Использование прикладных статистических программ
Глава 7. Основы математико-статистической обработки данных психологического исследования и форма представления результатов
Методы и способы математико-статистической обработки у студентов гуманитарных факультетов, в том числе и психологических, вызывают значи- тельные затруднения и, как следствие, боязнь и предубеждение в возможности их овладением. Однако, как показывает практика, это ложные заблуждения. Следует понять, что в современной психологии, в практической деятельности психолога любого уровня без использования аппарата математической стати- стики все ваши выводы могут восприниматься не более как умозрительные, с известной долей субъективности. С другой стороны, по мере накопления прак- тического опыта, базы данных эмпирических исследований, неизбежно встает задача их обобщения, выявления тенденций, динамики, характерных черт, осо- бенностей, которые невозможно обоснованно интерпретировать, не используя математические методы количественного анализа.
Следует уяснить основные принципы использования математико- статистических методов в психологии:
- без использования и владения аппаратом математической статистики вы не можете считать себя квалифицированным психологом;
- аппарат математической статистики в психологии лишь инструмент для обос- нования достоверности ваших выводов и математические критерии никогда не рассматривались в психологии в качестве абсолютной истины. В тоже время, игнорирование их ни в коем случае недопустимо и требует при необходимости дополнительного обоснования;
|
|
|
- в зависимости от того, как вы используете математико-статистический ин- струментарий, таковы и будут ваши выводы (в такой же мере ваши выводы мо- гут быть оспорены другими исследователями при использовании других мето- дов).
Изучая основы статистики, не следует бояться математических формул, без знания некоторых из них, несомненно, не обойтись, но главное понимать какую психологическую реальность они описывают, какой психологический смысл в них содержится. И тогда за математическими формулами, уровнями достоверности (статистической значимости), критическими значениями коэф- фициентов откроются психологические реалии, их значение и смысл.
Начнем с некоторых практических рекомендаций:
- всегда самое трудное - начало, но это зависит только от вашего желания и целеустремленности;
- начинать необходимо с четкого уяснения базовых понятий, определе- ний. В математической статистике они достаточно четко определены и не до- пускают двойственных толкований;
- в каждом методе, формуле уясните смысл того, для чего они использу- ются в психологическом исследовании, какие результаты они дают, и каким образом их можно и должно будет интерпретировать.
|
|
|
7. 1. Анализ первичных статистик
Для определения способов математико-статистической обработки, преж- де всего, необходимо оценить характер распределения данных по всем исследу- емым психологическим признакам. Для психологических признаков, имеющих нормальное распределение или близкое к нормальному, можно использовать методы параметрической статистики, которые во многих случаях являются более мощными, чем методы непараметрической статистики. Достоинством последних является то, что они позволяют проверять статистические гипотезы независимо от формы распределения [17, 25, 40, 60].
Одним из важнейших в математической статистике является понятие нормального распределения. Нормальное распределение - модель варьирования некоторой случайной величины, значения которой определяются множеством одновременно действующих независимых факторов. Графически характер та- кого распределения описывается кривой К. Гаусса (См. Рисунок 7.1). Такой ха- рактер распределения часто встречается в исследовании психических явлений, особенно в больших выборках, поэтому исследователь в области психологии чаще всего в каждом случае выявляет характер распределения исследуемого признака.
|
|
|
 Необходимо запомнить!
Необходимо запомнить!
Характер распределения выявляется, главным образом, с целью опреде- литься в методах математико-статистической обработки данных.
Если характер распределения показателей психологического признака имеет нормальное или близкое к нормальной форме распределения признака, описываемой кривой Гаусса, то мы можем использовать параметрические методы математической статистики, как наиболее простые, надежные и досто- верные: сравнительный анализ, расчет достоверности отличий признака между выборками по t-критерию Стьюдента, F-критерию Фишера, коэффициент кор- реляции Пирсона и др.
Если, кривая распределения показателей психологического признака да- лека от нормальной, то мы вынуждены будем использовать непараметриче- ской методы математической статистики: расчет достоверности отличий по критерию Q Розенбаума (для малых выборок), по критерию U Манна-Уитни, коэффициент ранговой корреляции Спирмена, факторный, многофакторный, кластерный и другие методы анализа.
Помимо этого, по характеру распределения можно составить общее пред- ставление об общей характеристике выборки испытуемых по данному признаку и тому, на сколько данная методика соответствует (т. е. «работает», валидна) данной выборке.
|
|
|
Основными важнейшими первичными статистиками характеризующими распределение исследуемого признака являются:
Средняя арифметическая— это величина, сумма отрицательных и по- ложительных отклонений от которой равна нулю. В статистике ее обозначают буквой (М) или (X). Чтобы ее подсчитать, надо суммировать все значения ряда и разделить сумму на количество суммированных значений.
