Сортировка слиянием ( merge sort)
Ещё один сравнительно быстрый и рекурсивный алгоритм сортировки наряду с быстрой сортировкой, которую мы выдали ещё в 1-м разделе (или также quick sort, сортировка Хоара)
Сортировка слияния похожа на быструю сортировку. Здесь массив делится на две примерно равные половины, каждая половина сортируется этой же функцией (происходит рекурсия), а потом отсортированные массивы соединяются.
Если сравнивать с быстрой сортировкой, то там тоже происходит рекурсивное деление, но принцип сортировки другой и больше похож на пузырьковый. Только в первую очередь происходят перестановки элементов на наибольшем возможном расстоянии.
Что у быстрой сортировки, то и у сортировки слиянием- скорость алгоритма O(n*log(n)), как и у пирамидальной.
Теперь сам код сортировки слиянием- тут представлен метод нисходящего слияния.
void mergesort(int a[], int l, int r) {
if (l == r) return;
int mid = (l+r) / 2;
mergesort(a, l, mid);
mergesort(a, mid + 1, r);
int i = l;
int j = mid + 1;
int *tmp = new int [r];
for (int step = 0; step < r - l + 1; step++) {
if ((j > r) || ((i <= mid) && (a[i] < a[j]))) { tmp[step] = a[i]; i++; }
else { tmp[step] = a[j]; j++; }
}
for (int step = 0; step < r - l + 1; step++) a[l + step] = tmp[step];
}
Используется сортировка массива из 11 элементов так: mergeSort(mass,0,10); т.е. указывается левый и правый элемент. Это было нужно для рекурсии. Можно сделать перегрузку чтобы можно было указывать как обычно- добавить ниже ещё 1 доп.функцию:
void mergesort(int a[], int size) {
mergesort(a,0,size-1);
}
И теперь можно использовать как обычно: mergesort(mass,11);
|
|
|
Ниже другой код сортировки слиянием, он организован без рекурсии. Этот метод называется методом восходящего слияния.
void mergesort(int a[], int size) {
int step = 1; int *temp= new int [size];
while (step<size) {
int index= 0; int l= 0; int m= l+step; int r= l+step*2;
do {
m= m<size ? m : size;
r= r<size ? r : size;
int i1= l, i2= m;
for (; i1 < m && i2 < r; ) {
if (a[i1]<a[i2]) temp[index++]= a[i1++];
else temp[index++]= a[i2++];
}
while (i1 < m) temp[index++]= a[i1++];
while (i2 < r) temp[index++]= a[i2++];
l+= step*2; m+= step*2; r+= step*2;
} while (l<size);
for (int i = 0; i < size; i++) a[i]= temp[i];
step*= 2;
}
}
Глупая сортировка (stupid sort, случайная сортировка)
Особенность этой сортировки в том, что она самая медленная и неразумная из всех, которые только можно было придумать. На практике она не используется и нужна лишь для теории и сравнения с более эффективными практичными алгоритмами. Скорость такой сортировки O(n*n!)
Суть в том, что массив перемешивается случайным образом. И если обнаружилось, что массив отсортированный- заканчиваем сортировку.
Ниже пример такого алгоритма:
// проверка на отсортированность
bool correct (int arr[], int size) {
while (--size > 0) if (arr[size-1] > arr[size]) return false;
return true;
}
// перемешивание
void shuffle (int arr[], int size) {
for (int i=0; i<size; i++) swap(arr[i], arr[rand()%size]);
}
// сама функция сортировки
|
|
|
void stupidsort (int arr[], int size) {
while (!correct(arr, size)) shuffle(arr, size);
}
Этой функцией можно сортировать массив до 10 элементов. С большими размерами алгоритм уже не справляется, т.к. приходится перебирать всё больше вариантов: время работы растёт по факториальному закону с домножением: 1, 4, 18, 96, 600, 4320 и т.д. Например, мой компьютер сортировал такой функцией массив из 10 целых чисел в пределах значений от 0 до 999 несколько секунд.
