементы четырех типов:
· внешняя сущность;
· процесс;
· накопитель данных;
|
|
|
· поток данных.
Пример диаграммы потоков данных приведен на рис. 2.2. Представленная на рис. диаграмма описывает процесс рассылки уведомлений о поступивших в продажу книгах. Книги поступают из издательства, являющегося внешней сущностью по отношению к рассматриваемой системе. Процесс получения книг фиксирует информацию о поступивших книгах в накопителе данных («Книги, имеющиеся в продаже»). Процесс печати почтовых карточек обрабатывает информацию о заказах и книгах из накопителей данных и направляет уведомление внешней сущности «Читатель». Заметим, что диаграмма потоков данных описывает логику функционирования системы безотносительно к какой-либо реализации. Так, информация о заказах на книги может храниться в базе данных, файле, картотеке; печать карточки может осуществляться с помощью компьютера или пишущей машинки и т. д. Решения о границах автоматизации, способах организации и представления информации, реализации процессов должны приниматься проектировщиком на более поздних стадиях создания системы; задача этапа системного анализа – это сбор по возможности наиболее полной информации о функционировании системы.
На этапе составления словаря данных производится уточнение каждого из понятий, указанного на диаграмме потоков данных. Например, на рис. 2.2 использован термин «Заявка». Какую структуру она имеет? Какая информация о заказчике и книге заносится в заявку? На все подобные вопросы должны быть даны ответы при составлении словаря. В данном примере структура заявки могла бы быть следующей:
|
|
|
ЗАЯВКА
ДАТА
НОМЕР
ЗАКАЗЧИК
ФАМИЛИЯ
ИМЯ
АДРЕС
ИНДЕКС
ГОРОД
УЛИЦА
ДОМ
КВАРТИРА
КНИГА
ИЗДАТЕЛЬСТВО
ГОД ИЗДАНИЯ
ШИФР ПО КАТАЛОГУ ИЗДАТЕЛЬСТВА
АВТОР
НАЗВАНИЕ
КОЛИЧЕСТВО ЭКЗЕМПЛЯРОВ
Приведенное описание дает исчерпывающее представление о логической структуре заявки и вместе с тем не несет никакой информации о типах, размерах, правилах кодирования полей. В общем случае словарь данных должен содержать исчерпывающее описание для каждого неэлементарного потока данных, встречающегося на диаграмме.
Описание логики процессов позволяет раскрыть внутреннее содержание, правила выполнения процессов. Для описания логики используются:
· деревья решений;
· таблицы решений;
· структурный естественный язык.
На рис. 2.3 приведено дерево решений, определяющее размер скидки в зависимости от типа покупателя и количества приобретаемых экземпляров книг. Количество уровней в дереве определяется числом анализируемых условий, а каждая ветвь соответствует некоторой комбинации вариантов.
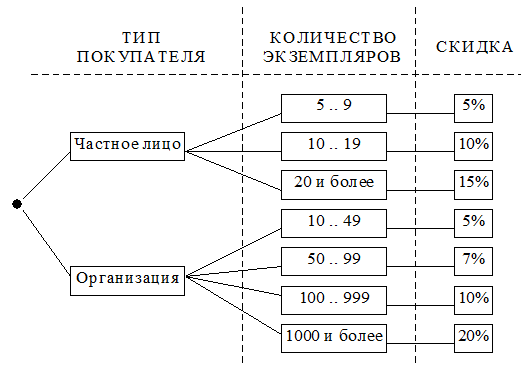
Рис. 2.3. Дерево решений для определения
скидки при покупке книг
Иногда (при большом количестве условий) информацию целесообразнее представлять в виде таблицы. Табл. 2.1 – это пример таблицы решений, соответствующей дереву решений на рис. 2.3.
Таблица 2.1
Таблица решений для определения размера скидки
| Тип покупателя | Количество экземпляров | Скидка |
| 5..9 | 5% | |
| Частное лицо | 10..19 | 10% |
| 20 и более | 15% | |
| 10..49 | 5% | |
| Организация | 50..99 | 7% |
| 100..999 | 10% | |
| 1000 и более | 20% |
Деревья и таблицы решений являются удобными формами описания действий, связанных с выбором при принятии решения. Для описания вычислений, пошагового выполнения процессов используется структурный естественный язык. Рассмотрим процесс печати почтовой карточки-уведомления, приведенный на рис. 2.2.
Вполне естественным требованием является обслуживание в первую очередь тех заказов, которые имеют более раннюю дату; тогда логика выполнения этого процесса может быть описана следующим образом:
выбрать очередную книгу;
ПОВТОРЯТЬ, ПОКА не исчерпаны заказы;
выбрать очередной заказ;
ЕСЛИ издательство, год и шифр книги совпадают с
указанными в заказе,
ТО печатать реквизиты заказа.
Накопители данных играют роль хранилищ информации, обработка которой должна быть по каким-либо причинам отложена. Структура накопителей данных, так же как и потоков, должна быть описана и занесена в словарь. При реализации системы накопителю будет соответствовать некоторая база данных, поэтому при проектировании накопителей может быть использована техника проектирования данных с помощью моделей “сущность - связь” и других моделей данных.
Важным вопросом при описании накопителей является спецификация схем доступа к данным (возможных запросов). На рис. 2.4 приведена схема прямого доступа к данным для накопителя, содержащего заказы на книги (см. рис. 2.2). В соответствии с рис. 2.4 прямой доступ возможен по фамилии автора, дате, названию, шифру и невозможен, например, по фамилии заказчика и количеству экземпляров.