Среднее квадратичное отклонение(обозначаемое греческой буквой σ - сигма) и называемое также основным, или стандартным, отклонением) - мера разнообразия входящих в группу объектов; она показывает, на сколько в среднем отклоняется каждая варианта (конкретное значение оцениваемого параметра) от средней арифметической. Чем сильнее разбросаны варианты относительно средней, тем большим оказывается и среднее квадратичное отклонение. Разброс значений характеризует и размах — разность между наибольшим и наименьшим значением в ряду. Однако сигма полнее характеризует разброс значений относительно средней арифметической.
Следует иметь в виду, что сигма (σ) - величина именованная и зависит не только от степени варьирования, но и от единиц измерения. Поэтому по сигме можно сравнивать изменчивость лишь одних и тех же показателей, а сопостав- лять сигмы разных признаков по абсолютной величине нельзя. Для того, чтобы сравнить по уровню изменчивости признаки любой размерности (выраженные в различных единицах измерения) и избежать влияния масштаба измерений средней арифметической на величину сигмы, применяют коэффициент вариа- ции, который представляет собой по существу приведение к одинаковому мас- штабу величины (σ).
Для нормального распределения существуют точные количественные за- висимости частот и значений, позволяющие прогнозировать появление новых вариант:
1) слева и справа от средней арифметической лежит 50% вариант;
2) в интервале от М - 1σ до М + 1σ ≈ 68 % вариант;
3) в интервале от М - 1.96 σ до М + 1.96 σ ≈ 95% вариант. (см. Рисунок 7.1)
 50%
50%
М-1σ 68% М+1σ
М-1,96σ 95% М+1,96σ
Рисунок 7.1
Таким образом, ориентируясь на эти характеристики нормального рас- пределения, можно оценить степень близости к нему рассматриваемого распре- деления психологического признака.
Следующими по важности характеристиками распределения показателей признака являются такие первичные статистики, как коэффициент асимметрии и эксцесс.
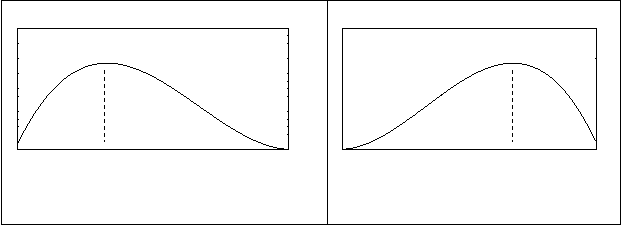
Коэффициент асимметрии -показатель скошенности распределения в левую или правую сторону по оси абсцисс. Если правая ветвь кривой длиннее левой - говорят о правосторонней (положительной) асимметрии (Рисунок 7.2); если левая ветвь длиннее правой – говорят о левосторонней (отрицательной) асимметрии (Рисунок 7.3).
 частоты
частоты
частоты
баллы Рисунок 7.2 - Правосторонняя
асимметрия
баллы Рисунок 7.3 - Левосторонняя
асимметрия
Эксцесспоказатель островершинности. Кривые, более высокие в своей средней части - островершинные, называются эксцессивными, у них большая величина эксцесса. При уменьшении величины эксцесса кривая становится все более плоской, приобретая вид плато, а затем и седловины - с прогибом в сред- ней части (Рисунок 7.4).
| Вариант А) | Вариант Б) | Вариант В) |

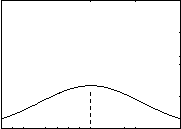
 Рисунок 7.4. - Показатели эксцессивности распределения
Рисунок 7.4. - Показатели эксцессивности распределения
Эти параметры позволяют составить первое приближенное представление о характере распределения:
1) у нормального распределения редко можно обнаружить коэффициент асимметрии, близкий к единице и более единицы (-1 и +1);
2) эксцесс у признаков с нормальным распределением обычно имеет вели- чину в диапазоне 2 – 4.
Однако, это только приблизительная оценка. Точную и строгую оценку нормальности распределения можно получить, используя один из существую- щих методов проверки (см. например, Суходольский Г.В. Основы математиче- ской статистики для психологов. – СПб., 1998; Математические методы в пси- хологии. – СПб., 2003.)