Двоичный поиск элемента в массиве
Бывает что нам нужно найти какой-то элемент в массиве или проверить его наличие. Мы уже это делали, но только через алгоритм линейного поиска. Линейный поиск значит что мы просто по очереди перебираем варианты и смотрим- он это или не он. Ниже функции, которые работают через линейный поиск и позволяют нам найти элемент в массиве:
// есть ли элемент в массиве
template <typename Type>
bool isInArray (Type m[], int size, Type checker) {
bool res= false;
for(int i=0; i<size; i++) {
if (m[i]==checker) res= true;
}
return res;
}
// поиск позиции элемента в массиве
template <typename Type>
int PozitionInArray (Type m[], int size, Type checker) {
if(!isInArray(m,size,checker)) return -1;
else {
int poz;
for(int i=0; i<size; i++) {
|
|
|
if (m[i]==checker) poz= i;
}
return poz;
}
}
// количество таких элементов в массиве
template <typename Type>
int QuantityInArray (Type m[], int size, Type checker) {
int num= 0;
for(int i=0; i<size; i++) {
if(m[i]==checker) num++;
}
return num;
}
Но загвоздка в том, что есть более эффективный способ поиска- двоичный поиск. В нём при каждой итерации область поиска сужается в 2 раза, поэтому такой поиск быстрее. Т.е. условно нужно не N итераций, а log(N). Только важный нюанс: двоичный поиск можно применять только в отсортированном массиве, поэтому сначала массив нужно отсортировать- это можно сделать быстрой сортировкой qsort или любой другой.
Рассмотрим принцип двоичного поиска на примере. Пусть у нас есть массив из 6 элементов. Будем рассматривать уже отсортированный по возрастанию массив.
(2) (3) (5) (7) (9) (15)
В функции для линейного поиска в качестве аргументов мы вбиваем массив, размер и элемент- функция выводит позицию этого элемента в массиве. Если этого элемента нет, то выводит -1. Нам нужно написать аналогичную функцию, но для двоичного поиска.
|
|
|
Пусть мы хотим найти 15. Глянем в середину, например (7). Т.к. 15 > 7, то идём вправо. Теперь ищем середину там. И так далее.
Ниже представлен алгоритм бинарного поиска элемента в массиве:
int FindPozition (int m[], int size, int x) {
int left= 0, right= size, mid= (left+right)/2;
while ( (m[mid]!=x) && (right-left>1) ) {
if (m[mid]<x) left= mid;
else right= mid;
mid= (left+right)/2;
}
return mid;
}
Данная функция ищет позицию элемента в отсортированном по возрастанию массиве. Но только если этот элемент есть.
Можно протестировать:
const int n= 10;
int m[n]= {0,1,3,5,6,6,7,7,9,15};
int x; cin >> x;
cout << FindPozition(m,n,x) << endl;
Как можно усовершенствовать программу? Ну во-первых пусть в этой функции он сначала и сортирует массив, используем для этого сортировку скоростью O(n*log(n))- пирамидальную, быструю или слиянием. Я буду использовать быструю сортировку, как и раньше:
template <typename Type>
void qsort(Type m[], int size) {
Type terek = 0;
int left= 0, right= 0;
if(size>1) {
Type *Left = new Type[size];
Type *Right = new Type[size];
terek = m[size/2];
for(int i=0;i<size;i++) {
if (i!=size/2) {
if (m[i]<terek) {
Left[left] = m[i]; left++;
}
else {
Right[right] = m[i]; right++;
}
}
}
qsort(Left,left);
qsort(Right,right);
for(int I=0;I<size;I++){
if (I<left) {
m[I]= Left[I];;
}
else if (I==left) {
m[I]= terek;
}
else {
m[I]= Right[I-(left+1)];
}
}
}
}
template <typename Type>
