Алгоритм сжатия данных RLE (кодирование длин серий)
Данный алгоритм относится к классу алгоритмов сжатия данных без потерь. Это означает, что данные, закодированные этим алгоритмом, могут быть восстановлены однозначно с точностью до бита, т. е. исходные данные восстанавливаются полностью. Этот алгоритм не относится к категории алгоритмов сжатия речевых сигналов. Он может использоваться для сжатия любых данных, представленных в цифровой форме (изображений, документов, аудио- и видеоданных). Иным словами, он является многоцелевым.
Серией называется последовательность из нескольких повторяющихся байт. Сжатие происходит в связи с тем, что во входном файле содержатся последовательности повторяющихся байтов. Очевидно, что чем больше последовательностей повторяющихся байтов в файле, тем лучше сжатие алгоритмом RLE.В связи с этим этот алгоритм получил широкое применение для сжатия изображений. Однако, возможны ситуации, когда сжатый алгоритмом RLE файл наоборот увеличится.
Алгоритм RLE имеет различные варианты [11]. Рассмотрим более подробно следующие два.
В первом варианте алгоритма серии, состоящие из одинаковых байтов,заменяются на пары<счётчик повторений, значение>. Это позволяет уменьшить избыточность данных. В данном варианте алгоритма RLE признаком счётчика являются единицы в двух верхних битах байта, кодирующегосчётчик [11] (см. рис. 8). Остальные 6 битов выделяются непосредственно на хранение значения счётчика.
|
|
|
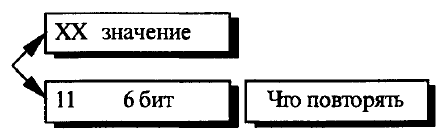
Рис.8. Кодирование серий в первом варианте алгоритма сжатия данных RLE
Степени сжатия данных для данного варианта алгоритма RLE:
· 32 – оценка для лучшего случая;
· 2 – оценка для среднего случая;
· 0,5 – оценка для худшего случая.
Этот вариант алгоритма применяют для сжатия деловой графики, а также изображений с большими областями одинакового цвета.
Во втором варианте алгоритма серии кодируются другим способом. Это позволяет добиться большей максимальной степени сжатия и меньшего увеличения файла в худшем случае. В данном варианте алгоритма RLE признаком повтора служит единица в старшем разряде кодирующего байта [11] (см. рис. 9). Остальные 7 битов выделяются непосредственно на хранение значения счётчика.

Рис.9. Кодирование серий во втором варианте алгоритма сжатия данных RLE
Степени сжатия данных для данного варианта алгоритма RLE:
· 64 – оценка для лучшего случая;
· 3 – оценка для среднего случая;
· 128/129 – оценка для худшего случая.
В тех случаях, когда длина серии превышает 127 байтов, последовательность повторов разбивается на части, в каждой из которых длина серии не превосходит 127 байтов.
Как следствие, реализация алгоритма RLEна языках более низкого уровня является достаточно нетривиальной.
|
|
|
Описание алгоритма распознавания участков пауз
Данный алгоритм распознавания участков пауз в речевом сигнале основан на сегментном соотношении сигнал/шум. Модель основывается на предположении о том, что входной зашумлённый сигнал 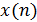 состоит из суммы двух сигналов – чистого речевого сигнала
состоит из суммы двух сигналов – чистого речевого сигнала  и аддитивного шумового сигнала
и аддитивного шумового сигнала 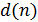 , т. е. имеет место такое представление[12]:
, т. е. имеет место такое представление[12]:
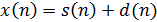 . (19)
. (19)
Применим дискретное преобразование Фурье (ДПФ) к правой и левой частям данного выражения. Получим:
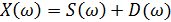 . (20)
. (20)
Выразим 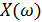 в полярной системе координат:
в полярной системе координат:
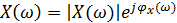 , (21)
, (21)
где 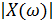 и
и 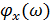 – амплитудный и фазовый спектры зашумлённого сигнала соответственно.
– амплитудный и фазовый спектры зашумлённого сигнала соответственно.
Спектр шума 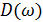 также можно выразить в терминах амплитудного и фазового спектров как
также можно выразить в терминах амплитудного и фазового спектров как 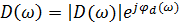 . Амплитудный спектр шума
. Амплитудный спектр шума 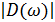 , вообще говоря, неизвестен. Но может быть заменён своим усреднённым значением, вычисленным по кадрам входного речевого сигнала, в которых отсутствует речь.
, вообще говоря, неизвестен. Но может быть заменён своим усреднённым значением, вычисленным по кадрам входного речевого сигнала, в которых отсутствует речь.
Подобным образом фазовый спектр шума 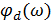 может быть заменён фазовым спектром зашумлённой речи . Отчасти это объясняется тем, что изменение фазы не влияет на разборчивость речи, а может только в некоторой степени иметь влияние на качество сигнала. Введя вышеуказанные замены, можно записать выражение для оценки спектра чистой речи:
может быть заменён фазовым спектром зашумлённой речи . Отчасти это объясняется тем, что изменение фазы не влияет на разборчивость речи, а может только в некоторой степени иметь влияние на качество сигнала. Введя вышеуказанные замены, можно записать выражение для оценки спектра чистой речи:
|
|
|
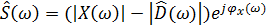 , (22)
, (22)
где 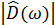 – оценка амплитудного спектра шума, определённая во время участков пауз речевого сигнала.
– оценка амплитудного спектра шума, определённая во время участков пауз речевого сигнала.
Данное уравнение даёт представление о главном принципе, лежащем в основе метода спектрального вычитания. В общей форме метод спектрального вычитания формулируется в следующем виде [12]:
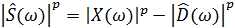 , (23)
, (23)
где p – показатель степени.