В более простом варианте показатели асимметрии и эксцесса с их ошиб- ками репрезентативности определяются по следующим формулам (см. Сидо- ренко Е.В., 1996, с. 232-233):
Общей причиной отклонения формы выборочного распределения призна- ка от нормального вида чаще всего является особенность процедуры измере- ния: используемая шкала может обладать неравномерной чувствительностью к измеряемому свойству в разных частях диапазона его изменчивости [40, с. 61].
Такие эмпирические отклонения от нормального вида, как право- или ле- восторонняя асимметрия или незначительный эксцесс (или бимодальное рас- пределение) довольно часто встречаются на практике. Связано это с особенно- стями экспериментальной выборки и используемыми измерительными проце- дурами.
В то же время, рассматриваемые в учебном пособии методы статистиче- ского анализа эмпирических данных вполне допускают отклонения от нор- мального распределения (одни - в большей степени, другие - в меньшей).
Но, в случае, если требуется убедительное обоснование, полученных ре- зультатов и производимых по ним вычислений, следует использовать, в каче- стве дополнительных несложные методы непараметрической статистики.
Следующий момент, на который следует обратить особое внимание, от- носится к интерпретации психологического значения, выявляемого данным ха- рактером распределения. Что же выявляет кривая Гаусса в характеристике пси- хологических явлений? Какой психологический смысл раскрывает кривая рас- пределения данных, оценок, тестовых баллов исследуемого психологического признака?
Следует иметь в виду, что кривая распределения тестовых баллов (оце- нок, результатов выполнения заданий и т. д.) с одной стороны, отражает свой- ства пунктов, из которых составлен тест (задание), а с другой стороны, харак- теризует состав выборки испытуемых, т. е. на сколько успешно они справляют- ся с заданием, насколько данный тест (задание) дифференцирует выборку по соответствующему качеству, признаку.
Если кривая имеет правостороннюю асимметрию1) то это значит, что в тесте преобладают трудные задания (для данной выборки) (см. Рисунок 7.2);
 1) При условии, что тестовые баллы по результатам обследования, чем выше, тем лучше развито данное свойство, способность или качество.
1) При условии, что тестовые баллы по результатам обследования, чем выше, тем лучше развито данное свойство, способность или качество.
если кривая имеет левостороннюю асимметрию, то значит большинство пунк- тов в тесте – легкие (слабые) (см. Рисунок 7.3).
Таким образом, имеется два варианта объяснения:
а) тест (задание) плохо дифференцирует испытуемых с низким уровнем развития способностей (свойств, качеств, характеристик): большинство испы- туемых получают примерно одинаковый, низкий балл.
б) тест хуже дифференцирует испытуемых с высоким развитием способ- ностей (свойств, качеств, характеристик): большинство испытуемых получают достаточно высокий балл.
Анализ эксцесса кривой распределения позволяет сделать следующие вы- воды в зависимости от формы распределения показателей (данных, вариант) психологического признака:
а) в случае, когда возникает значительный положительный эксцесс (экс- цессивная кривая) и вся масса баллов скучивается вблизи среднего значения (Рисунок 7.4 – Вариант А), возможны следующие объяснения:
- ключ составлен неверно – объединены при подсчете отрицательно свя- занные признаки, которые взаимоуничтожают баллы. Но, в практике психолога, который работает с валидными и надежными методиками, такие случаи исклю- чаются (кроме собственной невнимательности и безответственности);
- испытуемые применяют, разгадав направленность теста (опросника), специальную тактику «медианного балла» - искусственно балансируя ответы
«за» и «против» одного из полюсов измеряемого психологического признака.
б) если подбираются пункты, тесно положительно коррелирующие между собой (т. е. испытания не являются статистически независимыми), то в распре- делении баллов возникает отрицательный эксцесс, принимающий форму плато (Рисунок 7.4 – Вариант Б).
в) максимальных величин отрицательный эксцесс достигает по мере воз- растания вогнутости вершины распределения – до образования двух вершин – двух мод (с «провалом» между ними – Рисунок 7.4 – Вариант В). Такая бимо- дальная конфигурация распределения баллов указывает на то, что выборка ис- пытуемых разделилась на две категории, подгруппы (с плавным переходом между ними): одни справились с большинством заданий (согласились с боль- шинством вопросов), другие – не справились (не согласились). Такое распреде- ление свидетельствует, что в основе заданий (пунктов) лежит какой-то один общий им всем признак; соответствующий определенному свойству испытуе- мых: если у испытуемых есть это свойство (способность, знание, умение), то они справляются с большинством пунктов, заданий, если нет этого свойства – то не справляются [42, c. 55-56].
