Программа которая печатает саму себя
Это интересная вещь для общего развития, ниже представляю весь код:
#include <iostream>
using namespace std; string s = "\";\nvoid r(string &s, char c, string str)\n{\n size_t p = 0;\n while ((p = s.find(c, p)) != string::npos)\n { s = s.substr(0, p) + str + s.substr(p + 1); p += str.size(); }\n}\nint main()\n{\n string z = s;\n r(z, '\\\\', \"\\\\\\\\\"); r(z, '\\n', \"\\\\n\"); r(z, '\"', \"\\\\\\\"\");\n cout << \"#include <iostream>\\nusing namespace std; string s = \\\"\" << z << s;\n}\n";
void r(string &s, char c, string str)
{
size_t p = 0;
while ((p = s.find(c, p)) != string::npos)
{ s = s.substr(0, p) + str + s.substr(p + 1); p += str.size(); }
}
int main()
{
string z = s;
r(z, '\\', "\\\\"); r(z, '\n', "\\n"); r(z, '"', "\\\"");
cout << "#include <iostream>\nusing namespace std; string s = \"" << z << s;
}
Стандартная библиотека шаблонов
В завершении данной базы знаний я должен был обязательно упомянуть о такой вещи как стандартная библиотека шаблонов. Или по-английски Standart Template Library, STL. Сюда входят структуры данных, которые часто используются при программировании. Некоторые из них мы уже рассмотрели, например, вектор, стек, очередь и т.п. Но есть ещё и другие.
STL сначала была отдельным образованием, но позже вошла в язык с++. Суть в том, чтобы сэкономить время и усилия программиста- чтобы каждый раз не писать классы для одних и тех же частых структур данных, их один раз уже написали и всё. Данные классы шаблонны- например тот же стек может принимать в качестве инфополя любые типы данных: хоть числа, хоть строки, хоть векторы- всё что душе угодно или требуется при решении той или иной задачи.
|
|
|
Ниже полная схема STL, взятая из википедии.
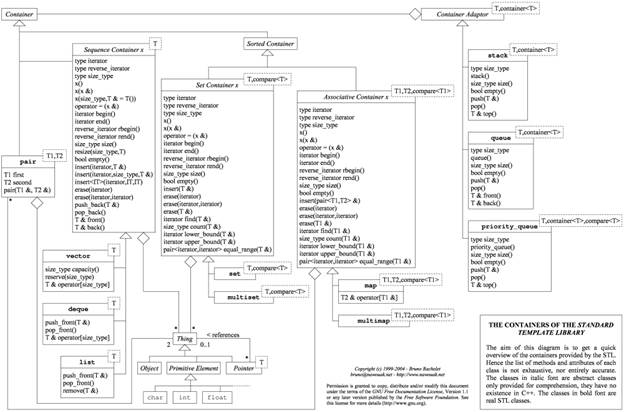
1. Вектор- он рассмотрен в главе 7.1.
2. Стек, очередь, очередь с приоритетом- рассмотрены в главе 3.2.
Рассмотрим остальные популярные шаблоны структур данных.
... ... ...
3. list или двусвязный список. Для работы нужно подключить #include <list>
Это структура данных наподобие стека, только мы можем двигаться в две стороны- как туда, так и обратно.
list <int> spisok; // создание списка из целых чисел
for(int i= 0; i<10; i++) spisok.push_back(i); // занесение в список значений 0, 1, 2 и т.д.
Первым элементом списка будет 0, последним 9. Это можно вывести через методы spisok.front() и spisok.back() - для первого и последнего соответственно.
...
Выводить список можно таким образом: сначала подключаем библиотеку
#include <iterator>
Далее используем такую конструкцию:
copy(spisok.begin(), spisok.end(), ostream_iterator<int>(cout," "));
...
Далее показаны ещё методы работы со списками:
list<int> s // создали новый пустой список
for(int i = 0; i < 15; i++) s.push_back(rand()%20); // заполнение списка случайными значениями
copy(s.begin(), s.end(), ostream_iterator<int>(cout," ")); // вывод списка
s.sort(); // сортировка списка по возрастанию
copy(s.begin(), s.end(), ostream_iterator<int>(cout," ")); // вывод списка
|
|
|
s.unique(); // оставление в списке только уникальные элементы
copy(s.begin(), s.end(), ostream_iterator<int>(cout," ")); // вывод списка
list<int> s2; // второй список
for(int i = 0; i < 15; i++) s2.push_back(rand()%10);
copy(s2.begin(), s2.end(), ostream_iterator<int>(cout," "));
s2.merge(s); // объединение с первым списком
copy(s2.begin(), s2.end(), ostream_iterator<int>(cout," "));
...
