Получение статистических данных
Министерство образования и науки Российской Федерации
(МИНОБРНАУКИ РОССИИ)
ТОМСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ (ТГУ)
Геолого-географический факультет
Кафедра минералогии и геохимии
Казаченко Артем Владимирович
Контрольная работа
по дисциплине «Математические методы моделирования в геологии»
Вариант №8
| Выполнил |
| Студент группы №02380 ________ П.О. Сидорова |
| Проверил |
| Доцент каф. минералогии и геохимии ___________Е. М. Асочакова |
Томск 2018
Содержание
Введение. 3
1. Статистические характеристики, используемые в геологии. 6
2. Закон распределения данных. 11
3. Дисперсионный анализ. 13
4. Корреляционный анализ. 18
5. Регрессионный анализ. 20
6. Нелинейная регрессия. 23
7. Кластерный анализ. 25
8. Факторный анализ. 29
Заключение. 35
Введение
На современном этапе развития естественных наук, под влиянием научно-технического прогресса происходят существенные изменения методов научных экспериментов, анализа и обобщения получаемых результатов. Этому способствуют не только расширившиеся возможности фундаментальных наук, но также бурное развитие электронно-вычислительной техники и комплексной автоматизации самых разнообразных видов человеческой деятельности. В последние десятилетия наблюдается глубокое проникновение математических методов исследования во все отрасли естественных наук, что способствовало исключительным успехам некоторых из них, например биологии, метеорологии и др. Для успешного развития геологических наук необходимо также использовать полный арсенал существующих прогрессивных научных и технических средств, включая математические методы.
Основная цель данной работы выяснить и понять распределение полезных компонентов в скв.53 Южно-русского участка, по данным полученным в результате рентгенофлуоресцентного анализа осадочных горных пород.
Для достижения поставленной цели решались следующие задачи:
1. научиться применять математические методы для обработки геологической информации;
2. научиться формулировать геологические задачи в пригодном виде для их решения математическими методами;
3. научится применять наиболее эффективные методы;
4. понять основные принципы геолого-математического моделирования;
5. установить возможность применения геолого-математического моделирования для данного участка.
Таблица №1
Исходные данные для достижения поставленной цели в %
| №пп | №пр | Na2O | MgO | Al2O3 | SiO2 | P2O5 | S* | K2O | CaO | TiO2 | MnO | Fe2O3 | ППП | Сумма |
| 1 | 31534 | 2,47 | 2,84 | 15,68 | 65,26 | 0,1 | 0,02 | 2,31 | 1,05 | 0,63 | 0,05 | 4,76 | 4,89 | 100,05 |
| 2 | 31535 | 1,97 | 2,47 | 12,12 | 70,05 | 0,09 | 0,02 | 2,31 | 0,96 | 0,55 | 0,08 | 4,53 | 4,71 | 99,85 |
| 3 | 31536 | 2,68 | 2,06 | 13,08 | 70,37 | 0,08 | 0,02 | 2,47 | 0,96 | 0,74 | 0,04 | 3,22 | 4,13 | 99,85 |
