Проведение вычислительных экспериментов и анализ результатов
После написания программы в системе Matlab были проведены вычислительные эксперименты.Также для применения дополнительного сжатия без потерь алгоритмом RLE был использован язык Python. В качестве исходных данных были взяты6 файлов формата .wav. Файлы подбирались таким образом, чтобы речь имела разный характер. В частности, пять файловсодержали в себе голосовую запись, а в одном файле (speech3.wav) был записан короткий фрагмент концерта с исполнением классики.
Пример графика с изображением участков с речевой активностью и участков пауз, полученный в ходе работы алгоритма распознавания участков пауз, приведён ниже (рис. 11).

Рис.11. Участки с речевой активностью и участки пауз сигнала, записанного в файле speech3.wav
Можно заметить, что данный алгоритм относится к числу детекторов речевой активности, распознающих даже небольшие участки пауз. Поэтому в реализованном методе слишком короткие участки пауз (длиной менее 360 отсчётов) сжимаются «основным» алгоритмом с целью улучшения качества синтезированной речи.
Рассмотрим первый вариант сжатия на основе рассматриваемого подхода: участки пауз сжимаются алгоритмом LPC-10, а участки речевой активностью – алгоритмом CELP9.6 kbps.Сначала исходные файлы сжимаются одним алгоритмом–CELP 9.6 kbps, а потом–первым вариантом исследуемого метода сжатия.Ниже приведены результаты вычислительного эксперимента – графики с исходным сигналом и синтезированным (полученном на выходе) в двух формах. На первой графики изображены раздельно, на второй – совместно (наложением двух сигналов). В качестве примера берётся файл speech3.wav.
|
|
|
Стоит отметить, что на участках пауз вокализованная речь практически полностью отсутствует. В связи с этим можно убрать из распределения битов в алгоритме LPC-10 7 битов, кодирующих период основного тона Pitch, с целью улучшения потенциального эффекта от применения разработанного метода. Таким образом, каждый кадр будет кодироваться 41 битом вместо 48 битов в исходном варианте распределения битов в кодировании параметров LPC-10(см. Глава 2 п. 2.1.1).
Поскольку алгоритм сжатия RLE относится к алгоритмам сжатия данных без потерь, то после декодирования синтезированная исследуемым методом речь по качеству ничем не будет отличаться от той, которая может быть получена только применением исследуемого метода, т. е. без применения дополнительного сжатия алгоритмом RLE.
На рис. 12, 13 изображены графикисигналов при сжатии всего исходного речевого сигнала одним алгоритмом CELP9.6 kbps.

Рис.12. Графики исходного сигнала speech3.wavи CELP 9.6 kbpsсинтезированного
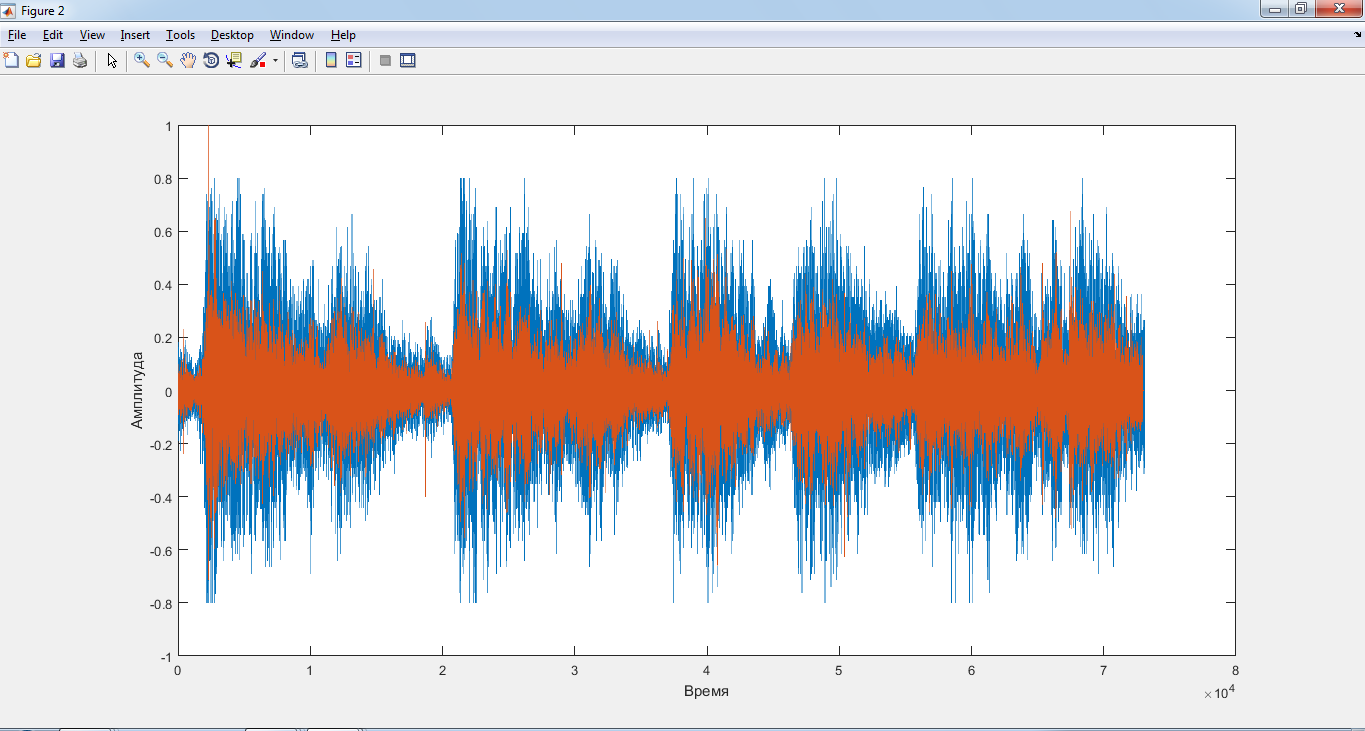
Рис.13. Графики исходного сигнала speech3.wavи CELP 9.6 kbpsсинтезированного (совместно)
|
|
|
На рис. 14,15изображены графики сигналов при сжатииисследуемым методом.