Начать с анализа первичных статистик надо еще и по той причине, что они весьма чувствительны к наличию выпадающих вариант Большие величины эксцесса и асимметрии часто являются индикатором ошибок при подсчетах вручную или ошибок при введении данных через клавиатуру для компьютер- ной обработки. Грубые промахи при введении данных в обработку можно об- наружить, если сравнить величины сигм у аналогичных параметров. Выделяю- щаяся величиной сигма может указывать на ошибки.
Существует правило, согласно которому все расчеты вручную должны выполняться дважды (особо ответственные - трижды), причем желательно раз- ными способами, с вариацией последовательности обращения к числовому массиву.
Другой причиной больших показателей эксцесса и асимметрии может яв- ляться недостаточная надежность и валидность методик, используемых для данной популяции.
В научных исследованиях по части (отдельной выборке) никогда не уда- ется полностью охарактеризовать целое, всегда остается вероятность того, что оценка генеральной совокупности на основе выборочных данных недостаточно точна, имеет некоторую большую или меньшую ошибку. Такие ошибки, пред- ставляющие собой ошибки обобщения, экстраполяции, связанные с перенесе- нием результатов, полученных при изучении выборки, на всю генеральную со- вокупность, называются ошибками репрезентативности.
Репрезентативность -степень соответствия выборочных показателей ге- неральным параметрам.
Статистические ошибки репрезентативности показывают, в каких преде- лах могут отклоняться от параметров генеральной совокупности (от математи- ческого ожидания или истинных значений) наши частные определения, полу- ченные на основе конкретных выборок. Очевидно, величина ошибки тем боль- ше, чем больше варьирование признака и чем меньше выборка. Это и отражено в формулах для вычисления статистических ошибок, характеризующих варьи- рование выборочных показателей вокруг их генеральных параметров.
Поэтому в число первичных статистик обязательно входит статистиче- ская ошибка средней арифметической.Формула для ее вычисления такова:
s
 mM = ± n
mM = ± n
; (7.2)
где mM - ошибка средней арифметической; σ - сигма, стандартное откло- нение; n- число значений признака.
Перечисленные основные первичные статистики позволяют оценить ха- рактер распределения данных в экспериментальном массиве и использовать ос- новные методы параметрической и непараметрической статистики для обосно- вания результатов эмпирического психологического исследования.
Основные методы математической статистики и форма представления результатов сравнительного анализа
Использование прикладных статистических программ
Использование прикладных статистических программ в компьютерной обработке на несколько порядков ускоряет обработку материала и предоставля- ет в распоряжение исследователя такие методы анализа, которые в ручной об-
работке не могут быть реализованы. Однако в полной мере эти преимущества могут быть использованы, если психолог имеет необходимый уровень подго- товки в этой области. Обычно, чем мощнее компьютерная программа (чем бо- лее широкие у нее возможности), тем больше времени она требует для освое- ния. Таким образом, затрачивать время на ее изучение при редких обращениях к мощному статистическому аппарату не совсем эффективно. Кроме того, очень часто использование таких программ для решения даже несложных задач также требует определенной суммы умений. Для того чтобы избежать лишних сложностей и временных затрат, целесообразно, стремиться выбрать программу имеющую достаточно развитую функцию подсказок, в том числе для неподго- товленного пользователя. Необходимо, чтобы в программе был предусмотрен режим меню - при нем пользователь на каждом шаге делает выбор для даль- нейшей работы из предложенных альтернатив и избавлен от необходимости самостоятельно формулировать задачу для работы компьютера и помнить все нужные для этого требования.
В настоящее время к числу таких программ относятся наиболее широко известные: «Statgraphics», «SPSS», «Statistica», «Mathematica» и их различные версии. Значительную помощь в овладении прикладной программой «SPSS» может оказать учебное пособие А.Д. Наследова «Математические методы пси- хологического исследования. Анализ и интерпретация данных» (2004). В дан- ной книге многообразие математико-статистических методов представлено в виде упорядоченной, логически взаимосвязанной системы с ориентацией на чи- тателя, не имеющего основательной математической подготовки. Описаны ос- новы применения этих методов, алгоритмы их выбора в зависимости от иссле- довательской ситуации – от исходных данных и задач исследования. Кроме то- го, применение каждого метода сопровождается примерами и пошаговыми ал- горитмами вычислений – как «вручную», так и с использованием стандартных статистических пакетов «SPSS».