При p=1 данное выражение описывает первоначальный метод спектрального вычитания. Но в практических приложениях часто используется показатель p=2. В таком случае данное выражение будет описывать правило вычитания спектров мощности. Правая часть может иметь отрицательный знак, что является следствием неточности в оценке спектра шума. Однако при этом амплитудное значение (или мощность) не может быть отрицательным. Как следствие, необходимо дополнить данное выражение для того, чтобы оценка спектра чистой речи всегда была неотрицательной.
Обозначим
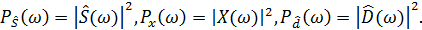 (24)
(24)
После этого модифицированное правило вычитания спектров мощности примет такой вид:
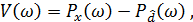 (25)
(25)
 (26)
(26)
|
|
|
В основе алгоритма распознавания участков пауз в речевом сигнале, основанном на сегментном соотношении сигнал/шум, лежит анализ энергии текущего кадра речевого сигнала и сравнение её с энергией оценки шума [12]. Кадры, содержащие участки активной речи, в среднем должны обладать большей энергией по сравнению с теми кадрами, которые содержат исключительно шум.
Данный алгоритм предусматривает использование параметра так называемого сегментного соотношения сигнал/шум:
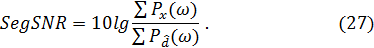
В процессе работы алгоритма рассчитывается значение 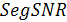 для каждого кадра, после чего выполняется сравнение данного параметра с пороговым значением
для каждого кадра, после чего выполняется сравнение данного параметра с пороговым значением 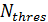 , которое определяется экспериментальным путём. Если
, которое определяется экспериментальным путём. Если 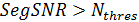 , то это свидетельствует о том, что текущий кадр речевого сигнала содержит речевую активность.
, то это свидетельствует о том, что текущий кадр речевого сигнала содержит речевую активность.
Описание исследуемого метода
Ниже приведён пример выделения в речевом сигнале участков, содержащих речевую активность, и участков пауз[1] (рис. 10).
Поскольку вокодерные системы характеризуются большой чувствительностью к фоновым шумам (см. Глава 1, п. 1.1), в момент записи речи на речевой сигнал также будет накладываться определённый шум. Как следствие, неизбежной будет передача зашумлённого речевого сигнала.
Фоновый шум может носить совершенно разный характер. Это может быть транспортный шум, шум людей на улице (за окном, за дверью), технический шум (например, шум, исходящий от функционирующего сервера) и т. д. Но в любом случае передача именно оригинального сигнала является необходимой задачей.

Рис.10. Участки с речевой активностью и участки пауз
Кончено, можно воспользоваться алгоритмами подавления шумов, после чего «вырезать» участки пауз, но тогда полученный сигнал будет отличен от записанного оригинального. Т. е. тогда будет иметь место подмена исходной информации в качественном смысле этого слова. Другое дело, когда самой целью является подавление фонового шума во входном сигнале. Но это уже задача для определённых целей, когда необходимо выполнение соответствующих условий.
Другим ещё более значимым вариантом будет ситуация, когда нам действительно важно точно сохранять оригинальность исходной записи вместе с фоновым шумом. Например, производится запись концерта, в частности с исполнением классики. Тогда в качестве фонового шума будет выступать оркестр, а в качестве непосредственной речи будет являться хор. Очевидно, что в такой ситуации в качестве участков пауз будут выступать маленькие промежутки времени, где отсутствует хоровое пение, т. к. разумеется, хор поёт не абсолютно непрерывно на протяжении всего выступления.
Поэтому в такой ситуации будет крайне важно передать ту информацию, при которой сохранялась бы оригинальность записанного сигнала для всех участков вне зависимости от того, присутствует ли речевая активность или нет.
Исследуемый метод состоит в том, чтобы сжимать исходный речевой сигнал двумя алгоритмами: одним – участки с речевой активностью, а другим – участки пауз. Представляется более целесообразным выбрать в качестве алгоритма для сжатия участков речевой активности более эффективный с точки зрения качества синтезированного сигнала, поскольку эта информация более важная, и задача в том, чтобы обеспечить лучшее качество её звучания. Для сжатия участков пауз будет использоваться другой алгоритм, с более низким качествомзвучания полученной на выходе речи.При этом участки с речевой активностью очевидно будут занимать больше памяти после сжатия по сравнению с участками пауз.
В качестве алгоритма распознавания пауз будет использован алгоритм, описанный в п. 2.3 данной главы. Что касается выбора алгоритмов для реализации самого метода непосредственно, то здесь будут рассмотрены два различных варианта с использованием алгоритмов сжатия речевых сигналов из п. 2.1 этой же главы.
В первом случае участки пауз сжимаются алгоритмом LPC-10, а участки речевой активностью – алгоритмом CELP 9.6 kbps.Во втором случае участки пауз сжимаются алгоритмом CELP 9.6 kbps, а участки речевой активности – алгоритмом CELP 16 kbps.
В результате реализации метода получается вокодер, работающий на переменной скорости, т. е.имеющий различную скорость сжатия исходного сигнала.
Реализация исследуемого метода с использованием для сжатия участков паузалгоритма LPC-10, а для участков речевой активности –алгоритм CELP16 kbpsвозможна, но не имеет смысла. Теоретически такой вариант может дать достаточно хороший эффект от сжатия, однако в синтезированном (полученном) сигнале при прослушивании качество записи на участках пауз будет крайне сильно отличаться в худшую сторону.
Также исследуется потенциальный эффект от применения сжатия двумя вариантами алгоритма RLE к файлу, полученному в результате сжатия реализованным методом.
Дата добавления: 2018-06-27; просмотров: 753; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!