Рис.14. Графики исходного сигнала speech3.wavи синтезированного с помощью метода

Рис.15. Графики исходного сигнала speech3.wavи синтезированного с помощью метода (совместно)
После того, как в результате применения метода был получен сжатый файл, к последнему применяются два варианта алгоритма сжатия данных RLE с целью исследования потенциального эффекта от такого подхода.
Ниже приведена таблица результатов вычислительного эксперимента по сжатию исходных файлов, содержащих речевые сигналы.
Таблица 6.
Таблица результатов вычислительного эксперимента по сжатию исходных файлов первым вариантом метода.
| speech1 | speech2 | speech3 | speech4 | speech5 | speech6 | |
| Размер исходного файла .wav в байтах | 93 364 | 96 346 | 146 270 | 68 444 | 113 244 | 94 044 |
| Размер сжатого файла .celp96 в байтах | 6 984 | 7 201 | 10 945 | 5 113 | 8 473 | 7 033 |
| Размер сжатого файла .cmpr в байтах | 5 286 | 5 233 | 6 994 | 3 193 | 5 851 | 5 348 |
| Размер сжатого файла .rle в байтах (RLE1) | 10 318 | 10 158 | 13 898 | 6 268 | 11 484 | 10 488 |
| Размер сжатого файла .rle в байтах (RLE2) | 5 385 | 5 342 | 7 147 | 3 259 | 5 967 | 5 455 |
|
|
|
Ниже приведён график сравнения результатов вычислительного эксперимента, построенный на основании полученных данных (рис. 16).
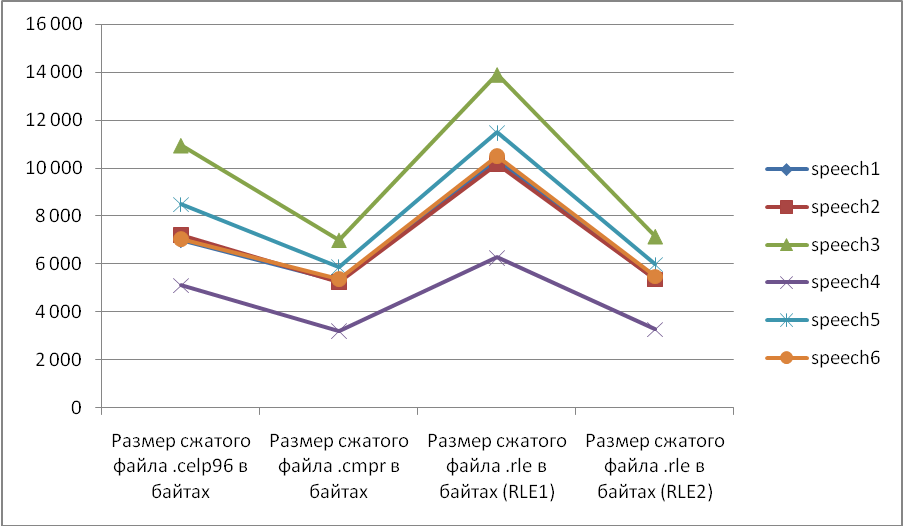
Рис.16. Сравнение результатов вычислительного эксперимента
Рассмотрим второй вариант исследуемого метода: участки пауз сжимаются алгоритмом CELP9.6 kbps, а участки речевой активностью –алгоритмом CELP16 kbps. Сначала исходные файлы сжимаются одним алгоритмом–CELP 16 kbps, а потом –вторым вариантом исследуемого метода сжатия.Ниже приведены результаты вычислительного эксперимента – графики с исходным сигналом и синтезированным (полученном на выходе) в двух формах. На первой графики изображены раздельно, на второй – совместно (наложением двух сигналов). В качестве примера берётся файл speech3.wav.
На рис. 17, 18 изображены графики сигналов при сжатии всего исходного речевого сигнала одним алгоритмом CELP16 kbps.