Рис. 2.4. Схема прямого доступа к данным
Элементы и правила построения диаграмм потоков данных
Диаграммы потоков данных строятся из четырех основных элементов (рис. 2.5):
· внешняя сущность;
· поток данных;
· процесс;
· накопитель данных.
Внешняя сущность представляет на диаграмме модели, организации, системы, находящиеся за пределами объекта разработки (за границами проектирования).
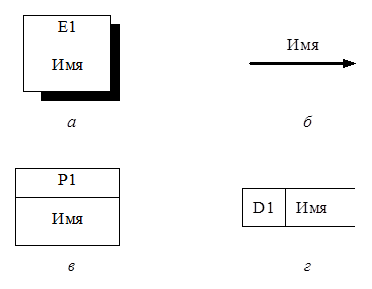
Рис. 2.5. Элементы диаграмм потоков данных:
а - внешняя сущность; б - поток данных; в - процесс; г - накопитель данных
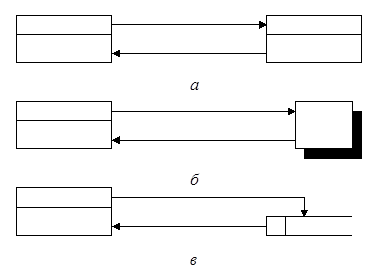
Рис. 2.6. Правила соединения элементов диаграмм потоков данных:
а - «процесс - процесс»; б - «процесс - внешняя сущность»;
в - «процесс - накопитель данных»
Вместе с тем внешние сущности являются источниками или приемниками информации по отношению к рассматриваемой системе и включаются в диаграмму для спецификации ее интерфейса. На диаграмме внешняя сущность изображается прямоугольником, внутри которого записывается ее уникальный идентификатор и имя (см. рис. 2.5, а). Уникальный идентификатор образуют литера E и порядковый номер внешней сущности.
Поток данных изображается стрелкой, направление которой совпадает с направлением потока данных. Над стрелкой указывается имя потока данных (см. рис. 2.5, б). Поток данных может рассматриваться как пневмопочта или конвейер, передающий пакеты данных между обрабатывающими их процессами.
Под процессами на диаграмме потоков данных понимаются произвольные задачи (вычислительная, задача управления и т. д.), в ходе выполнения которых совершается некоторая обработка информации. На диаграмме процесс обозначается прямоугольником, разбитым на две части (рис. 2.5, в). Вверху прямоугольника записывается уникальный идентификатор процесса на диаграмме, в нижней части – имя выполняемой функции. Уникальный идентификатор процесса образуют литера P и порядковый номер процесса.
В реальных системах довольно часто встречается ситуация, когда информация не может быть обработана сразу, она должна быть накоплена и сохранена для последующей обработки. При описании данных, обработка которых отложена, или данных, обрабатываемых многократно, используются накопители данных. Накопитель данных изображается на диаграмме прямоугольником с одной открытой стороной, внутри которого указывается уникальный идентификатор и имя накопителя (см. рис. 2.5, г). Уникальный идентификатор накопителя образуют литера D и его порядковый номер.
Правила соединения элементов на диаграмме потоков данных иллюстрирует рис. 2.6. Процесс может:
· принимать или передавать данные внешней сущности;
· принимать или передавать данные другому процессу;
· считывать или заносить данные в накопитель, другие связи запрещены.
Количество элементов на диаграммах потоков данных, описывающих даже относительно несложные системы, может достигать нескольких сотен. Так как построение и чтение таких диаграмм затруднено, строится их иерархия (рис. 2.7).
На верхнем уровне иерархии находится так называемая контекстная диаграмма, на которой рассматриваемая система представлена одной вершиной типа процесс. Контекстная диаграмма предназначена для отображения внешних связей системы, поэтому на ней изображаются внешние сущности, а также поступающие к ним и принимаемые от них потоки данных.
На диаграмме следующего уровня иерархии рассматриваемая система разбивается на несколько процессов. Любой процесс данной диаграммы может быть детализирован, т. е. ему может соответствовать диаграмма более низкого уровня иерархии. Количество иерархических уровней диаграмм ничем не ограничено; процесс декомпозиции имеет смысл прекратить, если описание процесса может быть сделано достаточно компактно с помощью деревьев и таблиц решений или на структурном естественном языке.
При построении иерархии диаграмм потоков данных должны соблюдаться следующие правила:
1) внешние сущности и накопители данных при необходимости дублируются на диаграммах более низкого уровня, копии накопителей и внешних сущностей специальным образом помечаются на диаграмме (рис. 2.8);
2) накопители данных размещаются на том уровне, на котором они используются более чем одним процессом (рис. 2.9), соблюдение данного требования позволяет избежать чрезвычайного усложнения диаграмм верхних уровней иерархии;
3) входные и выходные потоки детализируемого процесса должны либо дублироваться, либо уточняться на диаграмме следующего уровня (рис. 2.10) – иначе говоря, входными потоками для диаграммы более низкого уровня могут быть либо входные потоки процесса верхнего уровня, либо их компоненты (с учетом сделанных в словаре описаний структур данных); аналогичное требование справедливо и для выходных потоков диаграммы.
Жестких ограничений на количество элементов, расположенных на диаграмме, не существует; вместе с тем оптимальным числом считается порядка семи процессов. При большем количестве диаграмма становится трудночитаемой, а меньшее число приводит к появлению неоправданно большого количества диаграмм.
Дата добавления: 2018-10-26; просмотров: 288; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!