| 4 | 31537 | 2,78 | 1,68 | 11,28 | 73,35 | 0,04 | 0,02 | 2,78 | 0,83 | 0,75 | 0,04 | 2,81 | 3,36 | 99,71 |
| 5 | 31538 | 5,02 | 1,89 | 12,07 | 69,41 | 0,09 | 0,02 | 2,41 | 0,94 | 0,39 | 0,03 | 3,07 | 4,77 | 100,1 |
| 6 | 31539 | 0,51 | 2,37 | 38,17 | 33 | 0,1 | 0,02 | 0,99 | 1,29 | 1,98 | 0,07 | 9,91 | 12,66 | 101,08 |
| 7 | 31540 | 1,04 | 3,03 | 10,41 | 59,73 | 0,05 | 0,01 | 1,51 | 9,77 | 0,43 | 0,02 | 1,88 | 11,43 | 99,32 |
| 8 | 31541 | 2,18 | 3,39 | 13,74 | 62,78 | 0,08 | 0,02 | 2,08 | 2,81 | 0,57 | 0,08 | 4,68 | 6,91 | 99,33 |
| 9 | 31542 | 2,87 | 2,46 | 13,69 | 64,89 | 0,05 | 0,02 | 2,26 | 1,11 | 0,56 | 0,08 | 5,06 | 7,1 | 100,15 |
| 10 | 31544 | 2,03 | 2,59 | 17,44 | 67,19 | 0,05 | 0,02 | 2,45 | 0,93 | 0,65 | 0,02 | 2,16 | 4,89 | 100,41 |
| 11 | 31545 | 2,75 | 2,34 | 22,04 | 59,04 | 0,01 | 0,02 | 2,68 | 0,84 | 0,87 | 0,02 | 3,57 | 5,6 | 99,79 |
| 12 | 31546 | 2,26 | 2,94 | 18,43 | 65,6 | 0 | 0,04 | 2,49 | 0,87 | 0,7 | 0,04 | 2,97 | 4,12 | 100,45 |
| 13 | 31547 | 2,6 | 2,43 | 17,18 | 64,59 | 0,13 | 0,02 | 2,41 | 0,92 | 0,58 | 0,03 | 3,21 | 5,02 | 99,13 |
| 14 | 31548 | 1,39 | 4,08 | 10,08 | 64,78 | 0,07 | 0,02 | 1,73 | 4,05 | 0,33 | 0,04 | 3,74 | 9,04 | 99,35 |
| 15 | 31548 | 3,07 | 1,95 | 13,78 | 71,59 | 0,04 | 0,01 | 2,25 | 0,77 | 0,63 | 0,01 | 1,91 | 3,88 | 99,9 |
| 16 | 31549 | 1,88 | 1,71 | 9,04 | 77,67 | 0,02 | 0,02 | 1,9 | 0,76 | 0,44 | 0,02 | 2,37 | 3,81 | 99,64 |
| 17 | 31550 | 1,87 | 5,21 | 11,36 | 58,43 | 0,07 | 0,02 | 1,73 | 6,06 | 0,62 | 0,04 | 3,61 | 10,72 | 99,73 |
| 18 | 31551 | 3 | 1,76 | 13,76 | 70,7 | 0,02 | 0,02 | 2,6 | 0,71 | 0,72 | 0,02 | 2,3 | 4,21 | 99,82 |
| 19 | 31552 | 1,55 | 6,09 | 13,4 | 49,95 | 0,1 | 0,02 | 1,56 | 5,6 | 0,6 | 0,15 | 8,09 | 12,99 | 100,09 |
| 20 | 31553 | 2,18 | 2,23 | 13,77 | 71,84 | 0,03 | 0,02 | 2,59 | 0,78 | 0,58 | 0,02 | 2,46 | 3,35 | 99,84 |
| 21 | 31554 | 2,45 | 2,84 | 13,92 | 65,07 | 0,09 | 0,02 | 2,29 | 2,05 | 0,65 | 0,05 | 4,29 | 6,33 | 100,06 |
| 22 | 31555 | 2,92 | 3,2 | 11,88 | 60,9 | 0,09 | 0,02 | 2,21 | 3,04 | 0,55 | 0,1 | 6,73 | 8,54 | 100,18 |
| 23 | 31556 | 3,02 | 1,96 | 16,11 | 65,98 | 0,03 | 0,02 | 2,61 | 0,97 | 0,76 | 0,03 | 2,92 | 5,51 | 99,92 |
| 24 | 31557 | 2,72 | 2,65 | 15,57 | 62,56 | 0,11 | 0,02 | 2,45 | 1 | 0,68 | 0,07 | 5,77 | 6,42 | 100,03 |
| 25 | 31558 | 2,21 | 2,32 | 21,65 | 60,98 | 0,02 | 0,02 | 2,81 | 0,75 | 0,88 | 0,01 | 2,36 | 6,02 | 100,03 |
| 26 | 31559 | 2,91 | 3,2 | 10,24 | 65,61 | 0,02 | 0,02 | 2,03 | 3,96 | 0,41 | 0,04 | 3,43 | 8,17 | 100,02 |
| 27 | 31560 | 1,93 | 1,7 | 8,69 | 76,09 | 0 | 0,02 | 2,2 | 0,82 | 0,32 | 0,02 | 2,77 | 5,11 | 99,66 |
| 28 | 31561 | 0,85 | 1,45 | 9,64 | 80,06 | 0,01 | 0,02 | 2,06 | 0,62 | 0,72 | 0,01 | 1,31 | 2,69 | 99,45 |
| 29 | 31562 | 0,62 | 1,09 | 3,79 | 85,36 | 0,01 | 0,02 | 1,22 | 0,52 | 0,34 | 0,02 | 1,89 | 4,42 | 99,3 |