Рис.17. Графики исходного сигнала speech3.wavи CELP 16kbpsсинтезированного

Рис.18. Графики исходного сигнала speech3.wavи CELP 16kbpsсинтезированного (совместно)
На рис. 19,20изображены графики сигналов при сжатии исследуемым методом.
|
|
|

Рис.19. Графики исходного сигнала speech3.wavи синтезированного с помощью метода

Рис.20. Графики исходного сигнала speech3.wavи синтезированного с помощью метода (совместно)
После того, как в результате применения метода был получен сжатый файл, к последнему применяются два варианта алгоритма сжатия данных RLE с целью исследования потенциального эффекта от такого подхода.
Ниже приведена таблица результатов вычислительного эксперимента по сжатию исходных файлов, содержащих речевые сигналы.
Таблица 7.
Таблица результатов вычислительного эксперимента по сжатию исходных файлов вторым вариантом метода.
| speech1 | speech2 | speech3 | speech4 | speech5 | speech6 | |
| Размер исходного файла .wav в байтах | 93 364 | 96 346 | 146 270 | 68 444 | 113 244 | 94 044 |
| Размер сжатого файла .celp16 в байтах | 11 641 | 12 001 | 18 241 | 8 521 | 14 120 | 11 720 |
| Размер сжатого файла .cmpr в байтах | 10 248 | 10 385 | 14 961 | 6 937 | 11 977 | 10 344 |
| Размер сжатого файла .rle в байтах (RLE1) | 19 910 | 20 248 | 29 732 | 13 674 | 23 470 | 20 302 |
| Размер сжатого файла .rle в байтах (RLE2) | 10 379 | 10 537 | 15 290 | 7 064 | 12 136 | 10 498 |
Ниже приведён график сравнения результатов вычислительного эксперимента, построенный на основании полученных данных (рис. 21).