Мы же опираемся на возможности программы «Excel», как наиболее рас- пространенной и простой в обращении. Ее возможностей вполне достаточно для использования методов математико-статистического анализа при выполне- нии квалификационной научно-исследовательской работы (диплома) и анализа данных в практической работе психолога. Однако, следует иметь в виду, что ее возможности ограничены, особенно при проведении и математическом обосно- вании фундаментальных исследований.
Математико-статистическая обработка данных в программе Excel
После того, как составлена сводная таблица (в электронном варианте), в которую занесены все данные результатов экспериментов, обследований, пре- образована и закодирована дополнительная информация, необходимо опреде- лить возможность использования наиболее оптимальных методов математико- статистической обработки данных. Мы уже указывали в настоящей главе раз- дел 7.1. и повторимся еще раз.
В случае, если распределение признака по основным или интегральным шкалам имеет вид нормального или близкого к нормальному, то можно вполне обоснованно использовать методы параметрической статистики как более про- стые и надежные. В этой группе методов относят наиболее простые:
1) сравнительный анализ первичных статистик;
2) оценка достоверности отличий по t-критерию Стьюдента;
3) корреляционный анализ.
В случае, если распределение показателей психологического признака далекое от нормального или выборка незначительна – используют методы не- параметрической статистики. Среди этой группы методов наиболее простые:
1) Q-критерий Розенбаума;
2) U-критерий Манна-Уитни;
3) коэффициента ранговой корреляции rs Спирмена.
Вычисление данных критериев и некоторых других: H-критерия Круска- ла-Уоллиса, T-критерия Вилкоксона, и т. д. может осуществляться при помощи обычного калькулятора. Алгоритмы проведения данных расчетов с примерами очень подробно и доходчиво изложены Е.В. Сидоренко в практическом руко- водстве «Методы математической обработки в психологии» (1996), к которому мы и отсылаем читателя в случае необходимости использовать подобные мето- ды непараметрической статистики.
В приложении 2 приведена классификация задач и основные рекоменду- емые математико-статистические методы их решения, которые используются в психологии.
Вычисление первичных статистик и характера распределения
Признака
Прежде всего, необходимо твердо уяснить некоторые немногочисленные правила работы в программе Excel:
- входные параметры, параметры вычислений задаются на английском языке, за исключением случаев, которые будут специально оговорены;
- вычисления производятся в той ячейке, которая выделена курсором;
- для определения (задания) параметров вычислений (или координат яче- ек) используются верхняя (буквенная) и левая (числовая) координатные рамки окна Excel.
После того как сводная ведомость составлена в рукописном варианте (на необходимость этого мы указывали выше), она составляется в компьютерном варианте. Общий вид рабочего окна программы Excel и пример сводной табли- цы представлены на Рисунке 7.5.

Рисунок 7.5 - Вид рабочего окна программы Excel
Первое с чего следует начать – это вычислить первичные статистики и выявить характер распределения признака.
Первичные статистики: M, σ, n, m– вычисляются внизу таблицы по каж- дому признаку отдельно.
M – средняя арифметическая, вычисляемого признака. Функция
«СРЗНАЧ».
o -стандартное отклонение, среднеквадратичное отклонение показате- лей, вариант признака. Часто обозначается в программе Excel буквой – S, для того чтобы не использовать лишний раз таблицу символов. Функция «СТАН- ДОТКЛОН».
n – количество показателей (вариант) признака в столбце. Функция
«СЧЕТ».
m- ошибка средней арифметической.
В программе Excel существует два варианта вычислений первичных ста- тистик:
а) полуавтоматический (полу ручной, с набором некоторых данных для выполнения программных функций на клавиатуре);
б) автоматический (с использование возможностей, запрограммирован- ных функций).
Полуавтоматический вариант вычисления первичных статистик. Вся ра- бота ведется в окне, в котором набрана сводная таблица (как правило, это Лист 1). Курсором выделяется ячейка внизу таблицы под столбцом первого психоло- гического признака напротив вычисляемых статистик по порядку. Вначале M, затем – σ, далее – nи m. Алгоритм вычислений: выбираем в меню Вставку
 функции
функции
ƒn
щелчок левой клавишей мышки – открывается диалоговое окно Мастер функ- ций(Рисунок 7.6).