| 30 | 31563 | 1,29 | 4,68 | 9,73 | 61,36 | 0,03 | 0,02 | 1,73 | 5,32 | 0,38 | 0,06 | 4,05 | 11,79 | 100,42 |
| 31 | 31564 | 1,71 | 1,85 | 16,22 | 68,19 | 0 | 0,03 | 2,62 | 0,7 | 0,53 | 0,01 | 1,83 | 6,13 | 99,81 |
| 32 | 31565 | 2,6 | 2,26 | 13,66 | 66,43 | 0,04 | 0,03 | 2,26 | 1,3 | 0,52 | 0,03 | 4,13 | 6,68 | 99,94 |
| 33 | 31566 | 2,45 | 2,15 | 16,93 | 64,91 | 0,08 | 0,03 | 2,62 | 0,99 | 0,58 | 0,02 | 3 | 6,21 | 99,97 |
| 34 | 31567 | 1,69 | 2,3 | 13,02 | 68,52 | 0,06 | 0,02 | 2,29 | 2,14 | 0,46 | 0,03 | 2,52 | 6,86 | 99,91 |
Статистические характеристики используемые в геологии
Минимальное значение – наименьшее возможное значение, максимальное значение – наибольшее возможное значение. Среднее значение - статистический обобщенный показатель какой либо величины. Среднее арифметическое - (в математике и статистике) множества чисел — число, равное сумме всех чисел множества, делённая на их количество.

Среднее арифметическое взвешенное - общее название группы разновидностей среднего значения либо короткое название для любого из перечисленных: Среднее арифметическое взвешенное Среднее геометрическое взвешенное Среднее гармоническое взвешенное.
Среднее арифметическое взвешенное набора чисел x1……xn с весами ω1……ωn определяется как:
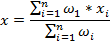
Средним геометрическим нескольких положительных вещественных чисел называется такое число, которым можно заменить каждое из этих чисел так, чтобы их произведение не изменилось.

Среднее степенное – любое число отличительное от нуля.
Среднее степени d (или просто среднее степенное) набора положительных вещественных чисел x1,…,xn определяется как:

Среднее квадратическое – число S, равное квадратному корню среднего арифметического квадратов данных чисел a1,a2,…,an:

Среднее гармоническое – один из способов, которым можно понимать «среднюю» величину некоторого набора чисел. Его можно определить следующим образом: пусть даны положительные числа x1,…xn, тогда их средним гармоническим будет такое число H, что

Можно получить явную формулу для среднего гармонического:

т.е. среднее гармоническое есть обратная величина к среднему от обратных к числам x1,…,xn.
Медиана – середина, в математической статистике – число, характеризующее выборку (например набор чисел). Если все элементы выборки различны, то медиана — это такое число выборки, что ровно половина из элементов выборки больше него, а другая половина меньше него. В более общем случае медиану можно найти, упорядочив элементы выборки по возрастанию или убыванию и взяв средний элемент. Например, выборка {11, 9, 3, 5, 5} после упорядочивания превращается в {3, 5, 5, 9, 11} и её медианой является число 5. Если в выборке чётное число элементов, медиана может быть не определена однозначно: для числовых данных чаще всего используют полусумму двух соседних значений (то есть медиану набора {1, 3, 5, 7} принимают равной 4).