Рис.21. Сравнение результатов вычислительного эксперимента
Очевидно, что чем больше файл с речевым сигналом, тем лучше его сжатие одним алгоритмом CELP9.6 kbps (16 kbps).При сжатии файла с речевым сигналом одним алгоритмом CELP16 kbps синтезированный сигнал будет очень близок к исходному по звучанию. Такое качество можно объяснить тем, что используется верхнее значение диапазона скоростей, при котором алгоритм CELP применяется эффективно (см. Глава 2, п. 2.1.2). Кроме того, это также связано с тем, что каждый кадр кодируется достаточно большим числом бит.
Использование первого варианта исследуемого метода даёт бо?льшую степень сжатия по сравнению с использованием второго варианта этого метода. Но применение второго варианта данного метода в свою очередь обеспечивает высокое качество звучания полученного речевого сигнала, включая как речь, так и фоновый шум.
Исходя из этого, выбор варианта реализованного метода необходимо осуществлять в зависимости от ситуации. Если важно увеличить степень сжатия сигнала, и при этом качество звучания участков пауз не является важным, то лучше использовать первый вариант метода. Если важно сохранить высокое качество звучание всего сигнала и участков пауз также, то лучше применить второй вариант метода.
Дополнительное применение первого варианта алгоритма RLE даёт значительный обратный эффект (размер файла .cmprувеличивается почти в 2 раза), поэтому его использование здесь крайне нецелесообразно. Дополнительное применение второго варианта алгоритма RLE также даёт обратный эффект, правда, уже незначительный (размер файла .cmprувеличивается в 0,98 раз). Это приблизительно соответствует оценкам для худшего случая работы обоих вариантов алгоритма RLE.
Как следствие, получаем тот факт, что в файле .cmpr, сжатом исследуемым методом, практически отсутствуют последовательности повторяющихся байтов, поскольку именно это и обуславливает худший случай работы данного алгоритма.
Поскольку второй вариант алгоритма сжатия данных RLE работает лучше, чем первый вариант того же алгоритма, можно предположить, что применение других алгоритмов сжатия без потерь (или их комбинации) позволит улучшить результат, полученный исследуемым методом.
В качестве возможного способа улучшения работы алгоритма сжатияRLE в данном методе можно применить последовательность преобразований, например, преобразование Барроуза-Уилера.
Проанализируем эффект от такого подхода. Тогда последовательность использования алгоритмов будет выглядеть так:
celp96/celp16 -> сжатие методом ->преобразование Барроуза-Уиллера -> ->RLE1/RLE2.
Для реализации алгоритмовпреобразования был выбран язык Python. Файл, сжатый таким образом, будем сохранять с расширением .mrle.Обозначим вариант алгоритма сжатия с использованием RLE1 как MRLE1, а с использованием RLE2 –MRLE2 соответственно.
Сначала будем использовать первый вариант исследуемого метода. Ниже приведена таблица результатов вычислительного эксперимента по сжатию исходных файлов, содержащих речевые сигналы, с использование данного подхода.
Таблица 8.
Таблица результатов вычислительного эксперимента по сжатию исходных файлов первым вариантом метода.
| speech1 | speech2 | speech3 | speech4 | speech5 | speech6 | |
| Размер сжатого файла .cmpr в байтах | 5 286 | 5 233 | 6 994 | 3 193 | 5 851 | 5 348 |
| Размер сжатого файла .rle в байтах (RLE1) | 10 318 | 10 158 | 13 898 | 6 268 | 11 484 | 10 488 |
| Размер сжатого файла .rle в байтах (RLE2) | 5 385 | 5 342 | 7 147 | 3 259 | 5 967 | 5 455 |
| Размер сжатого файла .mrle в байтах (MRLE1) | 10 006 | 9 782 | 13 574 | 6 030 | 11 182 | 10 230 |
| Размер сжатого файла .mrle в байтах (MRLE2) | 5 525 | 5 482 | 7 191 | 3 323 | 6 070 | 5 545 |
Ниже приведён график сравнения результатов вычислительного эксперимента, построенный на основании полученных данных (рис. 22).

Рис.22. Сравнение результатов вычислительного эксперимента
Теперь будем использовать второй вариант исследуемого метода. Ниже приведена таблица результатов вычислительного эксперимента по сжатию исходных файлов, содержащих речевые сигналы, с использование данного подхода.
Таблица 9.
Таблица результатов вычислительного эксперимента по сжатию исходных файлов вторым вариантом метода.
| speech1 | speech2 | speech3 | speech4 | speech5 | speech6 | |
| Размер сжатого файла .cmpr в байтах | 10 248 | 10 385 | 14 961 | 6 937 | 11 977 | 10 344 |
| Размер сжатого файла .rle в байтах (RLE1) | 19 910 | 20 248 | 29 732 | 13 674 | 23 470 | 20 302 |
| Размер сжатого файла .rle в байтах (RLE2) | 10 379 | 10 537 | 15 290 | 7 064 | 12 136 | 10 498 |
| Размер сжатого файла .mrle в байтах (MRLE1) | 19 446 | 19 650 | 29 048 | 13 198 | 22 640 | 19 698 |
| Размер сжатого файла .mrle в байтах (MRLE2) | 10572 | 10 730 | 15 360 | 7 155 | 12 419 | 10 688 |
Ниже приведён график сравнения результатов вычислительного эксперимента, построенный на основании полученных данных (рис. 23).