int FindPozition (Type m[], int size, Type x) {
qsort(m,size);
int left= 0, right= size, mid= (left+right)/2;
while ( (m[mid]!=x) && (right-left>1) ) {
if (m[mid]<x) left= mid;
else right= mid;
mid= (left+right)/2;
}
return mid;
}
Только программа всё равно покажет позицию в уже отсортированном массиве. Но зато теперь мы можем загонять и неотсортированный тоже. Т.е. таким образом мы находим номер элемента, начиная от самого минимального. Минимальный будет нулевым, максимальный- последним (size-1). При этом есть недостаток, что скорость работы замедляется, т.к. если массив уже отсортирован, всё равно придётся это проверить функцией qsort. Можно исправить это новым аргументом:
template <typename Type>
int FindPozition (Type m[], int size, Type x, string s="sorted") {
if(s=="not_sorted") qsort(m,size);
int left= 0, right= size, mid= (left+right)/2;
while ( (m[mid]!=x) && (right-left>1) ) {
if (m[mid]<x) left= mid;
else right= mid;
mid= (left+right)/2;
}
return mid;
}
При этом мы при вызове функции можем не писать строковый аргумент, если по умолчанию у нас массив отсортирован. Чтобы не использовать строки (string), можно использовать кодовый символ (тип char) или вообще булевое значение. Ниже пример с булевым аргументом:
template <typename Type>
int FindPozition (Type m[], int size, Type x, bool sorted= true) {
if(!sorted) qsort(m,size);
int left= 0, right= size, mid= (left+right)/2;
while ( (m[mid]!=x) && (right-left>1) ) {
if (m[mid]<x) left= mid;
else right= mid;
mid= (left+right)/2;
}
return mid;
}
Также я добавил шаблон типа данных в функцию поиска.
Теперь сделаем чтобы если элемент не найден, то выводилось бы -1, как и в линейном поиске. Тогда придётся добавить проверку сначала на наличие элемента в массиве вообще.
Заметим, что если мы просим найти элемента, которого в массиве нет, нам всегда выводится последняя позиция, т.е. size-1. Либо первая, т.е. 0. Используем это в условии и получим новую функцию с добавленным условием:
template <typename Type>
int FindPozition (Type m[], int size, Type x, bool sorted= true) {
if(!sorted) qsort(m,size);
int left= 0, right= size, mid= (left+right)/2;
while ( (m[mid]!=x) && (right-left>1) ) {
if (m[mid]<x) left= mid;
else right= mid;
mid= (left+right)/2;
}
if ( ((mid==size-1)&&(m[size-1]!=x)) || ((mid==0)&&(m[0]!=x)) ) return -1;
else return mid;
}
Алгоритм Хаффмана
Здесь мы рассмотрим самый попсовый принцип архивации и разархивации информации, он реализуется благодаря алгоритму Хаффмана.
Например, у нас есть какой-то текст, и мы хотим чтобы он занимал меньше памяти. Как известно, один символ у нас кодируется определённым числом бит. Например, если это кодировка ASCII, то на 1 символ нужен 8 бит. Но каждый символ используется в тексте с разной частотой. Что если мы самые частые символы будем копировать маленьким количеством бит, а самые редкие- большим. За счёт этого принципа на исходный текст нужно в сумме меньшее количество битов. Этот алгоритм называет алгоритмом Хаффмана.
Рассмотрим упрощённый случай. У нас есть текст, где всего 5 символов: а, б, в, г, д. И с помощью них мы шифруем какое-то послание. Сначала нужно сосчитать, сколько раз используется каждый символ в тексте: пусть (а) используется 12 раз, (б) 7 раз, (в) 5 раз, (г) 2 раза, (д) 6 раз.