Мо́да - значение во множестве наблюдений, которое встречается наиболее часто. (Мода = типичность.) Иногда в совокупности встречается более чем одна мода (например: 6, 2, 6, 6, 8, 9, 9, 9, 0; мода — 6 и 9). В этом случае можно сказать, что совокупность мультимодальна. Из структурных средних величин только мода обладает таким уникальным свойством. Как правило, мультимодальность указывает на то, что набор данных не подчиняется нормальному распределению.
Квартили - предоставляют важную информацию о структуре вариационного ряда к-л признака. Вместе с медианой они делят вариационный ряд на 4 равные части. Квартилей две, их обозначают символами Q, верхняя и нижняя квартиль. 25% значений меньше, чем нижняя квартиль, 75% значений меньше, чем верхняя квартиль.
Для расчёта квартили надо поделить вариационный ряд медианой на две равные части, а затем в каждой из них найти медиану. К примеру, если выборка состоит из 6 элементов, тогда за начальную квартиль выборки принимается второй элемент, а за нижнюю квартиль пятый элемент.

Рис 1. Квартили
В случае, если вариационный ряд состоит к примеру, из 9 элементов, тогда за верхнюю квартиль принимают арифм. среднее 2-го и 3-го элеметов, а за нижнюю арифм. среднее 7-го и 8-го элементов.
Децили – это значения признака в ранжированном ряду распределения, выбранные таким образом, что 10% единиц совокупности будут меньше по величине D1; 80% будут заключены между D1 и D9; остальные 10% превосходят D9.
Квантили – значение, которое заданная случайная величина не превышает с фиксированной вероятностью. Если вероятность задана в процентах, то квантиль называется перцентилем. Например, для развитых стран 95-процентиль продолжительности жизни составляет 100 лет, означает, что ожидается, что 95% людей не доживут до 100 лет.
Дисперсия – мера разброса значений случайной величины относительно ее математического ожидания. Обозначается D[X] в русской литературе и Var(X) в зарубежной. В статистике часто употребляется значение σ2x или σ2.
Среднеквадрати́ческое отклоне́ние (синонимы: среднее квадрати́ческое отклоне́ние, среднеквадрати́чное отклоне́ние, квадрати́чное отклоне́ние; близкие термины: станда́ртное отклоне́ние, станда́ртный разбро́с) — в теории вероятностей и статистике наиболее распространённый показатель рассеивания значений случайной величины относительно её математического ожидания. При ограниченных массивах выборок значений вместо математического ожидания используется среднее арифметическое совокупности выборок (измерений), это среднее арифметическое называют оценкой математического ожидания.
Коэффициент вариации - Мера относительного разброса случайной величины; показывает, какую долю среднего значения этой величины составляет её средний разброс.
Коэффициент вариации равен отношению стандартного отклонения к среднему значению:

Коэффициент вариации имеет смысл использовать при ненулевых средних значениях.
Коэффициент полезен в ситуациях, когда о размерах отклонения величины можно судить, зная ее среднее значение.
Иногда предлагается условная классификация вариабельности выборки на основе коэффициента вариации: при выборка вариабельна слабо, при - средне, при - сильно.
Асимметрия представляет собой числовое отображение степени отклонения графика распределения показателей от симметричного графика распределения. Если асимметрия больше 0, то чаще в распределении встречаются значения меньше среднего. Такая асимметрия называется положительной или левосторонней[1].
Коэффициент эксцесса - (коэффициент островершинности) в теории вероятностей — мера остроты пика распределения случайной величины.