Рис.23. Сравнение результатов вычислительного эксперимента
По результатам вычислительного эксперимента видно, что в данном случае использование вышеуказанногопреобразования данных перед сжатием алгоритмом RLE не даёт существенных преимуществ. Степень сжатия алгоритмом RLE1 несколько увеличилась (в среднем до 0,53), а степень сжатия алгоритмом RLE2 уменьшилась (в среднем до 0,97).
Рассмотрим теперь влияние скорости произносимой речи на эффект от сжатия исследуемым методом, а также на эффект от дополнительного сжатия алгоритмом RLE. Теоретически общая продолжительность участков пауз должна повлиять на степень сжатия метода.
На сайтах обучения английскому языку можно найти аудиозаписи, в которых некоторые слова произносятся подряд несколько раз, но с разной скоростью – сначала медленно, а потом быстро.Аналогичным образом автором были записаны два аудиофайла формата .wav, в которых по-английски словами произносились числа от 1 до 10. На первой записи (one-ten_slowly.wav) слова произносятся медленно, на второй (one-ten_fast.wav) – быстрее. Далее был проведён вычислительный эксперимент по аналогии с описанным выше.
Ниже приведены графики, полученные в результате вычислительного эксперимента с использованием первого варианта метода(рис. 24-27).В качестве примера для изображения графиков сигналов берётся файл one-ten_slowly.wav.
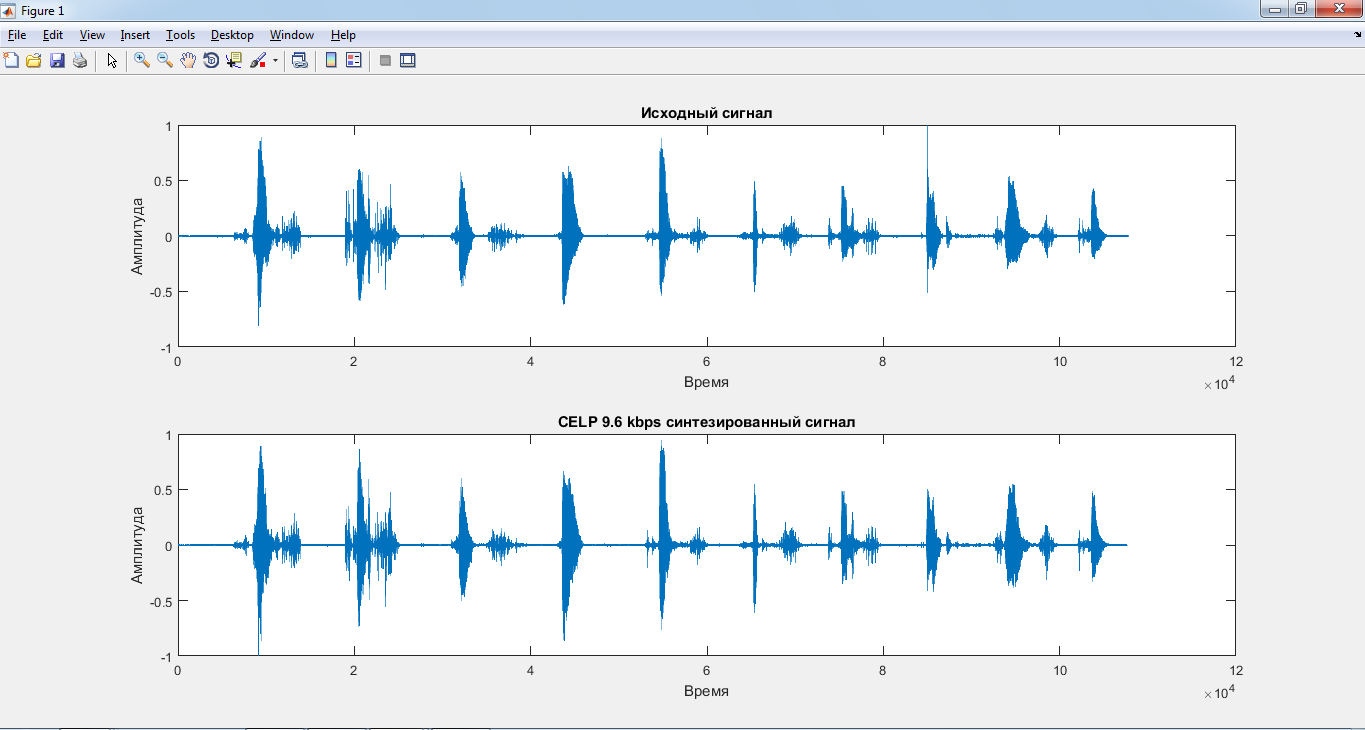
Рис.24. Графики исходного сигнала one-ten_slowly.wavи CELP9.6kbpsсинтезированного

Рис.25. Графики исходного сигнала one-ten_slowly.wavи CELP9.6kbpsсинтезированного (совместно)

Рис.26. Графики исходного сигнала one-ten_slowly.wavи синтезированного с помощью разработанного метода