Рисунок 7.6 – Вид диалогового окна «Мастер функций»
В левом окне «Категория» выбираем «10 недавно использовавшихся». В правом окне «Функция» появляется ряд функций из которых нас интересует:
«СРЗНАЧ» вычисляет M, «СТАНДОТКЛОН» - σ (S) , «СЧЕТ» - n (Если неко- торые из указанных функций отсутствуют, то их можно найти в окне «Катего- рия» > «Статистические»). Вычисляем по порядку. Выбираем функцию
«СРЗНАЧ» - ОК >появляется диалоговое окно (Рисунок 7.7).

Рисунок 7.7 – Диалоговое окно вычисления функции «СРЗНАЧ»
В окне Число 1задаем параметры вычисления, начиная с первого числен- ного значения признака и заканчивая последним численным значением признака
 в данном столбце. Для данного примера (см. Рис. раметры будут выглядеть следующим образом:
в данном столбце. Для данного примера (см. Рис. раметры будут выглядеть следующим образом:
С 4 : С 29
Сводной таблицы) эти па-
Далее команда >ОК и в выделенной курсором ячейке внизу сводной таб- лицы появляется вычисленное значение средней арифметической по группе всех показателей признака. По аналогичному алгоритму и заданным парамет- рам вычисляется «СТАНДОТКЛОН» - σ (S) и «СЧЕТ» - n (количество показа- телей, вариант в столбце признака).
Ошибка средней арифметической (mM) вычисляется по указанной ранее формуле.
s
 mM = ± n
mM = ± n
; (7.3)
где mM - ошибка средней арифметической; σ - сигма, стандартное отклонение; n- число значений признака.
Эта формула набирается вручную на клавиатуре в ячейке, выделенной курсором под столбцом первого психологического признака напротив вычисля- емой статистики (m). При наборе в программе Excel для нашего примера фор- мула имеет вид (см. 7.3):
 = С 34 / корень (C35) (7.4)
= С 34 / корень (C35) (7.4)
Примечание - Все значения формулы набираются только на ан- глийском языке, за исключением слова «корень». При наборе формулы необходимо быть предельно внимательным в соблю- дении последовательности всех знаков и скобок.
После того, как вычислены первичные статистики (M, σ (S), n, m) по первому признаку, следует рассчитать их по всем остальным. Это делается сле- дующим образом. Выделяется курсором столбец, вычисленных первичных ста- тистик по первому признаку (Рисунок 7.8), далее команда >«Копировать», за- тем выделяется область вставки под остальными столбцами признаков и ко- манда >«Вставить». Вычисляемые значения появляются автоматически, по- скольку связаны со значениями столбцов каждого признака соответствующими формулами и (Рисунок 7.9).

Рисунок 7.8

Рисунок 7.9
Преимущество данного метода вычисления первичных статистик состоит в том, что вычисленные значения функционально связаны посредством формул с данными табличных значений в столбцах каждого признака. При необходи- мости дополнить таблицу новыми данными, пересчет первичных статистик осуществляется автоматически.
Но в этом же заключается и недостаток данного метода вычислений. По- этому, в случае необходимости сохранить эти данные без изменения, следует их скопировать и вставить на другой лист командой «Специальная вставка» >
◙ «значения» (Рисунок 7.10). В таком случае данные вычислений на новом ли- сте будут функционально «разорваны», т.е. независимы от последующих вы- числений и операций, связанных с преобразованием сводной таблицы. При необходимости их можно распечатать отдельно для последующего анализа.
 Запомните: в программе Excel при переносе данных с одного листа на другой целесообразнее пользоваться функцией «Специальная вставка» >◙ «значения».
Запомните: в программе Excel при переносе данных с одного листа на другой целесообразнее пользоваться функцией «Специальная вставка» >◙ «значения».

Рисунок 7.10 – Вид диалогового окна «Специальная вставка»
Автоматический вариант вычисления первичных статистик с исполь- зование возможностей, запрограммированных функций.
Заложенные в программе Excel функции позволяют производить вычис- ления первичных статистик в более широком диапазоне характеристик кривой распределения. К ним относятся значения: среднее арифметическое, стандарт- ная ошибка (средней арифметической), медиана, мода, стандартное отклонение, дисперсия выборки, эксцесс, асимметричность, интервал, минимум, максимум, сумма, счет (количество данных в столбце признака) и т.д.
Алгоритм вычисления: выбираем в меню «Сервис» > «Анализ данных»
появляется окно функций (Рисунок 7.11).
 Примечание: в случае, если функция «Анализ данных» отсутствует, то ее необ- ходимо выставить. Алгоритм следующий: «Сервис» > «Надстройка» > «Пакет анализа» >ОК.