Пусть задана случайная величина X, такая что E│X│4<∞. Пусть µ4 обозначает четвертый центральный момент: µ4 = E [(X – EX)4], а  – стандартное отклонение X. Тогда коэффициент эксцесса задается формулой:
– стандартное отклонение X. Тогда коэффициент эксцесса задается формулой:

Получение статистических данных
1.2
С помощью программы Statistica 6.1 удалось получить такие статистические данные как:
1. среднее значение;
2. среднее гармоническое;
3. среднее геометрическое;
4. медиана;
5. мода;
6. частота моды;
7. сумма;
8. минимум;
9. максимум;
10. нижняя квартиль;
11. верхняя квартиль;
12. размах;
13. квартиль размаха;
14. дисперсия;
15. стандартное отклонение;
16. асимметрия;
17. эксцесс.
Полученные статистические данные указаны в таблице №2.
Таблица №2 Статистические данные
|
| N набл. | Среднее | Доверит. -95,000% | Доверит. +95,000% | Медиана | Мода | Частота моды | Сумма | Мини- мум | Макси-мум | Дисперс. | Стд. откл. | Станд. Ошибка | Асим-метрия | Эксцесс |
| Na2O | 34 | 2,22 | 1,92 | 2,52 | 2,24 | Множест. | 2 | 75,47 | 0,51 | 5,02 | 0,74 | 0,86 | 0,15 | 0,50 | 2,40 |
| MgO | 34 | 2,62 | 2,25 | 2,99 | 2,36 | Множест. | 2 | 89,17 | 1,09 | 6,09 | 1,12 | 1,06 | 0,18 | 1,67 | 3,18 |
| Al2O3 | 34 | 14,16 | 12,21 | 16,12 | 13,68 | Множест. | 1 | 481,57 | 3,79 | 38,17 | 31,41 | 5,60 | 0,96 | 2,39 | 9,77 |
| SiO2 | 34 | 65,95 | 62,85 | 69,05 | 65,61 | Множест. | 1 | 2242,24 | 33,00 | 85,36 | 78,97 | 8,89 | 1,52 | -1,26 | 5,28 |
| P2O5 | 34 | 0,05 | 0,04 | 0,07 | 0,05 | Множест. | 4 | 1,81 | 0,00 | 0,13 | 0,00 | 0,04 | 0,01 | 0,21 | -1,12 |
| S* | 34 | 0,02 | 0,02 | 0,02 | 0,02 | ,0200000 | 28 | 0,71 | 0,01 | 0,04 | 0,00 | 0,01 | 0,00 | 1,58 | 6,17 |
| K2O | 34 | 2,20 | 2,05 | 2,36 | 2,29 | 1,730000 | 3 | 74,91 | 0,99 | 2,81 | 0,19 | 0,44 | 0,08 | -1,05 | 0,79 |
| CaO | 34 | 1,95 | 1,23 | 2,67 | 0,97 | ,9600000 | 2 | 66,19 | 0,52 | 9,77 | 4,27 | 2,07 | 0,35 | 2,28 | 5,51 |
| TiO2 | 34 | 0,62 | 0,52 | 0,72 | 0,58 | ,5800000 | 3 | 21,10 | 0,32 | 1,98 | 0,08 | 0,28 | 0,05 | 3,52 | 16,91 |
| MnO | 34 | 0,04 | 0,03 | 0,05 | 0,03 | ,0200000 | 9 | 1,40 | 0,01 | 0,15 | 0,00 | 0,03 | 0,01 | 1,73 | 3,76 |
| Fe2O3 | 34 | 3,63 | 2,99 | 4,27 | 3,14 | Множест. | 1 | 123,31 | 1,31 | 9,91 | 3,35 | 1,83 | 0,31 | 1,76 | 3,72 |
| ППП | 34 | 6,43 | 5,46 | 7,39 | 5,81 | 4,890000 | 2 | 218,47 | 2,69 | 12,99 | 7,61 | 2,76 | 0,47 | 1,08 | 0,37 |
2. Закон распределения данных,точечные оценки параметров
Законом распределением случайной величины называют соответствие между возможными значениями и их вероятностями.