Рис.27. Графики исходного сигнала one-ten_slowly.wavи синтезированного с помощью разработанного метода (совместно)
После того, как в результате применения метода был получен сжатый файл, к последнему применяются два варианта алгоритма сжатия данных RLE с целью исследования потенциального эффекта от такого подхода.
Ниже приведена таблица результатов вычислительного эксперимента по сжатию исходных файлов, содержащих речевые сигналы.
Таблица 10.
Таблица результатов вычислительного эксперимента по сжатию исходных файлов первым вариантом метода.
| one-ten_slowly | one-ten_fast | |
| Размер исходного файла .wav в байтах | 215 644 | 151 644 |
| Размер сжатого файла .celp96 в байтах | 16 152 | 11 353 |
| Размер сжатого файла .cmpr в байтах | 9 624 | 7 000 |
| Размер сжатого файла .rle вбайтах (RLE1) | 18 976 | 13 752 |
| Размер сжатого файла .rle вбайтах (RLE2) | 9 822 | 7 146 |
Ниже приведён график сравнения результатов вычислительного эксперимента, построенный на основании полученных данных (рис. 28).

Рис.28. Сравнение результатов вычислительного эксперимента
Далее приведены графики, полученные в результате вычислительного эксперимента с использованием второго варианта метода (рис. 29-32).В качестве примера для изображения графиков сигналов берётся файл one-ten_fast.wav.

Рис.29. Графики исходного сигнала one-ten_fast.wavи CELP16kbpsсинтезированного

Рис.30. Графики исходного сигнала one-ten_fast.wavи CELP16kbpsсинтезированного (совместно)

Рис.31. Графики исходного сигнала one-ten_fast.wavи синтезированного с помощью разработанного метода

Рис.32. Графики исходного сигнала one-ten_fast.wavи синтезированного с помощью разработанного метода (совместно)
После того, как в результате применения метода был получен сжатый файл, к последнему применяются два варианта алгоритма сжатия данных RLE с целью исследования потенциального эффекта от такого подхода.
Ниже приведена таблица результатов вычислительного эксперимента по сжатию исходных файлов, содержащих речевые сигналы.
Таблица 11.
Таблица результатов вычислительного эксперимента по сжатию исходных файлов вторым вариантом метода.
| one-ten_slowly | one-ten_fast | |
| Размер исходного файла .wav в байтах | 215 644 | 151 644 |
| Размер сжатого файла .celp16 в байтах | 26 921 | 18 920 |
| Размер сжатого файла .cmpr в байтах | 21 465 | 15 305 |
| Размер сжатого файла .rle вбайтах (RLE1) | 42 290 | 30 058 |
| Размер сжатого файла .rle вбайтах (RLE2) | 21 820 | 15 532 |
Ниже приведён график сравнения результатов вычислительного эксперимента, построенный на основании полученных данных (рис. 33).