Примечание: в случае, если функция «Анализ данных» отсутствует, то ее необ- ходимо выставить. Алгоритм следующий: «Сервис» > «Надстройка» > «Пакет анализа» >ОК.

Рисунок 7.11 – Вид диалогового окна функций «Анализ данных»
 Выбираем функцию «Описательная статистика» >ОК. Появляется диало- говое окно (Рисунок 7.12).
Выбираем функцию «Описательная статистика» >ОК. Появляется диало- говое окно (Рисунок 7.12).
Рисунок 7.12 – Вид диалогового окна функции «Описательная статистика» Необходимо указать «входной интервал». Он задается, начиная от наиме-
нования первого психологического признака (в строке наименований, обозначе- ний признаков) по диагонали до последнего численного значения признака в по-
следнем столбце таблицы (см. Рисунок 7.14). В нашем случае данный интервал
С 3 : P 29(см. Рисунок 7.12).
Далее выставляются: группирование «по столбцам»,
«Метки в первой строке»,
«Новый рабочий лист» (выставляется автоматически),
«Итоговая статистика»,
 «Уровень надежности», остальные параметры указываются по желанию. После чего исполнительная команда – ОК. На новом листе появляется таблица следующего вида (Рисунок 7.13). Данную таблицу после незначительного ре- дактирования (удалить повторяющиеся столбцы с названиями первичных ста- тистик, за исключением первого) можно распечатать и использовать при прове- дении сравнительного анализа.
«Уровень надежности», остальные параметры указываются по желанию. После чего исполнительная команда – ОК. На новом листе появляется таблица следующего вида (Рисунок 7.13). Данную таблицу после незначительного ре- дактирования (удалить повторяющиеся столбцы с названиями первичных ста- тистик, за исключением первого) можно распечатать и использовать при прове- дении сравнительного анализа.
Рисунок 7.13 – Результаты вычисления первичных статистик при помощи функции «Описательная статистика»
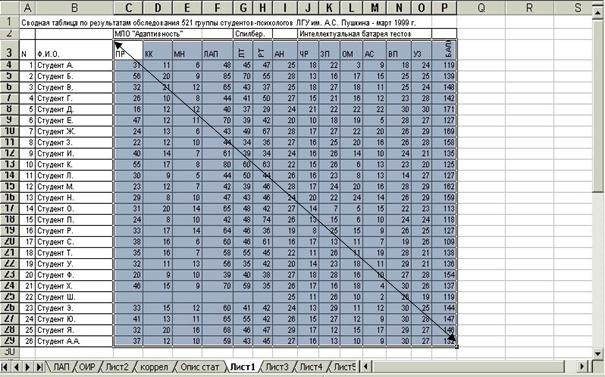 Рисунок 7.14 - Параметры «Входного интервала» С3 : Р29
Рисунок 7.14 - Параметры «Входного интервала» С3 : Р29
Характер распределения признака.
Точные количественные характеристики распределения, как было пока- зано выше, вычисляются при помощи функции «Описательная статистика». Однако, для наглядного представления характера распределения исследуемого признака, целесообразно построить гистограмму частотного распределения. Особенно в случае, если вы предполагаете использовать методы параметриче- ской статистики.
Алгоритм вычислений в программе Excel следующий: «Сервис» > «Ана- лиз данных» > «Гистограмма» -ОК (см. Рисунок 7.11). Появляется диалого- вое окно «Гистограмма» (Рисунок 7.15).
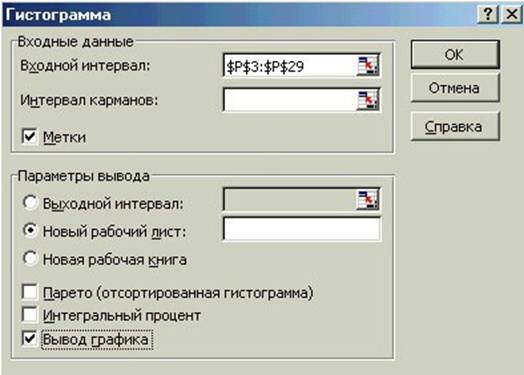
Рисунок 7.15 – Вид диалогового окна функции «Гистограмма»
Гистограмма строится по столбцам, т.е. по совокупности данных (пара- метров) признака. Как правило, характер распределения данных признака вы- является по основным (интегральным) шкалам методики (теста, задания).