Точечное оценивание - это вид статистического оценивания, при котором значение неизвестного параметра q приближается отдельным числом.
Суть точечного оценивания в том, что для τ(q) строится одна статистика t(x) = τ, которая принимается за оценку τ(q), т.е. t(x) = τ.
«Хорошей» оценкой является такая оценка, которая наиболее близка к истинному значению τ(q), т.е. когда ее значения в каком-то смысле сконцентрированы вокруг истинного значения τ(q) [6].
Задача точечного оценивания
Исследуется случайная величина X, распределение которой относится к параметрическому множеству Fq(x), где q (q1,..., qk) – неизвестный k-мерный параметр.
Имеется выборка наблюденных значений случайной величины Fq(x):t = t(q) oбъема выборки n. Требуется построить точечную оценку (статистику) для данной функции t = t(q) и исследовать качество данной оценки.
Cвойства точечных оценок t=t(x)
a) Несмещенность: Et(x) = t(q) (EX – математическое ожидание случайной величины Fn(x)) или асимптотическая несмещенность Et(x) ¾¾¾®t(q), при n®¥ [2].
б) Состоятельность:Одно из самых очевидных требований к точечной оценке заключается в том, чтобы можно было ожидать достаточно хорошего приближения к истинному значению параметра при достаточно больших значениях объема выборки n. Это означает, что оценка t(x) должна сходиться к истинному значению t(q) при n®¥. Это свойство оценки и называется состоятельностью. Поскольку речь идет о случайных величинах, для которых имеются разные виды сходимости, то и данное свойство может быть точно сформулировано по-разному:
- если t(x) сходится к истинному значению t(q) с вероятностью 1 (почти наверное), то тогда оценка называется сильно состоятельной;
- если имеет место сходимость по вероятности, то тогда оценка называется слабо состоятельной.
Условие состоятельности является практически обязательным для всех используемых на практике оценок. Несостоятельные оценки используются крайне редко [7].
в) Эффективность несмещенной оценки характеризуется дисперсией Dt(x) и используется для сравнения качества несмещенных оценок.
Одновременное выполнение этих желательных свойств не всегда возможно, поэтому представление о «хорошей» оценке зависит от цели и возможностей исследования, определяющих приоритетные свойства оценки. Так, для малых выборок часто важна несмещенность оценки, а для больших – асимптотическая несмещенность и состоятельность. А иногда, сознательно отказываясь от одних свойств оценок, добиваются выполнения других, более важных с точки зрения исследования свойств [7].
Интервальная оценка среднего
Интервальное оценивание — один из видов статистического оценивания, предполагающий построение интервала, в котором с некоторой вероятностью находится истинное значение оцениваемого параметра.
Предположим, что x= x1,...,xn – выборка объёма n наблюдений над случайной величиной Х, распределение которой относится к параметрическому семейству Fθ(х), где θ = (θ1,…, θк) и θ Î Θ (Θ − параметрическое множество). Требуется оценить некоторую функцию τ = τ(θ). Доверительное оценивание τ означает нахождение k-мерной области, заключающей неизвестное значение функции τ с заданной доверительной вероятностью γ. Искомое доверительное множество становится доверительным интервалом, и задача состоит в построении двух статистик t1 = t1(x) и t2 = t2 (x) (концов доверительного интервала J = (t1,t2), заключающего в себе неизвестное значение параметра θ с заданной доверительной вероятностью γ: γ = P (t1<θ<t2).
При доверительном оценивании заданное значение γ (обычно близкое к единице) означает надёжность оценивания τ(θ) с точностью, определяемой размером доверительной области. При построении доверительного интервала для параметра θ его длина – точность оценивания, а γ – заданная надежность. Поэтому желательно строить кратчайший доверительный интервал, соответствующий наибольшей точности при данном γ.