Рис.33. Сравнение результатов вычислительного эксперимента
Можно заметить, что речевой сигнал, содержащий более размеренную речь, сжимается лучше исследуемым методом, чем сигнал, содержащий более быструю речь. Из четырёх случаев лучший случай показал увеличение степени сжатия речевого сигнала разработанным методом на 40,42% (сжатие файла one-ten_slowly.wav первым вариантом метода), худший – увеличение степени сжатия на 19,11% (сжатие файла one-ten_fast.wav вторым вариантом метода) соответственно. Использование первого варианта метода даёт лучшее увеличение степени сжатия по сравнению с использованием второго варианта метода. Поскольку конкретно в данной ситуации качество пауз в синтезированном сигнале не играет особой роли, а речь, синтезированная 9.6 kbpsвокодером, уже показывает достаточное качество звучания, то в подобных случаях лучшеи целесообразнее применять первыйвариантисследуемогометода.
Дополнительное применение обоих вариантов алгоритма RLE даёт обратный эффект, аналогичный случаям, описанным выше. Поэтому применениеданного алгоритма сжатия без потерь в таких случаях также не рекомендуется.
По результатам проведённых вычислительных экспериментов видно, что:
· При использовании первого варианта исследуемого метода степень сжатия сигнала улучшается в среднем на 32% (в лучшем и худшем случаях – на 40% и на 24% соответственно);
· При применении второго варианта исследуемого метода степень сжатия сигнала улучшается в среднем на 16% (в лучшем и худшем случаях – на 20% и на 12% соответственно);
· При дополнительном применении к полученному в результате использования первого варианта метода файлу .cmprалгоритма сжатия RLE1 размер данного файла изменяется в среднем в 0,51 раз (в лучшем и худшем случаях – в 0,52 раз и в 0,5 раз соответственно), что приблизительно соответствует оценке для худшего случая для этого алгоритма;
· При дополнительном применении к полученному в результате использования второго варианта метода файлу .cmprалгоритма сжатия RLE1 размер данного файла изменяется в среднем в 0,51 раз (в лучшем и худшем случаях – в 0,51 раз и в 0,5 раз соответственно), что приблизительно соответствует оценке для худшего случая для этого алгоритма;
· При дополнительном применении к полученному в результате использования первого варианта метода файлу .cmprалгоритма сжатия RLE2 размер данного файла изменяется в среднем в 0,98 раз (в лучшем и худшем случаях – в 0,98 раз), что приблизительно соответствует оценке для худшего случая для этого алгоритма;
· При дополнительном применении к полученному в результате использования второго варианта метода файлу .cmprалгоритма сжатия RLE2 размер данного файла изменяется в среднем в 0,99 раз (в лучшем и худшем случаях – в 0,99 раз и в 0,98 раз соответственно), что приблизительно соответствует оценке для худшего случая для этого алгоритма.
Таким образом, исследуемый метод показал достаточно неплохой эффект. Использование первого варианта метода обеспечивает большее сжатие сигнала, но при этом использование второго даёт лучшее качество звучания как участков пауз, так и всей речи в целом. Рекомендуется использование первого варианта метода в тех ситуациях, где сохранение качества звучания участков пауз не является существенной целью. Дополнительное применение алгоритма сжатия без потерь RLE к полученному в результате работы метода файлу не рекомендуется.
Заключение
В данной работе были рассмотрены различные алгоритмы обработки речевых сигналов, в частности алгоритмы сжатия и распознавания участков пауз. Алгоритм линейного предсказания лежит в основе современных алгоритмов сжатия речевых сигналов[13]. В последних разработках алгоритмов сжатия речи нового поколения применяют алгоритм речеобразования CELP [14].Данный алгоритм входит в структуру стандарта MPEG-4, входит в набор кодеков MPEG-4 Audio [15], активно используется в протоколах технологии VoIP[16].Также был исследован методсжатия речевых сигналов, основанный на разделении сжатия активной речи и пауз.
Также был проведен сравнительный анализ алгоритмов сжатия речевых сигналов. Сравнивались результаты, полученные алгоритмом сжатия CELP, с результатами алгоритмов, основанных на раздельном сжатии участков пауз и активной речи.
Для реализации алгоритмов сжатия речевых сигналов была выбрана система Matlab. Для реализации алгоритма сжатия данных RLE был использован язык Python.
В ходе данной работы были получены следующие результаты:
· Был реализован и исследован метод сжатия, основанный на разделении сжатия активной речи и пауз;
· При применении первого варианта исследуемогометода получается улучшить степень сжатия сигнала в среднем на 32%, а при применении второго варианта данного метода – на 16%;
· При дополнительном применении к полученному в результате использования исследуемого метода файлу .cmprалгоритма сжатия RLE1 размер данного файла изменяется в среднем в 0,51 раз;
· При дополнительном применении к полученному в результате использования исследуемого метода файлу .cmprалгоритма сжатия RLE2 размер данного файла изменяется в среднем в 0,98 раз;
· При использованиипреобразования Барроуза-Уиллера перед сжатием алгоритмом RLEстепень сжатия алгоритмом RLE1 увеличивается в среднем до 0,53, а степень сжатия алгоритмом RLE2 уменьшается в среднем до 0,97;