Для нашего случая целесообразно построить гистограммы и выявить ха- рактер распределения признака по основным подшкалам методики МЛО
«Адаптивность» (ПР - поведенческая регуляция; КК – коммуникативные кач- кства; МН – моральная нормативность) и интегральной шкале (ЛАП – личност- ный адаптационный потенциал), основным шкалам методики «Спилбергер- Ханин» (РТ – реактивная тревожность, ЛТ – личностная тревожность), инте- гральной шкале интеллектуального развития «Балл».
В качестве примера, рассчитаем только характер распределения по инте- гральной шкале общего уровня интеллектуального развития «Балл». В диалого- вом окне функции «Гистограмма» задаем входной интервал. Начиная от наиме-нования признака столбца данных в общей шкале наименований (параметры P3) и заканчивая последним численным значением признака в данном столбце (па- раметр P29).
Для нашей таблицы значений признака этот интервал P 3 : P 29(см. Ри- сунок 7.5, затем Рисунок 7.15). Далее выставляем:
«Метки» - «Новый рабочий лист» (задается автоматически) – «Вывод графика» - ОК. На новом рабочем листе появляется гистограмма частотного распределения значений признака в данном столбце (Рисунок 7.16).

Рисунок 7.16 – Гистограмма частотного распределения значений призна-
ка по шкале «Балл»
Аналогично строятся гистограммы частотного распределения значений признака по остальным шкалам.
Выяснив, что распределение признака по основным шкалам нормальное или близкое к нормальному, мы в праве переходить к сравнительному анализу и использованию наиболее распространенных методов параметрической стати- стики.
Сравнительный анализ первичных статистик
И формы его представления
Первичной и наиболее распространенной формой анализа данных резуль- татов психологического исследования является сравнительный анализ первич- ных статистик между двумя или более группами выборок. Пренебрегать им не следует уже в силу того, что он показывает степень различия в значениях меж- ду исследуемыми психологическими признаками. Помимо этого практика пока- зывает, что эти различия всегда будут существовать.
Однако, делать обобщения касающиеся этих различий в исследуемых вы- борках и экстраполировать (переносить) их на всю популяцию в целом крайне недопустимо. Ибо, выявленные различия посредством сравнительного анализа первичных статистик показательны и характеризуют различия лишь между данными выборками.
Данные сравнительного анализа первичных статистик оформляются в таблицах. Форма их представления в тексте научной публикации или класси- фикационной (дипломной) работы выглядит следующим образом. Например:
Таблица 7.1 - Сравнение средних значений компонентов эмпатийного потенциала высокодисциплинированных и низкодисциплинированных учащихся
|
Психологический признак | Дисц. = 8-10 баллов, n = 63 чел. | Не дисц.= 1-3 балла, n =36 чел. |
t-Stud |
p | ||
| М±m | σ | М±m | σ | |||
| Sp– стремление к принятию | 101,2±2,19 | 17.4 | 92,6±2,71 | 17,5 | 2,471 | <0,05 |
| So– страх отвержения | 151,3±2,74 | 21,8 | 136,6±2,51 | 163 | 3,937 | <0,05 |
| Rc- рациональный канал эмпатии | 3,2±0,15 | 1,2 | 3,4±0,23 | 1,5 | 0,714 | >0,05 |
| Ec- эмоциональный канал | 2,6±0,21 | 1,7 | 2,9±0,22 | 1,5 | 0,962 | >0,05 |
| Us– установки, спо- собств. эмпатии | 3,1±0,20 | 1,6 | 2,5±0,18 | 1,2 | 2,314 | <0,05 |
| Pr- проникающая способность | 3,7±0,13 | 1,1 | 2,9±0,23 | 1,5 | 3,069 | <0,05 |
| It- идентификация | 3,5±0,21 | 1,6 | 2,5±0,12 | 0,8 | 3,924 | <0,05 |
| Ou– общий уровень эмпатии | 18,7±0,49 | 3,9 | 16,9±0,46 | 3,0 | 2,685 | <0,05 |
| Et- эмпатическая тенденция | -1,3±2,65 | 21,1 | -5,5±3,08 | 20,0 | 1,022 | >0.05 |
Примечание - Жирным шрифтом выделены психологические признаки, по ко- торым существуют различия на достоверно значимом уровне.
После использования ряда других методов (в приведенном примере, это оценка достоверности различий между средними по t-критерию Стьюдента), таблица может быть дополнена показателями критериев и уровнем их довери- тельной значимости (p).
Кроме того, эти данные можно для наглядности отобразить графически, например, в диаграммах разных форм и видов.
19
18,5
18
17,5
Дата добавления: 2018-06-01; просмотров: 816; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!