Можно добавлять элементы и в начало списка, для этого вместо push_back() используется метод push_front.
Объединяет он немного странно, но можно заметить как это происходит: остаётся второй список, идём по нему пока элемент этого второго списка не станет больше элемента первого списка. Далее он уже суёт элементы из первого списка- опять пока не встретится тот что больше из второго списка. И вот подобная запутанная система- использовать её есть смысл м.б. разве что с отсортированными списками.
... ... ...
4. Двусторонняя очередь или deque. Сокращение от double-ended-queue.
Тут всё аналогично двустороннему списку, методы тоже называются аналогично. Это как очередь, только добавлять элементы мы можем с двух сторон. Нужно подключить понятно какую библиотеку:
#include <deque>
Ну и для вывода очереди нужно использовать ту же библиотеку итераторов.
...
Ниже будет пример работы:
|
|
|
int dequeSize = 0; cin >> dequeSize; // вводим размер очереди
deque<char> m(dequeSize); // создаём очередь из символов
for(int i = 0; i < m.size(); i++) cin >> m[i]; // вводим элементы в очередь (как одно слово можно)
// если очередь не пустая, выводим её элементы
if (!m.empty()) copy( m.begin(), m.end(), ostream_iterator<char>(cout," ") );
...
Вот ещё методы работы с двухсторонними очередями:
push_front() - добавление элемента в начало
push_back() - добавление в конец
pop_front(), pop_back() - соответственно, удаление
resize(NewSize, NewElements) - переназначение размера очереди (NewSize), при этом новые пустые элементы заполняются значением NewElements. Этот метод только увеличивает размер, но не уменьшает.
... ... ...
5. map (карта) - хранит в качестве элемента 2 типа данных, например строку и соответствующее ей числовое значение.
Или по-другому это ассоциативный массив. Один элемент называется ключом, а другой- значением.
С подобными вещами мы уже сталкивались не раз, но при этом не использовали map- можно например эти 2 типа данных объединить в класс и далее использовать в массиве. Но вот здесь расскажем ещё про одну возможностью
Для работы нужно подключить соответствующую библиотеку: #include <map>
В map все ключи уникальные. Если нужно использовать повторяющиеся ключи, то применяется структура данных multimap.
|
|
|
...
Ниже будет условный пример- хэштег и число его упоминаний:
map<string,int> hashtag; // создание ассоциативного массива
// внесение значений
hashtag["москва"]= 26512;
hashtag["казань"]= 12512;
hashtag["муська"]= 45200;
cout << hashtag["муська"] << endl; // вывод одного из элементов
По сути вместо итератора у нас может стоять не только порядковое число типа 0,1,2 и т.д. типа int, а вообще любая вещь- в данном случае это строка.
... ... ...
6. Множество и мультимножество- set, multiset.
По сути это обычные вектора или массивы, но суть в том что новый элемент ставится сразу так чтобы весь массив был отсортирован- т.е. изначально в отсортированном порядке.
set <int> x; // создаём пустое множество целых чисел
for(int i=0; i<10; i++) x.insert(rand()%10 + 1); // заполняем случайными значениями
copy( x.begin(), x.end(), ostream_iterator<int>(cout, " ")); // выводим
Сортировка происходить по возрастанию. Повторяющиеся элементы отбрасываются. Для того чтобы не отбрасывались, понятно что использовать- multuset. Достаточно поменять при объявлении set на multiset и всё- вся остальная программа не меняется.
... ... ...
7. Массив значений (valarray) - отличие его в том, что с ним можно производить простейшие операции сложения, умножения и т.п. Нужно подключить #include <valarray>
Ниже пример суммирования:
valarray <int> x(10); valarray <int> y(10); // создали 2 массива из 10 элементов
for(int i=0; i<x.size(); i++) x[i]= rand()%20 + 1; // заполнение случайными значениями
for(int i=0; i<y.size(); i++) y[i]= rand()%10 + 2;
for(int i=0; i<x.size(); i++) cout << x[i] <<" "; cout << endl; // вывод массива
for(int i=0; i<y.size(); i++) cout << y[i] << " "; cout << endl;
valarray <int> z= x+y; // массив из суммы
for(int i=0; i<z.size(); i++) cout << z[i] << " "; // вывод нового массива
...
Можно сделать массив булевых значений:
valarray<bool> res(10);
res = (x<y); // если x[i]<y[i], то res[i]= 1 (true), иначе 0 (false)
for(int i = 0; i < res.size(); i++) cout << res[i] << " ";
________________________________________________
КОНЕЦ
27-31.10.17
Дата добавления: 2018-09-22; просмотров: 205; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!