· Выявлено, какие алгоритмы лучше подходят для использования в реализованном методе для определённых целей. Были даны соответствующие рекомендации по применению реализованного метода .
В качестве исходных данных для проведённого исследования были использованыреальные звуковые записи, что является необходимым условием актуальности полученных результатов.
В процессе сжатия речевого сигнала происходит потеря качества записи. В данной работе был дан сравнительный анализ качества звучания записей, сжатых различными вариантами исследуемого метода. Качество звучания проверялось в результате прослушивания декодированной записи. Но такой способ проверки носит достаточно субъективный характер. Каждый может оценить качество звучания по-своему.
Проблема заключается в следующем: как доказать, что определённый вариант исследуемого метода даёт качество звучания декодированной записи лучше, чем какой-либо другой? Для этого необходимо использовать математическое обоснование, разработать метод оценки.
Поскольку записываемый сигнал подвергается процессу дискретизации, можно заметить, что каждый отсчёт сигнала декодированной записи был восстановлен с некоторой ошибкой. Как следствие, высокое качество звучания полученной записи будет в том случае, если для каждого отсчёта данная ошибка будет минимальной. В данной ситуации можно воспользоваться, например, методом наименьших квадратов. Но лучше применять этот метод не на всём сигнале, а на каждом кадре отдельно, а далее каким-либо образом оценить ошибку для всего сигнала. Изучение данного вопроса может стать объектом дальнейших исследований и логическим продолжением проведённого в данной работе исследования.
Таким образом, были решены и рассмотрены все поставленные задачи: исследовать существующие алгоритмы обработки речевых сигналов, реализовать и исследоватьметод для улучшения степени сжатия сигнала, провести вычислительные эксперименты, провести анализ полученных результатов, оценить эффект от использования данного метода и дать соответствующие рекомендации по его применению.
Список литературы
1. Методы и алгоритмы детектированияактивности речи. – Электрон.дан. – Режим доступа: http://www.dspa.ru/articles/year2013/jour13_1/art13_1_10.pdf – Загл. с экрана.
2. Kondoz A.M. Digital Speech. Coding for Low Bit Rate Communication Systems. – John Wiley & Sons, Ltd. 2004.– 442 p.
3. Обзор методов и алгоритмов сжатия речевой информации в системах цифровой радиосвязи. – Электрон.дан. – Режим доступа: https://cyberleninka.ru/article/v/obzor-metodov-i-algoritmov-szhatiya-rechevoy-informatsii-v-sistemah-tsifrovoy-radiosvyazi– Загл. с экрана.
4. Конспект лекций учебной дисциплины Модуляция в системах цифрового радиовещания. – Электрон.дан. – Режим доступа: http://mwpt.kai.ru/files/2014/12/МСЦР-Лекции.pdf– Загл. с экрана.
5. Лабораторная работа№1. Кодирование речевых сигналов на основе линейного предсказания. – Электрон.дан. – Режим доступа: http://k14.spb.ru/cm/uploads/109/006– Загл. с экрана.
6. Ахмад Х. М., Жирков В. Ф. Введение в цифровую обработку речевых сигналов : учеб.пособие / Х. М. Ахмад, В. Ф. Жирков ; Владим. гос. ун-т. – Владимир :Изд-во Владим. гос. ун-та, 2007. – 192 с.
7. L. R. Rabiner, R. W. Schafer. Introduction to DigitalSpeech Processing. – now Publishers Inc. 2007. – 213 p.
8. Speech & Audio Coding. – Электрон.дан. – Режим доступа: http://read.pudn.com/downloads92/ebook/360474/MC05.pdf – Загл. с экрана.
9. Метод кодирования речевых сигналов. – Электрон.дан. – Режим доступа: http://www.sagatelecom.ru/encyclopedia/protocol/detail.php?ID=99 – Загл. с экрана.
10. Overview of Code Excited Linear Predictive Coder. – Электрон.дан. – Режим доступа: http://ijrdet.com/files/Volume3Issue1/IJRDET_0714_28.pdf– Загл. с экрана.
11. Ватолин Д. и др. Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео. - М.: ДИАЛОГ-МИФИ, 2003. - 384 с.
12. Цифровая обработка аудио- и видеоданных. – Электрон.дан. – Режим доступа: https://libeldoc.bsuir.by/bitstream/123456789/13287/2/Petrovskii_Cifrovaya.pdf– Загл. с экрана.
13. Анализ речи на основе линейного предсказания. – Электрон.дан. – Режим доступа: https://cyberpedia.su/12x14102.html – Загл. с экрана.
14. Алгоритм речеобразования CELP. – Электрон.дан. – Режим доступа: http://www.delphiplus.org/zashchita-informatsii-v-telekommunikatsionnykh-sistemakh/algoritm-recheobrazovaniya-celp.html – Загл. с экрана.
15. Сжатие аудиоданных. Общие принципы и устройство MP3. Дмитрий Ватолин. Московский Государственный Университет CSMSUGraphics&MediaLab. – Электрон.дан. – Режим доступа: http://www.compression.ru/dv/course/compr_audio.pdf – Загл. с экрана.
16. Codetopic-excited linear predictive (CELP) coders (VoIP Protocols). – Электрон.дан. – Режим доступа: http://what-when-how.com/voip-protocols/codetopic-excited-linear-predictive-celp-coders-voip-protocols/ – Загл. с экрана.
17. LPC10 2.4kbps federal standard in speech coding. – Электрон.дан. – Режим доступа: http://slideplayer.com/slide/3275047/ – Загл. с экрана.
Дата добавления: 2018-06-27; просмотров: 794; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!