Минимизация алфавита элементов символов числового кода
При автоматической обработке информации с использованием ЭВМ, как правило, используют числовое (цифровое) кодирование, при этом, естественно, возникает вопрос обоснования используемой системы счисления. Действительно, при уменьшении основания системы счисления упрощается алфавит элементов символов кода, но происходит удлинение символов кода. С другой стороны, чем больше основание системы счисления, тем меньшее число разрядов требуется для представления одного символа кода, а, следовательно, и меньшее время для его передачи, но с ростом основания системы счисления существенно повышаются требования к каналам связи и техническим средствам распознавания элементарных сигналов, соответствующих различным элементам символов кода. В частности, код числа, записанного в двоичной системе счисления, в среднем приблизительно в 3,5 раза длиннее десятичного кода. Так как во всех системах обработки информации приходится хранить большие информационные массивы в виде числовой информации, то одним из существенных критериев выбора алфавита элементов символов числового кода (т.е. основания используемой системы счисления) является минимизация количества электронных элементов в устройствах хранения, а также их простота и надежность.
При определении количества электронных элементов, требуемых для фиксации каждого из элементов символов кода, необходимо исходить из практически оправданного предположения, что для этого требуется количество простейших электронных элементов (например, транзисторов), равное основанию системы счисления a. Тогда для хранения в некотором устройстве n элементов символов кода потребуется M электронных элементов:
|
|
|
M = a·n. (7.1)
Наибольшее количество различных чисел, которое может быть записано в этом устройстве N:
N = an .
Прологарифмировав это выражение и выразив из него n, получим:
n = ln N / ln a.
Преобразовав выражение (7.1) к виду:
M = a ∙ ln N / ln a (7.2)
можно определить, при каком основании логарифмов a количество элементов M будет минимальным при заданном N. Продифференцировав по a функцию M = f(a) и приравняв её производную к нулю, получим:
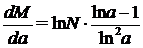 = 0.
= 0.
Очевидно, что для любого конечного a: ln N / ln2 a ≠ 0
и, следовательно,
ln a -1 = 0,
откуда a = e ≈ 2,7.
Так как основание системы счисления может быть только целым числом, то а выбирают равным 2 или 3. Для примера зададимся максимальной емкостью устройства хранения N = 106 чисел. Тогда при различных основаниях систем счисления (а)количество элементов (M)в таком устройстве хранения будет, в соответствии с выражением (7.2), следующие (табл. 7.1):
|
|
|
Таблица 7.1
| а | 2 | 3 | 4 | 5 | 10 | 20 |
| М | 39,2 | 38,2 | 39,2 | 42,9 | 60 | 91,2 |
Следовательно, если исходить из минимизации количества оборудования, то наиболее выгодными окажутся двоичная, троичная и четверичная системы счисления, которые близки по этому параметру. Но так как техническая реализация устройств, работающих в двоичной системе счисления, значительно проще, то наибольшее распространение при числовом кодировании получили коды на основе системы счисления по основанию 2.
Избыточность кодов
Понятие избыточности означает, что фактическая энтропия кода или сообщения (Н)меньше, чем максимально возможная энтропия (Hmax), т. е. число символов в сообщении или элементов в символе кода больше, чем это требовалось бы при полном их использовании.
Понятие избыточности легко пояснить следующим примером.
Выделение полезного сигнала на уровне помех – одна из основных проблем передачи информации. Одним из путей повышения надёжности передачи сообщений может быть передача дополнительных символов, т.е. повышение избыточности сообщений.
|
|
|
Действительно, по теореме Котельникова, непрерывное сообщение (сигнал) можно передать последовательностью мгновенных отсчетов его значений с промежутками между ними  :
:
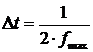 ,
,
где fmax – верхняя граничная частота в спектре сигнала.
При наличии помех промежутки между отсчетами (Δtn) необходимо уменьшать, т.е.
 .
.
В этом случае мы увеличиваем число отсчетов и, следовательно, увеличиваем избыточность сообщения и тем самым повышаем его помехозащищенность.
Пусть сообщение из n символов содержит количество информации I. Если сообщение обладает избыточностью, то его (при отсутствии шума) можно передать меньшим числом символов n0(n0< n). При этом, количества информации (I1и I1max), приходящиеся на один символ сообщения, будут связаны соотношением:
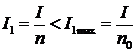
и, следовательно,
n ∙ I1 = n0 ∙ I1max.
За меру избыточности принимается величина R:
 (7.3)
(7.3)
Таким образом, избыточность – это свойство, характеризующее возможность представления тех же сообщений в более экономной форме.
При кодировании избыточных сообщений возникает определенная исходная избыточность кодов. Наличие исходной избыточности уменьшает пропускную способность каналов и увеличивает формат сообщений. Вместе с тем в процессе передачи информации избыточность сообщений и кодов является средством, полезным для борьбы с внешними возмущающими воздействиями и помехами.
|
|
|
По наличию избыточности коды также делятся на избыточные и неизбыточные. Для неизбыточных кодов характерно то, что они позволяют просто определить различные символы сообщения. Переход от неизбыточного кода к избыточному осуществляется путем добавления позиций в кодовых символах, которые можно получить либо путем различных логических операций, выполняемых над основными информационными позициями, либо путем использования алгоритмов, связывающих неизбыточный и избыточный коды. Например, если есть символы сообщения А1; А2; А3; А4, то их можно закодировать в двоичном неизбыточном коде:
А1 = 00; А2 = 01; А3 = 10; А4 = 11.
Для получения избыточного кода можно ввести еще одну позицию, значение которой будет определяться как сумма значений предшествующих символов по модулю два:
А1 = 000; А2 = 011; А3 = 101; А4 = 110.
Особенностью такого кода является то, что он позволяет обнаружить любую единичную ошибку (ошибку в одной из позиций кода), выявившуюся в процессе передачи кода.
Лекция 3.
Дата добавления: 2018-05-12; просмотров: 341; Мы поможем в написании вашей работы! |

Мы поможем в написании ваших работ!