Общий приём при нахождении доверительного интервала состоит в построении центральной статистики Z = Z(θ), т.е. такой статистики, распределение которой не зависит от неизвестного параметра θ. Если Z(θ) непрерывна и монотонна по θ, то это обеспечивает однозначную эквивалентность событий {t1* < Z < t2*} и {t1 < θ <t2*}. Тогда, если удалось найти t1* = t1*(θ) и t2* = t2*(θ) − нижнюю и верхнюю доверительные границы, то решая неравенство t1* < Z < t2* относительно θ, находим значения t1 и t2 − искомые границы доверительного интервала для неизвестного параметра θ [7].
Дисперсионный анализ
Дисперсионный анализ — метод в математической статистике, направленный на поиск зависимостей в экспериментальных данных путём исследования значимости различий в средних значениях. В отличие от t-критерия, позволяет сравнивать средние значения трёх и более групп. Разработан Р. Фишером для анализа результатов экспериментальных исследований.
Суть дисперсионного анализа сводится к изучению влияния одной или нескольких независимых переменных, обычно именуемых факторами, на зависимую переменную. Зависимые переменные представлены значениями абсолютных шкал (шкала отношений). Независимые переменные являются номинативными (шкала наименований), то есть отражают групповую принадлежность, и могут иметь две или более градации (или уровня). Градации, соответствующие независимым выборкам объектов, называются межгрупповыми, а градации, соответствующие зависимым выборкам, — внутригрупповыми.
В зависимости от типа и количества переменных различают:
- однофакторный и многофакторный дисперсионный анализ (одна или несколько независимых переменных);
- одномерный и многомерный дисперсионный анализ (одна или несколько зависимых переменных);
- дисперсионный анализ с повторными измерениями (для зависимых выборок);
- дисперсионный анализ с постоянными факторами, случайными факторами, и смешанные модели с факторами обоих типов;
Однофакторный дисперсионный анализ. Простейшим случаем дисперсионного анализа является одномерный однофакторный анализ для двух или нескольких независимых групп, когда все группы объединены по одному признаку. В ходе анализа проверяется нулевая гипотеза о равенстве средних. При анализе двух групп дисперсионный анализ тождественен двухвыборочному t-критерию Стьюдента для независимых выборок, и величина F-статистики равна квадрату соответствующей t-статистики.
Для подтверждения положения о равенстве дисперсий обычно применяется критерий Ливена (Levene's test). В случае отвержения гипотезы о равенстве дисперсий основной анализ неприменим. Если дисперсии равны, то для оценки соотношения межгрупповой и внутригрупповой изменчивости применяется F-критерий Фишера:

Если F-статистика превышает критическое значение, то нулевая гипотеза не может быть принята (отвергается) и делается вывод о неравенстве средних. При анализе средних двух групп результаты могут быть интерпретированы непосредственно после применения критерия Фишера.
При наличии трёх и более групп требуется попарное сравнение средних для выявления статистически значимых отличий между ними. Априорный анализ включает метод контрастов, при котором межгрупповая сумма квадратов дробится на суммы квадратов отдельных контрастов:

где, Ψ есть контраст между средними двух групп, и затем при помощи критерия Фишера проверяется соотношение среднего квадрата для каждого контраста к внутригрупповому среднему квадрату:

Апостериорный анализ включает post-hoc t-критерии по методам Бонферрони или Шеффе, а также сравнение разностей средних по методу Тьюки. Особенностью post-hoc-тестов является использование внутригруппового среднего квадрата  для оценки любых пар средних. Тесты по методам Бонферрони и Шеффе являются наиболее консервативными, так как они используют наименьшую критическую область при заданном уровне значимости α.
для оценки любых пар средних. Тесты по методам Бонферрони и Шеффе являются наиболее консервативными, так как они используют наименьшую критическую область при заданном уровне значимости α.
