Внутри- и межоператорный параллелизм
Как показано на рисунке, параллельное выполнение происходит на двух отдельных уровнях: внутри- и межоператорного параллелизма. Внутриоператорный параллелизм представляет собой параллельное выполнение несколькими серверами одной операции, например, просмотра таблицы, сортировки или соединения. А межоператорный параллелизм относится к одновременному выполнению нескольких отдельных параллельных операций. Например, в то время как один ряд серверов запросов осуществляет параллельный просмотр таблицы, другой ряд может выполнять параллельную сортировку просмотренных строк.
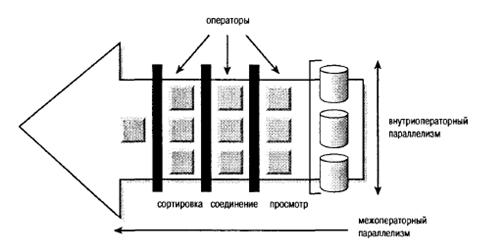
Рис.3. Динамическое распределение данных в очередях таблиц
Эффективный динамический механизм взаимодействия между процессами, называемый очередью таблиц, соединяет каждую пару «Производитель - потребитель» и эффективным образом перераспределяет результат, полученный от ряда серверов производителей, для следующего ряда потребителей. При этом перераспределение происходит динамически с учётом требований оптимального разделения данных для данной операции. В примере с просмотром таблицы, после которого следует сортировка, производители получают результат, распределенный произвольным образом, а соответствующее разделение данных для операции сортировки осуществляется в интервале ключевых значений. Механизм обработки таблиц, показанный на рисунке заключается в следующем: берутся строки, выбранные с помощью процессов просмотра таблиц, а затем прозрачным образом перераспределяются среди серверов сортировки, разделяясь в интервале ключевых значений.
|
|
|
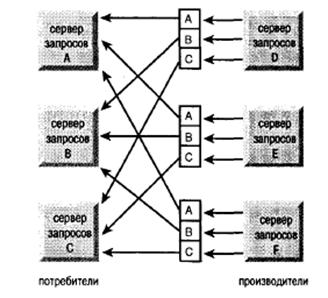
Рис.4. Схематическое представление обмана транзакциями при обработке данных
Разделяемый пул
Область разделяемого пула в SGA (Системная глобальная область) содержит библиотечный кэш, кэш словаря данных, кэш результатов обработки SQL-запросов, кэш результатов обработки функций PL/SQL, буферы для сообщений о параллельном выполнении и управляющие структуры. Словарь данных представляет собой набор таблиц и представлений базы данных, содержащих связанную информацию о базе данных, ее структурах и пользователях. База данных регулярно обращается к словарю данных при синтаксическом разборе SQL-операторов.
База данных настолько часто обращается к словарю данных, что для хранения его данных выделены две специальные области памяти. Одна область называется кэшем словаря данных. Ее также называют кэшем строк, поскольку она хранит данные в виде строк, а не буферов (в которых хранятся целые блоки данных). Другая область памяти для хранения данных словаря называется библиотечным кэшем. Все процессы пользователей базы данных совместно пользуются этими двумя кэшами для доступа к информации из словаря данных. База данных отображает каждый обрабатываемый SQL-оператор в разделяемой области SQL (в то время как частная область SQL расположена в PGA). База данных отслеживает ситуации, когда два пользователя выполняют одинаковый SQL-оператор, а затем повторно использует для них разделяемую область SQL. Разделяемая область SQL содержит дерево синтаксического разбора и план выполнения заданного SQL-оператора. Происходит экономия памяти, используя одну разделяемую область SQL для SQL-операторов, выполняемых несколько раз, что обычно случается, когда много пользователей работают с одним приложением. При синтаксическом разборе нового SQL-оператора база данных выделяет память в разделяемом пуле для хранения разделяемой области SQL. Размер этой памяти зависит от сложности оператора.
|
|
|
База данных обрабатывает программные блоки PL/SQL (процедуры, функции, пакеты, анонимные блоки и триггеры базы данных) практически так же, как и отдельные SQL-операторы. Выделяется частная область для хранения значений конкретного сеанса, который запускает программный блок, включая локальные и глобальные переменные, переменные пакетов (также называемые экземплярами пакета), а также буферы для выполнения SQL. Если к программному блоку обращаются несколько пользователей, для всех их используется единая разделяемая область, при этом у каждого пользователя есть своя отдельная копия частной области SQL, в которой хранятся значения переменных сеанса этого пользователя. Отдельные SQL-операторы, содержащиеся в программном блоке PL/SQL, обрабатываются аналогично другим SQL-операторам. Несмотря на то, что SQL-операторы происходят из программного блока PL/SQL, они используют разделяемую область для хранения их синтаксически разобранных представлений и частную область для каждого сеанса, запускающего оператор. Кэш результатов обработки SQL-запросов и кэш результатов обработки функций PL/SQL используют одну и ту же архитектуру, отображаются посредством динамических представлений производительности ($V) и администрируются с помощью одного и того же пакета. Результаты запросов и их фрагменты могут кэшироваться в памяти в кэше результатов обработки SQL-запросов. После этого база данных сможет использовать кэшированные результаты для будущего выполнения таких же запросов и их фрагментов. Поскольку извлечение результатов из кэша результатов обработки SQL-запросов выполняется значительно быстрее, чем повторная обработка запроса, при выполнении часто используемых запросов можно достичь существенного повышения производительности, если их результаты находятся в кэше. Функция PL/SQL иногда используется для возврата результата вычисления, в котором входными параметрами являются один или несколько параметризованных запросов, вызываемых функцией. В некоторых случаях такие запросы обращаются к данным, изменяемым довольно редко по сравнению с частотой вызова функции. В исходном тексте SQL-функции можно использовать синтаксические конструкции, чтобы указать, что результат следует сохранить в кэше результатов обработки PL/SQL-функций, а также убедиться в том, что кэш будет очищен, когда в таблицах из списка таблиц попадется DML.
|
|
|
|
|
|
Механизм блокирования
Механизм блокирования разработан для обеспечения максимально возможной степени параллельного доступа к данным базы данных. Для транзакций, которые изменяют данные, используются блокировки на уровне строки, а не на уровне блока или таблицы. При изменениях объектов (например, перемещении таблицы) возникают блокировки на уровне объекта, при этом база данных или схема не блокируются. При запросе данных блокировки не возникают. Кроме того, запрос будет выполнен успешно даже в том случае, если опрашиваемые данные уже заблокированы (будут отображены первоначальные значения, восстановленные из данных отмены операций и существовавшие до создания блокировки). В ситуациях, когда несколько транзакций пытаются заблокировать один ресурс, блокировку создаст первая транзакция, которая попыталась обратиться к нему. Другие транзакции будут ожидать окончания первой транзакции. Механизм обслуживания очередей работает автоматически и не требует вмешательства администратора. Все автоматические блокировки снимаются после подтверждения транзакции. Транзакция считается защищенной после выполнения оператора COMMIT или ROLLBACK. Если транзакцию выполнить не удалось, тот же фоновый процесс автоматически отменит все изменения, внесенные незаконченной транзакцией, и снимет все созданные ею блокировки.
Дата добавления: 2018-06-27; просмотров: 332; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!