Запишем это друг под дружкой:
а б в г д
12 7 5 2 6
Теперь составим двоичное дерево. Цифры частот будут листами дерева. Мы берём 2 самых маленьких упоминания: в нашем случае это в(5) и г(2). И от них ведём 2 линии и составляем новый узел с суммарной частотой: 5+2=7. Одной чёрточке присваиваем 0, другой 1. И продолжаем таким образом. Ниже картинка на примере 3 символов:
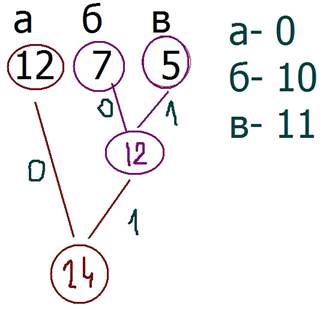
Кодирование начинается с корня. Например, для символа б- мы идём от 24 к 12 по дорожке 1, а потом от 12 к 7 по дорожке 0. Итоговый код 10.
Теперь посмотрим как закодировать например текст ААБВБ: ставим поочерёдно: 0, потом 0, потом 10, потом 11, потом опять 10, т.е. 00101110
Вот мы и поняли принцип алгоритма Хаффмана. Самое сложное- это его запрограммировать. Это, конечно, лютый пиздец и тут нам нужны более продвинутые и углублённые программистские знания, поэтому я приведу код, который я нашёл и который работает, хоть и не без косяков:
#include <iostream>
#include <vector>
#include <map>
#include <list>
#include <fstream>
using namespace std;
class Node {
public:
int a; char c;
Node *left, *right;
Node() {left=right=NULL;}
Node(Node *L, Node *R) { left = L; right = R; a = L->a + R->a; }
};
struct MyCompare {
bool operator()(const Node* l, const Node* r) const { return l->a < r->a; }
};
vector<bool> code;
map<char,vector<bool> > table;
void BuildTable(Node *root) {
if (root->left!=NULL) { code.push_back(0); BuildTable(root->left);}
if (root->right!=NULL) { code.push_back(1); BuildTable(root->right);}
if (root->left==NULL && root->right==NULL) table[root->c]=code;
code.pop_back();
}
int main (int argc, char *argv[]) {
////// считаем частоты символов
ifstream f("1.txt", ios::out | ios::binary);
map<char,int> m;
while (!f.eof()) { char c = f.get(); m[c]++;}
////// записываем начальные узлы в список list
list<Node*> t;
for( map<char,int>::iterator itr=m.begin(); itr!=m.end(); ++itr) {
Node *p = new Node;
p->c = itr->first;
p->a = itr->second;
t.push_back(p); }
////// создаем дерево
while (t.size()!=1) {
t.sort(MyCompare());
Node *SonL = t.front();
t.pop_front();
Node *SonR = t.front();
t.pop_front();
Node *parent = new Node(SonL,SonR);
t.push_back(parent);
}
Node *root = t.front(); //root - указатель на вершину дерева
////// создаем пары 'символ-код':
BuildTable(root);
////// Выводим коды в файл output.txt
f.clear(); f.seekg(0); // перемещаем указатель снова в начало файла
ofstream g("output.txt", ios::out | ios::binary);
int count=0; char buf=0;
while (!f.eof()) {
char c = f.get();
vector<bool> x = table[c];
for(int n=0; n<x.size(); n++) {
buf = buf | x[n]<<(7-count);
count++;
if (count==8) { count=0; g<<buf; buf=0; }
}
}
f.close(); g.close();
///// считывание из файла output.txt и преобразование обратно
ifstream F("output.txt", ios::in | ios::binary);
setlocale(LC_ALL,"Russian"); // чтоб русские символы отображались в командной строке
Node *p = root;
count=0; char byte;
byte = F.get();
while(!F.eof()) {
bool b = byte & (1 << (7-count) ) ;
if (b) p=p->right; else p=p->left;
if (p->left==NULL && p->right==NULL) {cout<<p->c; p=root;}
count++;
if (count==8) {count=0; byte = F.get();}
}
F.close();
cout << endl; system("pause");
return 0;
}
Дата добавления: 2018-09-22; просмотров: 222; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!