Помимо оценки средних дисперсионный анализ включает определение коэффициента детерминации R2, показывающего, какую долю общей изменчивости объясняет данный фактор:

Двухфакторный дисперсионный анализ позволяет исследовать воздействие на случайную величину двух факторов. Он допускает много вариантов в зависимости от целей исследования и исходных данных и представляет собой уже достаточно сложную процедуру.
В каждой ячейке может быть рассчитана групповая средняя и изменчивость в виде суммы центрированных квадратов:
 ;
; 
Общая средняя для всего вариационного ряда и сумма квадратов отклонений индивидуальных значений от общей средней или общая изменчивость :
 ,
, 
Внутригрупповая изменчивость (точнее изменчивость внутри ячеек) в двухфакторном дисперсионном анализе рассматривается как остаточная не учтенная факторами изменчивость:

Для оценки внутригрупповой дисперсии число степеней свободы рассчитывается исходя из того, что для каждой ячейки это число равно  . Тогда число степеней свободы для всех ячеек:
. Тогда число степеней свободы для всех ячеек:
 ;
;  ;
; 
Изменчивость, связанная с воздействием обоих факторов вместе, может быть рассчитана как изменчивость между ячейками или как сумма квадратов отклонений средних значений в ячейках от общей средней, умноженная на количество наблюдений в каждой конкретной ячейке. Число степеней свободы для оценки межгрупповой дисперсии (группы - ячейки) будет равно числу ячеек без одной.
 ,
, 
Изменчивость связанная с воздействием первого фактора представляет собой в табличной модели изменчивость между строками таблицы, то есть сумму квадратов отклонений средних значений строк (градаций первого фактора) от общей средней. При этом каждый центрированный квадрат должен быть умножен на количество наблюдений в строке. Количество наблюдений в строке, средняя групповая для строки, межгрупповая изменчивость и оценка межстроковой дисперсии рассчитываются по формулам:
 ;
;  ;
;  ;
; 
Изменчивость, связанная с воздействием второго фактора, представляет собой сумму квадратов отклонений средних значений столбцов от общего среднего. Каждый центрированный квадрат должен быть умножен на количество наблюдений в столбце. Формулы для расчета количества наблюдений в столбце, средней групповой для столбца, межгрупповой (группы - столбцы) изменчивости и оценки дисперсии:
 ;
;  ;
;  ;
;  .
.
Сумма межгрупповой изменчивости по строкам, межгрупповой изменчивости по столбцам и внутригрупповой изменчивости по ячейкам не равна общей изменчивости.
 ;
;
Разность  рассматривается как изменчивость, связанная с взаимодействием факторов. Расчет оценки дисперсии
рассматривается как изменчивость, связанная с взаимодействием факторов. Расчет оценки дисперсии  производится для числа степеней свободы (p - 1)(q - 1):
производится для числа степеней свободы (p - 1)(q - 1): 
Изменчивость, связанная с взаимодействием факторов, отражает степень коррелированности этих факторов. При расчете F-критерия для оценки значимости факторов в знаменателе всегда располагается оценка внутривыборочной (неучтенной и случайной) дисперсии  с числом степеней свободы (n – p,q). B числителе располагается оценка дисперсии соответствующего фактора. Тогда:
с числом степеней свободы (n – p,q). B числителе располагается оценка дисперсии соответствующего фактора. Тогда:
 ; при числе степеней свободы числителя ( p - 1 ),
; при числе степеней свободы числителя ( p - 1 ),
 ; при числе степеней свободы числителя ( q - 1 ),
; при числе степеней свободы числителя ( q - 1 ),
 ; при числе степеней свободы числителя (p-1)(q-1),
; при числе степеней свободы числителя (p-1)(q-1),
где F1, F2, F12 - критерии Фишера для оценки значимости, соответственно, первого фактора, второго фактора и взаимодействия первого и второго факторов. Нулевые гипотезы о равенстве факториальных и случайной дисперсий отвергаются, если значение соответствующего F- критерия превысит его критическое значение для заданного уровня значимости и числа степеней свободы.
Дата добавления: 2018-06-27; просмотров: 407; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!